Recognition: unknown
DuET: Dual Execution for Test Output Prediction with Generated Code and Pseudocode
Pith reviewed 2026-05-10 15:51 UTC · model grok-4.3
The pith
Combining direct code execution with LLM-simulated pseudocode execution improves reliability of test output predictions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The work claims that LLM-based pseudocode execution grounds predictions in a form that tolerates small generation mistakes better than raw code execution, and that these two grounding methods are complementary because code execution catches hallucinations in pseudocode reasoning while pseudocode reasoning avoids crashes from syntax or runtime errors in the generated code. Their combination through functional majority voting therefore yields higher accuracy than either grounding method used alone.
What carries the argument
The DuET dual-execution framework, which generates both code and pseudocode, runs the code directly, simulates pseudocode execution via LLM reasoning, and selects the final output by majority vote across the two results.
If this is right
- Direct code execution fails on minor syntax or runtime mistakes while pseudocode reasoning tolerates abstraction-level errors.
- Pseudocode reasoning can introduce its own inconsistencies that concrete code execution can correct.
- Majority voting across the two executions produces more stable test output predictions than single-path methods.
- The complementarity holds because the failure modes of the two paths are largely non-overlapping.
Where Pith is reading between the lines
- The same dual-path idea could be tested on other LLM code tasks such as program repair or specification inference.
- Different aggregation rules beyond simple majority might further exploit the complementarity.
- The approach points toward broader use of mixed concrete and abstract execution traces inside LLM pipelines.
Load-bearing premise
That errors from direct code execution and from LLM pseudocode reasoning differ enough for majority voting to pick the correct output more often than either method alone.
What would settle it
A set of test cases where the majority-vote prediction matches the single best of the two separate methods no more often than chance or shows lower accuracy than the stronger individual method.
Figures




















read the original abstract
This work addresses test output prediction, a key challenge in test case generation. To improve the reliability of predicted outputs by LLMs, prior approaches generate code first to ground predictions. One grounding strategy is direct execution of generated code, but even minor errors can cause failures. To address this, we introduce LLM-based pseudocode execution, which grounds prediction on more error-resilient pseudocode and simulates execution via LLM reasoning. We further propose DuET, a dual-execution framework that combines both approaches by functional majority voting. Our analysis shows the two approaches are complementary in overcoming the limitations of direct execution suffering from code errors, and pseudocode reasoning from hallucination. On LiveCodeBench, DuET achieves the state-of-the-art performance, improving Pass@1 by 13.6 pp.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DuET, a dual-execution framework for test output prediction that combines direct execution of LLM-generated code with LLM-based pseudocode execution via functional majority voting. It claims the approaches are complementary (code execution fails mainly on syntax/runtime errors; pseudocode on hallucinations) and reports state-of-the-art results on LiveCodeBench, improving Pass@1 by 13.6 percentage points over prior methods.
Significance. If the complementarity mechanism and experimental gains are robustly validated, DuET provides a practical, training-free way to improve reliability in LLM-driven test case generation by exploiting distinct failure modes. The reported Pass@1 improvement on a standard benchmark like LiveCodeBench would be a meaningful advance for automated software testing.
major comments (2)
- [Analysis section (referenced in abstract)] The central claim that the two execution modes are complementary enough for majority voting to reliably outperform the stronger single method (and that this drives the 13.6 pp gain) is load-bearing but unsupported by quantitative evidence. The abstract states the complementarity but the manuscript provides no error-type breakdown, per-instance disagreement rates, or ablation comparing voting to individual methods or random ensembles (see the analysis section referenced in the abstract).
- [Experiments section] The experimental results lack details required to assess the SOTA claim: specific LLMs and prompting setups for each execution mode, exact baseline reproductions, number of trials or statistical significance tests, and controls for confounds such as test-case distribution or model choice. Without these, the performance delta cannot be confidently attributed to DuET rather than other factors.
minor comments (2)
- [Abstract] The abstract mentions 'our analysis shows' the complementarity but does not point to the specific section, table, or figure containing the supporting measurements.
- [Introduction] Pass@1 and other metrics should be explicitly defined on first use, even if standard in the subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for improvement in substantiating our claims about complementarity and in providing fuller experimental documentation. We address each major comment below and commit to a major revision that incorporates the suggested enhancements.
read point-by-point responses
-
Referee: [Analysis section (referenced in abstract)] The central claim that the two execution modes are complementary enough for majority voting to reliably outperform the stronger single method (and that this drives the 13.6 pp gain) is load-bearing but unsupported by quantitative evidence. The abstract states the complementarity but the manuscript provides no error-type breakdown, per-instance disagreement rates, or ablation comparing voting to individual methods or random ensembles (see the analysis section referenced in the abstract).
Authors: We agree that the analysis section requires additional quantitative support to robustly validate the complementarity claim and its contribution to the reported gains. While the manuscript qualitatively contrasts the failure modes (syntax/runtime errors in direct code execution versus hallucinations in pseudocode reasoning), it does not include the requested error-type breakdowns, per-instance disagreement statistics, or ablations against individual methods and random ensembles. We will revise the analysis section to add these elements, drawing on our existing experimental runs to categorize errors, measure agreement rates, and compare majority voting performance against the stronger single method and random baselines. This will provide direct evidence that the 13.6 pp improvement stems from the dual-execution mechanism rather than other factors. revision: yes
-
Referee: [Experiments section] The experimental results lack details required to assess the SOTA claim: specific LLMs and prompting setups for each execution mode, exact baseline reproductions, number of trials or statistical significance tests, and controls for confounds such as test-case distribution or model choice. Without these, the performance delta cannot be confidently attributed to DuET rather than other factors.
Authors: We acknowledge that the experiments section would benefit from greater specificity to allow full assessment of the SOTA results. The manuscript identifies GPT-4 as the primary model for both code generation and pseudocode execution, describes the prompting approach, and notes that baselines were reproduced under matching conditions; however, we did not include exhaustive details such as exact prompt templates in the main text, the number of trials (we performed multiple runs for averaging), statistical significance tests, or explicit controls for confounds like test-case difficulty distribution. We will expand this section to provide the missing details, include statistical tests (e.g., McNemar's test for paired comparisons), and add stratified results by test-case characteristics to strengthen attribution of the performance delta to DuET. revision: yes
Circularity Check
No circularity: empirical framework with independent benchmark validation
full rationale
The paper presents DuET as an engineering framework that combines direct code execution with LLM-simulated pseudocode execution via majority voting. Its central result is an empirical Pass@1 improvement of 13.6 pp on LiveCodeBench, reported as an observation rather than a derived quantity. No equations, fitted parameters, or first-principles claims are present that reduce to the inputs by construction. Complementarity is asserted from qualitative analysis of error types, but this does not constitute a self-referential loop or a renamed known result. No self-citation chains, uniqueness theorems, or smuggled ansatzes appear in the provided text as load-bearing for the performance claim. The derivation is therefore self-contained as a proposal validated against an external benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based pseudocode execution provides a more error-resilient grounding for output prediction than direct code execution
invented entities (1)
-
DuET dual-execution framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-planning code generation with large language models. ACM Transactions on Software Engineering and Methodology, 33(7):1–30. Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yu- taka Matsuo, and Yusuke Iwasawa. 2022. Large lan- guage models are zero-shot reasoners. Advances in neural information processing systems, 35:22199– 22213. Sumith Kulal, Panupon...
-
[2]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Competition-level code generation with alpha- code. Science, 378(6624):1092–1097. Chenxiao Liu, Shuai Lu, Weizhu Chen, Daxin Jiang, Alexey Svyatkovskiy, Shengyu Fu, Neel Sundare- san, and Nan Duan. 2023a. Code execution with pre-trained language models. In Findings of the Association for Computational Linguistics: ACL 2023, pages 4984–4999, Toronto, Canad...
work page internal anchor Pith review arXiv 2023
-
[3]
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions. arXiv preprint arXiv:2406.15877. A Related Work Grounded Test Output PredictionTest case generation provides input-output pairs to verify code correctness (Chen et al., 2023; Huang et al., 2024; Han et al., 2024), while also enabling feedback-driven refinement...
work page internal anchor Pith review arXiv 2023
-
[4]
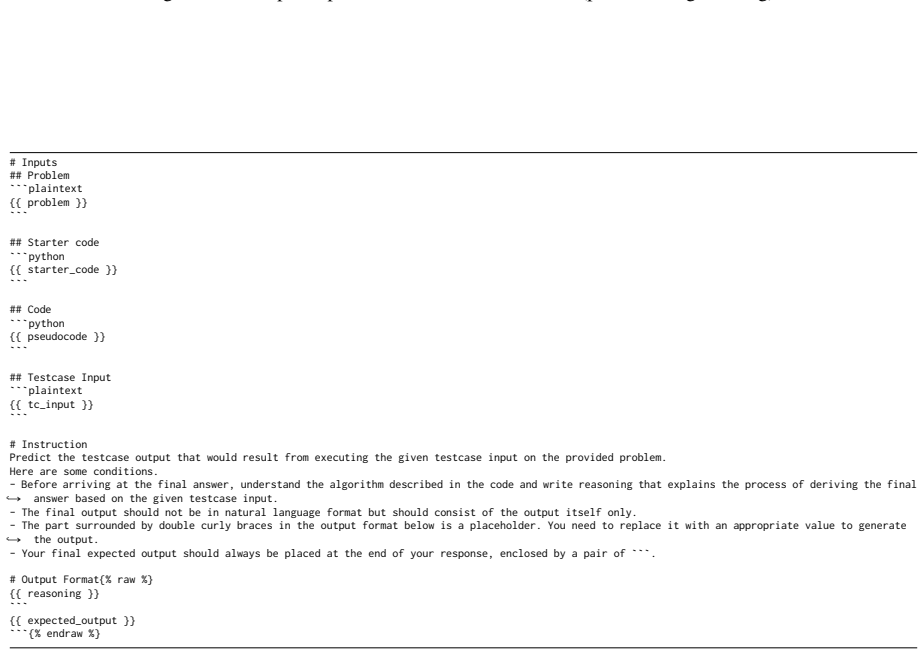
00", "25
Initialize a list possible_ends with values ["00", "25", "50", "75"] which represent the numbers divisible by 25
-
[5]
Set min_operations to a large value (e.g., length of num + 1) to keep track of the minimum operations needed
-
[6]
Initialize two pointers, i and j, to the end of the string num
Iterate over each possible_end in possible_ends: a. Initialize two pointers, i and j, to the end of the string num. b. Set found_digits to 0, representing how many digits of possible_end have been matched. c. While iterating from the end of num towards the beginning: - If found_digits is 0 and num[i] matches the second character of possible_end: * Increme...
-
[7]
If min_operations is still set to its initial large value, return the length of num - 1 (all digits removed except one)
-
[8]
2245047" special (divisible by 25), we need to find the fewest deletions needed to end the number with
Return min_operations. Figure 10: Generated Pseudocode (Correct). To determine the minimum number of operations required to make the number "2245047" special (divisible by 25), we need to find the fewest deletions needed to end the number with "00", "25", "50", or "75".ãÑ
-
[9]
- The second last'0'is at index 5
For "00": - The last'0'is at index 6. - The second last'0'is at index 5. - Operations needed: (6 - 5 - 1) + (7 - 6 - 1) = 0 + 0 = 0
-
[10]
- The nearest'2'before that'5'is at index 2
For "25": - The last'5'is at index 4. - The nearest'2'before that'5'is at index 2. - Operations needed: (4 - 2 - 1) + (7 - 4 - 1) = 1 + 2 = 3
-
[11]
- The nearest'5'before that'0'is at index 4
For "50": - The last'0'is at index 6. - The nearest'5'before that'0'is at index 4. - Operations needed: (6 - 4 - 1) + (7 - 6 - 1) = 1 + 0 = 1
-
[12]
75": - The last'5'is at index 4. - There is no'7'before that'5'. The minimum operations among these options are 0 (for ending
For "75": - The last'5'is at index 4. - There is no'7'before that'5'. The minimum operations among these options are 0 (for ending "00"). Thus, no deletions are needed to make the number special. ``` 0 ``` Figure 11: LLM-based Execution (Execution Hallucination). def minimumOperations(num: str) -> int: possible_ends = ["00", "25", "50", "75"] min_operatio...
-
[13]
Initialize a graph with nodes representing each index of the array nums
-
[14]
Connect two nodes with an edge if the difference between their corresponding values in nums is less than or equal to limit
-
[15]
Perform a Depth-First Search (DFS) or Breadth-First Search (BFS) to find all connected components of the graph
-
[16]
- Sort this subarray to get the lexicographically smallest order
For each connected component: - Extract the subarray of nums corresponding to the indices in this component. - Sort this subarray to get the lexicographically smallest order
-
[17]
Replace the elements in the original nums array at the positions of the connected component with the sorted values
-
[18]
Figure 14: Generated Pseudocode (Correct)
Return the modified nums array as the result. Figure 14: Generated Pseudocode (Correct). To solve the problem, we need to find the lexicographically smallest array by swapping elements within a certain limit of their differences. The approach involves creating a graph where each index in the array represents a node, and an edge exists between nodes if the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.