Recognition: 2 theorem links
· Lean TheoremBayMOTH: Bayesian optiMizatiOn with meTa-lookahead -- a simple approacH
Pith reviewed 2026-05-10 15:44 UTC · model grok-4.3
The pith
BayMOTH is a meta-Bayesian optimization method that selectively uses related-task data when it helps and defaults to lookahead search otherwise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper introduces BayMOTH, a meta-BO algorithm that utilizes information from related tasks only when an internal check determines it is useful, otherwise reverting to lookahead Bayesian optimization within the same unified procedure, and reports that this yields competitive results on standard benchmarks while preserving performance when test tasks share limited structure with the meta-training set.
What carries the argument
An internal usefulness detector that decides at each query whether to draw on meta-training data or to run pure lookahead search.
If this is right
- The method remains competitive with prior meta-BO algorithms when tasks are aligned.
- Performance stays strong in regimes where new tasks share little structure with the meta-training set.
- A single framework handles both high- and low-relatedness cases without separate logic branches.
- The approach applies directly to sequential black-box function optimization problems.
Where Pith is reading between the lines
- The same usefulness detector could be tested in other sequential decision settings such as active learning or experimental design.
- If the detector generalizes, practitioners could apply meta-learning more freely without first verifying task similarity.
- The fallback behavior suggests that hybrid meta-plus-lookahead designs may be more robust than pure meta-learning in uncertain environments.
Load-bearing premise
The internal check can correctly identify when meta-data is helpful versus when it should be ignored, without creating new errors on the tested optimization tasks.
What would settle it
A benchmark run in which the method's usefulness detector selects meta-data on a clearly mismatched task and produces measurably worse final performance than pure lookahead Bayesian optimization.
Figures













read the original abstract
Bayesian optimization (BO) has for sequential optimization of expensive black-box functions demonstrated practicality and effectiveness in many real-world settings. Meta-Bayesian optimization (meta-BO) focuses on improving the sample efficiency of BO by making use of information from related tasks. Although meta-BO is sample-efficient when task structure transfers, poor alignment between meta-training and test tasks can cause suboptimal queries to be suggested during online optimization. To this end, we propose a simple meta-BO algorithm that utilizes related-task information when determined useful, falling back to lookahead otherwise, within a unified framework. We demonstrate competitiveness of our method with existing approaches on function optimization tasks, while retaining strong performance in low task-relatedness regimes where test tasks share limited structure with the meta-training set.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes BayMOTH, a simple meta-Bayesian optimization algorithm that utilizes related-task information when determined useful and falls back to lookahead otherwise, all within a unified framework. It claims competitiveness with existing meta-BO methods on function optimization tasks while retaining strong performance in low task-relatedness regimes where test tasks share limited structure with the meta-training set.
Significance. If the usefulness decision rule can be shown to work reliably without introducing new failure modes, the approach would address a practical limitation in meta-BO by mitigating negative transfer. A simple, unified method that selectively incorporates meta-information could be valuable for real-world sequential optimization where task alignment is uncertain.
major comments (2)
- Abstract: the central claims of competitiveness and retained performance in low-relatedness regimes are asserted without any quantitative results, description of baselines, statistical controls, or implementation details for the usefulness decision rule, leaving the claims with limited verifiable support.
- Abstract: no description is given of how the internal mechanism detects when related-task information is useful versus when to ignore it, which is load-bearing for the unified framework and the claim of robustness across relatedness regimes.
minor comments (2)
- The title employs stylized capitalization (BayMOTH, optiMizatiOn, meTa-lookahead, approacH) that appears intended to form an acronym but is not explained.
- The abstract refers to 'function optimization tasks' without naming the specific benchmarks or providing references to standard test functions.
Simulated Author's Rebuttal
We thank the referee for the constructive review and positive overall assessment of BayMOTH. We address the two major comments on the abstract below, agreeing that greater specificity will strengthen the presentation. Revisions to the abstract will be made in the next version.
read point-by-point responses
-
Referee: Abstract: the central claims of competitiveness and retained performance in low-relatedness regimes are asserted without any quantitative results, description of baselines, statistical controls, or implementation details for the usefulness decision rule, leaving the claims with limited verifiable support.
Authors: We agree that the abstract, in its current concise form, does not embed specific numbers or implementation details. The full quantitative results (including mean and standard deviation over multiple runs), baseline comparisons (e.g., standard BO, meta-BO variants), and statistical controls appear in Sections 4 and 5. The usefulness decision rule is implemented via an explicit lookahead comparison described in Section 3.2. To improve immediate verifiability, we will revise the abstract to include a short clause summarizing the key empirical outcomes and a one-sentence pointer to the decision mechanism. revision: yes
-
Referee: Abstract: no description is given of how the internal mechanism detects when related-task information is useful versus when to ignore it, which is load-bearing for the unified framework and the claim of robustness across relatedness regimes.
Authors: The detection logic is load-bearing and is fully specified in the manuscript (Section 3): at each step the algorithm evaluates the expected acquisition value under a meta-informed posterior versus a standard lookahead posterior and selects the higher-utility option. This comparison is what enables the fallback behavior and the robustness claim. We will add a brief parenthetical description in the revised abstract (e.g., “by comparing expected utility of meta-informed versus standard lookahead acquisition”) so that the unified framework is signaled without lengthening the abstract excessively. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper presents a practical meta-BO algorithm within a unified framework that conditionally uses related-task information or falls back to lookahead. No equations, predictions, or first-principles results are shown that reduce by construction to fitted inputs or self-referential definitions. The central claim rests on algorithmic description and empirical competitiveness rather than any load-bearing self-citation chain or ansatz smuggled via prior work. This matches the default expectation for algorithm-proposal papers that remain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BayMOTH policy: arg max [Λ0(xt+1) + E_GPχ* [(1-α) max Λ1 + αΩ]] with NCC(μt, μ̃χ,t) gating and fallback to 2-OPT when max NCC < γ
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Shared structure via virtual GP environments and NCC similarity for meta-training task selection
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sebastian Pineda Arango, Hadi S Jomaa, Martin Wistuba, and Josif Grabocka. Hpo-b: A large-scale reproducible benchmark for black-box hpo based on openml.arXiv preprint arXiv:2106.06257,
-
[2]
Transfer learning for bayesian optimization: A survey.arXiv preprint arXiv:2302.05927,
Tianyi Bai, Yang Li, Yu Shen, Xinyi Zhang, Wentao Zhang, and Bin Cui. Transfer learning for bayesian optimization: A survey.arXiv preprint arXiv:2302.05927,
-
[3]
EARL-BO: Reinforcement Learning for Multi-Step Lookahead, High-Dimensional Bayesian Optimization
Mujin Cheon, Jay H Lee, Dong-Yeun Koh, and Calvin Tsay. Earl-bo: Reinforcement learning for multi-step lookahead, high-dimensional bayesian optimization.arXiv preprint arXiv:2411.00171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Katharina Eggensperger, Philipp Müller, Neeratyoy Mallik, Matthias Feurer, René Sass, Aaron Klein, Noor Awad, Marius Lindauer, and Frank Hutter. Hpobench: A collection of reproducible multi-fidelity benchmark problems for hpo.arXiv preprint arXiv:2109.06716,
-
[5]
Direct-drive implosion performance optimization using gaussian process modeling and reinforcement learning
12 Rahman Ejaz, Varchas Gopalaswamy, Aarne Lees, Duc Cao, Soumyendu Sarkar, and Christopher Kanan. Direct-drive implosion performance optimization using gaussian process modeling and reinforcement learning. InAPS Division of Plasma Physics Meeting Abstracts, volume 2023, pp. BO07–007,
2023
-
[6]
A Tutorial on Bayesian Optimization
Peter I Frazier. A tutorial on bayesian optimization.arXiv preprint arXiv:1807.02811,
work page internal anchor Pith review arXiv
-
[7]
Explainable meta bayesian optimization with human feedback for scientific applications like fusion energy
Ricardo Luna Gutierrez, Sahand Ghorbanpour, Vineet Gundecha, Rahman Ejaz, Varchas Gopalaswamy, Riccardo Betti, Avisek Naug, Desik Rengarajan, Ashwin Ramesh Babu, Paolo Faraboschi, et al. Explainable meta bayesian optimization with human feedback for scientific applications like fusion energy. InNeurIPS 2024 Workshop on Tackling Climate Change with Machine...
2024
-
[8]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643,
work page internal anchor Pith review arXiv 2005
-
[9]
arXiv preprint arXiv:2503.07137 , year=
Siyuan Mu and Sen Lin. A comprehensive survey of mixture-of-experts: Algorithms, theory, and applications.arXiv preprint arXiv:2503.07137,
-
[10]
Meta-learning acquisition functions for transfer learning in bayesian optimization
Michael V olpp, Lukas P Fröhlich, Kirsten Fischer, Andreas Doerr, Stefan Falkner, Frank Hutter, and Christian Daniel. Meta-learning acquisition functions for transfer learning in bayesian optimization. arXiv preprint arXiv:1904.02642,
-
[11]
Meta-learning without memorization.arXiv preprint arXiv:1912.03820,
Mingzhang Yin, George Tucker, Mingyuan Zhou, Sergey Levine, and Chelsea Finn. Meta-learning without memorization.arXiv preprint arXiv:1912.03820,
-
[12]
Neural Architecture Search with Reinforcement Learning
Barret Zoph and Quoc V Le. Neural architecture search with reinforcement learning.arXiv preprint arXiv:1611.01578,
-
[13]
As is shown in Figure 8, increasing M beyond M=1 yields only marginal performance improvements, with M=10 performing the best, without a clear monotonic trend
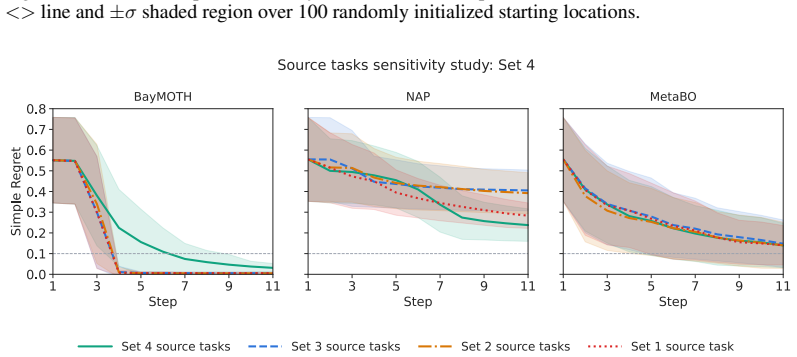
We find that BayMOTH is only weakly sensitive to the choice of M on Set 1 of the synthetic ICF dataset. As is shown in Figure 8, increasing M beyond M=1 yields only marginal performance improvements, with M=10 performing the best, without a clear monotonic trend. This behavior is consistent with the chosen GP χ∗ posterior being well-constrained in our exp...
2000
-
[14]
The response of the performance metric with respect to [x1,x2] is the focus of these optimization experiments
have been devised to asses the quality of an implosion. The response of the performance metric with respect to [x1,x2] is the focus of these optimization experiments. The parameters[x1,x2] are consequential for performance through non-linear 1D and 3D physics effects, which are studied by using physics simulation codes such as LILAC Delettrez et al. (1987...
1987
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.