Robust Explanations for User Trust in Enterprise NLP Systems
Pith reviewed 2026-05-10 14:55 UTC · model grok-4.3
The pith
Decoder LLMs produce 73 percent lower flip rates in token explanations than encoder models under realistic input noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
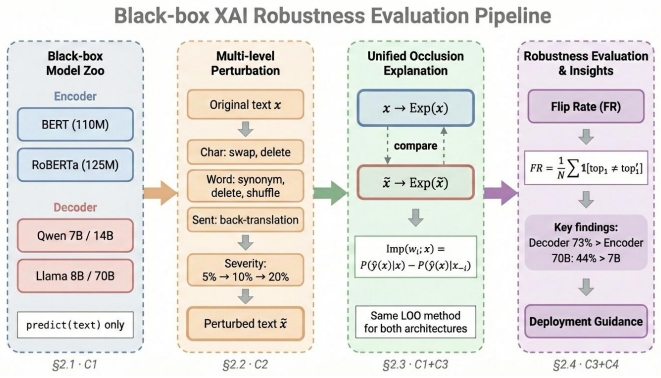
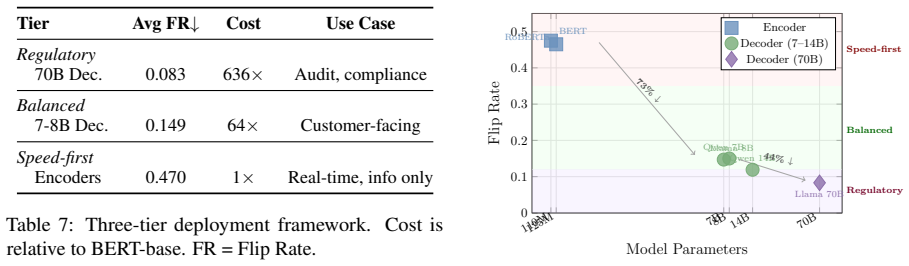
A leave-one-out occlusion protocol operationalized as top-token flip rate under multi-level perturbations demonstrates that decoder LLMs deliver substantially more stable explanations than encoder baselines, with an average 73 percent reduction in flip rates and a further 44 percent improvement when scaling from 7B to 70B parameters.
What carries the argument
Top-token flip rate under leave-one-out occlusion explanations tested against swap, deletion, shuffling, and back-translation perturbations at multiple severity levels.
If this is right
- Decoder LLMs keep their top explanatory tokens consistent even after users swap words, delete phrases, or rephrase inputs.
- Explanation stability scales upward with decoder model size, supporting the choice of larger models for compliance-sensitive tasks.
- A plotted cost-robustness curve lets teams select models and explanation methods before deployment.
- Encoder-based systems may need extra validation steps or alternative explanation techniques in noisy production environments.
Where Pith is reading between the lines
- Organizations shifting from encoders to decoders could reduce the frequency of user confusion caused by shifting explanations.
- The evaluation protocol could be applied to other explanation formats such as feature attributions or attention maps.
- Real-world deployment logs might reveal additional perturbation types that further differentiate model families.
Load-bearing premise
The selected perturbations at multiple severity levels adequately stand in for the input variations users actually produce in enterprise NLP systems.
What would settle it
A follow-up experiment that replaces the paper's perturbation set with real user typo logs or synonym substitutions and finds encoder flip rates equal to or below decoder rates would undermine the claimed stability advantage.
Figures


read the original abstract
Robust explanations are increasingly required for user trust in enterprise NLP, yet pre-deployment validation is difficult in the common case of black-box deployment (API-only access) where representation-based explainers are infeasible and existing studies provide limited guidance on whether explanations remain stable under real user noise, especially when organizations migrate from encoder classifiers to decoder LLMs. To close this gap, we propose a unified black-box robustness evaluation framework for token-level explanations based on leave-one-out occlusion, and operationalize explanation robustness with top-token flip rate under realistic perturbations (swap, deletion, shuffling, and back-translation) at multiple severity levels. Using this protocol, we conduct a systematic cross-architecture comparison across three benchmark datasets and six models spanning encoder and decoder families (BERT, RoBERTa, Qwen 7B/14B, Llama 8B/70B; 64,800 cases). We find that decoder LLMs produce substantially more stable explanations than encoder baselines (73% lower flip rates on average), and that stability improves with model scale (44% gain from 7B to 70B). Finally, we relate robustness improvements to inference cost, yielding a practical cost-robustness tradeoff curve that supports model and explanation selection prior to deployment in compliance-sensitive applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a black-box framework for evaluating the robustness of token-level explanations in NLP systems using leave-one-out occlusion. Through experiments on three benchmark datasets with six models (encoders: BERT, RoBERTa; decoders: Qwen 7B/14B, Llama 8B/70B), totaling 64,800 cases, it reports that decoder LLMs exhibit 73% lower top-token flip rates under perturbations (swap, deletion, shuffling, back-translation) compared to encoders, with a 44% improvement from 7B to 70B scale. It also provides a cost-robustness tradeoff analysis for enterprise deployment decisions.
Significance. If the perturbation protocol adequately captures real user noise, the work provides useful empirical evidence on the superior stability of explanations from decoder LLMs over encoders and the benefits of model scale, along with a practical cost-robustness curve that could inform pre-deployment choices in compliance-sensitive applications. The systematic cross-architecture comparison and large evaluation scale are strengths that enhance its potential utility for practitioners.
major comments (3)
- Abstract: The quantitative claims of 73% lower flip rates for decoders and 44% scale gain lack error bars, confidence intervals, statistical significance tests, or per-dataset breakdowns, making it impossible to assess whether the reported architecture and scale effects are reliable or generalizable.
- Evaluation Framework (or §3): The perturbations are positioned as 'realistic' for enterprise user noise to support pre-deployment guidance in compliance-sensitive applications, but no validation against actual enterprise logs, crowdsourced edits, or observed error patterns is provided; this assumption is load-bearing for the applicability of the stability claims.
- Experiments section: Full protocol details (exact severity levels for each perturbation type, dataset names and splits, and how the 64,800 cases were constructed) are insufficiently specified, preventing reproduction and independent verification of the flip-rate results.
minor comments (2)
- Abstract: Naming the three benchmark datasets explicitly would improve clarity and allow readers to immediately contextualize the results.
- Consider adding a summary table of models, datasets, perturbation types, and key metrics to aid quick reference.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to improve clarity, statistical rigor, and reproducibility.
read point-by-point responses
-
Referee: Abstract: The quantitative claims of 73% lower flip rates for decoders and 44% scale gain lack error bars, confidence intervals, statistical significance tests, or per-dataset breakdowns, making it impossible to assess whether the reported architecture and scale effects are reliable or generalizable.
Authors: We agree that the abstract would be strengthened by statistical details. In the revision we will add error bars or confidence intervals to the reported 73% and 44% figures, include the outcomes of statistical significance tests for the architecture and scale comparisons, and provide per-dataset breakdowns (either in the main text or appendix) to show consistency across the three benchmarks. revision: yes
-
Referee: Evaluation Framework (or §3): The perturbations are positioned as 'realistic' for enterprise user noise to support pre-deployment guidance in compliance-sensitive applications, but no validation against actual enterprise logs, crowdsourced edits, or observed error patterns is provided; this assumption is load-bearing for the applicability of the stability claims.
Authors: The referee is correct that we provide no direct validation against enterprise logs. Our perturbation types are drawn from commonly reported user noise patterns in the literature, but we lacked access to proprietary logs. We will revise the manuscript to qualify the perturbations as 'representative of common user-induced noise' rather than directly validated, and we will add an explicit limitations paragraph discussing the gap to real enterprise deployments. revision: partial
-
Referee: Experiments section: Full protocol details (exact severity levels for each perturbation type, dataset names and splits, and how the 64,800 cases were constructed) are insufficiently specified, preventing reproduction and independent verification of the flip-rate results.
Authors: We apologize for the missing details. The revised version will specify the exact severity levels for each perturbation (swap, deletion, shuffling, back-translation), name the datasets and their train/test splits, and provide a transparent breakdown of how the 64,800 cases were generated. We will also include a table or pseudocode to support full reproducibility. revision: yes
Circularity Check
No significant circularity; empirical results are independent of framework definition
full rationale
The paper's headline findings (73% lower flip rates for decoders, 44% scale gain) are obtained by applying a fixed, explicitly enumerated perturbation protocol (swap/deletion/shuffling/back-translation at graded severities) to LOO-occlusion explanations on six independently trained models and three benchmarks. No equation or result is defined in terms of itself; the protocol is proposed once and then executed to produce the measurements. No fitted parameters are relabeled as predictions, no uniqueness theorem is imported from prior self-work, and no ansatz is smuggled via citation. The evaluation chain is therefore self-contained and falsifiable against the stated datasets and perturbation set.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Leave-one-out occlusion identifies the most important tokens for a model's prediction
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of NAACL-HLT, pages 4171–4186. Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric ...
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[2]
Scaling Laws for Neural Language Models
Is BERT really robust? a strong baseline for natural language attack on text classification and entailment. In Proceedings of AAAI, volume 34, pages 8018–8025. Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scal- ing laws for neural language models.arXiv p...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
“Why should I trust you?”: Explaining the pre- dictions of any classifier. InProceedings of KDD, pages 1135–1144. Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D Manning, Andrew Ng, and Christopher Potts
-
[4]
LLaMA: Open and Efficient Foundation Language Models
Recursive deep models for semantic compositional- ity over a sentiment treebank. InProceedings of EMNLP, pages 1631–1642. Mukund Sundararajan, Ankur Taly, and Qiqi Yan. 2017. Ax- iomatic attribution for deep networks. InInternational Conference on Machine Learning, pages 3319–3328. Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Mar- tinet, Marie-An...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.