Recognition: unknown
Shared Emotion Geometry Across Small Language Models: A Cross-Architecture Study of Representation, Behavior, and Methodological Confounds
Pith reviewed 2026-05-10 16:07 UTC · model grok-4.3
The pith
Mature small language models from different architectures share nearly identical 21-emotion geometries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We extract 21-emotion vector sets from twelve small language models under a unified comprehension-mode pipeline at fp16 precision and compare the resulting geometries via representational similarity analysis on raw cosine RDMs. The five mature architectures share nearly identical 21-emotion geometry, with pairwise RDM Spearman correlations of 0.74-0.92. This universality persists across diametrically opposed behavioral profiles: Qwen 2.5 and Llama 3.2 occupy opposite poles of MTI Compliance facets yet produce nearly identical emotion RDMs (rho = 0.81), so behavioral facet differences arise above the shared emotion representation. Gemma-3 1B base exhibits extreme residual-stream anisotropy (0
What carries the argument
21-emotion vector sets extracted via a unified comprehension-mode pipeline at fp16 precision, compared through representational similarity analysis on cosine RDMs
If this is right
- Emotion geometries in mature models remain stable between base and instruct versions with RDM correlations of at least 0.92.
- Behavioral differences between models arise from layers above the shared emotion representation.
- Only immature models undergo geometric restructuring from RLHF.
- Cross-study comparisons of emotion vectors require decomposing method effects into coarse dissociation, sub-parameter sensitivity, precision effects, and cross-experiment biases.
- The shared geometry is largely determined by pretraining rather than later fine-tuning in mature architectures.
Where Pith is reading between the lines
- This convergence may imply that emotion geometry emerges as a stable byproduct of next-token prediction on large text corpora.
- The finding could extend to testing whether the same geometry appears in models trained on non-English data or different tokenizers.
- Researchers could examine if the shared emotion RDMs predict similar patterns of emotional bias or response in downstream applications across model families.
- The four-layer decomposition of method effects suggests that single-pipeline studies risk misattributing similarities between any two models.
Load-bearing premise
The unified comprehension-mode pipeline at fp16 precision extracts emotion vectors in a comparable way across architectures without introducing architecture-specific biases that could artifactually inflate the reported similarities.
What would settle it
Extracting emotion vectors from a new mature-architecture model using the same pipeline and observing RDM Spearman correlations below 0.7 with the existing mature set, or finding that an immature model shows no geometric restructuring after RLHF.
Figures





read the original abstract
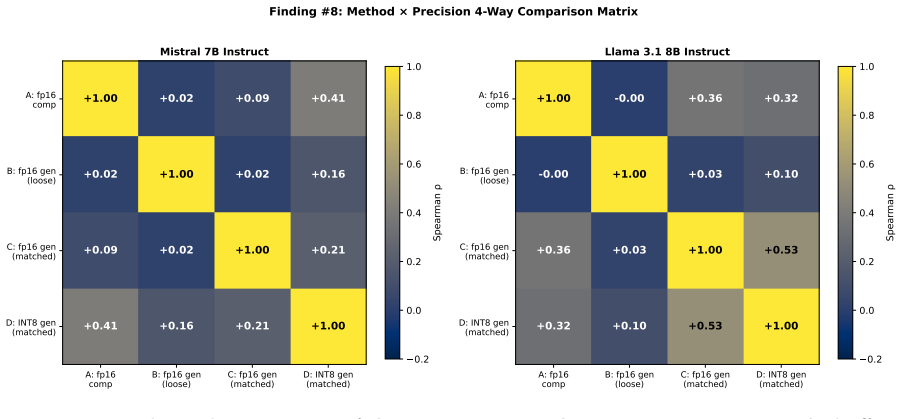
We extract 21-emotion vector sets from twelve small language models (six architectures x base/instruct, 1B-8B parameters) under a unified comprehension-mode pipeline at fp16 precision, and compare the resulting geometries via representational similarity analysis on raw cosine RDMs. The five mature architectures (Qwen 2.5 1.5B, SmolLM2 1.7B, Llama 3.2 3B, Mistral 7B v0.3, Llama 3.1 8B) share nearly identical 21-emotion geometry, with pairwise RDM Spearman correlations of 0.74-0.92. This universality persists across diametrically opposed behavioral profiles: Qwen 2.5 and Llama 3.2 occupy opposite poles of MTI Compliance facets yet produce nearly identical emotion RDMs (rho = 0.81), so behavioral facet differences arise above the shared emotion representation. Gemma-3 1B base, the one immature case in our dataset, exhibits extreme residual-stream anisotropy (0.997) and is restructured by RLHF across all geometric descriptors, whereas the five already-mature families show within-family base x instruct RDM correlations of rho >= 0.92 (Mistral 7B v0.3 at rho = 0.985), suggesting RLHF restructures only representations that are not yet organized. Methodologically, we show that what prior work has read as a single comprehension-vs-generation method effect in fact decomposes into four distinct layers -- a coarse method-dependent dissociation, robust sub-parameter sensitivity within generation, a true precision (fp16 vs INT8) effect, and a conflated cross-experiment bias that distorts in opposite directions for different models -- so that a single rho between two prior emotion-vector studies is not a safe basis for interpretation without the layered decomposition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extracts 21-emotion vector sets from twelve small language models (six architectures, base/instruct variants, 1B-8B parameters) under a single comprehension-mode pipeline at fp16 precision. It compares the resulting geometries via representational similarity analysis on raw cosine RDMs, reporting that five mature architectures (Qwen 2.5 1.5B, SmolLM2 1.7B, Llama 3.2 3B, Mistral 7B v0.3, Llama 3.1 8B) share nearly identical emotion geometry with pairwise RDM Spearman correlations of 0.74-0.92. This similarity holds across opposed behavioral profiles (e.g., Qwen 2.5 and Llama 3.2 at rho=0.81). Gemma-3 1B (immature) shows extreme residual anisotropy (0.997) and is restructured by RLHF, while mature families show high base-instruct stability (rho >= 0.92). The paper further decomposes prior method confounds into four layers: coarse method dissociation, sub-parameter sensitivity, precision effects, and cross-experiment bias.
Significance. If the results hold after addressing pipeline controls, the work would demonstrate architecture-independent 21-emotion geometry in mature SLMs, with behavioral differences arising above this shared representation. The four-layer confound decomposition is a clear methodological strength, providing a falsifiable framework for interpreting prior RSA studies and avoiding over-reliance on single rho values. Direct empirical RDM comparisons and within-family base/instruct correlations (e.g., Mistral at rho=0.985) add reproducibility value. Significance is limited by the absence of explicit bias controls, which could affect the universality claim.
major comments (2)
- [Abstract / Methods] Abstract / Methods (unified pipeline description): The central universality claim for the five mature architectures depends on the fp16 comprehension pipeline producing functionally equivalent emotion vectors across models. No controls are reported for tokenizer differences, layer selection/normalization, or residual anisotropy (explicitly noted only for Gemma). High RDM Spearman values (0.74-0.92) could therefore arise from shared extraction artifacts rather than intrinsic geometric convergence, even after the four-layer decomposition. Explicit ablation or normalization steps are needed to secure this link.
- [Abstract] Abstract (mature vs. immature distinction): The classification of models as 'mature' (high base-instruct stability, low anisotropy) versus 'immature' (Gemma) appears derived from the observed geometric outcomes rather than a pre-specified criterion. This risks post-hoc interpretation when claiming that RLHF restructures only immature representations. A clearer a priori definition or additional models would make the distinction load-bearing for the RLHF restructuring claim.
minor comments (2)
- [Abstract] The abstract packs multiple distinct claims (geometry universality, behavioral independence, RLHF effects, and four-layer decomposition) into one paragraph; separating the methodological contribution would improve readability.
- The 21 emotions are treated as a fixed set; briefly noting their selection rationale or source (even if standard) would clarify this free parameter.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important methodological considerations for strengthening the universality claim and the mature/immature distinction. We respond to each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract / Methods (unified pipeline description): The central universality claim for the five mature architectures depends on the fp16 comprehension pipeline producing functionally equivalent emotion vectors across models. No controls are reported for tokenizer differences, layer selection/normalization, or residual anisotropy (explicitly noted only for Gemma). High RDM Spearman values (0.74-0.92) could therefore arise from shared extraction artifacts rather than intrinsic geometric convergence, even after the four-layer decomposition. Explicit ablation or normalization steps are needed to secure this link.
Authors: We acknowledge that the unified pipeline, while consistent in prompt template and precision, does not include explicit ablations for tokenizer effects or layer-specific normalization, and reports residual anisotropy only for Gemma. The four-layer confound decomposition and the observation that high correlations persist across models with divergent tokenizers and opposed behavioral profiles provide supporting evidence that the geometry is not solely artifactual. Nevertheless, to directly address the concern, we will revise the Methods and Results sections to add: (i) residual anisotropy metrics for all twelve models, (ii) a sensitivity analysis comparing last-layer versus averaged final-layer vectors, and (iii) vector normalization prior to RDM computation, with the corresponding RDM correlations reported in a new supplementary table. These controls will be presented as robustness checks rather than altering the primary findings. revision: yes
-
Referee: [Abstract] Abstract (mature vs. immature distinction): The classification of models as 'mature' (high base-instruct stability, low anisotropy) versus 'immature' (Gemma) appears derived from the observed geometric outcomes rather than a pre-specified criterion. This risks post-hoc interpretation when claiming that RLHF restructures only immature representations. A clearer a priori definition or additional models would make the distinction load-bearing for the RLHF restructuring claim.
Authors: We agree that the mature/immature label was informed by the observed base-instruct stability and anisotropy values, creating a potential circularity for the RLHF claim. In the revision we will replace the post-hoc framing with an a priori operational definition: models are classified as mature if they belong to families with documented multi-stage post-training and exceed 1B parameters (with Gemma-3 1B noted as the exception due to its limited training scale). We will also add an explicit limitations paragraph stating that the RLHF-restructuring observation is based on a single immature case and requires replication with additional immature models before it can be treated as general. This change preserves the empirical pattern while removing the risk of post-hoc interpretation. revision: yes
Circularity Check
No significant circularity; claims rest on direct empirical RDM comparisons without reduction to inputs by construction.
full rationale
The paper extracts 21-emotion vectors from multiple models under a single described pipeline, computes raw cosine RDMs, and reports Spearman correlations (0.74-0.92) as observed empirical outcomes. No equations or steps define a quantity in terms of itself, fit parameters on a subset then relabel the fit as a prediction, or invoke self-citations to establish uniqueness or force an ansatz. The methodological decomposition into four confound layers is likewise presented as an empirical finding from the data rather than a definitional necessity. The central universality claim is therefore a measured pattern, not a tautology or self-referential derivation.
Axiom & Free-Parameter Ledger
free parameters (2)
- Selection of 21 emotions
- Model selection across 12 specific models
axioms (1)
- domain assumption Cosine similarity is an appropriate measure for comparing emotion vectors in residual streams.
Reference graph
Works this paper leans on
-
[1]
SmolLM2: When Smol Goes Big -- Data-Centric Training of a Small Language Model
Werra, L., & Wolf, T. (2025).SmolLM2: When Smol Goes Big — Data-Centric Training of a Small Language Model.arXiv:2502.02737. Anthropic. (2026).Emotion Concepts and their Function in a Large Language Model.Trans- former Circuits Thread. https://transformer-circuits.pub/2026/emotions/
work page internal anchor Pith review arXiv 2025
-
[2]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., et al. (2024).The Llama 3 Herd of Models.arXiv:2407.21783. Gemma Team. (2025).Gemma 3 Technical Report.arXiv:2503.19786
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Jeong, J. (2026a).Extracting and Steering Emotion Representations in Small Language Models: A Methodological Comparison.arXiv:2604.04064
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
(2026b).MTI: A Behavior-Based Temperament Profiling System for AI Agents
Jeong, J. (2026b).MTI: A Behavior-Based Temperament Profiling System for AI Agents. arXiv:2604.02145
-
[5]
Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M.-A., Stock, P., Le Scao, T., Lavril, T., Wang, T., Lacroix, T., & El Sayed, W. (2023).Mistral 7B. arXiv:2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Meng, K., Bau, D., Andonian, A., and Belinkov, Y
Lin, B. Y., Ravichander, A., Lu, X., Dziri, N., Sclar, M., Chandu, K., Bhagavatula, C., & Choi, Y. (2024). The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learn- ing. InInternational Conference on Learning Representations (ICLR).arXiv:2312.01552
- [7]
-
[8]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Park, K., Choe, Y. J., & Veitch, V. (2024). The Linear Representation Hypothesis and the Geometry of Large Language Models. InProceedings of the 41st International Conference on Machine Learning (ICML), PMLR 235:39643–39666. arXiv:2311.03658
work page internal anchor Pith review arXiv 2024
-
[9]
Rimsky, N., Gabrieli, N., Schulz, J., Tong, M., Hubinger, E., & Turner, A. M. (2024). Steering Llama 2 via Contrastive Activation Addition. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pages 15504–15522. arXiv:2312.06681
work page internal anchor Pith review arXiv 2024
-
[10]
Yang, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Li, C., Liu, D., Huang, F., Wei, H., et al. (2025).Qwen2.5 Technical Report.arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
arXiv preprint arXiv:2305.11206 , year=
Ghosh, G., Lewis, M., Zettlemoyer, L., &Levy, O.(2023). LIMA:LessIsMoreforAlignment. InAdvances in Neural Information Processing Systems (NeurIPS).arXiv:2305.11206. 34
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.