Recognition: unknown
Record-Remix-Replay: Hierarchical GPU Kernel Optimization using Evolutionary Search
Pith reviewed 2026-05-10 15:52 UTC · model grok-4.3
The pith
Record-Remix-Replay optimizes full scientific GPU applications more effectively and nearly an order of magnitude faster than traditional or modern evolutionary search methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Record-Remix-Replay (R^3) enables end-to-end optimization of GPU kernels by hierarchically applying evolutionary search guided by large language models, Bayesian optimization, and record-replay techniques. This integration allows efficient exploration of a combined space including source-level changes, compiler pass sequences, and runtime parameters. As a result, it achieves superior performance on complete scientific applications compared to optimizing kernel parameters or compiler flags alone, and does so nearly ten times faster than current evolutionary search approaches.
What carries the argument
The Record-Remix-Replay (R^3) hierarchical framework, which records compilation and execution traces to enable rapid remixing and replay of optimized variants during search that spans source implementation, compiler passes, and kernel launch parameters.
Load-bearing premise
The hierarchical combination of LLM-driven evolutionary search, Bayesian optimization, and record-replay compilation can explore the full GPU optimization space scalably without adding prohibitive overhead or requiring extra human input.
What would settle it
Running Record-Remix-Replay on a full scientific application and measuring that the achieved performance is no better than tuning kernel parameters and compiler flags separately, or that total search time is not substantially lower than existing evolutionary search methods.
Figures







read the original abstract
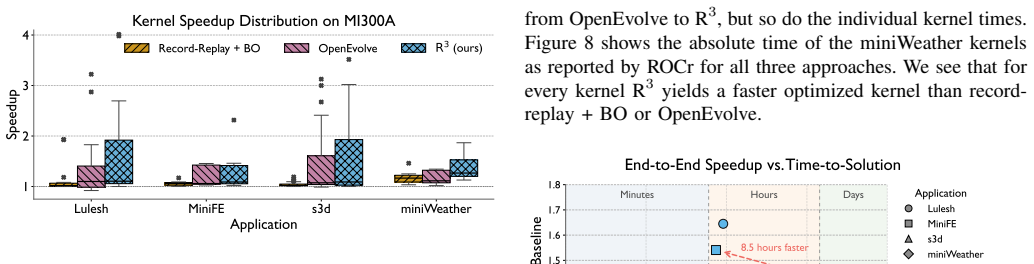
As high-performance computing and AI workloads become increasingly dependent on GPUs, maintaining high performance across rapidly evolving hardware generations has become a major challenge. Developers often spend months tuning scientific applications to fully exploit new architectures, navigating a complex optimization space that spans algorithm design, source implementation, compiler flags and pass sequences, and kernel launch parameters. Existing approaches can effectively search parts of this space in isolation, such as launch configurations or compiler settings, but optimizing across the full space still requires substantial human expertise and iterative manual effort. In this paper, we present Record-Remix-Replay (R^3), a hierarchical optimization framework that combines LLM-driven evolutionary search, Bayesian optimization, and record-replay compilation techniques to efficiently explore GPU kernel optimizations from source-level implementation choices down to compiler pass ordering and runtime configuration. By making candidate evaluation fast and scalable, our approach enables practical end-to-end search over optimization dimensions that are typically treated separately. We show that Record-Remix-Replay can optimize full scientific applications better than traditional approaches over kernel parameters and compiler flags, while also being nearly an order of magnitude faster than modern evolutionary search approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Record-Remix-Replay (R^3) hierarchical optimization framework for GPU kernels. It combines LLM-driven evolutionary search, Bayesian optimization, and record-replay compilation to explore optimizations across source-level implementation, compiler flags and passes, and kernel launch parameters. The central claim is that this approach optimizes full scientific applications better than traditional methods limited to kernel parameters and compiler flags, while achieving nearly an order of magnitude faster optimization times compared to modern evolutionary search techniques by making candidate evaluations fast and scalable.
Significance. If the results hold, this work could be significant for the field of high-performance computing and GPU-accelerated scientific applications. By hierarchically integrating established techniques with LLM-driven search, it promises to automate what currently requires substantial manual expertise, potentially accelerating the adaptation of codes to new GPU architectures. The claimed reduction in optimization time would be particularly valuable for large-scale applications where tuning is a bottleneck.
major comments (2)
- [Abstract] The abstract asserts concrete performance gains and speedups over traditional approaches and modern evolutionary search, but provides no experimental setup, baselines, workloads, quantitative results, tables, or error analysis to support these claims. Without this evidence, the central claims cannot be evaluated.
- [Framework Description] The description of the R^3 framework does not include any analysis or measurements of the overhead introduced by LLM calls, the number of LLM inferences per generation, Bayesian optimization costs, or record-replay compilation times. This information is necessary to substantiate the claim that the approach is nearly an order of magnitude faster, as unaccounted latency in these components could negate the speedup.
minor comments (2)
- [Abstract] The title uses 'Evolutionary Search' but the abstract emphasizes LLM-driven evolutionary search; clarifying the role of LLMs versus traditional evolutionary algorithms would improve precision.
- [Abstract] The term 'record-replay compilation techniques' is introduced without a brief definition or reference, which may confuse readers unfamiliar with the specific method.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight opportunities to improve clarity and substantiation of our claims, and we outline specific revisions below to address them.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts concrete performance gains and speedups over traditional approaches and modern evolutionary search, but provides no experimental setup, baselines, workloads, quantitative results, tables, or error analysis to support these claims. Without this evidence, the central claims cannot be evaluated.
Authors: We appreciate this observation. The abstract is designed as a concise high-level summary of the contributions and findings, with the full experimental setup (including baselines, workloads such as the scientific applications tested, quantitative results, tables, and error analysis) presented in detail in Sections 4 and 5. To better support the claims at the abstract level, we will revise the abstract to include a brief reference to the key workloads evaluated and the magnitude of observed speedups, while directing readers to the relevant sections for complete details. revision: yes
-
Referee: [Framework Description] The description of the R^3 framework does not include any analysis or measurements of the overhead introduced by LLM calls, the number of LLM inferences per generation, Bayesian optimization costs, or record-replay compilation times. This information is necessary to substantiate the claim that the approach is nearly an order of magnitude faster, as unaccounted latency in these components could negate the speedup.
Authors: We agree that a breakdown of these overhead components is important for rigorously supporting the speedup claims. The manuscript currently focuses on the hierarchical integration and end-to-end results. We will add a new subsection (likely in Section 3) that reports measurements of LLM inference overheads, the number of inferences per generation, Bayesian optimization costs, and record-replay compilation times, including how these contribute to the overall nearly order-of-magnitude improvement relative to standard evolutionary search. revision: yes
Circularity Check
No circularity: framework combines established techniques with no derivations or self-referential reductions
full rationale
The paper describes Record-Remix-Replay (R^3) as a hierarchical framework integrating LLM-driven evolutionary search, Bayesian optimization, and record-replay compilation to explore GPU kernel optimizations. No equations, first-principles derivations, fitted parameters presented as predictions, or load-bearing self-citations appear in the provided text. Claims rest on empirical evaluation of the combined system rather than any step that reduces by construction to its inputs. This is a standard engineering contribution presenting a new composition of prior methods, with no evidence of self-definitional, fitted-input, or uniqueness-imported circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption GPU kernel optimization involves a complex space spanning algorithm design, source implementation, compiler flags and pass sequences, and kernel launch parameters.
invented entities (1)
-
Record-Remix-Replay (R^3) hierarchical optimization framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Opentuner: an extensible framework for program autotuning,
J. Ansel, S. Kamil, K. Veeramachaneni, J. Ragan-Kelley, J. Bosboom, U.-M. O’Reilly, and S. Amarasinghe, “Opentuner: An extensible framework for program autotuning,” in2014 23rd International Conference on Parallel Architecture and Compilation Techniques (PACT), 2014, pp. 303–315. [Online]. Available: https://doi.org/10. 1145/2628071.2628092
-
[2]
Active harmony: Towards automated performance tuning,
C. Tapus, I.-H. Chung, and J. Hollingsworth, “Active harmony: Towards automated performance tuning,” inSC ’02: Proceedings of the 2002 ACM/IEEE Conference on Supercomputing, 2002, pp. 44–44. [Online]. Available: https://doi.org/10.1109/SC.2002.10062
-
[3]
Kernel launcher: C++ library for optimal-performance portable cuda applications,
S. Heldens and B. van Werkhoven, “Kernel launcher: C++ library for optimal-performance portable cuda applications,”arXiv preprint arXiv:2303.12374, 2023. [Online]. Available: https://doi.org/10.48550/ arXiv.2303.12374
-
[4]
Cltune: A generic auto-tuner for opencl kernels,
C. Nugteren and V . Codreanu, “Cltune: A generic auto-tuner for opencl kernels,” in2015 IEEE 9th International Symposium on Embedded Multicore/Many-core Systems-on-Chip (MCSoC). Los Alamitos, CA, USA: IEEE Computer Society, sep 2015, pp. 195–202. [Online]. Available: https://doi.org/10.1109/MCSoC.2015.10
-
[5]
Piecewise holistic autotuning of compiler and runtime parameters,
M. Popov, C. Akel, W. Jalby, and P. de Oliveira Castro, “Piecewise holistic autotuning of compiler and runtime parameters,” inEuro- Par 2016: Parallel Processing, P.-F. Dutot and D. Trystram, Eds. Cham: Springer International Publishing, 2016, pp. 238–250. [Online]. Available: https://doi.org/10.1007/978-3-319-43659-3 18
-
[6]
CERE: llvm-based codelet extractor and replayer for piecewise benchmarking and optimization,
P. de Oliveira Castro, C. Akel, E. Petit, M. Popov, and W. Jalby, “CERE: llvm-based codelet extractor and replayer for piecewise benchmarking and optimization,”ACM Trans. Archit. Code Optim., vol. 12, no. 1, pp. 6:1–6:24, 2015. [Online]. Available: https://doi.org/10.1145/2724717
-
[7]
Z. Xie, J. Liu, J. Li, and D. Li, “Merchandiser: Data placement on heterogeneous memory for task-parallel hpc applications with load- balance awareness,” inProceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’23. New York, NY , USA: Association for Computing Machinery, 2023, p. 204–217. [Onli...
-
[8]
Scalable Tuning of (OpenMP) GPU Applications via Kernel Record and Replay,
K. Parasyris, G. Georgakoudis, E. Rangel, I. Laguna, and J. Doerfert, “Scalable Tuning of (OpenMP) GPU Applications via Kernel Record and Replay,” inProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, ser. SC ’23. New York, NY , USA: Association for Computing Machinery, Nov. 2023, pp. 1–14. [Online...
-
[9]
A Survey of Evolutionary Algorithms,
L. Liu, T. Fei, Z. Zhu, K. Wu, and Y . Zhang, “A Survey of Evolutionary Algorithms,” in2023 4th International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Aug. 2023, pp. 22–27. [Online]. Available: https://doi.org/ 10.1109/ICBAIE59714.2023.10281260
-
[10]
Mathematical discoveries from program search with large language models,
B. Romera-Paredes, M. Barekatain, A. Novikov, M. Balog, M. P. Kumar, E. Dupont, F. J. R. Ruiz, J. S. Ellenberg, P. Wang, O. Fawzi, P. Kohli, and A. Fawzi, “Mathematical discoveries from program search with large language models,”Nature, vol. 625, no. 7995, pp. 468–475, Jan
-
[11]
[Online]. Available: https://doi.org/10.1038/s41586-023-06924-6
-
[12]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
A. Novikov, N. V ˜u, M. Eisenberger, E. Dupont, P.-S. Huang, A. Z. Wagner, S. Shirobokov, B. Kozlovskii, F. J. R. Ruiz, A. Mehrabian, M. P. Kumar, A. See, S. Chaudhuri, G. Holland, A. Davies, S. Nowozin, P. Kohli, and M. Balog, “AlphaEvolve: A coding agent for scientific and algorithmic discovery,” Jun. 2025. [Online]. Available: https://doi.org/10.48550/...
work page internal anchor Pith review doi:10.48550/arxiv.2506.13131 2025
-
[13]
A. Cheng, S. Liu, M. Pan, Z. Li, B. Wang, A. Krentsel, T. Xia, M. Cemri, J. Park, S. Yang, J. Chen, L. Agrawal, A. Desai, J. Xing, K. Sen, M. Zaharia, and I. Stoica, “Barbarians at the Gate: How AI is Upending Systems Research,” Oct. 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.06189
-
[14]
Openevolve: an open-source evolutionary cod- ing agent,
A. Sharma, “Openevolve: an open-source evolutionary cod- ing agent,” 2025. [Online]. Available: https://github.com/ algorithmicsuperintelligence/openevolve
2025
-
[15]
J.-B. Mouret and J. Clune, “Illuminating search spaces by mapping elites,” Apr. 2015. [Online]. Available: https://doi.org/10.48550/arXiv. 1504.04909
work page internal anchor Pith review doi:10.48550/arxiv 2015
-
[16]
Kernel tuner: A search-optimizing gpu code auto- tuner,
B. van Werkhoven, “Kernel tuner: A search-optimizing gpu code auto- tuner,”Future Generation Computer Systems, vol. 90, pp. 347–358,
-
[17]
Available: https://doi.org/10.1016/j.future.2018.08.004
[Online]. Available: https://doi.org/10.1016/j.future.2018.08.004
-
[18]
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning,
T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, M. Cowan, H. Shen, L. Wang, Y . Hu, L. Ceze, C. Guestrin, and A. Krishnamurthy, “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning,” Feb
-
[19]
Available: https://doi.org/10.48550/arXiv.1802.04799
[Online]. Available: https://doi.org/10.48550/arXiv.1802.04799
-
[20]
Ansor: Generating high-performance tensor programs for deep learning,
L. Zheng, C. Jia, M. Sun, Z. Wu, C. H. Yu, A. Haj-Ali, Y . Wang, J. Yang, D. Zhuo, K. Sen, J. E. Gonzalez, and I. Stoica, “Ansor: Generating high-performance tensor programs for deep learning,” arXiv, 2020, oSDI 2020 (arXiv version). [Online]. Available: https://doi.org/10.48550/arXiv.2006.06762
-
[21]
Tensor program optimization with probabilistic programs,
J. Shao, X. Zhou, S. Feng, B. Hou, R. Lai, H. Jin, W. Lin, M. Masuda, C. H. Yu, and T. Chen, “Tensor program optimization with probabilistic programs,” arXiv, 2022, accepted to NeurIPS 2022 (arXiv version). [Online]. Available: https://doi.org/10.48550/arXiv.2205.13603
-
[22]
Learning to optimize halide with tree search and random programs,
A. Adams, K. Ma, L. Anderson, R. Baghdadi, T.-M. Li, M. Gharbi, B. Steiner, S. Johnson, K. Fatahalian, F. Durand, and J. Ragan-Kelley, “Learning to optimize halide with tree search and random programs,” ACM Transactions on Graphics, vol. 38, no. 4, pp. 121:1–121:12,
-
[23]
Available: https://doi.org/10.1145/3306346.3322967
[Online]. Available: https://doi.org/10.1145/3306346.3322967
-
[24]
Triton: an intermediate language and compiler for tiled neural network computations,
P. Tillet, H. T. Kung, and D. Cox, “Triton: An intermediate language and compiler for tiled neural network computations,” inProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages (MAPL 2019), 2019, pp. 10–19. [Online]. Available: https://doi.org/10.1145/3315508.3329973
-
[25]
A. H. Ashouri, A. Bignoli, G. Palermo, C. Silvano, S. Kulkarni, and J. Cavazos, “Micomp: Mitigating the compiler phase-ordering problem using optimization sub-sequences and machine learning,”ACM Trans. Archit. Code Optim., vol. 14, no. 3, Sep. 2017. [Online]. Available: https://doi.org/10.1145/3124452
-
[26]
Compilergym: Robust, performant compiler optimization environments for ai research,
C. Cummins, B. Wasti, J. Guo, B. Cui, J. Ansel, S. Gomez, S. Jain, J. Liu, O. Teytaud, B. Steiner, Y . Tian, and H. Leather, “Compilergym: Robust, performant compiler optimization environments for ai research,” in2022 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), 2022, pp. 92–105. [Online]. Available: https://doi.org/10.1109/...
-
[27]
Apollo: Reusable models for fast, dynamic tuning of input-dependent code,
D. Beckingsale, O. Pearce, I. Laguna, and T. Gamblin, “Apollo: Reusable models for fast, dynamic tuning of input-dependent code,” in2017 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2017, pp. 307–316. [Online]. Available: https://doi.org/10.1109/IPDPS.2017.38
-
[28]
Artemis: Automatic runtime tuning of parallel execution parameters using machine learning,
C. Wood, G. Georgakoudis, D. Beckingsale, D. Poliakoff, A. Gimenez, K. Huck, A. Malony, and T. Gamblin, “Artemis: Automatic runtime tuning of parallel execution parameters using machine learning,” inHigh Performance Computing, B. L. Chamberlain, A.-L. Varbanescu, H. Ltaief, and P. Luszczek, Eds. Cham: Springer International Publishing, 2021, pp. 453–472. ...
-
[29]
Auto-tuning parameter choices in hpc applications using bayesian optimization,
H. Menon, A. Bhatele, and T. Gamblin, “Auto-tuning parameter choices in hpc applications using bayesian optimization,” in2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2020, pp. 831–840. [Online]. Available: https://doi.org/10. 1109/IPDPS47924.2020.00090
-
[30]
Gptune: Multitask learning for autotuning exascale applications,
Y . Liu, W. M. Sid-Lakhdar, O. Marques, X. Zhu, C. Meng, J. W. Demmel, and X. S. Li, “Gptune: Multitask learning for autotuning exascale applications,” inProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, ser. PPoPP ’21. New York, NY , USA: Association for Computing Machinery, 2021, p. 234–246. [Online]. Avai...
-
[31]
An architecture for flexible auto-tuning: The periscope tuning framework 2.0,
R. Mijakovi ´c, M. Firbach, and M. Gerndt, “An architecture for flexible auto-tuning: The periscope tuning framework 2.0,” in 2016 2nd International Conference on Green High Performance Computing (ICGHPC), 2016, pp. 1–9. [Online]. Available: https: //doi.org/10.1109/ICGHPC.2016.7508066
-
[32]
Proteus: Portable Runtime Optimization of GPU Kernel Execution with Just-in-Time Compilation,
G. Georgakoudis, K. Parasyris, and D. Beckingsale, “Proteus: Portable Runtime Optimization of GPU Kernel Execution with Just-in-Time Compilation,” inProceedings of the 23rd ACM/IEEE International Symposium on Code Generation and Optimization, ser. CGO ’25. New York, NY , USA: Association for Computing Machinery, Mar. 2025, pp. 507–522. [Online]. Available...
-
[33]
Integrating performance tools in model reasoning for gpu kernel optimization,
D. Nichols, K. Parasyris, C. Jekel, A. Bhatele, and H. Menon, “Integrating performance tools in model reasoning for gpu kernel optimization,” 2025, https://doi.org/10.48550/arXiv.2510.17158. [Online]. Available: https://arxiv.org/abs/2510.17158
-
[34]
Agentic ai security: Threats, defenses, evaluation, and open challenges,
D. Nichols, P. Polasam, H. Menon, A. Marathe, T. Gamblin, and A. Bhatele, “ Performance-Aligned LLMs for Generating Fast HPC Code ,”IEEE Transactions on Parallel & Distributed Systems, no. 01, pp. 1–12, Mar. 5555, https://doi.org/10.1109/TPDS.2026.3675550. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/TPDS. 2026.3675550
-
[35]
Efficient Memory Management for Large Language Model Serving with PagedAttention
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient Memory Management for Large Language Model Serving with PagedAttention,” Sep. 2023, arXiv:2309.06180 [cs]. [Online]. Available: https://doi.org/10.48550/ arXiv.2309.06180
work page internal anchor Pith review arXiv 2023
-
[36]
Lulesh 2.0 updates and changes,
I. Karlin, J. Keasler, and J. R. Neely, “Lulesh 2.0 updates and changes,” Lawrence Livermore National Laboratory (LLNL), Tech. Rep., 07
-
[37]
Available: https://doi.org/10.2172/1090032
[Online]. Available: https://doi.org/10.2172/1090032
-
[38]
P. T. Lin, M. A. Heroux, R. F. Barrett, and A. B. Williams, “Assessing a mini-application as a performance proxy for a finite element method engineering application,”Concurrency and Computation: Practice and Experience, vol. 27, no. 17, pp. 5374–5389, 2015. [Online]. Available: https://doi.org/10.1002/cpe.3587
-
[39]
The scalable heterogeneous computing (shoc) benchmark suite,
A. Danalis, G. Marin, C. McCurdy, J. S. Meredith, P. C. Roth, K. Spafford, V . Tipparaju, and J. S. Vetter, “The scalable heterogeneous computing (shoc) benchmark suite,” inProceedings of the 3rd Workshop on General-Purpose Computation on Graphics Processing Units, ser. GPGPU-3. New York, NY , USA: Association for Computing Machinery, 2010, p. 63–74. [Onl...
-
[40]
M. R. Norman, “miniweather,” [Computer Software], March 2020. [Online]. Available: https://doi.org/10.11578/dc.20201001.88
-
[41]
arXiv: 2303.14006 ISBN: 9798350397390
Z. Jin and J. S. Vetter, “A Benchmark Suite for Improving Performance Portability of the SYCL Programming Model,” in2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Apr. 2023, pp. 325–327. [Online]. Available: https://doi.org/10.1109/ISPASS57527.2023.00041
-
[42]
J. Bergstra, R. Bardenet, Y . Bengio, and B. K ´egl, “Algorithms for hyper-parameter optimization,” inProceedings of the 25th International Conference on Neural Information Processing Systems, ser. NIPS’11. Red Hook, NY , USA: Curran Associates Inc., Dec. 2011, pp. 2546–2554, https://dl.acm.org/doi/10.5555/2986459.2986743. [Online]. Available: https://pap...
-
[43]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Bao, B. Barak, A. Bennett, T. Bertao, N. Brett, E. Brevdo, G. Brockman, S. Bubeck, C. Chang, K. Chen, M. Chen, E. Cheung, A. Clark, D. Cook, M. Dukhan, C. Dvorak, K. Fives, V . Fomenko, T. Garipov, K. Georgiev, M. Glaese, T. Gogineni, A. Goucher, L. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[44]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. J. Ostrow, A. Ananthram, A. Nathan, A. Luo, A. Helyar, A. Madry, A. Efremov, A. Spyra, A. Baker- Whitcomb, A. Beutel, A. Karpenko, A. Makelov, A. Neitz, A. Wei, A. Barr, A. Kirchmeyer, A. Ivanov, A. Christakis, A. Gillespie, A. Tam, A. Bennett, A. Wan, A. Huang, A. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.03267 2025
-
[45]
Solving lattice qcd systems of equations using mixed precision solvers on gpus,
M. Clark, R. Babich, K. Barros, R. Brower, and C. Rebbi, “Solving lattice qcd systems of equations using mixed precision solvers on gpus,” Computer Physics Communications, vol. 181, no. 9, pp. 1517–1528,
-
[46]
Available: https://doi.org/10.1016/j.cpc.2010.05.002
[Online]. Available: https://doi.org/10.1016/j.cpc.2010.05.002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.