Something from Nothing: Data Augmentation for Robust Severity Level Estimation of Dysarthric Speech
Pith reviewed 2026-05-15 10:02 UTC · model grok-4.3
The pith
A teacher-student pipeline with pseudo-labels and contrastive pretraining turns unlabeled dysarthric speech into a robust severity estimator that works across unseen languages and disease types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
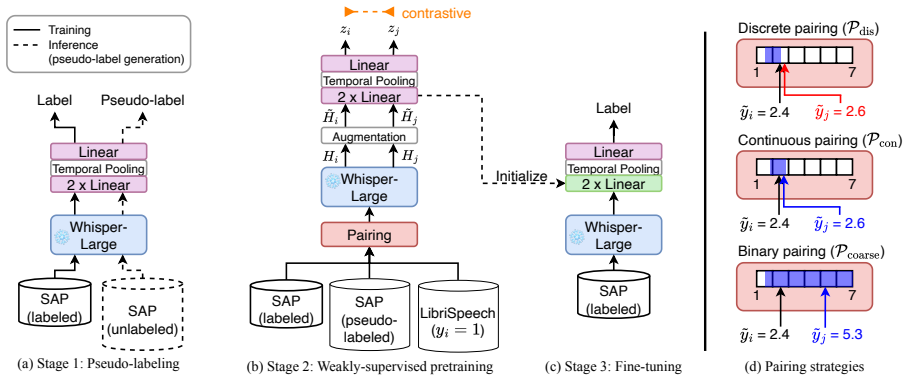
The central claim is that a three-stage framework—pseudo-label generation on unlabeled dysarthric speech by a teacher model, followed by weakly supervised pretraining via label-aware contrastive learning that mixes typical and dysarthric utterances, then task-specific fine-tuning—yields a severity-level estimator whose average SRCC with human ratings reaches 0.761 across five completely unseen datasets spanning multiple etiologies and languages.
What carries the argument
The label-aware contrastive learning strategy that pulls embeddings of speech samples with similar pseudo-labels closer together and pushes dissimilar ones apart during pretraining on combined typical and dysarthric data.
Load-bearing premise
The pseudo-labels produced by the teacher model are accurate enough that contrastive pretraining on them produces features that generalize to new acoustic conditions and disease types.
What would settle it
Training the full framework on a fresh collection of dysarthric speech from an entirely new language and etiology and measuring an average SRCC below 0.6 on a held-out portion of that collection would falsify the robustness claim.
Figures




read the original abstract
Dysarthric speech quality assessment (DSQA) is critical for clinical diagnostics and inclusive speech technologies. However, subjective evaluation is costly and difficult to scale, and the scarcity of labeled data limits robust objective modeling. To address this, we propose a three-stage framework that leverages unlabeled dysarthric speech and large-scale typical speech datasets to scale training. A teacher model first generates pseudo-labels for unlabeled samples, followed by weakly supervised pretraining using a label-aware contrastive learning strategy that exposes the model to diverse speakers and acoustic conditions. The pretrained model is then fine-tuned for the downstream DSQA task. Experiments on five unseen datasets spanning multiple etiologies and languages demonstrate the robustness of our approach. Our Whisper-based baseline significantly outperforms SOTA DSQA predictors such as SpICE, and the full framework achieves an average SRCC of 0.761 across unseen test datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a three-stage framework for dysarthric speech quality assessment (DSQA) to mitigate labeled data scarcity: (1) a teacher model generates pseudo-labels on unlabeled dysarthric speech, (2) label-aware contrastive pretraining on a mix of unlabeled dysarthric and large-scale typical speech data, and (3) fine-tuning for severity estimation. Experiments on five unseen datasets spanning multiple etiologies and languages report that a Whisper-based baseline outperforms prior SOTA predictors such as SpICE, with the full framework achieving an average SRCC of 0.761.
Significance. If the central claims hold, the work provides a scalable route to train robust DSQA models by exploiting abundant unlabeled speech, which could improve generalization across etiologies, languages, and acoustic conditions. The multi-dataset evaluation on held-out unseen data is a positive design choice that directly tests cross-condition robustness.
major comments (2)
- [Abstract and §3] Abstract and framework description (§3): The reported average SRCC of 0.761 on five unseen datasets is presented without error bars, ablation results isolating the contribution of the label-aware contrastive stage, or any direct metric of pseudo-label accuracy (e.g., SRCC of teacher pseudo-labels versus human ratings on a held-out dysarthric subset). Because the entire pipeline depends on the teacher producing sufficiently accurate pseudo-labels for the contrastive pretraining to learn generalizable severity cues, the absence of this validation leaves open the possibility that observed gains arise from label noise propagation rather than the proposed augmentation strategy.
- [§4] Experiments (§4): The claim that the framework generalizes to unseen etiologies, languages, and acoustic conditions rests on performance measured across five held-out datasets, yet no statistical significance tests, confidence intervals, or cross-dataset variance analysis accompany the SRCC numbers. This makes it impossible to determine whether the outperformance over SpICE is reliable or dataset-specific.
minor comments (2)
- [Abstract] The abstract states that the Whisper baseline 'significantly outperforms' SpICE but provides no numerical comparison or reference to the specific table/figure containing those results.
- [§3.2] Notation for the contrastive loss and pseudo-label generation process could be clarified with an explicit equation or pseudocode block to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of validation and statistical rigor. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and framework description (§3): The reported average SRCC of 0.761 on five unseen datasets is presented without error bars, ablation results isolating the contribution of the label-aware contrastive stage, or any direct metric of pseudo-label accuracy (e.g., SRCC of teacher pseudo-labels versus human ratings on a held-out dysarthric subset). Because the entire pipeline depends on the teacher producing sufficiently accurate pseudo-labels for the contrastive pretraining to learn generalizable severity cues, the absence of this validation leaves open the possibility that observed gains arise from label noise propagation rather than the proposed augmentation strategy.
Authors: We agree that direct validation of pseudo-label quality is necessary to rule out noise propagation. In the revised manuscript we will add error bars to all reported SRCC values. We will also include a new ablation that isolates the label-aware contrastive pretraining stage and report the SRCC between teacher pseudo-labels and human ratings on a held-out dysarthric subset. These additions will confirm that the observed gains arise from the proposed strategy. revision: yes
-
Referee: [§4] Experiments (§4): The claim that the framework generalizes to unseen etiologies, languages, and acoustic conditions rests on performance measured across five held-out datasets, yet no statistical significance tests, confidence intervals, or cross-dataset variance analysis accompany the SRCC numbers. This makes it impossible to determine whether the outperformance over SpICE is reliable or dataset-specific.
Authors: We concur that statistical analysis is required to support generalization claims. In the revision we will add confidence intervals to the SRCC results, perform paired statistical significance tests against SpICE and other baselines, and include a cross-dataset variance analysis. These changes will demonstrate that the outperformance is consistent rather than dataset-specific. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical three-stage ML pipeline (teacher pseudo-labeling on unlabeled data, label-aware contrastive pretraining, then fine-tuning) evaluated via SRCC on five held-out unseen datasets spanning etiologies, languages, and conditions. No equations, self-definitional steps, or self-citations are described that reduce the reported performance metric to a fitted parameter or input by construction. The evaluation on independent test sets provides external validation, aligning with standard non-circular practice for such frameworks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pseudo-labels from teacher model are sufficiently reliable for contrastive pretraining
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A teacher model first generates pseudo-labels for unlabeled samples, followed by weakly supervised pretraining using a label-aware contrastive learning strategy... LStage2 = Lcontrast + λLvar
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We employ a label-aware contrastive learning approach inspired by [12] to better align the representations with perceptual quality labels.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Training-Free Cross-Lingual Dysarthria Severity Assessment via Phonological Subspace Analysis in Self-Supervised Speech Representations
A training-free method quantifies dysarthria severity via d-prime scores on phonological contrasts in HuBERT embeddings, correlating with clinical ratings across 5 languages and multiple conditions.
-
Phonological Subspace Collapse Is Aetiology-Specific and Cross-Lingually Stable: Evidence from 3,374 Speakers
Phonological subspace collapse in SSL speech representations produces aetiology-specific degradation profiles that remain stable in shape across languages and model architectures.
Reference graph
Works this paper leans on
-
[1]
Introduction Dysarthria is a motor speech disorder caused by neurological impairments, leading to substantial degradation in acoustic and perceptual characteristics. Accurate dysarthric speech quality assessment (DSQA) is essential for clinical diagnosis, early detection of progressive neurological conditions, rehabilitation monitoring, and the developmen...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Related Works 2.1. Speech Quality Assessment Speech quality assessment (SQA) aims to predict perceived speech quality, typically represented by a mean opinion score (MOS). Traditional intrusive metrics such as PESQ [18] and signal-based measures like SI-SNR [19] and STOI [20] require reference signals, and even codec-oriented intrusive metrics like W ARP-...
work page 2022
-
[3]
further improves this approach for the regression task by contrasting samples based on the label order, and improves ro- bustness, efficiency, and generalization. [30] proposes an SQA model with contrastive pretraining on audio pairs generated by injecting noise at perceptually similar SNR levels. However, applying such methods to DSQA is challenging due ...
-
[4]
Background 3.1. Severity Level Prediction Severity-level prediction is a key dimension of dysarthric speech quality assessment (DSQA), aiding clinical assessment and providing auxiliary supervision for downstream tasks such as automatic dysarthric speech recognition (ASR) [31] and dysarthric speech generation with a TTS model [32]. How- ever, collecting d...
work page 2025
-
[5]
Proposed Method Our goal is to develop a robust and generalizable DSQA model. Due to the scarcity of labeled dysarthric speech data, our key motivation is to leverage large amounts of unlabeled dysarthric speech alongside large-scale typical speech. This allows the model to be exposed to diverse speaker identities and acous- tic environments. However, eff...
-
[6]
Experiments 5.1. Experimental setup Whisper-large-v3 [26] is adopted as the backbone for feature extraction and is frozen throughout training. Whisper features are extracted after applying voice activity detection (V AD) [37] to the original speech signals following [38]. For Stage 1, two linear layers are applied, followed by statistical temporal pooling...
-
[7]
Broad Impact This work advances scalable and automated assessment of dysarthric speech severity, with potential benefits for clinical monitoring, rehabilitation, and the development of more in- clusive speech technologies. Our experiments further suggest that the proposed approach can generalize to non-English lan- guages, where labeled data are often eve...
-
[8]
Conclusion and Future Works In this work, we proposed a three-stage framework for ro- bust dysarthric speech severity estimation that leverages unla- beled dysarthric speech and large-scale typical speech through (a)τ= 0.1 (b)τ= 1.0 (c)τ= 10.0 (d)τ= 100.0 Figure 5:Embedding spaces with differentτ. Since the Lib- riSpeech and SAP datasets have distinct cha...
-
[9]
Generative AI Use Disclosure The authors acknowledge the use of an AI tool for copyediting and polishing the English language in this manuscript. The tool was used only to improve clarity, grammar, and style, and was not used to generate substantial portions of the manuscript or to develop the scientific content. All research design, experiments, analyses...
-
[10]
DNSMOS: A non- intrusive perceptual objective speech quality metric to evaluate noise suppressors,
C. K. A. Reddy, V . Gopal, and R. Cutler, “DNSMOS: A non- intrusive perceptual objective speech quality metric to evaluate noise suppressors,” inProc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2021, pp. 6493–6497
work page 2021
-
[11]
UTMOS: UTokyo-sarulab system for voicemos challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichiet al., “UTMOS: UTokyo-sarulab system for voicemos challenge 2022,” inProc. Interspeech, 2022, pp. 4521–4525
work page 2022
-
[12]
Speech intelligibility classifiers from 550k disordered speech samples,
S. Venugopalan, J. Tobin, S. J. Yang, K. Seaver, R. J. Cave et al., “Speech intelligibility classifiers from 550k disordered speech samples,” inProc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2023, pp. 1–5
work page 2023
-
[13]
Disordered speech data collection: Lessons learned at 1 million utterances from project euphonia
R. L. MacDonald, P.-P. Jiang, J. Cattiau, R. Heywood, R. Cave et al., “Disordered speech data collection: Lessons learned at 1 million utterances from project euphonia.” inProc. Interspeech, vol. 2021, 2021, pp. 4833–4837
work page 2021
-
[14]
J. Narain, V . Kowtha, C. Lea, L. Tooley, D. Yeeet al., “V oice Quality Dimensions as Interpretable Primitives for Speaking Style for Atypical Speech and Affect,” inProc. Interspeech, 2025, pp. 4628–4632
work page 2025
-
[15]
Community-supported shared infrastructure in sup- port of speech accessibility,
M. Hasegawa-Johnson, X. Zheng, H. Kim, C. Mendes, M. Dick- insonet al., “Community-supported shared infrastructure in sup- port of speech accessibility,”Journal of Speech, Language, and Hearing Research, vol. 67, no. 11, pp. 4162–4175, 2024
work page 2024
-
[16]
A sim- ple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A sim- ple framework for contrastive learning of visual representations,” inProc. of the International Conference on Machine Learning (ICML), vol. 119, 2020, pp. 1597–1607
work page 2020
-
[17]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 12 449–12 460
work page 2020
-
[18]
Hubert: Self-supervised speech representation learning by masked prediction of hidden units,
W.-N. Hsu, B. Bolte, Y .-H. H. Tsai, K. Lakhotia, R. Salakhutdinov et al., “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021
work page 2021
-
[19]
Lib- rispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an asr corpus based on public domain audio books,” in Proc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2015, pp. 5206–5210
work page 2015
-
[20]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeaveyet al., “Robust speech recognition via large-scale weak supervision,” inProc. of the International Conference on Machine Learning (ICML), 2023, pp. 28 492–28 518
work page 2023
-
[21]
Su- pervised contrastive learning,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tianet al., “Su- pervised contrastive learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 18 661–18 673
work page 2020
-
[22]
Dysarthric speech database for universal access re- search,
H. Kim, M. Hasegawa-Johnson, A. Perlman, J. Gunderson, T. S. Huanget al., “Dysarthric speech database for universal access re- search,” inProc. Interspeech, 2008, pp. 1741–1744
work page 2008
-
[23]
DysArinV ox: DYSphonia & DYSarthria mandARIN speech corpus,
H. Zhang, T. Zhang, G. Liu, D. Fu, X. Houet al., “DysArinV ox: DYSphonia & DYSarthria mandARIN speech corpus,” inProc. Interspeech, 2024, pp. 932–936
work page 2024
-
[24]
EasyCall Corpus: A dysarthric speech dataset,
R. Turrisi, A. Braccia, M. Emanuele, S. Giulietti, M. Pugliatti et al., “EasyCall Corpus: A dysarthric speech dataset,” inProc. Interspeech, 2021, pp. 41–45
work page 2021
-
[25]
EW A-DB – early warning of alzheimer speech database,
I. of Informatics of the Slovak Academy of Sciences, A. P. s.r.o., P.-E. University, M. Trnka, and M. Rusko, “EW A-DB – early warning of alzheimer speech database,” 2023
work page 2023
-
[26]
NeuroV oz: a castil- lian spanish corpus of parkinsonian speech,
J. Mendes-Laureano, J. A. G ´omez-Garc´ıa, A. Guerrero-L ´opez, E. Luque-Buzo, J. D. Arias-Londo ˜noet al., “NeuroV oz: a castil- lian spanish corpus of parkinsonian speech,”Scientific Data, vol. 11, no. 1, p. 1367, 2024
work page 2024
-
[27]
A. W. Rix, J. G. Beerends, M. P. Hollier, and A. P. Hekstra, “Per- ceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs,” in Proc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), vol. 2, 2001, pp. 749–752
work page 2001
-
[28]
SDR – half-baked or well done?
J. L. Roux, S. Wisdom, H. Erdogan, and J. R. Hershey, “SDR – half-baked or well done?” inProc. of the IEEE International Con- ference on Acoustics, Speech, and Signal Processing (ICASSP), 2018, pp. 626–630
work page 2018
-
[29]
A short-time objective intelligibility measure for time-frequency weighted noisy speech,
C. H. Taal, R. C. Hendriks, R. Heusdens, and J. R. Jensen, “A short-time objective intelligibility measure for time-frequency weighted noisy speech,” inProc. of the IEEE International Con- ference on Acoustics, Speech, and Signal Processing (ICASSP), 2010, pp. 4214–4217
work page 2010
-
[30]
Warp-Q: Quality prediction for generative neural speech codecs,
W. A. Jassim, J. Skoglund, M. Chinen, and A. Hines, “Warp-Q: Quality prediction for generative neural speech codecs,” inProc. of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2021, pp. 401–405
work page 2021
-
[31]
W. C. Huang, E. Cooper, Y . Tsao, H.-M. Wang, T. Todaet al., “The V oiceMOS Challenge 2022,” inProc. Interspeech, 2022, pp. 4536–4540
work page 2022
-
[32]
On the relation between speech quality and quantized latent represen- tations of neural codecs,
M. M. Halimeh, M. Torcoli, P. Grundhuber, and E. Habets, “On the relation between speech quality and quantized latent represen- tations of neural codecs,” inProc. of the IEEE International Con- ference on Acoustics, Speech, and Signal Processing (ICASSP), 2025, pp. 1–5
work page 2025
-
[33]
Can we reconstruct a dysarthric voice with the large speech model parler TTS?
A. Sanchez and S. King, “Can we reconstruct a dysarthric voice with the large speech model parler TTS?” inProc. Interspeech, 2025, pp. 4138–4142
work page 2025
-
[34]
Objective and Subjective Evaluation of Diffusion-Based Speech Enhancement for Dysarthric Speech,
D. de Groot, T. Patel, D. Kayande, O. Scharenborg, and Z. Yue, “Objective and Subjective Evaluation of Diffusion-Based Speech Enhancement for Dysarthric Speech,” inProc. Interspeech, 2025, pp. 2740–2744
work page 2025
-
[35]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeaveyet al., “Robust speech recognition via large-scale weak supervision,” inProc. of the International Conference on Machine Learning (ICML), 2022
work page 2022
-
[36]
SUPERB: Speech processing universal performance benchmark,
S.-W. Yang, P.-H. Chi, Y .-S. Chuang, C.-I. Lai, K. Lakho- tiaet al., “SUPERB: Speech processing universal performance benchmark,” inProc. Interspeech, 2021
work page 2021
-
[37]
EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark,
Z. Ma, M. Chen, H. Zhang, Z. Zheng, W. Chenet al., “EmoBox: Multilingual Multi-corpus Speech Emotion Recognition Toolkit and Benchmark,” inProc. Interspeech, 2024, pp. 1580–1584
work page 2024
-
[38]
Rank-N-Contrast: Learning continuous representations for regression,
K. Zha, P. Cao, J. Son, Y . Yang, and D. Katabi, “Rank-N-Contrast: Learning continuous representations for regression,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[39]
J. Fan and D. S. Williamson, “JSQA: Speech quality assessment with perceptually-inspired contrastive pretraining based on jnd audio pairs,” inProc. of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2025, pp. 1–5
work page 2025
-
[40]
Dysarthric speech recognition us- ing dysarthria-severity-dependent and speaker-adaptive models,
M. Kim, J. Yoo, and H. Kim, “Dysarthric speech recognition us- ing dysarthria-severity-dependent and speaker-adaptive models,” inProc. Interspeech, 2013
work page 2013
-
[41]
Accurate synthesis of dysarthric speech for asr data augmenta- tion,
M. Soleymanpour, M. T. Johnson, R. Soleymanpour, and J. Berry, “Accurate synthesis of dysarthric speech for asr data augmenta- tion,”Speech Commun., vol. 164, no. C, 2024
work page 2024
-
[42]
M. Merler, C. Agurto, J. Peller, E. Roitberg, A. Taitzet al., “Clin- ical assessment and interpretation of dysarthria in ALS using at- tention based deep learning AI models,”NPJ Digital Medicine, vol. 8, 2025
work page 2025
-
[43]
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: emphasized channel attention, propagation and aggrega- tion in TDNN based speaker verification,” inProc. Interspeech, 2020, pp. 3830–3834
work page 2020
-
[44]
Understanding the behaviour of contrastive loss,
F. Wang and H. Liu, “Understanding the behaviour of contrastive loss,” inProc. of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 2495–2504
work page 2020
-
[45]
VICReg: Variance- invariance-covariance regularization for self-supervised learning,
A. Bardes, J. Ponce, and Y . LeCun, “VICReg: Variance- invariance-covariance regularization for self-supervised learning,” inProc. of the International Conference on Learning Representa- tions (ICLR), 2022
work page 2022
-
[46]
S. Team, “Silero V AD: pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,” https:// github.com/snakers4/silero-vad, 2024
work page 2024
-
[47]
Improved Intelli- gibility of Dysarthric Speech using Conditional Flow Matching,
S. Das, N. Singh, A. Gangwar, and S. Umesh, “Improved Intelli- gibility of Dysarthric Speech using Conditional Flow Matching,” inProc. Interspeech, 2025, pp. 2118–2122
work page 2025
-
[48]
Decoupled weight decay regulariza- tion,
I. Loshchilov and F. Hutter, “Decoupled weight decay regulariza- tion,” inProc. of the International Conference on Learning Rep- resentations (ICLR), 2017
work page 2017
-
[49]
Visualizing data using t- sne,
L. van der Maaten and G. E. Hinton, “Visualizing data using t- sne,”Journal of Machine Learning Research, vol. 9, pp. 2579– 2605, 2008
work page 2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.