Recognition: unknown
Rethinking Uncertainty in Segmentation: From Estimation to Decision
Pith reviewed 2026-05-10 16:08 UTC · model grok-4.3
The pith
Uncertainty estimates in medical segmentation improve safety only when linked to specific deferral decision policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
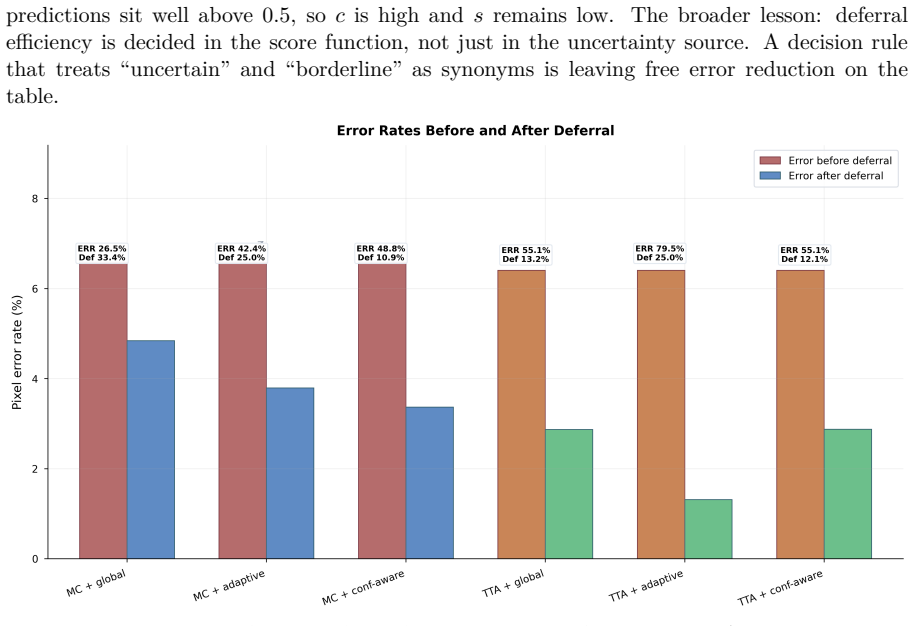
The paper establishes that optimizing uncertainty alone fails to capture most of the achievable safety gains in segmentation. Using Monte Carlo Dropout and Test-Time Augmentation combined with three deferral strategies on retinal vessel benchmarks, the best method and policy combination removes up to 80 percent of segmentation errors at only 25 percent pixel deferral while achieving strong cross-dataset robustness. Calibration improvements do not translate to better decision quality, highlighting a disconnect between standard uncertainty metrics and real-world utility. These findings suggest that uncertainty should be evaluated based on the decisions it enables, rather than in isolation.
What carries the argument
A two-stage pipeline of uncertainty estimation followed by a decision policy that converts uncertainty maps into pixel-level actions such as acceptance or deferral.
If this is right
- Uncertainty optimization by itself misses most of the achievable safety gains from the overall pipeline.
- Calibration metrics do not serve as reliable proxies for decision quality under deferral policies.
- A simple confidence-aware deferral rule that prioritizes uncertain low-confidence predictions delivers strong error reduction with limited deferral.
- The performance of well-matched method and policy pairs transfers across different retinal vessel datasets.
Where Pith is reading between the lines
- The same estimation-to-decision framing could be tested on other medical imaging tasks to check whether the observed disconnect generalizes.
- Custom decision policies tuned to specific clinical costs of errors versus deferrals might unlock additional gains beyond the strategies examined.
- Papers reporting uncertainty estimates could begin including decision-quality metrics to make their claims more directly actionable.
Load-bearing premise
The tested uncertainty sources and deferral strategies are representative enough to conclude that optimizing uncertainty alone generally fails to capture safety gains.
What would settle it
An experiment on a new segmentation task or dataset where refining uncertainty estimates alone produces higher decision quality than any of the tested policy combinations.
Figures








read the original abstract
In medical image segmentation, uncertainty estimates are often reported but rarely used to guide decisions. We study the missing step: how uncertainty maps are converted into actionable policies such as accepting, flagging, or deferring predictions. We formulate segmentation as a two-stage pipeline, estimation followed by decision, and show that optimizing uncertainty alone fails to capture most of the achievable safety gains. Using retinal vessel segmentation benchmarks (DRIVE, STARE, CHASE_DB1), we evaluate two uncertainty sources (Monte Carlo Dropout and Test-Time Augmentation) combined with three deferral strategies, and introduce a simple confidence-aware deferral rule that prioritizes uncertain and low-confidence predictions. Our results show that the best method and policy combination removes up to 80 percent of segmentation errors at only 25 percent pixel deferral, while achieving strong cross-dataset robustness. We further show that calibration improvements do not translate to better decision quality, highlighting a disconnect between standard uncertainty metrics and real-world utility. These findings suggest that uncertainty should be evaluated based on the decisions it enables, rather than in isolation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that uncertainty in medical image segmentation should be assessed through its impact on downstream decision policies rather than in isolation. Formulating segmentation as estimation followed by decision, it evaluates MC Dropout and Test-Time Augmentation uncertainty sources with three deferral strategies (including a proposed confidence-aware rule) on the DRIVE, STARE, and CHASE_DB1 retinal vessel datasets, reporting that the best combinations remove up to 80% of errors at 25% pixel deferral with cross-dataset robustness, while finding that calibration gains do not improve decision quality.
Significance. If the empirical findings hold under broader testing, the work would usefully demonstrate a practical disconnect between standard uncertainty metrics and safety outcomes in decision-making, supporting a shift toward policy-oriented evaluation of uncertainty methods in medical imaging. The concrete deferral results and public-benchmark evaluation provide a useful baseline, though the narrow method and dataset scope limits immediate generalizability.
major comments (2)
- [Abstract] Abstract: the claim that 'optimizing uncertainty alone fails to capture most of the achievable safety gains' and that 'calibration improvements do not translate to better decision quality' rests on experiments using only two uncertainty estimators (MC Dropout, TTA) and three deferral strategies across three closely related binary retinal-vessel datasets. This selection leaves open whether other estimators (e.g., deep ensembles) or policies would close the observed gap, or whether the disconnect persists on multi-class or non-retinal tasks; the general conclusion therefore requires additional experiments to be load-bearing.
- [Abstract] Abstract / Results: the reported figures (80% error removal at 25% deferral, cross-dataset robustness) are presented without error bars, statistical significance tests, or variance across random seeds, making it impossible to assess whether the performance differences between uncertainty sources and policies are reliable.
minor comments (1)
- [Abstract] Abstract: the term 'strong cross-dataset robustness' would benefit from explicit quantification (e.g., mean and std of Dice or error-removal rates across the three datasets) for precision.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our claims and the statistical presentation of results. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'optimizing uncertainty alone fails to capture most of the achievable safety gains' and that 'calibration improvements do not translate to better decision quality' rests on experiments using only two uncertainty estimators (MC Dropout, TTA) and three deferral strategies across three closely related binary retinal-vessel datasets. This selection leaves open whether other estimators (e.g., deep ensembles) or policies would close the observed gap, or whether the disconnect persists on multi-class or non-retinal tasks; the general conclusion therefore requires additional experiments to be load-bearing.
Authors: We agree that the experiments are confined to MC Dropout and TTA on binary retinal vessel segmentation. Our study deliberately focuses on these standard estimators and a controlled set of deferral policies to isolate the effect of the decision stage. The core contribution is the demonstration that policy-oriented evaluation reveals safety gains not captured by uncertainty optimization or calibration alone; we do not claim universality across all estimators or tasks. In revision we will qualify the abstract and add an explicit limitations paragraph stating that broader validation with ensembles or multi-class data remains future work, while preserving the load-bearing status of the reported disconnect within the evaluated setting. revision: partial
-
Referee: [Abstract] Abstract / Results: the reported figures (80% error removal at 25% deferral, cross-dataset robustness) are presented without error bars, statistical significance tests, or variance across random seeds, making it impossible to assess whether the performance differences between uncertainty sources and policies are reliable.
Authors: We accept this criticism. The revised manuscript will report means and standard deviations over multiple random seeds for all key metrics, include error bars on the primary figures, and add paired statistical significance tests between the best policy combinations and baselines. These additions will allow readers to evaluate the reliability of the 80% error removal and cross-dataset results. revision: yes
Circularity Check
No circularity: purely empirical evaluation on public benchmarks
full rationale
The paper frames segmentation as a two-stage estimation-then-decision pipeline and reports results from evaluating two off-the-shelf uncertainty estimators (MC Dropout, TTA) plus three deferral policies on three standard retinal vessel datasets. No equations, fitted parameters, or predictions are defined in terms of the target quantities; no self-citations are used to justify load-bearing claims; and no ansatz or uniqueness theorem is invoked. All reported metrics (error removal at given deferral rates, cross-dataset robustness, calibration-decision disconnect) are direct empirical measurements, not reductions to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Monte Carlo Dropout and Test-Time Augmentation produce reliable uncertainty estimates for segmentation
- domain assumption Retinal vessel segmentation benchmarks are representative for evaluating decision policies
Reference graph
Works this paper leans on
-
[1]
TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation
Jieneng Chen, Yongyi Lu, Qihang Yu, Xiangde Luo, Ehsan Adeli, Yan Wang, Le Lu, Alan L Yuille, and Yuyin Zhou. TransUNet: Transformers make strong encoders for medical image segmentation. InarXiv preprint arXiv:2102.04306,
work page internal anchor Pith review arXiv
-
[2]
Learning Confidence for Out -of-Distribution Detection in Neural Networks,
Terrance DeVries and Graham W Taylor. Learning confidence for out-of-distribution detection in neural networks. InarXiv preprint arXiv:1802.04865,
-
[3]
Max-Heinrich Laves, Sontje Ihler, Jacob F Fast, Lena A Kahrs, and Tobias Ortmaier. Well- calibrated prediction uncertainty in medical imaging with scaled prediction sets.arXiv preprint arXiv:2006.10824,
-
[4]
B.5 Runtime breakdown Table 9:Per-image runtime breakdown on DRIVE (mean over 20 images)
and decile plot (Figure 5b) reflect. B.5 Runtime breakdown Table 9:Per-image runtime breakdown on DRIVE (mean over 20 images). Forward passes dominate total cost; aggregation and deferral scoring are negligible. Best (fastest) per row in bold. Component MC Drop. (T=30) TTA (K=6) Ensemble (N=5) Determ. Preprocessing 0.005s 0.005s 0.005s 0.005s Forward pass...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.