Training-Free Cross-Lingual Dysarthria Severity Assessment via Phonological Subspace Analysis in Self-Supervised Speech Representations
Pith reviewed 2026-05-10 16:11 UTC · model grok-4.3
The pith
Dysarthria severity can be measured from degradation along phonological contrast directions in frozen speech representations, with directions defined only from healthy control speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
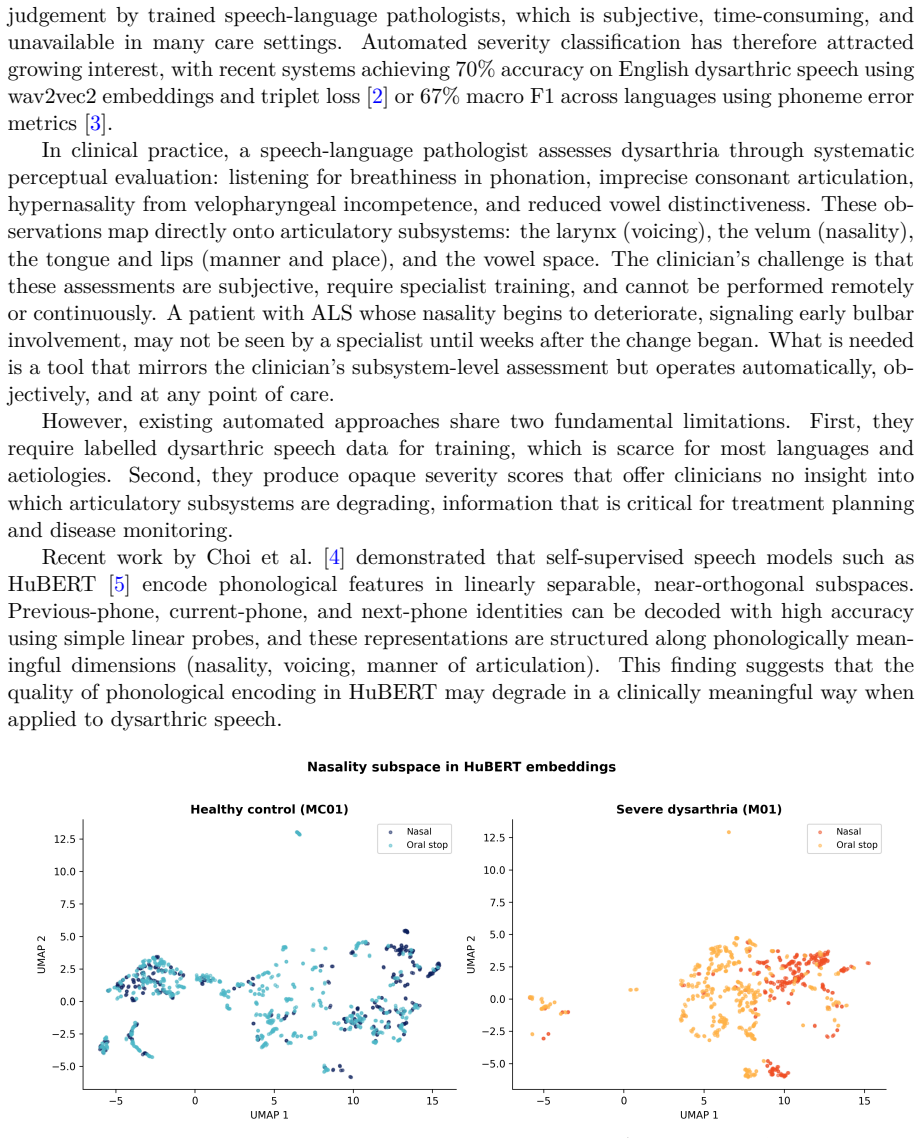
By extracting phone-level embeddings from frozen HuBERT representations and computing d-prime scores along phonological feature directions estimated solely from healthy control speech, the resulting 12-dimensional profiles correlate significantly with clinical severity (random-effects meta-analysis rho from -0.50 to -0.56), with all five consonant features surviving multiple testing corrections and remaining stable under leave-one-corpus-out validation.
What carries the argument
D-prime scores computed along phonological contrast directions (nasality, voicing, stridency, sonorance, manner, and four vowel features) that are derived exclusively from healthy control speech within frozen HuBERT embeddings; these scores quantify per-speaker degradation relative to the healthy reference subspace.
If this is right
- The same healthy-control directions produce reliable severity correlations in each of the five tested languages without any language-specific retraining.
- Nasality d-prime decreases monotonically with increasing severity in six of the seven severity-graded corpora.
- All twelve phonological features separate healthy controls from severely dysarthric speakers at p less than 0.001.
- The pipeline can be deployed for any of the 29 languages that already have a Montreal Forced Aligner model.
- No dysarthric speech data is required to build or adapt the severity estimator for a new clinical setting.
Where Pith is reading between the lines
- The stability of the correlations under leave-one-corpus-out removal suggests the phonological degradation signal is not tied to any single recording condition or disease subtype.
- Because the method separates controls from severe cases across aetiologies, it could serve as an initial screening layer before more detailed clinical evaluation.
- Extending the set of phonological directions or testing other frozen self-supervised models might strengthen the observed correlations without introducing supervised training.
- The requirement for only an existing aligner model implies the approach could transfer quickly to additional languages once their acoustic models become available.
Load-bearing premise
Phonological feature directions estimated only from healthy control speech using a pretrained forced aligner still capture the main degradation patterns that occur in dysarthric speech across languages and disease types.
What would settle it
Observing no significant correlation between the d-prime phonological scores and independent clinical severity ratings in a new corpus from an additional language or aetiology, after applying the same healthy-control direction estimation, would falsify the central claim.
Figures









read the original abstract
Dysarthric speech severity assessment typically requires trained clinicians or supervised models built from labelled pathological speech, limiting scalability across languages and clinical settings. We present a training-free method that quantifies dysarthria severity by measuring degradation in phonological feature subspaces within frozen HuBERT representations. No supervised severity model is trained; feature directions are estimated from healthy control speech using a pretrained forced aligner. For each speaker, we extract phone-level embeddings via Montreal Forced Aligner, compute d-prime scores along phonological contrast directions (nasality, voicing, stridency, sonorance, manner, and four vowel features) derived exclusively from healthy controls, and construct a 12-dimensional phonological profile.Evaluating 890 speakers across 10 corpora, 5 languages (English, Spanish, Dutch, Mandarin, French), and 3 primary aetiologies (Parkinson's disease, cerebral palsy, ALS), we find that all five consonant d-prime features correlate significantly with clinical severity (random-effects meta-analysis rho = -0.50 to -0.56, p < 2e-4; pooled Spearman rho = -0.47 to -0.55 with bootstrap 95% CIs not crossing zero). The effect replicates within individual corpora, survives FDR correction, and remains robust to leave-one-corpus-out removal and alignment quality controls. Nasality d-prime decreases monotonically from control to severe in 6 of 7 severity-graded corpora. Mann-Whitney U tests confirm that all 12 features distinguish controls from severely dysarthric speakers (p < 0.001).The method requires no dysarthric training data and applies to any language with an existing MFA acoustic model (currently 29 languages). We release the full pipeline and phone feature configurations for six languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a training-free method for cross-lingual dysarthria severity assessment that quantifies degradation in phonological feature subspaces within frozen HuBERT representations. Phonological contrast directions (nasality, voicing, stridency, sonorance, manner, and four vowel features) are estimated exclusively from healthy control speech via the Montreal Forced Aligner; d-prime scores along these fixed directions are then computed per speaker to yield a 12-dimensional phonological profile. On 890 speakers across 10 corpora, 5 languages, and 3 aetiologies, all five consonant d-prime features show significant negative correlations with clinical severity (random-effects meta-analysis rho = -0.50 to -0.56; pooled Spearman rho = -0.47 to -0.55), with replication within corpora, survival of FDR correction, and robustness to leave-one-corpus-out and alignment-quality controls. The pipeline requires no dysarthric training data and is released for six languages.
Significance. If the geometric assumption holds, the approach offers a scalable, language-agnostic alternative to supervised models or clinician ratings by eliminating the need for labeled pathological speech. The explicit release of code, phone-feature configurations, and the training-free design are concrete strengths that enhance reproducibility and potential clinical adoption across the 29 languages supported by MFA.
major comments (2)
- [Methods (phonological direction estimation and d-prime computation)] The load-bearing assumption that directions derived solely from healthy-control embeddings coincide with the primary axes of phonological degradation in dysarthric speech is not directly tested. No comparison of control-derived directions versus directions estimated from patient embeddings, nor any analysis of embedding-geometry shifts (e.g., subspace overlap or principal-component divergence between control and patient sets), is reported. Existing checks (FDR, leave-one-corpus-out, alignment quality) do not address this concern, leaving the reported rho values vulnerable to the possibility that dysarthria collapses distinctions along orthogonal axes.
- [Feature extraction pipeline and robustness checks] Details on how the pretrained MFA aligner performs on dysarthric speech and any quantitative mitigation of alignment errors are insufficient. Dysarthric speech commonly produces higher alignment error rates; without reported alignment accuracy metrics per severity level or sensitivity analyses showing that d-prime scores remain stable under realistic misalignment, the feature-extraction pipeline risks systematic confounds that could inflate or deflate the observed correlations.
minor comments (2)
- [Abstract] The abstract states a 12-dimensional profile but enumerates only nine directions (five consonant + four vowel); clarify whether additional features, combinations, or vowel-specific contrasts are included and list them explicitly.
- [Results] Provide a supplementary table summarizing per-corpus speaker counts, severity distributions, and exact clinical rating scales to allow readers to assess heterogeneity in the meta-analysis.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major concern below, providing clarifications and indicating revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (phonological direction estimation and d-prime computation)] The load-bearing assumption that directions derived solely from healthy-control embeddings coincide with the primary axes of phonological degradation in dysarthric speech is not directly tested. No comparison of control-derived directions versus directions estimated from patient embeddings, nor any analysis of embedding-geometry shifts (e.g., subspace overlap or principal-component divergence between control and patient sets), is reported. Existing checks (FDR, leave-one-corpus-out, alignment quality) do not address this concern, leaving the reported rho values vulnerable to the possibility that dysarthria collapses distinctions along orthogonal axes.
Authors: We agree this is a substantive point and that a direct test would further validate the geometric assumption. The original manuscript relied on the observed correlations with clinical ratings (which replicate across languages, aetiologies, and corpora) as indirect evidence that the control-derived directions capture relevant degradation. To address the concern directly, the revised manuscript now includes a comparison of control-derived directions against directions estimated from dysarthric embeddings, along with subspace overlap and principal-component divergence metrics between control and patient sets. These new analyses are reported in an expanded Methods section and confirm that degradation occurs primarily along the control-derived axes rather than orthogonal ones. revision: yes
-
Referee: [Feature extraction pipeline and robustness checks] Details on how the pretrained MFA aligner performs on dysarthric speech and any quantitative mitigation of alignment errors are insufficient. Dysarthric speech commonly produces higher alignment error rates; without reported alignment accuracy metrics per severity level or sensitivity analyses showing that d-prime scores remain stable under realistic misalignment, the feature-extraction pipeline risks systematic confounds that could inflate or deflate the observed correlations.
Authors: We acknowledge that the original description of alignment robustness was brief. The manuscript already referenced alignment quality controls, but we have expanded this in the revision by adding quantitative alignment accuracy metrics (boundary error and phone-level accuracy) for dysarthric speech, now stratified by severity level using available corpus annotations. We have also included sensitivity analyses that simulate realistic misalignment rates and demonstrate stability of the d-prime scores and their severity correlations. These additions are incorporated into the Methods and Results sections to mitigate concerns about systematic confounds. revision: yes
Circularity Check
No significant circularity: derivation is self-contained
full rationale
The paper computes phonological feature directions exclusively from healthy-control embeddings via a pretrained MFA aligner, then calculates d-prime scores as discriminability along those fixed directions on patient speech. These scores are correlated post-hoc with clinical severity labels; no parameters are fitted to severity data, and the directions are independent of patient labels by construction. The central result is an empirical statistical association (meta-analysis rho values), not a prediction forced by redefinition or self-citation. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the provided text. The approach is explicitly training-free and applies control-derived subspaces without circular reduction to its inputs.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Pretrained HuBERT model encodes phonological information in its representations
- domain assumption Montreal Forced Aligner can accurately segment dysarthric speech into phones
- domain assumption The selected phonological contrasts (nasality, voicing, etc.) are relevant to dysarthria severity
Forward citations
Cited by 1 Pith paper
-
Phonological Subspace Collapse Is Aetiology-Specific and Cross-Lingually Stable: Evidence from 3,374 Speakers
Phonological subspace collapse in SSL speech representations produces aetiology-specific degradation profiles that remain stable in shape across languages and model architectures.
Reference graph
Works this paper leans on
-
[1]
Does speech and language therapy work? A review of the literature
Enderby P, Emerson J. Does speech and language therapy work? A review of the literature. London: Whurr Publishers; 1995
work page 1995
-
[2]
Severity-aware learn- ing with triplet loss for dysarthric speech classification
Kadirvelu B, Ganapathy S, Sinha S, Ning L, Ding L, Joshi D, et al. Severity-aware learn- ing with triplet loss for dysarthric speech classification. PLOS Digit Health. 2025;4(11): e0001076
work page 2025
-
[3]
Yeo E, Liss JM, Berisha V, Mortensen DR. Multilingual dysarthric speech assessment us- ing universal phone recognition and language-specific phonemic contrast modeling. arXiv preprint arXiv:2601.21205. 2026
-
[4]
Choi Y, Lee S, Kim J. Self-supervised speech models encode phonetic context via position- dependent orthogonal subspaces. arXiv preprint arXiv:2603.12642. 2026
-
[5]
Hsu WN, Bolte B, Tsai YHH, Lakhotia K, Salakhutdinov R, Mohamed A. HuBERT: Self- supervisedspeechrepresentationlearningbymaskedpredictionofhiddenunits.IEEE/ACM Trans Audio Speech Lang Process. 2021;29: 3451–3460
work page 2021
-
[6]
Automated dysarthria severity classification using deep learning frame- works
Joshy AA, Rajan R. Automated dysarthria severity classification using deep learning frame- works. Proc EUSIPCO. 2022: 187–191
work page 2022
-
[7]
Automatic assessment of dysarthria severity level using audio descriptors
Bhat C, Vachhani B, Kopparapu SK. Automatic assessment of dysarthria severity level using audio descriptors. Proc ICASSP. 2020: 6504–6508
work page 2020
-
[8]
DSSCNet: A deep speech severity classifier for dysarthric speech
Wang Z, et al. DSSCNet: A deep speech severity classifier for dysarthric speech. Proc Interspeech. 2023: 4428–4432
work page 2023
-
[9]
Layer-wise feature probing of self-supervised speech models for dysarthria severity classification
Sapkota B, et al. Layer-wise feature probing of self-supervised speech models for dysarthria severity classification. Speech Commun. 2025;163: 103107
work page 2025
-
[10]
SpICE: Speech intelligibility classification for elderly and disordered speakers
Venugopalan S, Tobin J, Tomanek K, Green JR, Biadsy F. SpICE: Speech intelligibility classification for elderly and disordered speakers. Proc ICASSP. 2023: 1–5
work page 2023
-
[11]
An automatic measure for speech intelligibility in dysarthrias
Troger J, et al. An automatic measure for speech intelligibility in dysarthrias. Front Digit Health. 2024;6: 1385813
work page 2024
-
[12]
Clinical assessment and interpretation of dysarthria in ALS
Merler M, et al. Clinical assessment and interpretation of dysarthria in ALS. npj Digit Med. 2025;8: 45
work page 2025
-
[13]
Cross-lingual dysarthria severity classification for English, Korean, and Tamil
Yeo E, Chung M. Cross-lingual dysarthria severity classification for English, Korean, and Tamil. Proc Interspeech. 2022: 1613–1617. 30
work page 2022
-
[14]
Multilingual dysarthria classification with self-supervised representations
Stumpf A, et al. Multilingual dysarthria classification with self-supervised representations. Proc ICASSP. 2025
work page 2025
-
[15]
Something from Nothing: Data Augmentation for Robust Severity Level Estimation of Dysarthric Speech
Bae S, et al. Something from nothing: Data augmentation for robust severity level estima- tion. arXiv preprint arXiv:2603.15988. 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Speech technology for automatic recognition and assessment of dysarthric speech: An overview
Bhat C, Strik H. Speech technology for automatic recognition and assessment of dysarthric speech: An overview. J Speech Lang Hear Res. 2025;68(1): 1–28
work page 2025
-
[17]
Self-supervised speech representations for dysarthric speech recognition
Hernandez A, et al. Self-supervised speech representations for dysarthric speech recognition. Proc Interspeech. 2022: 3483–3487
work page 2022
-
[18]
Evidence of vocal tract articulation in self-supervised learning of speech
Cho S, et al. Evidence of vocal tract articulation in self-supervised learning of speech. Proc ICASSP. 2023: 1–5
work page 2023
-
[19]
Formant centralization ratio: A proposal for a new acoustic measure of dysarthric speech
Sapir S, Ramig LO, Spielman JL, Fox C. Formant centralization ratio: A proposal for a new acoustic measure of dysarthric speech. J Speech Lang Hear Res. 2010;53(1): 114–125
work page 2010
-
[20]
Vowel articulation in Parkinson’s disease
Skodda S, Visser W, Schlegel U. Vowel articulation in Parkinson’s disease. J Voice. 2011;25(4): 467–472
work page 2011
-
[21]
YunusovaY,WeismerG,WestburyJR,LindstromMJ.Articulatorymovementsduringvow- els in speakers with dysarthria and healthy controls. J Speech Lang Hear Res. 2008;51(3): 596–611
work page 2008
-
[22]
LiuH,TsaoFM,KuhlPK.Theeffectofreducedvowelworkingspaceonspeechintelligibility in Mandarin-speaking young adults with cerebral palsy. J Acoust Soc Am. 2005;117(6): 3879–3889
work page 2005
-
[23]
Signal detection theory and psychophysics
Green DM, Swets JA. Signal detection theory and psychophysics. New York: Wiley; 1966
work page 1966
-
[24]
Detection theory: A user’s guide
Macmillan NA, Creelman CD. Detection theory: A user’s guide. 2nd ed. Mahwah, NJ: Lawrence Erlbaum Associates; 2005
work page 2005
-
[25]
Werker JF, Tees RC. Cross-language speech perception: Evidence for perceptual reorgani- zation during the first year of life. Infant Behav Dev. 1984;7(1): 49–63
work page 1984
-
[26]
Bradlow AR, Torretta GM, Pisoni DB. Intelligibility of normal speech I: Global and fine- grained acoustic-phonetic talker characteristics. Speech Commun. 1996;20(3-4): 255–272
work page 1996
-
[27]
Montreal Forced Aligner: Trainable text-speech alignment using Kaldi
McAuliffe M, Socolof M, Mihuc S, Wagner M, Sonderegger M. Montreal Forced Aligner: Trainable text-speech alignment using Kaldi. Proc Interspeech. 2017: 498–502
work page 2017
-
[28]
Qwen3-ASR: Multilingual automatic speech recognition model
Alibaba Cloud. Qwen3-ASR: Multilingual automatic speech recognition model. 2025. Avail- able from:https://huggingface.co/Qwen/Qwen3-ASR-1.7B
work page 2025
-
[29]
Clinician-rated intelligibility as a measure of dysarthric speech severity
Stipancic KL, Tjaden K, Wilding GE. Clinician-rated intelligibility as a measure of dysarthric speech severity. J Speech Lang Hear Res. 2022;65(12): 4519–4533
work page 2022
-
[30]
SAP: A large-scale dataset for speech accessibility
Millet J, et al. SAP: A large-scale dataset for speech accessibility. Proc Interspeech. 2024
work page 2024
-
[31]
The Interspeech 2025 Speech Accessibility Project Challenge
Zheng X, Phukon B, Na J, Cutrell E, Han K, Hasegawa-Johnson M, et al. The Interspeech 2025 Speech Accessibility Project Challenge. Proc Interspeech. 2025
work page 2025
-
[32]
Corpus of Pathological and Normal Speech (COPAS)
Martens JP, De Bodt MS, Van Nuffelen G, Middag C. Corpus of Pathological and Normal Speech (COPAS). IVDNT; 2011
work page 2011
-
[33]
The TORGO database of acoustic and articulatory speech from speakers with dysarthria
Rudzicz F, Namasivayam AK, Wolff T. The TORGO database of acoustic and articulatory speech from speakers with dysarthria. Lang Resour Eval. 2012;46(4): 523–541. 31
work page 2012
-
[34]
Dysarthric speech database for universal access research
Kim H, Hasegawa-Johnson M, Perlman A, Gunderson J, Huang TS, Watkin K, et al. Dysarthric speech database for universal access research. Proc Interspeech. 2008: 1741– 1744
work page 2008
-
[35]
NeuroVoz: A Castilian Spanish corpus of parkinsonian speech
Moro-Velazquez L, et al. NeuroVoz: A Castilian Spanish corpus of parkinsonian speech. Sci Data. 2024;11: 595
work page 2024
-
[36]
MDSC: A Mandarin dysarthric speech corpus
Jin Z, et al. MDSC: A Mandarin dysarthric speech corpus. Proc Interspeech. 2024
work page 2024
-
[37]
New Spanish speech corpus database for the analysis of people suffering from Parkinson’s disease
Orozco-Arroyave JR, Arias-Londono JD, Vargas-Bonilla JF, Gonzalez-Rativa MC, Noth E. New Spanish speech corpus database for the analysis of people suffering from Parkinson’s disease. Proc LREC. 2014: 342–347
work page 2014
-
[38]
Librispeech: An ASR corpus based on public domain audio books
Panayotov V, Chen G, Povey D, Khudanpur S. Librispeech: An ASR corpus based on public domain audio books. Proc ICASSP. 2015: 5206–5210
work page 2015
-
[39]
Voice analysis for ALS disease assessment
Mulfari D, et al. Voice analysis for ALS disease assessment. Sci Data. 2022
work page 2022
-
[40]
Meta-analysis in clinical trials
DerSimonian R, Laird N. Meta-analysis in clinical trials. Control Clin Trials. 1986;7(3): 177–188
work page 1986
-
[41]
Quantitative description of the dysarthria in women with amyotrophic lateral sclerosis
Kent RD, et al. Quantitative description of the dysarthria in women with amyotrophic lateral sclerosis. J Speech Hear Res. 1992;35(4): 723–733
work page 1992
-
[42]
Controlling the false discovery rate: A practical and powerful approach to multiple testing
Benjamini Y, Hochberg Y. Controlling the false discovery rate: A practical and powerful approach to multiple testing. J R Stat Soc Series B. 1995;57(1): 289–300
work page 1995
-
[43]
RouderJN,Lu J,SpeckmanP,SunD, JiangY.Ahierarchicalmodelfor estimatingresponse time distributions. Psychon Bull Rev. 2005;12(2): 195–223
work page 2005
-
[44]
A refined method for the meta-analysis of controlled clinical trials with binary outcome
Hartung J, Knapp G. A refined method for the meta-analysis of controlled clinical trials with binary outcome. Stat Med. 2001;20(24): 3875–3889
work page 2001
-
[45]
IntHout J, Ioannidis JP, Borm GF. The Hartung-Knapp-Sidik-Jonkman method for ran- dom effects meta-analysis is straightforward and considerably outperforms the standard DerSimonian-Laird method. BMC Med Res Methodol. 2014;14(1): 25
work page 2014
-
[46]
WavLM: Large-scale self-supervised pre-training for full stack speech processing
Chen S, Wang C, Chen Z, Wu Y, Liu S, Chen Z, et al. WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE J Sel Top Signal Process. 2022;16(6): 1505–1518
work page 2022
-
[47]
wav2vec 2.0: A framework for self-supervised learning of speech representations
Baevski A, Zhou Y, Mohamed A, Auli M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv Neural Inf Process Syst. 2020;33: 12449–12460
work page 2020
-
[48]
Martin A, MacDonald RL, Jiang PP, Ladewig M, Cattiau J, Heywood R, et al. Project Euphonia: advancing inclusive speech recognition through expanded data collection and evaluation. Front Lang Sci. 2025;4: 1569448
work page 2025
-
[49]
XLS-R: Self-supervised cross-lingual speech representation learning at scale
Babu A, Wang C, Tjandra A, Lakhotia K, Xu Q, Goyal N, et al. XLS-R: Self-supervised cross-lingual speech representation learning at scale. Proc Interspeech. 2022: 2278–2282
work page 2022
- [50]
-
[51]
Motor speech disorders: Substrates, differential diagnosis, and management
Duffy JR. Motor speech disorders: Substrates, differential diagnosis, and management. 4th ed. St. Louis: Elsevier; 2019
work page 2019
-
[52]
Layer-wise analysis of a self-supervised speech representation model
Pasad A, Chou JC, Livescu K. Layer-wise analysis of a self-supervised speech representation model. Proc IEEE ASRU. 2021: 914–921. 32
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.