Recognition: unknown
Do BERT Embeddings Encode Narrative Dimensions? A Token-Level Probing Analysis of Time, Space, Causality, and Character in Fiction
Pith reviewed 2026-05-10 15:22 UTC · model grok-4.3
The pith
BERT embeddings encode extractable information on time, space, causality, and character in fiction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
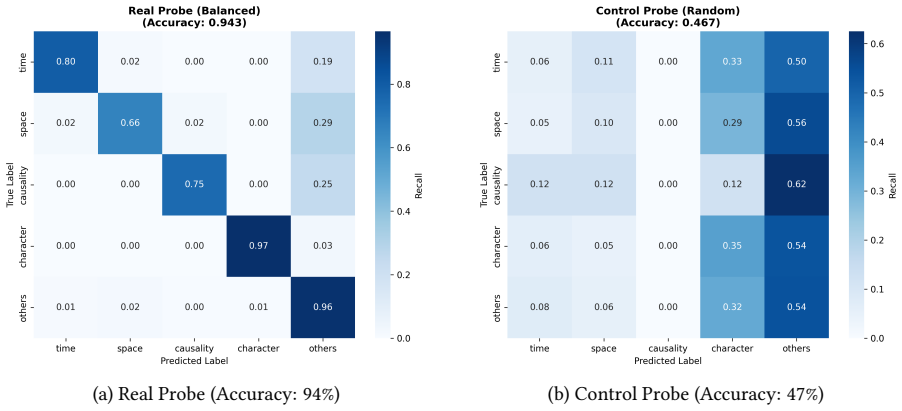
BERT embeddings encode meaningful narrative information about time, space, causality, and character, shown by a linear probe reaching 94 percent accuracy on token-level classification of these dimensions, far above the 47 percent baseline on variance-matched random embeddings, with a macro-average recall of 0.83 under balanced weighting though unsupervised clustering aligns only near-randomly.
What carries the argument
Linear probe classifier applied to BERT token embeddings for predicting narrative dimension labels at the word level.
If this is right
- BERT embeddings contain extractable signals for narrative dimensions that enable token-level classification at high accuracy.
- Narrative categories exhibit boundary leakage, with rare dimensions such as causality and space frequently misclassified into the others category.
- Unsupervised clustering of the embeddings recovers the predefined narrative categories only at near-random levels with an ARI of 0.081.
- Balanced class weighting allows the probe to achieve a macro-average recall of 0.83 across all narrative dimensions.
Where Pith is reading between the lines
- Pretraining on large text collections may allow models to acquire implicit representations of storytelling mechanics without explicit supervision.
- Narrative encoding could be partially entangled with syntactic patterns, which would require separate controls such as part-of-speech baselines to isolate.
- Layer-wise probing on the same data could reveal at which depths these narrative features become most accessible.
Load-bearing premise
The token labels produced with LLM assistance accurately capture the narrative dimensions without systematic bias or annotation errors.
What would settle it
If a linear probe trained on the same BERT embeddings but using manually verified labels instead of LLM-generated ones drops to near 50 percent accuracy, the claim that the embeddings encode these narrative dimensions would fail.
Figures



read the original abstract
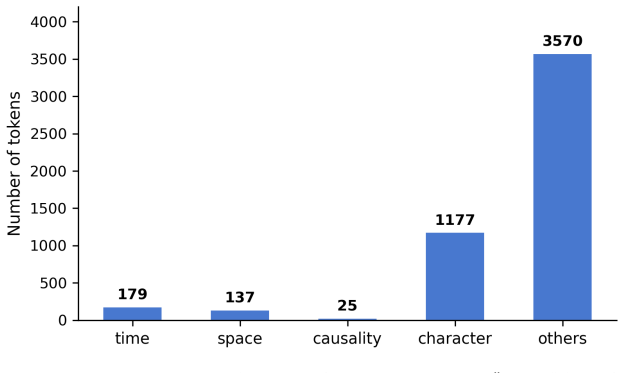
Narrative understanding requires multidimensional semantic structures. This study investigates whether BERT embeddings encode dimensions of fictional narrative semantics -- time, space, causality, and character. Using an LLM to accelerate annotation, we construct a token-level dataset labeled with these four narrative categories plus "others." A linear probe on BERT embeddings (94% accuracy) significantly outperforms a control probe on variance-matched random embeddings (47%), confirming that BERT encodes meaningful narrative information. With balanced class weighting, the probe achieves a macro-average recall of 0.83, with moderate success on rare categories such as causality (recall = 0.75) and space (recall = 0.66). However, confusion matrix analysis reveals "Boundary Leakage," where rare dimensions are systematically misclassified as "others." Clustering analysis shows that unsupervised clustering aligns near-randomly with predefined categories (ARI = 0.081), suggesting that narrative dimensions are encoded but not as discretely separable clusters. Future work includes a POS-only baseline to disentangle syntactic patterns from narrative encoding, expanded datasets, and layer-wise probing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that BERT embeddings encode narrative dimensions (time, space, causality, character) in fiction. It uses LLM-assisted annotation to create a token-level dataset with five classes (including 'others'), trains a linear probe achieving 94% accuracy (vs. 47% on variance-matched random embeddings), and reports macro-average recall of 0.83 under balanced class weighting. Clustering yields low alignment with the labels (ARI=0.081), which the authors interpret as evidence of encoding without discrete separability. They note boundary leakage into the 'other' class and outline future work including a POS baseline.
Significance. If the central result holds after validation of the labels, the work would demonstrate that pre-trained contextual embeddings capture multidimensional narrative semantics beyond generic statistics, with the variance-matched random control providing a useful baseline to isolate learned representations. This could inform downstream tasks in story understanding and generation. The empirical probe-vs-control design is a clear strength, though the low clustering ARI and planned but absent POS baseline limit immediate claims about narrative-specific encoding independent of syntax.
major comments (2)
- [Abstract] Abstract: the 94% probe accuracy and claim of 'meaningful narrative information' depend on the LLM-generated token labels being a faithful proxy for the narrative dimensions. No dataset size, inter-annotator agreement, human validation, or error analysis of the automated annotations is reported, leaving open the possibility that the linear probe recovers the LLM annotator's systematic biases or decision boundaries (including the noted 'Boundary Leakage' into 'others') rather than intrinsic properties of BERT embeddings. The random-embedding control rules out generic variance but does not address label noise.
- [Clustering analysis] Clustering analysis: the reported ARI of 0.081 (near-random) is presented as showing that dimensions are 'encoded but not as discretely separable clusters.' This interpretation is reasonable but weakens the broader significance of the encoding claim, as it suggests the information may be distributed in ways that do not support the narrative categories as coherent, recoverable structures without supervision.
minor comments (2)
- [Abstract] The abstract omits the total number of tokens or documents in the dataset and the specific LLM/prompting details used for annotation, which are needed to assess the scale and reproducibility of the results.
- A table reporting per-class support (number of tokens) alongside the recall figures would help contextualize performance on rare categories such as causality (recall 0.75) and space (recall 0.66).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comments point by point below, acknowledging limitations where they exist and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 94% probe accuracy and claim of 'meaningful narrative information' depend on the LLM-generated token labels being a faithful proxy for the narrative dimensions. No dataset size, inter-annotator agreement, human validation, or error analysis of the automated annotations is reported, leaving open the possibility that the linear probe recovers the LLM annotator's systematic biases or decision boundaries (including the noted 'Boundary Leakage' into 'others') rather than intrinsic properties of BERT embeddings. The random-embedding control rules out generic variance but does not address label noise.
Authors: We agree that the validity of the LLM-generated labels is foundational to interpreting the probe results and that the manuscript currently lacks key details on the annotation process. The paper does not report dataset size, inter-annotator agreement, human validation, or a dedicated error analysis, which leaves open the possibility of recovering annotator-specific patterns. We will revise the Methods and Results sections to report the exact dataset size and class distribution, describe the LLM prompting procedure in full, and include an error analysis focused on boundary leakage cases. We will also add a small human validation study on a held-out subset and report agreement statistics. While the variance-matched random embedding baseline rules out generic variance effects, we acknowledge it does not address label noise and will explicitly discuss this limitation along with its implications for the claims. revision: partial
-
Referee: [Clustering analysis] Clustering analysis: the reported ARI of 0.081 (near-random) is presented as showing that dimensions are 'encoded but not as discretely separable clusters.' This interpretation is reasonable but weakens the broader significance of the encoding claim, as it suggests the information may be distributed in ways that do not support the narrative categories as coherent, recoverable structures without supervision.
Authors: We agree that an ARI of 0.081 indicates near-random alignment and that this finding limits claims about the narrative categories forming coherent, unsupervised structures. Our manuscript already presents this result as evidence that the dimensions are encoded in a distributed rather than discretely clustered manner. This does not contradict the probe results but qualifies the nature of the encoding. We will expand the discussion section to elaborate on this distinction, compare it to other distributed semantic features in embeddings, and clarify the implications for downstream narrative tasks that may require supervision. revision: no
Circularity Check
No significant circularity; results are measured empirical outcomes
full rationale
The paper constructs a token-level dataset via LLM-assisted annotation for narrative categories and then trains a linear probe on BERT embeddings to predict those fixed labels, reporting 94% accuracy against a 47% variance-matched random embedding baseline. This performance gap is an observed measurement on held-out data rather than a quantity derived by construction from the inputs. No equations reduce the probe accuracy to the annotation process itself, no self-citations form a load-bearing chain, and the random control is an independent statistical benchmark. The analysis remains self-contained against external controls without self-definitional loops or fitted inputs renamed as predictions.
Axiom & Free-Parameter Ledger
free parameters (1)
- balanced class weights
axioms (2)
- domain assumption Linear probes can extract semantic information encoded in pre-trained embeddings
- ad hoc to paper LLM-generated token labels accurately represent narrative dimensions
Reference graph
Works this paper leans on
-
[1]
Belinkov, Probing classifiers: Promises, shortcomings, and advances, Computational Linguistics 48 (2022) 207–219
Y. Belinkov, Probing classifiers: Promises, shortcomings, and advances, Computational Linguistics 48 (2022) 207–219
2022
-
[2]
Devlin, M.-W
J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, Bert: Pre-training of deep bidirectional transformers for language understanding, in: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), 2019, pp. 4171–4186
2019
-
[3]
I. Tenney, D. Das, E. Pavlick, What do you learn from context? probing for sentence structure in contextualized word representations, arXiv preprint arXiv:1905.06316 (2019). URL: https: //arxiv.org/abs/1905.06316
work page Pith review arXiv 1905
-
[4]
Piper, R
A. Piper, R. J. So, D. Bamman, Narrative theory for computational narrative understanding, in: Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 2021, pp. 298–311
2021
-
[5]
Genette, Narrative Discourse: An Essay in Method, volume 3, Cornell University Press, 1983
G. Genette, Narrative Discourse: An Essay in Method, volume 3, Cornell University Press, 1983
1983
-
[6]
P. Törnberg, Best practices for text annotation with large language models, arXiv preprint arXiv:2402.05129 (2024). URL: https://doi.org/10.48550/arXiv.2402.05129
-
[7]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al., Openai gpt-5 system card, arXiv preprint arXiv:2601.03267 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
M. E. Peters, M. Neumann, M. Iyyer, M. Gardner, C. Clark, K. Lee, L. Zettlemoyer, Deep con- textualized word representations, in: M. Walker, H. Ji, A. Stent (Eds.), Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), Association for Computat...
-
[9]
Hewitt, P
J. Hewitt, P. Liang, Designing and interpreting probes with control tasks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, 2019, pp. 2733–2743
2019
-
[10]
Austen, Pride and prejudice, Project Gutenberg EBook No
J. Austen, Pride and prejudice, Project Gutenberg EBook No. 1342, HTML edition, 1813. URL: https://www.gutenberg.org/files/1342/1342-h/1342-h.htm, accessed: 10 Dec 2025
2025
-
[11]
Y. Zhu, R. Kiros, R. Zemel, R. Salakhutdinov, R. Urtasun, A. Torralba, S. Fidler, Aligning books and movies: Towards story-like visual explanations by watching movies and reading books, in: Proceedings of the IEEE International Conference on Computer Vision, 2015, pp. 19–27
2015
-
[12]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, E. Duchesnay, Scikit-learn: Machine learning in Python, Journal of Machine Learning Research 12 (2011) 2825– 2830
2011
-
[13]
D. C. Liu, J. Nocedal, On the limited memory BFGS method for large scale optimization, Mathe- matical Programming 45 (1989) 503–528
1989
-
[14]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, J. Melville, UMAP: Uniform manifold approximation and projection for dimension reduction, arXiv preprint arXiv:1802.03426 (2018)
work page internal anchor Pith review arXiv 2018
-
[15]
K. Ethayarajh, How contextual are contextualized word representations? comparing the geometry of BERT, ELMo, and GPT-2 embeddings, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Ho...
-
[16]
Jawahar, B
G. Jawahar, B. Sagot, D. Sautier, What does BERT learn about the structure of language?, in: Pro- ceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Florence, Italy, 2019, pp. 3651–3657
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.