Mining Large Language Models for Low-Resource Language Data: Comparing Elicitation Strategies for Hausa and Fongbe
Pith reviewed 2026-05-10 15:01 UTC · model grok-4.3
The pith
Strategic prompting extracts 6-41 times more usable Hausa and Fongbe text from GPT-4o Mini than from Gemini.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By comparing six elicitation task types on GPT-4o Mini and Gemini 2.5 Flash, the authors establish that GPT-4o Mini extracts 6-41 times more usable target-language words per API call. Optimal strategies differ by language: Hausa benefits from functional text and dialogue prompts, while Fongbe requires constrained generation prompts.
What carries the argument
Systematic comparison of six elicitation task types across two commercial LLMs, scored by usable target-language words generated per API call.
If this is right
- Hausa data extraction works best with prompts that involve functional text and dialogue.
- Fongbe data extraction improves when prompts tightly constrain what the model generates.
- Commercial LLM APIs can supply scalable volumes of low-resource language text when the right model and task are chosen.
- Released corpora and code allow direct reuse or further refinement by other groups.
Where Pith is reading between the lines
- If the generated text performs well in real applications, the same prompting patterns could be tried on dozens of other low-resource languages.
- Model providers may face new questions about whether and how their training data can be repurposed for language documentation.
- Combining outputs from several models or adding light human filtering could raise quality without losing the efficiency gain.
Load-bearing premise
That text produced by the models counts as usable for downstream NLP tasks even without detailed checks against native-speaker data or error analysis.
What would settle it
Train a concrete NLP system such as a machine translation model or part-of-speech tagger on the extracted corpora and compare its accuracy to the same system trained on human-collected Hausa or Fongbe text.
Figures




read the original abstract
Large language models (LLMs) are trained on data contributed by low-resource language communities, yet the linguistic knowledge encoded in these models remains accessible only through commercial APIs. This paper investigates whether strategic prompting can extract usable text data from LLMs for two West African languages: Hausa (Afroasiatic, approximately 80 million speakers) and Fongbe (Niger-Congo, approximately 2 million speakers). We systematically compare six elicitation task types across two commercial LLMs (GPT-4o Mini and Gemini 2.5 Flash). GPT-4o Mini extracts 6-41 times more usable target-language words per API call than Gemini. Optimal strategies differ by language: Hausa benefits from functional text and dialogue, while Fongbe requires constrained generation prompts. We release all generated corpora and code.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates strategic prompting to extract usable text data from commercial LLMs (GPT-4o Mini and Gemini 2.5 Flash) for Hausa and Fongbe. It compares six elicitation task types and reports that GPT-4o Mini yields 6-41 times more usable target-language words per API call than Gemini, with language-specific optimal strategies (functional text and dialogue for Hausa; constrained generation for Fongbe). All generated corpora and code are released.
Significance. If the usability of extracted words is rigorously validated, the work offers a practical, scalable approach to addressing data scarcity for low-resource languages by mining LLMs, with potential impact on NLP for West African languages. The empirical comparison across models and strategies, combined with the open release of data and code, supports reproducibility and further investigation.
major comments (3)
- [Abstract and Results] Abstract and Results: The central quantitative claim (GPT-4o Mini extracts 6-41 times more usable words per API call) depends entirely on the authors' internal judgment of 'usable' target-language words, yet no section describes the criteria, human validation by native speakers, inter-annotator agreement, error typology, or comparison against gold native-speaker text.
- [Methods] Methods: The six elicitation task types are introduced but lack sufficient detail on exact prompt templates, how 'constrained generation' or 'functional text' were operationalized differently per language, total API calls made, or any post-generation filtering steps, preventing independent assessment of the reported multipliers and strategy rankings.
- [Results] Results: No quantitative quality metrics (e.g., grammaticality scores, perplexity on held-out data, or downstream task performance lift) are reported for the extracted words; the released corpora are offered for inspection, but the paper itself supplies none, leaving the language-specific optimal-strategy claims unsupported by evidence beyond the authors' unvalidated counts.
minor comments (2)
- [Abstract] Abstract: Speaker population figures ('approximately 80 million' for Hausa, '2 million' for Fongbe) are stated without citation; adding references would improve context.
- The manuscript would benefit from an explicit Limitations section discussing risks of LLM hallucinations, code-switching, or dialectal bias in the generated text for these languages.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight important areas for improving the clarity and rigor of our work. We address each major comment below and specify the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and Results] The central quantitative claim (GPT-4o Mini extracts 6-41 times more usable words per API call) depends entirely on the authors' internal judgment of 'usable' target-language words, yet no section describes the criteria, human validation by native speakers, inter-annotator agreement, error typology, or comparison against gold native-speaker text.
Authors: We agree that the definition and assessment of 'usable' words requires explicit documentation. In the revised manuscript, we will add a dedicated subsection in Methods that defines the usability criteria (predominantly target-language content with coherent structure and minimal code-switching) and provides concrete examples of usable versus non-usable outputs for both languages. We did not perform formal native-speaker validation, inter-annotator agreement, or error typology analysis, as the study prioritized comparative elicitation efficiency over corpus validation. We will add this as an explicit limitation and note that the released corpora enable independent validation by others. No direct comparison to gold native text was conducted. revision: partial
-
Referee: [Methods] The six elicitation task types are introduced but lack sufficient detail on exact prompt templates, how 'constrained generation' or 'functional text' were operationalized differently per language, total API calls made, or any post-generation filtering steps, preventing independent assessment of the reported multipliers and strategy rankings.
Authors: We acknowledge the need for greater methodological transparency. The revised manuscript will include all six exact prompt templates in a new appendix. We will also expand the Methods section to describe the language-specific operationalization of each strategy (including differences in constraints for Hausa versus Fongbe), report the precise number of API calls per model-language-strategy combination, and detail all post-generation steps such as duplicate removal and basic language filtering. revision: yes
-
Referee: [Results] No quantitative quality metrics (e.g., grammaticality scores, perplexity on held-out data, or downstream task performance lift) are reported for the extracted words; the released corpora are offered for inspection, but the paper itself supplies none, leaving the language-specific optimal-strategy claims unsupported by evidence beyond the authors' unvalidated counts.
Authors: We recognize that additional metrics would provide stronger support. In the revision, we will report basic quantitative indicators in Results, such as the percentage of target-language tokens (via automated detection) and average text length per strategy. We did not compute grammaticality scores, perplexity, or downstream task performance, as suitable benchmarks and held-out data for Hausa and Fongbe are limited and would have required resources outside the scope of this elicitation-focused study. We will discuss this limitation and emphasize that the open corpora facilitate such analyses. The strategy rankings remain grounded in the yield of usable words, which will be better supported by the expanded Methods details. revision: partial
Circularity Check
No circularity: purely empirical counts from API experiments
full rationale
The paper conducts a direct empirical comparison of six prompting strategies across two LLMs, measuring usable target-language words per API call via explicit filtering criteria applied to generated outputs. No equations, derivations, fitted parameters, or self-citations are invoked as load-bearing premises. The central results (multipliers of 6-41x and language-specific strategy rankings) are computed from observed token counts rather than any self-referential definition or renamed input. The work is self-contained against external benchmarks: replication requires only repeating the documented prompts against the same commercial APIs. No step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Natural Language Processing (NLP) technologies remain largely inaccessible to speakers of most African languages due to severe data scarcity (Joshi et al., 2020). Languages such as Fongbe, a national language of Benin, and Hausa, widely spoken across West Africa, suffer from limited digital text resources despite having millions of speakers. ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[2]
How does the linguistic quality of LLM- generated text vary across elicitation task types for Hausa and Fongbe?
-
[3]
Which elicitation strategies produce the great- est lexical diversity and domain coverage per API call?
-
[4]
Do optimal elicitation strategies differ between languages with different levels of LLM sup- port? 1.2. Summary of Contributions •A systematic taxonomy of LLM elicitation strategies for low-resource language data ex- traction,evaluatedacrosssixtasktypesfortwo typologically distinct West African languages (Section 3). •An empirical comparison of two commer...
-
[5]
Related Work 2.1. African Language NLP Resources Research on African language technology has ac- celerated significantly since 2019. The Masakhane project established a participatory approach to machine translation across more than 30 African languages (Nekoto et al., 2020). Subse- quent efforts produced standardized benchmarks: MasakhaNER 2.0 for NER acr...
work page 2019
-
[6]
Conti- nentalsurveysconfirmthatmostAfricanlanguages lacksufficientcorpora(Hedderichetal.,2021)
given its international media presence, while Fongbe falls closer to the lowest tiers (0–1). Conti- nentalsurveysconfirmthatmostAfricanlanguages lacksufficientcorpora(Hedderichetal.,2021). Our workproposesLLM-baseddataextractionasascal- able complement to manual corpus construction. 2.2. LLMs for Low-Resource Languages Robinson et al. (2023) showed that C...
work page 2021
-
[7]
how well do LLMs translate into lan- guage X?
outperform multilingual baselines but focus on comprehension rather than generation. A critical gap persists: none of these studies investigate whichtypesof prompts maximize ex- tractable language data. Our work reframes the question from “how well do LLMs translate into lan- guage X?” to “which prompting strategies extract the most usable data from LLMs ...
work page 2019
-
[8]
Methodology We design a controlled experiment comparing six elicitation task types across two LLMs and two lan- guages. All prompts, scripts, and evaluation code arereleasedpublicly(see AppendixA).Fullprompt structures and examples are provided in Appendix D. 3.1. Elicitation Task Taxonomy Table 1 summarizes six task types, each probing a different dimens...
work page 2000
-
[9]
Results We report results from 600 API calls (150 prompts ×2 models×2 languages). 4.1. Output Validity Table 2 reports the percentage of outputs exceed- ing the 20-token minimum and the average word count per condition. Gemini GPT-4o Mini Task Fon Hau Fon Hau Creative 28/18 76/27 100/90 100/104 Functional 36/17 68/20 100/153 100/205 Structured 40/18 56/20...
-
[10]
Discussion 5.1. Optimal Elicitation Strategies by Language Our results confirm that optimal strategies differ substantially between languages (RQ3). ForHausa, functional text and dialogue yield the most usable words (190–205 per call with GPT-4o Mini), while constrained generation and topicswitchingachievethehighestlanguagefidelity (100% for both models)....
work page 2023
-
[11]
Conclusion and Future Work We presented an exploratory evaluation of six LLM elicitation strategies for extracting usable text data forHausaandFongbe. Whilethescaleofthisstudy is limited, our initial findings suggest three trends worth investigating further. First, GPT-4o Mini pro- duces substantially more usable text than Gemini 2.5 Flash, yielding 6× mo...
-
[12]
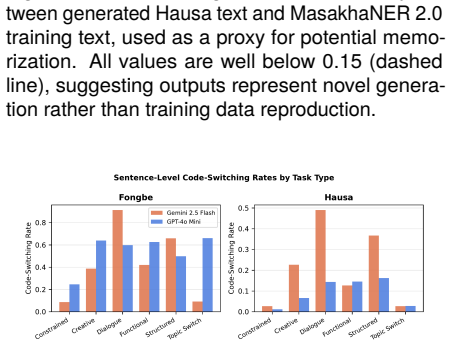
Limitations This study has several limitations. First, we eval- uate only two commercial LLMs; the performance gapweobservemaynotgeneralizetoopen-source or African-language-focused models. Second, our evaluation relies entirely on automatic metrics; hu- man evaluation by native speakers is essential, particularly for Fongbe where GlotLID misidenti- fies 4...
-
[13]
Ourworkaimstoredirectencoded knowledge back to these communities
Ethics Statement Data provenance and community benefit.We acknowledge that LLMs were trained on data con- tributed by language communities, often without explicitconsent. Ourworkaimstoredirectencoded knowledge back to these communities. All gener- ated data will be released under CC-BY-4.0. Quality and potential harms.LLM-generated text may contain errors...
-
[14]
Data and Code Availability All generated corpora, prompts, generation scripts, and evaluation code will be made publicly available upon acceptance under a CC-BY-4.0 license. The evaluation pipeline, including the GlotLID-based language fidelity assessment, is provided for full reproducibility
-
[15]
Acknowledgements The authors thank the reviewers for their construc- tive feedback. We acknowledge the Masakhane community for their foundational contributions to African NLP resources, particularly the MasakhaNER 2.0 and MasakhaPOS datasets used in our evaluation. This publication was developed as part of the Center for Inclusive Digital Transformation o...
-
[16]
Bibliographical References David Adelani, Jesujoba Alabi, Angela Fan, Julia Kreutzer, et al. 2022a. A few thousand trans- lations go a long way! Leveraging pre-trained models for African news translation. InProceed- ings of the 2022 Conference of the North Ameri- canChapteroftheAssociationforComputational Linguistics. Association for Computational Lin- gu...
work page 2022
-
[17]
Fikira: Multilingual reasoning dataset for Africanlanguages. MasakhaneProjectTechnical Report. David Adelani, Graham Neubig, Sebastian Ruder, Shruti Rijhwani, Michael Beukman, Chester Palen-Michel, Constantine Lignos, Jesujoba Al- abi, Shamsuddeen Muhammad, Peter Nabende, Cheikh Dione, et al. 2022b. MasakhaNER 2.0: Africa-centric transfer learning for nam...
-
[18]
Available: https://arxiv.org/abs/2003.11529
GlotLID: Language identification for low-resource languages. https: //huggingface.co/cis-lmu/glotlid. Version 1.0. Claire Lefebvre and Anne-Marie Brousseau. 2002. A Grammar of Fongbe. Mouton de Gruyter, Berlin. Wilhelmina Nekoto, Vukosi Marivate, Tshinondiwa Matsila, Timi Fasubaa, et al. 2020. Participatory research for low-resourced machine translation: ...
-
[19]
Improvingneuralmachinetranslationmod- els with monolingual data. InProceedings of the 54th Annual Meeting of the Association for Com- putational Linguistics. Association for Computa- tional Linguistics. JasonWeiandKaiZou.2019. EDA:Easydataaug- mentation techniques for boosting performance on text classification tasks. InProceedings of the 2019 Conference ...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.