Compliant But Unsatisfactory: The Gap Between Auditing Standards and Practices for Probabilistic Genotyping Software
Pith reviewed 2026-05-10 16:33 UTC · model grok-4.3
The pith
Audit standards for probabilistic genotyping software permit compliant audits that do not set use restrictions based on failures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ASB 018 envisions that compliant audits of probabilistic genotyping software will establish restrictions on its use based on observed failures, yet the standard's requirements allow audits to comply without creating such boundaries. This occurs because of design elements such as imprecise wording and terms left undefined, which the authors identify through qualitative review of the standard text and five real audit reports. The result is that audits can satisfy the rules while failing to deliver the restrictions the standard aims to produce.
What carries the argument
ASB 018 and its specific requirements, whose vague language and undefined terms allow audits to meet compliance criteria without imposing use restrictions after failures are seen.
If this is right
- Audits can satisfy ASB 018 while leaving software that has shown problems available for use in additional criminal cases.
- Clear definitions and outcome specifications in standards would be needed to force audits to produce the restrictions ASB 018 intends.
- Current compliant audits of probabilistic genotyping software may not provide the safeguards the standard was written to create.
- Audit standards in other domains could contain similar design features that separate compliance from effectiveness.
Where Pith is reading between the lines
- If the pattern holds, probabilistic genotyping software with documented errors could remain in use across more jurisdictions than intended.
- The same design issues might appear in standards for other AI tools used in high-stakes decisions, allowing superficial compliance.
- One way to test the claim would be to give auditors sample failure data and observe whether their reports include use restrictions while still meeting ASB 018 rules.
Load-bearing premise
The gaps between the standard's goals and the audits examined are caused mainly by the wording and structure of ASB 018 rather than by auditor choices or outside pressures.
What would settle it
Locate an audit report for probabilistic genotyping software that complies with ASB 018 yet explicitly sets new restrictions on software use after documenting specific failures.
Figures
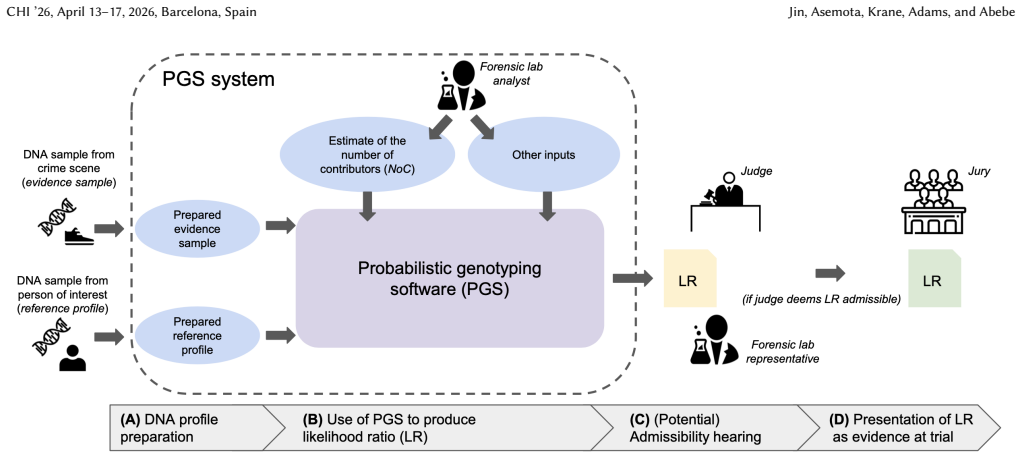

read the original abstract
AI governance efforts increasingly rely on audit standards: agreed-upon practices for conducting audits. However, poorly designed standards can hide and lend credibility to inadequate systems. We explore how an audit standard's design influences its effectiveness through a case study of ASB 018, a standard for auditing probabilistic genotyping software -- software that the U.S. criminal legal system increasingly uses to analyze DNA samples. Through qualitative analysis of ASB 018 and five audit reports, we identify numerous gaps between the standard's desired outcomes and the auditing practices it enables. For instance, ASB 018 envisions that compliant audits establish restrictions on software use based on observed failures. However, audits can comply without establishing such boundaries. We connect these gaps to the design of the standard's requirements such as vague language and undefined terms. We conclude with recommendations for designing audit standards and evaluating their effectiveness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the ASB 018 audit standard for probabilistic genotyping software permits compliant audits that fail to achieve the standard's intended outcomes, such as establishing restrictions on software use based on observed failures. Through qualitative analysis of the standard text and five audit reports, the authors identify multiple gaps and attribute them primarily to design features including vague language and undefined terms, concluding with recommendations for improved audit standard design.
Significance. If the gaps are substantiated, the work contributes to AI governance literature by demonstrating how audit standards can lend credibility to inadequate systems without enforcing meaningful constraints. The concrete mapping of standard provisions to audit report practices provides actionable insights for forensic DNA analysis and broader high-stakes AI auditing; the qualitative approach is a strength when paired with transparent methods.
major comments (2)
- [Methods] Methods section: The qualitative analysis of ASB 018 and the five audit reports lacks explicit details on report selection criteria, coding scheme, and inter-rater reliability measures. This is load-bearing for the central claim because the identification of 'numerous gaps' and their linkage to standard design rests on the reproducibility and robustness of the document analysis.
- [Discussion] Discussion section: The attribution of observed gaps (e.g., compliant audits not establishing use restrictions) primarily to ASB 018 design features such as vague language is not isolated from alternative drivers including auditor discretion, resource limits, or criminal-justice system incentives. Without counterfactual analysis, interviews, or explicit checks for these factors, the causal claim remains descriptive rather than demonstrated.
minor comments (1)
- [Abstract] Abstract: The summary of the qualitative analysis could briefly note the number of reports examined and the main analytical approach to better orient readers to the evidence base.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which have helped us strengthen the transparency and framing of our qualitative analysis. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Methods] Methods section: The qualitative analysis of ASB 018 and the five audit reports lacks explicit details on report selection criteria, coding scheme, and inter-rater reliability measures. This is load-bearing for the central claim because the identification of 'numerous gaps' and their linkage to standard design rests on the reproducibility and robustness of the document analysis.
Authors: We agree that greater methodological transparency is needed to support the reproducibility of our findings. In the revised manuscript, we have expanded the Methods section with: (1) explicit selection criteria for the five audit reports (publicly available reports from ASB-accredited laboratories using probabilistic genotyping software, selected to cover multiple software vendors and jurisdictions); (2) a description of the coding scheme, which combined deductive codes drawn directly from ASB 018 requirements with inductive codes for observed practices and gaps; and (3) clarification that the analysis was performed by a single researcher with iterative self-review, and that a full codebook with coded excerpts has been added to the appendix to enable external assessment. These additions directly address the concern while remaining consistent with the qualitative, document-based nature of the study. revision: yes
-
Referee: [Discussion] Discussion section: The attribution of observed gaps (e.g., compliant audits not establishing use restrictions) primarily to ASB 018 design features such as vague language is not isolated from alternative drivers including auditor discretion, resource limits, or criminal-justice system incentives. Without counterfactual analysis, interviews, or explicit checks for these factors, the causal claim remains descriptive rather than demonstrated.
Authors: We appreciate the distinction drawn between descriptive mapping and causal isolation. Our analysis is descriptive: it provides concrete, provision-by-provision mappings between ASB 018 language and the practices documented in the audit reports to show how the standard's design features (vague terms, lack of specificity) permit compliant audits that do not achieve intended outcomes. We do not claim to have isolated design features as the sole or primary cause or ruled out other drivers such as auditor discretion or resource constraints. To address this, we have revised the Discussion to explicitly characterize the contribution as descriptive and added a Limitations subsection that acknowledges these alternative factors and notes that establishing stronger causal claims would require complementary methods (e.g., auditor interviews) beyond the scope of this document analysis. revision: partial
Circularity Check
No circularity: qualitative document analysis with external grounding
full rationale
The paper conducts a qualitative analysis of the ASB 018 standard text and five external audit reports to identify gaps between envisioned outcomes (e.g., establishing use restrictions based on failures) and enabled practices. It attributes gaps to design features such as vague language and undefined terms through direct interpretive comparison, without any derivations, equations, fitted parameters, predictions, or self-citations that reduce claims to their own inputs by construction. All conclusions rest on external source material and standard interpretive reasoning rather than self-referential loops, satisfying the criteria for a self-contained non-circular analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Qualitative analysis of a standard and a small set of audit reports can identify systematic gaps attributable to the standard's wording.
Reference graph
Works this paper leans on
-
[1]
2015.Guidelines for the Validation of Probabilistic Genotyping Systems. Guidelines. Scientific Working Group on DNA Analysis Methods (SWGDAM). https://www. swgdam.org/_files/ugd/4344b0_22776006b67c4a32a5ffc04fe3b56515.pdf
work page 2015
-
[2]
In- ternal Validation Study Summary
2018.Internal Validation of STRmix V2.4 for Fusion NYC OCME. In- ternal Validation Study Summary. NYC Office of the Medical Examiner (OCME). https://www.nyc.gov/assets/ocme/downloads/pdf/STRmix-V2-4- Fusion-5C-Validation%20Summary.pdf
work page 2018
-
[3]
Internal Validation Study Summary
2018.Internal Validation of STRmix V2.5 for the Colorado Bureau of In- vestigation (CBI) Forensic Laboratories (GlobalFiler, 3500xL CE). Internal Validation Study Summary. Colorado Bureau of Investigation (OCME). https://www.ascld.org/wp-content/uploads/formidable/43/2018-STRmix- Validation_FINAL-38656-1-Rev.pdf
work page 2018
-
[4]
Internal Validation Study Summary
2019.Palm Beach County Sheriff’s Office Internal Validation of STRmix V2.6.2 (Powerplex Fusion6C, 3500xICE). Internal Validation Study Summary. Palm Beach County Sheriff’s Office (PBSO). https://www.ascld.org/wp- content/uploads/formidable/43/PBSO-STRmix-v2.6.2-Internal-Validation- Powerplex-Fusion-6C-3500xl-CE.pdf
work page 2019
- [5]
-
[6]
Internal Validation Study Summary
2021.Internal Validation of STRmix v2.7 for Fusion 5C/3500xL Data. Internal Validation Study Summary. NYC Office of the Medical Examiner (OCME). https:// www.nyc.gov/assets/ocme/downloads/pdf/internal_validation_strmix_2_7.pdf
work page 2021
-
[7]
2023.Guideline for Internal Validation / Verification of Various Aspects of the DNA Profiling Process. Guidelines. The European Network of Forensic Science Insti- tutes (ENFSI). https://enfsi.eu/wp-content/uploads/2024/02/ENFSI-Validation- Guideline-04012024.pdf
work page 2023
-
[8]
Internal Validation Study Summary
2024.Maryland State Police Forensic Sciences Division Internal Validation of STRmix V2.9.1). Internal Validation Study Summary. Maryland State Police (MSP). https://www.ascld.org/wp-content/uploads/formidable/43/FSD-Biology- STRmix-V2.9.1-Internal-Validation-Summary.pdf
work page 2024
-
[9]
2024.Software Validation for DNA Mixture Interpretation. Guidelines. UK Forensic Science Regulator. https://assets.publishing.service.gov.uk/media/ 5f607bbc8fa8f5106b23aa3a/G223_Mix_software_valid_Issue2_accessV3.pdf
work page 2024
-
[10]
2025.Quality Assurance Standards for Forensic DNA Testing Laboratories. Guide- lines. Federal Bureau of Investigation (FBI). https://www.swgdam.org/_files/ ugd/4344b0_c2c9d0c7652f4977a57649ce500466aa.pdf
work page 2025
-
[11]
Rediet Abebe, Moritz Hardt, Angela Jin, John Miller, Ludwig Schmidt, and Rebecca Wexler. 2022. Adversarial scrutiny of evidentiary statistical software. InProceed- ings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. 1733–1746
work page 2022
-
[12]
Nov 4, 2025.Celebrating Ten Years of the AAFS Standards Board
Teresa Ambrosius. Nov 4, 2025.Celebrating Ten Years of the AAFS Standards Board. https://www.aafs.org/article/celebrating-ten-years-aafs-standards-board
work page 2025
-
[13]
American National Standards Institute (ANSI). [n. d.].American National Stan- dards (ANS) Introduction. https://www.ansi.org/american-national-standards/ ans-introduction/overview#introduction
-
[14]
2020.Standard for Validation of Probabilistic Genotyping Systems
ANSI/ASB Standard 018, 1st Ed. 2020.Standard for Validation of Probabilistic Genotyping Systems. Standard. AAFS Standards Board, Colorado Springs, CO. https://www.aafs.org/sites/default/files/media/documents/018_Std_e1.pdf
work page 2020
-
[15]
Legal Information Institute at Cornell University. 2023. Daubert Standard. https: //www.law.cornell.edu/wex/daubert_standard
work page 2023
-
[16]
Glen Berman, Nitesh Goyal, and Michael Madaio. 2024. A Scoping Study of Evaluation Practices for Responsible AI Tools: Steps Towards Effectiveness Evalu- ations. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–24
work page 2024
-
[17]
Hugh Beyer and Karen Holtzblatt. 1999. Contextual design.interactions6, 1 (1999), 32–42. CHI ’26, April 13–17, 2026, Barcelona, Spain Jin, Asemota, Krane, Adams, and Abebe
work page 1999
-
[18]
Abeba Birhane, Ryan Steed, Victor Ojewale, Briana Vecchione, and Inioluwa Deb- orah Raji. 2024. AI auditing: The broken bus on the road to AI accountability. In2024 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 612–643
work page 2024
-
[19]
Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accu- racy disparities in commercial gender classification. InConference on fairness, accountability and transparency. PMLR, 77–91
work page 2018
-
[20]
John Butler. 2024. History of DNA Mixture Interpretation: Supplemental Doc- ument to DNA Mixture Interpretation: A NIST Scientific Foundation Review. (2024)
work page 2024
-
[21]
John Butler, Hariharan Iyer, Richard Press, Melissa Taylor, Peter Vallone, and Sheila Willis. 2024. DNA Mixture Interpretation: A NIST Scientific Foundation Review. https://doi.org/10.6028/NIST.IR.8351
-
[22]
Marc Canellas. 2021. Defending IEEE software standards in federal criminal court.Computer54, 6 (2021), 14–23
work page 2021
-
[23]
Alexandra Chouldechova, Diana Benavides-Prado, Oleksandr Fialko, and Rhema Vaithianathan. 2018. A case study of algorithm-assisted decision making in child maltreatment hotline screening decisions. InConference on fairness, accountability and transparency. PMLR, 134–148
work page 2018
-
[24]
Michael D Coble and Jo-Anne Bright. 2019. Probabilistic genotyping software: an overview.Forensic Science International: Genetics38 (2019), 219–224
work page 2019
-
[25]
Michael D Coble, Jo-Anne Bright, John S Buckleton, and James M Curran. 2015. Uncertainty in the number of contributors in the proposed new CODIS set. Forensic Science International: Genetics19 (2015), 207–211
work page 2015
-
[26]
Michael D Coble, John Buckleton, John M Butler, T Egeland, R Fimmers, P Gill, L Gusmão, B Guttman, Michael Krawczak, N Morling, et al. 2016. DNA Commission of the International Society for Forensic Genetics: Recommendations on the validation of software programs performing biostatistical calculations for forensic genetics applications.Forensic Science Int...
work page 2016
-
[27]
Commonwealth v. Foley, 38 A.3d 882, 888–90. (Pa. Super. Ct. 2012)
work page 2012
-
[28]
Sasha Costanza-Chock, Inioluwa Deborah Raji, and Joy Buolamwini. 2022. Who Audits the Auditors? Recommendations from a field scan of the algorithmic auditing ecosystem. InProceedings of the 2022 ACM Conference on Fairness, Ac- countability, and Transparency. 1571–1583
work page 2022
-
[29]
2009.Strengthening forensic science in the United States: a path forward
National Research Council, Division on Engineering, Physical Sciences, Commit- tee on Applied, Theoretical Statistics, Global Affairs, Committee on Science, Law, and Committee on Identifying the Needs of the Forensic Sciences Community. 2009.Strengthening forensic science in the United States: a path forward. National Academies Press
work page 2009
-
[30]
Wesley Hanwen Deng, Manish Nagireddy, Michelle Seng Ah Lee, Jatinder Singh, Zhiwei Steven Wu, Kenneth Holstein, and Haiyi Zhu. 2022. Exploring how machine learning practitioners (try to) use fairness toolkits. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency. 473–484
work page 2022
-
[31]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iii, and Kate Crawford. 2021. Datasheets for datasets. Commun. ACM64, 12 (2021), 86–92
work page 2021
-
[32]
Geiger, Udayan Tandon, Anoolia Gakhokidze, Lian Song, and Lilly Irani
Stuart R. Geiger, Udayan Tandon, Anoolia Gakhokidze, Lian Song, and Lilly Irani
-
[33]
https://ijoc.org/index.php/ijoc/article/download/20811/4455
Making Algorithms Public: Reimagining Auditing From Matters of Fact to Matters of Concern.International Journal of Communication18 (2024), 634–655. https://ijoc.org/index.php/ijoc/article/download/20811/4455
work page 2024
-
[34]
Marissa Kumar Gerchick, Ro Encarnación, Cole Tanigawa-Lau, Lena Armstrong, Ana Gutiérrez, and Danaé Metaxa. 2025. Auditing the Audits: Lessons for Algo- rithmic Accountability from Local Law 144’s Bias Audits. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. 29–44
work page 2025
-
[35]
Ellen P Goodman and Julia Trehu. 2022. Algorithmic Auditing: Chasing AI Accountability.Santa Clara High Tech. LJ39 (2022), 289
work page 2022
-
[36]
Lara Groves, Jacob Metcalf, Alayna Kennedy, Briana Vecchione, and Andrew Strait. 2024. Auditing work: Exploring the New York City algorithmic bias audit regime. InThe 2024 ACM Conference on Fairness, Accountability, and Transparency. 1107–1120
work page 2024
-
[37]
Kenneth Holstein, Jennifer Wortman Vaughan, Hal Daumé III, Miro Dudik, and Hanna Wallach. 2019. Improving fairness in machine learning systems: What do industry practitioners need?. InProceedings of the 2019 CHI conference on human factors in computing systems. 1–16
work page 2019
-
[38]
Chris Jay Hoofnagle. 2016. Assessing the Federal Trade Commission’s Privacy Assessments.IEEE Security & Privacy14, 2 (2016), 58–64
work page 2016
-
[39]
2024.About the AI Standards Hub
AI Standards Hub. 2024.About the AI Standards Hub. https://aistandardshub. org/the-ai-standards-hub/
work page 2024
-
[40]
Steven J Jackson and Sarah Barbrow. 2015. Standards and/as innovation: Protocols, creativity, and interactive systems development in ecology. InProceedings of the 33rd annual ACM conference on human factors in computing systems. 1769–1778
work page 2015
-
[41]
Angela Jin and Niloufar Salehi. 2024. (Beyond) Reasonable Doubt: Challenges that Public Defenders Face in Scrutinizing AI in Court. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–19
work page 2024
-
[42]
Hannah Kelly, Michael Coble, Maarten Kruijver, Richard Wivell, and Jo-Anne Bright. 2022. Exploring likelihood ratios assigned for siblings of the true mixture contributor as an alternate contributor.Journal of forensic sciences67, 3 (2022), 1167–1175
work page 2022
-
[43]
Dan E Krane and M Katherine Philpott. 2022. Using Laboratory Validation to Identify and Establish Limits to the Reliability of Probabilistic Genotyping Systems. InHandbook of DNA Profiling. Springer, 297–319
work page 2022
-
[44]
Khoa Lam, Benjamin Lange, Borhane Blili-Hamelin, Jovana Davidovic, Shea Brown, and Ali Hasan. 2024. A framework for assurance audits of algorithmic systems. InThe 2024 ACM Conference on Fairness, Accountability, and Trans- parency. 1078–1092
work page 2024
-
[45]
Michelle S Lam, Ayush Pandit, Colin H Kalicki, Rachit Gupta, Poonam Sahoo, and Danaë Metaxa. 2023. Sociotechnical Audits: Broadening the Algorithm Auditing Lens to Investigate Targeted Advertising.Proceedings of the ACM on Human-Computer Interaction7, CSCW2 (2023), 1–37
work page 2023
-
[46]
Mark Latonero and Aaina Agarwal. 2021. Human rights impact assessments for AI: learning from Facebook’s failure in Myanmar.Carr Center for Human Rights Policy Harvard Kennedy School, Harvard University(2021)
work page 2021
-
[47]
Christie Lawrence, Isaac Cui, and Daniel Ho. 2023. The bureaucratic challenge to AI governance: An empirical assessment of implementation at US federal agencies. InProceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society. 606–652
work page 2023
-
[48]
Michelle Seng Ah Lee and Jat Singh. 2021. The landscape and gaps in open source fairness toolkits. InProceedings of the 2021 CHI conference on human factors in computing systems. 1–13
work page 2021
-
[49]
Michael A Madaio, Luke Stark, Jennifer Wortman Vaughan, and Hanna Wallach
-
[50]
InProceedings of the 2020 CHI conference on human factors in computing systems
Co-designing checklists to understand organizational challenges and opportunities around fairness in AI. InProceedings of the 2020 CHI conference on human factors in computing systems. 1–14
work page 2020
-
[51]
Jeanna Matthews, Marzieh Babaeianjelodar, Stephen Lorenz, Abigail Matthews, Mariama Njie, Nathaniel Adams, Dan Krane, Jessica Goldthwaite, and Clinton Hughes. 2019. The right to confront your accusers: Opening the black box of forensic DNA software. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society. 321–327
work page 2019
-
[52]
Jeanna Neefe Matthews, Graham Northup, Isabella Grasso, Stephen Lorenz, Marzieh Babaeianjelodar, Hunter Bashaw, Sumona Mondal, Abigail Matthews, Mariama Njie, and Jessica Goldthwaite. 2020. When trusted black boxes don’t agree: Incentivizing iterative improvement and accountability in critical software systems. InProceedings of the AAAI/ACM Conference on ...
work page 2020
-
[53]
Jacob Metcalf, Emanuel Moss, Elizabeth Anne Watkins, Ranjit Singh, and Madeleine Clare Elish. 2021. Algorithmic impact assessments and accountability: The co-construction of impacts. InProceedings of the 2021 ACM conference on fairness, accountability, and transparency. 735–746
work page 2021
-
[54]
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model cards for model reporting. InProceedings of the conference on fairness, accountability, and transparency. 220–229
work page 2019
-
[55]
Geoffrey Stewart Morrison, Cedric Neumann, and Patrick Henry Geoghegan
-
[56]
Vacuous standards–subversion of the OSAC standards-development pro- cess. , 206–209 pages
-
[57]
Katherine L Moss. 2015. The admissibility of TrueAllele: A computerized DNA interpretation system.Wash. & Lee L. Rev.72 (2015), 1033
work page 2015
-
[58]
Deirdre K Mulligan, Colin Koopman, and Nick Doty. 2016. Privacy is an es- sentially contested concept: a multi-dimensional analytic for mapping privacy. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences374, 2083 (2016), 20160118
work page 2016
-
[59]
Deirdre K Mulligan, Joshua A Kroll, Nitin Kohli, and Richmond Y Wong. 2019. This thing called fairness: Disciplinary confusion realizing a value in technology. Proceedings of the ACM on Human-Computer Interaction3, CSCW (2019), 1–36
work page 2019
-
[60]
Ziad Obermeyer, Brian Powers, Christine Vogeli, and Sendhil Mullainathan. 2019. Dissecting racial bias in an algorithm used to manage the health of populations. Science366, 6464 (2019), 447–453
work page 2019
-
[61]
American Academy of Forensic Sciences (AAFS). [n. d.].About ASB. https: //www.aafs.org/academy-standards-board/about-asb
-
[62]
Victor Ojewale, Ryan Steed, Briana Vecchione, Abeba Birhane, and Inioluwa Debo- rah Raji. 2025. Towards AI Accountability Infrastructure: Gaps and Opportunities in AI Audit Tooling(CHI ’25). Association for Computing Machinery, New York, NY, USA, Article 815, 29 pages. https://doi.org/10.1145/3706598.3713301
-
[63]
David R Paoletti, Travis E Doom, Carissa M Krane, Michael L Raymer, and Dan E Krane. 2005. Empirical analysis of the STR profiles resulting from conceptual mixtures.Journal of forensic sciences50, 6 (2005), JFS2004475–6
work page 2005
-
[64]
Evani Radiya-Dixit and Gina Neff. 2023. A Sociotechnical Audit: Assessing Police Use of Facial rRecognition. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency. 1334–1346
work page 2023
-
[65]
Inioluwa Deborah Raji, Andrew Smart, Rebecca N White, Margaret Mitchell, Timnit Gebru, Ben Hutchinson, Jamila Smith-Loud, Daniel Theron, and Parker Barnes. 2020. Closing the AI accountability gap: Defining an end-to-end frame- work for internal algorithmic auditing. InProceedings of the 2020 conference on fairness, accountability, and transparency. 33–44
work page 2020
-
[66]
Inioluwa Deborah Raji, Peggy Xu, Colleen Honigsberg, and Daniel Ho. 2022. Outsider oversight: Designing a third party audit ecosystem for ai governance. In Compliant But Unsatisfactory: The Gap Between Auditing Standards and Practices for Probabilistic Genotyping Software CHI ’26, April 13–17, 2026, Barcelona, Spain Proceedings of the 2022 AAAI/ACM Confer...
work page 2022
-
[67]
Bogdana Rakova, Jingying Yang, Henriette Cramer, and Rumman Chowdhury
-
[68]
Where responsible AI meets reality: Practitioner perspectives on enablers for shifting organizational practices.Proceedings of the ACM on Human-Computer Interaction5, CSCW1 (2021), 1–23
work page 2021
-
[69]
Andrea Roth. 2016. Machine testimony.Yale LJ126 (2016), 1972
work page 2016
-
[70]
Bianca GS Schor, Chris Norval, Ellen Charlesworth, and Jatinder Singh. 2024. Mind the gap: Designers and standards on algorithmic system transparency for users. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 1–16
work page 2024
-
[71]
Andrew D Selbst. 2021. An institutional view of algorithmic impact assessments. Harv. JL & Tech.35 (2021), 117
work page 2021
-
[72]
Brooklyn Defender Services. [n. d.].The Kinship Problem. https://indefenseof. us/issues/kinship-problem
-
[73]
Maneka Sinha. 2022. Radically reimagining forensic evidence.Ala. L. Rev.73 (2022), 879
work page 2022
-
[74]
Mar 11, 2025.STRmix™Now Being Used to Interpret Crime Scene Evi- dence in 91 U.S
STRmix. Mar 11, 2025.STRmix™Now Being Used to Interpret Crime Scene Evi- dence in 91 U.S. Labs. https://www.strmix.com/news/strmix-now-being-used- to-interpret-crime-scene-evidence-in-91-u-s-labs
work page 2025
-
[75]
United States v. Anderson, 673 F. Supp. 3d 671 (21-CR-204). (M.D. Pa. 2023)
work page 2023
- [76]
-
[77]
United States v. Lewis, 442 F. Supp. 3d 1122 (18-CR-194). (D. Minn. 2020)
work page 2020
-
[78]
Ortiz, 736 F.Supp.3d 895 (21-CR-2503)
United States v. Ortiz, 736 F.Supp.3d 895 (21-CR-2503). (S.D. Cal. 2024)
work page 2024
-
[79]
Richmond Y Wong, Michael A Madaio, and Nick Merrill. 2023. Seeing like a toolkit: How toolkits envision the work of AI ethics.Proceedings of the ACM on Human-Computer Interaction7, CSCW1 (2023), 1–27
work page 2023
-
[80]
Lucas Wright, Roxana Mika Muenster, Briana Vecchione, Tianyao Qu, Pika Cai, Alan Smith, Comm 2450 Student Investigators, Jacob Metcalf, J Nathan Matias, et al. 2024. Null Compliance: NYC Local Law 144 and the challenges of algorithm accountability. InThe 2024 ACM Conference on Fairness, Accountability, and Transparency. 1701–1713
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.