Recognition: unknown
Towards Scalable Lightweight GUI Agents via Multi-role Orchestration
Pith reviewed 2026-05-10 13:41 UTC · model grok-4.3
The pith
Lightweight 3B multimodal models can handle complex real-world GUI tasks through multi-role orchestration after targeted data synthesis and two-stage training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The LAMO framework endows a lightweight MLLM with GUI-specific knowledge and task scalability, allowing multi-role orchestration to expand its capability boundary for GUI automation. LAMO combines role-oriented data synthesis with a two-stage training recipe: supervised fine-tuning with Perplexity-Weighted Cross-Entropy optimization for knowledge distillation and visual perception enhancement, and reinforcement learning for role-oriented cooperative exploration. With LAMO, we develop a task-scalable native GUI agent, LAMO-3B, supporting monolithic execution and MAS-style orchestration. When paired with advanced planners as a plug-and-play policy executor, LAMO-3B can continuously benefit.
What carries the argument
The LAMO framework, which uses role-oriented data synthesis plus Perplexity-Weighted Cross-Entropy supervised fine-tuning followed by reinforcement learning for cooperative role exploration.
If this is right
- LAMO-3B can run GUI automation tasks by itself in a single monolithic execution mode.
- The same model can be dropped into multi-agent systems as a reusable policy executor.
- Performance can keep rising whenever a stronger planner is attached without retraining the executor.
- The approach avoids the cost of training and maintaining many separate expert models for different GUI skills.
- The resulting agent remains deployable on resource-constrained devices while still participating in realistic workflows.
Where Pith is reading between the lines
- The same role-synthesis plus staged-training pattern could be tested on other agent domains that currently require large models or many specialists.
- If the method works, it would make GUI automation tools cheaper to run on ordinary phones and laptops rather than servers.
- Developers might now experiment with adding new roles or planners without rebuilding the entire agent from scratch each time.
Load-bearing premise
Role-oriented data synthesis together with the two-stage training recipe can overcome the limited capacity of a lightweight model for complex real-world GUI tasks without needing separate skill-specific expert models.
What would settle it
A head-to-head online evaluation on a broad set of in-the-wild GUI tasks where LAMO-3B fails to match the success rate or adaptability of either a much larger single model or a system built from multiple skill-specific experts.
Figures










read the original abstract
Autonomous Graphical User Interface (GUI) agents powered by Multimodal Large Language Models (MLLMs) enable digital automation on end-user devices. While scaling both parameters and data has yielded substantial gains, advanced methods still suffer from prohibitive deployment costs on resource-constrained devices. When facing complex in-the-wild scenarios, lightweight GUI agents are bottlenecked by limited capacity and poor task scalability under end-to-end episodic learning, impeding adaptation to multi-agent systems (MAS), while training multiple skill-specific experts remains costly. Can we strike an effective trade-off in this cost-scalability dilemma, enabling lightweight MLLMs to participate in realistic GUI workflows? To address these challenges, we propose the LAMO framework, which endows a lightweight MLLM with GUI-specific knowledge and task scalability, allowing multi-role orchestration to expand its capability boundary for GUI automation. LAMO combines role-oriented data synthesis with a two-stage training recipe: (i) supervised fine-tuning with Perplexity-Weighted Cross-Entropy optimization for knowledge distillation and visual perception enhancement, and (ii) reinforcement learning for role-oriented cooperative exploration. With LAMO, we develop a task-scalable native GUI agent, LAMO-3B, supporting monolithic execution and MAS-style orchestration. When paired with advanced planners as a plug-and-play policy executor, LAMO-3B can continuously benefit from planner advances, enabling a higher performance ceiling. Extensive static and online evaluations validate the effectiveness of our design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the LAMO framework to enable scalable lightweight GUI agents. It combines role-oriented data synthesis with a two-stage training recipe—perplexity-weighted cross-entropy supervised fine-tuning for knowledge distillation and visual perception enhancement, followed by reinforcement learning for role-oriented cooperative exploration—to produce LAMO-3B, a 3B MLLM-based agent. This agent supports both monolithic execution and MAS-style orchestration and can serve as a plug-and-play policy executor paired with advanced planners. Effectiveness is asserted via static and online evaluations.
Significance. If the empirical results hold, the work could be significant by offering a practical trade-off in the cost-scalability dilemma for GUI automation: lightweight models could handle complex in-the-wild tasks through multi-role orchestration without the expense of larger models or multiple skill-specific experts, while benefiting from ongoing planner improvements.
major comments (1)
- Abstract: the central claim that the two-stage recipe (perplexity-weighted CE SFT then RL) endows a lightweight MLLM with sufficient GUI-specific knowledge and task scalability to overcome capacity limits for complex tasks rests on the assertion of 'extensive static and online evaluations' validating the design, yet the text supplies no quantitative results, baselines, metrics, or error analysis. This leaves the claim only weakly supported and makes it impossible to assess whether monolithic vs. MAS execution modes or the training choices actually expand the capability boundary.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. The feedback highlights an important opportunity to strengthen the presentation of our results. We address the major comment point by point below.
read point-by-point responses
-
Referee: Abstract: the central claim that the two-stage recipe (perplexity-weighted CE SFT then RL) endows a lightweight MLLM with sufficient GUI-specific knowledge and task scalability to overcome capacity limits for complex tasks rests on the assertion of 'extensive static and online evaluations' validating the design, yet the text supplies no quantitative results, baselines, metrics, or error analysis. This leaves the claim only weakly supported and makes it impossible to assess whether monolithic vs. MAS execution modes or the training choices actually expand the capability boundary.
Authors: We agree that the abstract would benefit from including concrete quantitative highlights to make the central claim more immediately verifiable. The full manuscript already contains the requested elements: Section 4 (Experiments) reports static and online evaluations with explicit baselines (including prior GUI agents and larger MLLMs), metrics (task success rate, efficiency, and error breakdowns), and direct comparisons of monolithic versus MAS-style orchestration. These results show that the two-stage training enables LAMO-3B to close much of the gap to larger models on complex in-the-wild tasks. To address the referee's concern, we will revise the abstract to incorporate 2-3 key quantitative findings (e.g., success-rate improvements and MAS gains) while preserving its length and focus. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical training framework (role-oriented data synthesis + perplexity-weighted CE SFT followed by RL) for a 3B MLLM GUI agent, with claims validated by static and online evaluations. No mathematical derivations, predictions, or first-principles results are presented that reduce by construction to fitted inputs or self-citations. The central claims rest on experimental outcomes rather than tautological redefinitions or load-bearing self-references. This is a standard empirical methods paper with no detectable circular steps.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Reinforcement Learning for LLM-based Multi-Agent Systems through Orchestration Traces
This survey organizes RL for LLM multi-agent systems into reward families, credit units, and five orchestration sub-decisions, notes the absence of explicit stopping-decision training in its paper pool, and releases a...
Reference graph
Works this paper leans on
-
[1]
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu
Navigating the digital world as humans do: Universal visual grounding for gui agents.arXiv preprint arXiv:2410.05243. Ming Gu, Ziwei Wang, Sicen Lai, Zirui Gao, Sheng Zhou, and Jiajun Bu. 2026. Towards scalable web ac- cessibility audit with mllms as copilots. InProceed- ings of the AAAI Conference on Artificial Intelligence, volume 40, pages 38515–38523....
-
[2]
Memory in the Age of AI Agents
Memory in the age of ai agents.Preprint, arXiv:2512.13564. Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276. Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Sc...
work page internal anchor Pith review arXiv 2024
-
[3]
GUI-R1 : A Generalist R1-Style Vision-Language Action Model For GUI Agents
Gui-r1: A generalist r1-style vision-language action model for gui agents.arXiv preprint arXiv:2504.10458. China Mobile. 2025. Jt-guiagent-v1: A planner- grounder agent for reliable gui interaction. Project Website. OpenAI. 2025a. Developing a generalist computer- using agent. OpenAI. 2025b. Gpt-5.1 model overview. Internal model release; no peer-reviewed...
work page internal anchor Pith review arXiv 2025
-
[4]
A survey on (m) llm-based gui agents.arXiv preprint arXiv:2504.13865, 2025
Os-genesis: Automating gui agent trajectory construction via reverse task synthesis. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 5555–5579. Fei Tang, Haolei Xu, Hang Zhang, Siqi Chen, Xingyu Wu, Yongliang Shen, Wenqi Zhang, Guiyang Hou, Zeqi Tan, Yuchen Yan, Kaitao Song, Jian...
-
[5]
Kimi-vl technical report.arXiv preprint arXiv:2504.07491. Tesseract OCR. 2025. Tesseract OCR: Tesseract open source ocr engine. https://github.com/ tesseract-ocr/tesseract. Accessed: 2025-12- 15. Unotools. 2025. Unotools 0.3.3. https://pypi.org/ project/unotools/. Python Package Index. Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen...
work page internal anchor Pith review arXiv 2025
-
[6]
OS-ATLAS: A Foundation Action Model for Generalist GUI Agents
Os-atlas: A foundation action model for gener- alist gui agents.arXiv preprint arXiv:2410.23218. Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, and 1 others
work page internal anchor Pith review arXiv
-
[7]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040–52094. Yiheng Xu, Zekun Wang, Junli Wang, Dunjie Lu, Tian- bao Xie, Amrita Saha, Doyen Sahoo, Tao Yu, and Caiming Xiong. 2024. Aguvis: Unified pure vision agents for autonomous gui interaction.arXiv prepri...
-
[8]
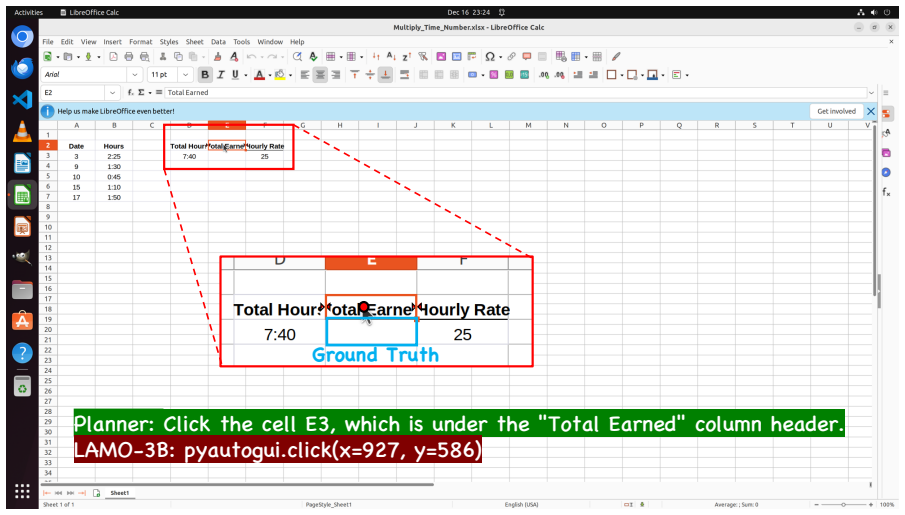
**Screenshot**: the current screenshot image
-
[9]
**Action Space**: a list of available action tools and their descriptions
-
[10]
to the right of the search bar
**Atomic Action**: the low-level action to be executed . Here are some instructions for you: **1) Ground the target** - Identify the most likely UI element/region corresponding to the action. - Use the screenshot to name the element (button / icon / tab / input box / list item / link). - Add distinguishing clues: visible text, icon meaning, color, shape, ...
-
[11]
the predicted action shows
**Previous Actions**: A list of actions that have been taken so far. 2) **Former thought**: A description of the thought process of the previous action. 3) **Goal**: A description of the task to be accomplished. 4) **ATOMIC ACTION**: The predicted next action, including operation type and parameters, in pyautogui format. 5) **Full Screenshot**: A screensh...
-
[12]
Your principle: Your task is to guide that model to generate the **Thought** based only on the **Goal**, **Previous Actions**, **ATOMIC ACTION** and the Screenshot
-
[13]
(ii)Do not infer the target from the mouse position
For mouse-related actions: (i)Ignore the mouse position in the screenshot. (ii)Do not infer the target from the mouse position. (iii) Mouse position is irrelevant and provides no valid clue
-
[14]
(ii)Merge repetitive actions (such as multiple spaces, backspaces, deletes, or enters) into one description, and specify the exact number
For text editing or input-related actions: (i)Observe the cursor position to understand where the user is preparing to type or edit text. (ii)Merge repetitive actions (such as multiple spaces, backspaces, deletes, or enters) into one description, and specify the exact number. (iii) Infer the user’s true intent and predict what the final text will look lik...
-
[15]
Do not mention any predicted action or mouse position
**Extremely important**: The output must contain only logical, executable instructions derived from the ’goal’, task context, and action history. Do not mention any predicted action or mouse position
-
[16]
Search for the item,
**Extremely important**: The output Thought must be written as a single continuous paragraph of reasoning, like natural self-talk, not divided into bullet points or numbered sections. You must strictly follow this structure in your answer. ====== OUTPUT **Thought**: Output your rigorous and comprehensive thinking process. 17 The Prompt for GP Data Synthes...
2092
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.