Recognition: unknown
SIR-Bench: Evaluating Investigation Depth in Security Incident Response Agents
Pith reviewed 2026-05-10 15:16 UTC · model grok-4.3
The pith
SIR-Bench evaluates security agents on genuine forensic investigation depth rather than alert parroting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
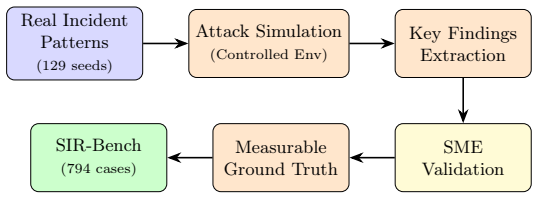
SIR-Bench, derived from 129 anonymized incident patterns with expert-validated ground truth, measures autonomous security incident response agents on triage accuracy, novel finding discovery, and tool usage appropriateness. The Once Upon A Threat framework replays the patterns in controlled cloud environments to produce authentic telemetry. An adversarial LLM-as-Judge evaluates the agents by inverting the burden of proof and requiring concrete evidence. The SIR agent under test achieves 97.1 percent true positive detection, 73.4 percent false positive rejection, and 5.67 novel key findings per case on average, establishing a baseline for future agents.
What carries the argument
The Once Upon A Threat (OUAT) replay framework that generates authentic telemetry from real incident patterns, together with the three-metric evaluation (triage accuracy, novel finding discovery, tool appropriateness) performed by an adversarial LLM-as-Judge that demands concrete forensic evidence.
Load-bearing premise
Replaying anonymized incident patterns inside controlled cloud environments produces telemetry that faithfully matches real-world security incidents, and the adversarial LLM-as-Judge reliably identifies novel findings without its own biases or errors.
What would settle it
Running the identical SIR agent on live, unreplayed security incidents and comparing its true-positive rate, false-positive rejection rate, and average number of novel findings against the SIR-Bench results.
Figures
read the original abstract
We present SIR-Bench, a benchmark of 794 test cases for evaluating autonomous security incident response agents that distinguishes genuine forensic investigation from alert parroting. Derived from 129 anonymized incident patterns with expert-validated ground truth, SIR-Bench measures not only whether agents reach correct triage decisions, but whether they discover novel evidence through active investigation. To construct SIR-Bench, we develop Once Upon A Threat (OUAT), a framework that replays real incident patterns in controlled cloud environments, producing authentic telemetry with measurable investigation outcomes. Our evaluation methodology introduces three complementary metrics: triage accuracy (M1), novel finding discovery (M2), and tool usage appropriateness (M3), assessed through an adversarial LLM-as-Judge that inverts the burden of proof -- requiring concrete forensic evidence to credit investigations. Evaluating our SIR agent on the benchmark demonstrates 97.1% true positive (TP) detection, 73.4% false positive (FP) rejection, and 5.67 novel key findings per case, establishing a baseline against which future investigation agents can be measured.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SIR-Bench, a benchmark of 794 test cases derived from 129 anonymized real-world security incident patterns with expert-validated ground truth. It presents the OUAT framework for replaying these patterns in controlled cloud environments to generate authentic telemetry, defines three metrics (M1: triage accuracy, M2: novel finding discovery via adversarial LLM-as-Judge, M3: tool usage appropriateness), and reports baseline results for the authors' SIR agent of 97.1% true positive detection, 73.4% false positive rejection, and 5.67 novel key findings per case.
Significance. If the construction and evaluation hold, this work provides a useful new benchmark that explicitly targets investigation depth rather than surface-level triage, filling a gap in security agent evaluation. The use of real incident patterns, measurable outcomes, and an adversarial judge that requires concrete evidence are positive design choices that could support reproducible progress in the field.
major comments (3)
- [Section 4] Section 4 (Evaluation Methodology): The adversarial LLM-as-Judge used to score M2 (novel key findings) is presented as inverting the burden of proof and requiring concrete forensic evidence, yet no human-expert calibration study, inter-rater reliability metrics, or agreement analysis with domain experts is reported. This directly undermines confidence in the headline 5.67 novel findings per case and the claim that the benchmark reliably distinguishes genuine investigation from alert parroting.
- [Section 3] Section 3 (Benchmark Construction): The selection criteria for the 129 incident patterns and the precise procedure used for expert validation of ground truth are not detailed (e.g., number of experts, validation protocol, or handling of ambiguous cases). Without these, reproducibility of the 794 test cases and assessment of selection bias cannot be evaluated.
- [Results] Results section: The reported performance figures (97.1% TP, 73.4% FP rejection) are given as point estimates without confidence intervals, variance across cases, or statistical significance tests relative to any baseline agent. This weakens the assertion that these numbers establish a reliable baseline for future agents.
minor comments (2)
- [Introduction] The abstract and introduction use the term 'adversarial LLM-as-Judge' without an early formal definition or pseudocode for the prompt template; moving a concise description to Section 2 would improve readability.
- [Section 3] Table or figure captions for the benchmark statistics (e.g., distribution of incident types) could explicitly state the source of the 129 patterns to aid quick assessment of coverage.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. These have highlighted important areas where additional detail and statistical rigor will strengthen the presentation of SIR-Bench. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Evaluation Methodology): The adversarial LLM-as-Judge used to score M2 (novel key findings) is presented as inverting the burden of proof and requiring concrete forensic evidence, yet no human-expert calibration study, inter-rater reliability metrics, or agreement analysis with domain experts is reported. This directly undermines confidence in the headline 5.67 novel findings per case and the claim that the benchmark reliably distinguishes genuine investigation from alert parroting.
Authors: We agree that explicit human calibration and inter-rater metrics would increase confidence in M2. The adversarial judge was intentionally designed to require concrete evidence citations before crediting any novel finding, which we believe produces a conservative assessment. In the revision we will expand Section 4 with the full judge prompt template, several annotated examples of accepted and rejected findings, and an explicit limitations paragraph noting the absence of a formal calibration study. We will also make the judge prompts and a sample of judgments publicly available to support external validation. revision: yes
-
Referee: [Section 3] Section 3 (Benchmark Construction): The selection criteria for the 129 incident patterns and the precise procedure used for expert validation of ground truth are not detailed (e.g., number of experts, validation protocol, or handling of ambiguous cases). Without these, reproducibility of the 794 test cases and assessment of selection bias cannot be evaluated.
Authors: We accept that the current description in Section 3 is insufficient for full reproducibility. We will substantially expand this section to document the selection criteria applied to the 129 patterns, the number of experts who performed validation, the exact validation protocol (including independent review steps and consensus procedures), and the process for handling ambiguous cases. These additions will allow readers to evaluate potential selection bias and replicate the benchmark construction. revision: yes
-
Referee: [Results] Results section: The reported performance figures (97.1% TP, 73.4% FP rejection) are given as point estimates without confidence intervals, variance across cases, or statistical significance tests relative to any baseline agent. This weakens the assertion that these numbers establish a reliable baseline for future agents.
Authors: We concur that reporting only point estimates limits the strength of the baseline claim. We will revise the Results section to include bootstrap 95% confidence intervals for all reported metrics, per-case variance and range statistics, and a comparison against a simple non-investigative baseline agent with appropriate statistical testing. These quantitative improvements will be added in the next version. revision: yes
Circularity Check
No significant circularity; results are direct measurements on a newly constructed benchmark
full rationale
The paper constructs SIR-Bench from 129 anonymized incident patterns via the OUAT replay framework, defines three metrics (M1 triage accuracy, M2 novel finding discovery via adversarial LLM-as-Judge, M3 tool usage), and reports empirical performance numbers (97.1% TP, 73.4% FP rejection, 5.67 findings/case) as direct outcomes of running its SIR agent on the 794 test cases. No equations or steps reduce a claimed result to a fitted parameter renamed as prediction, no self-citation chain supplies the load-bearing justification, and no ansatz or uniqueness theorem is smuggled in. The derivation is self-contained as an independent benchmark protocol whose outputs are measurements rather than tautological re-expressions of its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Anonymized real incident patterns can be replayed in controlled cloud environments to produce authentic telemetry with measurable investigation outcomes.
- domain assumption Expert-validated ground truth from 129 patterns reliably supports 794 test cases that distinguish genuine forensic investigation from alert parroting.
invented entities (3)
-
SIR-Bench
no independent evidence
-
Once Upon A Threat (OUAT)
no independent evidence
-
Adversarial LLM-as-Judge
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Cyber Defense Benchmark: Agentic Threat Hunting Evaluation for LLMs in SecOps
A new benchmark shows frontier LLMs achieve only 3.8% average recall identifying malicious events from raw logs and fail to meet 50% recall thresholds on most tactics.
Reference graph
Works this paper leans on
-
[1]
Liu, Z. SecQA: A Concise Question-Answering Dataset for Evaluating Large Language Models in Computer Security.arXiv preprint arXiv:2312.15838, 2023
- [2]
-
[3]
Vilches, Francesco Balassone, Luis Javier Navarrete-Lozano, Cristóbal R
Sanz-Gómez, M., Mayoral-Vilches, V., Balassone, F., et al. Cybersecurity AI Benchmark (CAIBench): A Meta-Benchmark for Evaluating Cybersecurity AI Agents.arXiv preprint arXiv:2510.24317, 2025
-
[4]
Liu, Z., et al. PACEbench: A Framework for Evaluating Practical AI Cyber-Exploitation Capabilities.arXiv preprint arXiv:2510.11688, 2025
-
[5]
Liu, X., Yu, F., Li, X., Yan, G., Yang, P., and Xi, Z. Benchmarking LLMs in an Embodied Environment for Blue Team Threat Hunting.arXiv preprint arXiv:2505.11901, 2025
-
[6]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Zheng, L., Chiang, W.-L., Sheng, Y., et al. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. InAdvances in Neural Information Processing Systems, 2023
2023
-
[7]
He, J., et al. LLM-as-a-Judge for Software Engineering: Literature Review, Vision, and the Road Ahead.arXiv preprint arXiv:2510.24367, 2025
-
[8]
and Hockenmaier, J
Haldar, R. and Hockenmaier, J. Rating Roulette: Self-Inconsistency in LLM-As-A-Judge Frameworks. InProceedings of EMNLP, 2025
2025
-
[9]
Security Orchestration, Automation and Response (SOAR): A Comprehensive Guide.Palo Alto Networks Technical Report, 2020
Demisto. Security Orchestration, Automation and Response (SOAR): A Comprehensive Guide.Palo Alto Networks Technical Report, 2020
2020
-
[10]
IRCopilot: Automated Incident Response with Large Language Models
Lin, X., Zhang, J., Deng, G., Liu, T., Zhang, T., Guo, Q., and Chen, R. IRCopilot: Automated Incident Response with Large Language Models. arXiv preprint arXiv:2505.20945, 2025. 12
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.