Recognition: unknown
ReConText3D: Replay-based Continual Text-to-3D Generation
Pith reviewed 2026-05-10 13:47 UTC · model grok-4.3
The pith
ReConText3D uses a compact replay memory of text embeddings to let text-to-3D models learn new categories while retaining old generation ability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
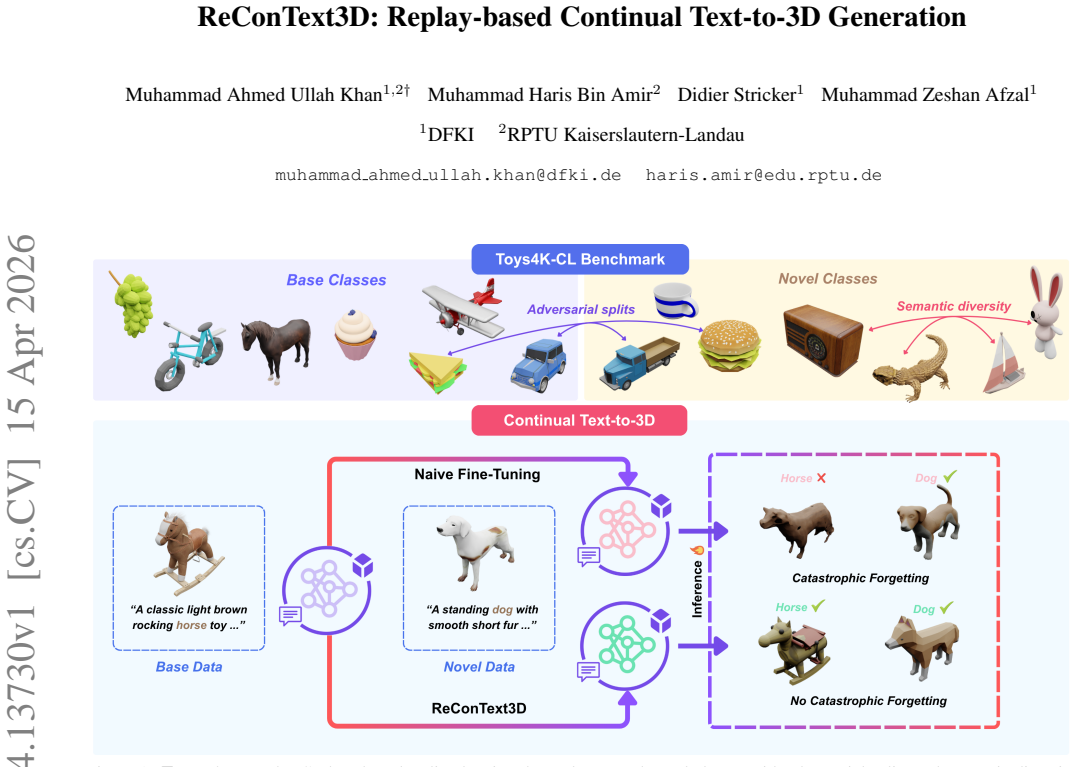
ReConText3D is the first framework for continual text-to-3D generation. It first shows that existing text-to-3D models suffer catastrophic forgetting when trained incrementally on new categories. The method then constructs a compact and diverse replay memory by applying k-center selection directly to text embeddings, enabling the model to learn new 3D categories from textual descriptions while preserving synthesis quality for prior assets. Experiments on the Toys4K-CL benchmark, built from balanced and semantically diverse splits of the Toys4K dataset, demonstrate consistent outperformance over baselines across multiple generative backbones.
What carries the argument
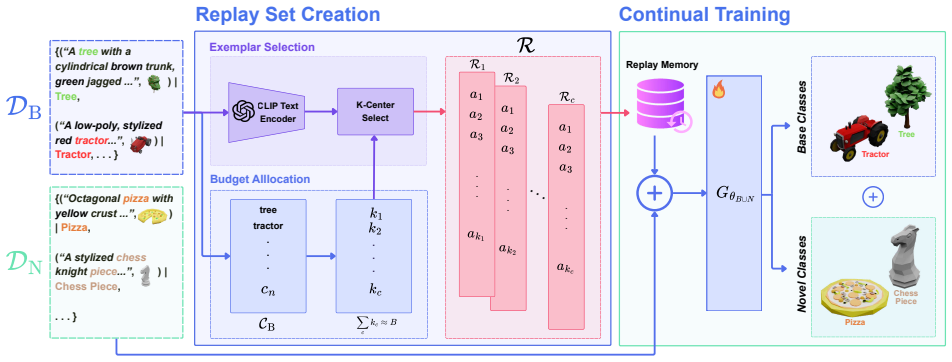
Compact replay memory formed by k-center clustering on text embeddings, which selects representative prior examples for rehearsal during new class training.
If this is right
- Generative models can be updated with new textual descriptions of 3D objects over time without complete retraining.
- Generation quality for both previously seen and newly added classes stays high on balanced incremental splits.
- The same replay selection works across different text-to-3D backbones without any model-specific modifications.
- A dedicated benchmark now exists for measuring how well continual learning methods perform in the text-to-3D setting.
Where Pith is reading between the lines
- The success of text-only selection for replay suggests that semantic information in embeddings is already sufficient to capture the diversity needed for 3D shape rehearsal.
- Similar replay buffers could be tested in related generation tasks such as text-to-image or text-to-video where forgetting is also observed.
- Future extensions might combine the buffer with lightweight regularization or dynamic buffer sizing to further reduce storage while preserving performance.
- This approach could support practical systems that grow libraries of 3D assets by adding categories as new descriptive text becomes available.
Load-bearing premise
That a compact replay buffer selected solely by k-center clustering on text embeddings is sufficient to rehearse and retain the full generative capability for prior classes without any architectural changes or additional regularization.
What would settle it
If incremental training on new classes using only the k-center text-embedding replay buffer still produces large drops in generation quality for old classes on the Toys4K-CL splits, or if models without the replay show no forgetting at all, the central claim would not hold.
Figures









read the original abstract
Continual learning enables models to acquire new knowledge over time while retaining previously learned capabilities. However, its application to text-to-3D generation remains unexplored. We present ReConText3D, the first framework for continual text-to-3D generation. We first demonstrate that existing text-to-3D models suffer from catastrophic forgetting under incremental training. ReConText3D enables generative models to incrementally learn new 3D categories from textual descriptions while preserving the ability to synthesize previously seen assets. Our method constructs a compact and diverse replay memory through text-embedding k-Center selection, allowing representative rehearsal of prior knowledge without modifying the underlying architecture. To systematically evaluate continual text-to-3D learning, we introduce Toys4K-CL, a benchmark derived from the Toys4K dataset that provides balanced and semantically diverse class-incremental splits. Extensive experiments on the Toys4K-CL benchmark show that ReConText3D consistently outperforms all baselines across different generative backbones, maintaining high-quality generation for both old and new classes. To the best of our knowledge, this work establishes the first continual learning framework and benchmark for text-to-3D generation, opening a new direction for incremental 3D generative modeling. Project page is available at: https://mauk95.github.io/ReConText3D/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ReConText3D, the first framework for continual text-to-3D generation. It shows that existing text-to-3D models suffer catastrophic forgetting under incremental training, then proposes a replay-based approach that builds a compact replay buffer via k-center clustering on text embeddings to rehearse prior classes without any architectural modifications or extra regularization. A new benchmark Toys4K-CL is introduced with balanced class-incremental splits from Toys4K, and experiments across generative backbones demonstrate consistent outperformance on both old and new classes.
Significance. If the central empirical claims hold, the work is significant as the first systematic treatment of continual learning for text-to-3D generation. It contributes a new benchmark (Toys4K-CL) and demonstrates that a simple, architecture-agnostic replay strategy can mitigate forgetting in this domain. Credit is due for the reproducible benchmark construction and the empirical validation across multiple backbones; these elements provide a concrete foundation for future incremental 3D generative modeling research.
major comments (2)
- [Method] Method (replay memory construction via text-embedding k-Center selection): the central claim that a small buffer of texts chosen solely by k-center clustering in CLIP-style embedding space is sufficient to retain full prior-class generative capability is load-bearing. Because the underlying text-to-3D model maps text to 3D geometry/appearance via score distillation or latent optimization, semantic text embeddings can group prompts that produce visually dissimilar 3D assets; rehearsal on only the selected texts therefore risks under-sampling the learned output manifold. The manuscript should include an ablation that isolates the k-center component (e.g., random text selection or storing a few generated latents) to verify that the reported retention of old-class quality is not an artifact of the specific Toys4K-CL splits.
- [Experiments] Experiments section (Toys4K-CL results): while consistent outperformance across backbones is reported, the manuscript provides no details on run-to-run variance, statistical significance tests, or confidence intervals. In addition, no ablation specifically removes or replaces the k-center selection step itself. These omissions make it difficult to assess whether the gains are robust or merely plausible on the chosen benchmark splits.
minor comments (1)
- [Abstract] Abstract: the description of Toys4K-CL would benefit from a brief statement of the number of classes, the incremental split sizes, and the precise metrics used for old-class retention.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below. We agree that additional ablations and statistical reporting will strengthen the paper and will incorporate them in the revised manuscript.
read point-by-point responses
-
Referee: [Method] Method (replay memory construction via text-embedding k-Center selection): the central claim that a small buffer of texts chosen solely by k-center clustering in CLIP-style embedding space is sufficient to retain full prior-class generative capability is load-bearing. Because the underlying text-to-3D model maps text to 3D geometry/appearance via score distillation or latent optimization, semantic text embeddings can group prompts that produce visually dissimilar 3D assets; rehearsal on only the selected texts therefore risks under-sampling the learned output manifold. The manuscript should include an ablation that isolates the k-center component (e.g., random text selection or storing a few generated latents) to verify that the reported retention of old-class quality is not an artifact of the specific Toys4K-CL splits.
Authors: We acknowledge the referee's concern that CLIP-style text embeddings may not perfectly align with visual dissimilarities in generated 3D assets. Our design choice is grounded in the observation that text-to-3D models are conditioned directly on these embeddings, so selecting diverse prompts in embedding space provides a principled way to cover the input distribution without architecture-specific modifications. To directly address the risk of under-sampling, we will add a new ablation in the revised manuscript that compares k-center selection against random text selection and, where feasible given memory constraints, against replay of generated latents. This will confirm that the reported retention on Toys4K-CL is attributable to the k-center strategy rather than benchmark-specific artifacts. revision: yes
-
Referee: [Experiments] Experiments section (Toys4K-CL results): while consistent outperformance across backbones is reported, the manuscript provides no details on run-to-run variance, statistical significance tests, or confidence intervals. In addition, no ablation specifically removes or replaces the k-center selection step itself. These omissions make it difficult to assess whether the gains are robust or merely plausible on the chosen benchmark splits.
Authors: We agree that the absence of variance reporting and an explicit ablation of the k-center component limits the ability to assess robustness. In the revised manuscript we will report all main results as means over multiple independent runs with standard deviations and 95% confidence intervals. We will also add statistical significance tests (e.g., paired t-tests against baselines) for key metrics. In addition, we will include a dedicated ablation that replaces k-center selection with random text sampling to isolate its contribution on the Toys4K-CL splits. revision: yes
Circularity Check
No significant circularity; empirical method validated on new benchmark
full rationale
The paper proposes ReConText3D as an empirical framework for continual text-to-3D generation: it applies standard k-center clustering on text embeddings to build a replay buffer, demonstrates catastrophic forgetting in existing models, and reports outperformance on the introduced Toys4K-CL benchmark across generative backbones. No load-bearing step reduces by construction to a fitted parameter, self-definition, or self-citation chain; the replay heuristic is presented as a practical choice and evaluated externally via experiments rather than derived tautologically from its own inputs. The derivation chain consists of method description plus benchmark results, remaining self-contained against external validation.
Axiom & Free-Parameter Ledger
free parameters (1)
- k (number of centers in k-Center selection)
Reference graph
Works this paper leans on
-
[1]
Foundation model-powered 3d few-shot class in- cremental learning via training-free adaptor
Sahar Ahmadi, Ali Cheraghian, Morteza Saberi, Md Towsif Abir, Hamidreza Dastmalchi, Farookh Hussain, and Shafin Rahman. Foundation model-powered 3d few-shot class in- cremental learning via training-free adaptor. InProceedings of the Asian Conference on Computer Vision, pages 2282– 2299, 2024. 3
2024
-
[2]
Building Normalizing Flows with Stochastic Interpolants
Michael S Albergo and Eric Vanden-Eijnden. Building nor- malizing flows with stochastic interpolants.arXiv preprint arXiv:2209.15571, 2022. 2
work page internal anchor Pith review arXiv 2022
-
[3]
End-to-end incremental learning
Francisco Manuel Castro Pay ´an, Manuel J Mar ´ın-Jim´enez, Nicol´as Guil-Mata, Cordelia Schmid, Karteek Alahari, et al. End-to-end incremental learning. 2018. 3
2018
-
[4]
Riemannian walk for incremen- tal learning: Understanding forgetting and intransigence
Arslan Chaudhry, Puneet K Dokania, Thalaiyasingam Ajan- than, and Philip HS Torr. Riemannian walk for incremen- tal learning: Understanding forgetting and intransigence. In Proceedings of the European conference on computer vision (ECCV), pages 532–547, 2018. 2, 3
2018
-
[5]
Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation
Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fan- tasia3d: Disentangling geometry and appearance for high- quality text-to-3d content creation. InProceedings of the IEEE/CVF international conference on computer vision, pages 22246–22256, 2023. 2
2023
-
[6]
3dtopia-xl: Scaling high- quality 3d asset generation via primitive diffusion
Zhaoxi Chen, Jiaxiang Tang, Yuhao Dong, Ziang Cao, Fangzhou Hong, Yushi Lan, Tengfei Wang, Haozhe Xie, Tong Wu, Shunsuke Saito, et al. 3dtopia-xl: Scaling high- quality 3d asset generation via primitive diffusion. InPro- ceedings of the Computer Vision and Pattern Recognition Conference, pages 26576–26586, 2025. 2
2025
-
[7]
Learning without mem- orizing
Prithviraj Dhar, Rajat Vikram Singh, Kuan-Chuan Peng, Ziyan Wu, and Rama Chellappa. Learning without mem- orizing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5138–5146,
-
[8]
I3dol: Incremental 3d object learning without catas- trophic forgetting
Jiahua Dong, Yang Cong, Gan Sun, Bingtao Ma, and Lichen Wang. I3dol: Incremental 3d object learning without catas- trophic forgetting. InProceedings of the AAAI conference on artificial intelligence, pages 6066–6074, 2021. 3
2021
-
[9]
How to continually adapt text-to-image diffusion models for flexible customization?Advances in Neural In- formation Processing Systems, 37:130057–130083, 2024
Jiahua Dong, Wenqi Liang, Hongliu Li, Duzhen Zhang, Meng Cao, Henghui Ding, Salman H Khan, and Fahad Shah- baz Khan. How to continually adapt text-to-image diffusion models for flexible customization?Advances in Neural In- formation Processing Systems, 37:130057–130083, 2024. 3
2024
-
[10]
Learning a unified classifier incrementally via rebalancing
Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a unified classifier incrementally via rebalancing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 831–839,
-
[11]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
A survey on text-to-3d contents generation in the wild.arXiv preprint arXiv:2405.09431, 2024
Chenhan Jiang. A survey on text-to-3d contents generation in the wild.arXiv preprint arXiv:2405.09431, 2024. 2
-
[13]
Shap-e: Generating conditional 3d implicit functions
Heewoo Jun and Alex Nichol. Shap-e: Generat- ing conditional 3d implicit functions.arXiv preprint arXiv:2305.02463, 2023. 2, 4, 6, 1
-
[14]
Generative ai meets 3d: A survey on text-to-3d in aigc era.arXiv preprint arXiv:2305.06131, 2023
Chenghao Li, Chaoning Zhang, Joseph Cho, Atish Wagh- wase, Lik-Hang Lee, Francois Rameau, Yang Yang, Sung- Ho Bae, and Choong Seon Hong. Generative ai meets 3d: A survey on text-to-3d in aigc era.arXiv preprint arXiv:2305.06131, 2023. 2
-
[15]
Learning without forgetting
Zhizhong Li and Derek Hoiem. Learning without forgetting. IEEE transactions on pattern analysis and machine intelli- gence, 40(12):2935–2947, 2017. 2, 3
2017
-
[16]
Luciddreamer: Towards high- fidelity text-to-3d generation via interval score matching
Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiao- gang Xu, and Yingcong Chen. Luciddreamer: Towards high- fidelity text-to-3d generation via interval score matching. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 6517–6526, 2024. 2
2024
-
[17]
Magic3d: High-resolution text-to-3d content creation
Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 300–309, 2023. 2
2023
-
[18]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximil- ian Nickel, and Matt Le. Flow matching for generative mod- eling.arXiv preprint arXiv:2210.02747, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Scalable 3d captioning with pretrained models
Tiange Luo, Chris Rockwell, Honglak Lee, and Justin Johnson. Scalable 3d captioning with pretrained models. Advances in Neural Information Processing Systems, 36: 75307–75337, 2023. 6
2023
-
[21]
Packnet: Adding mul- tiple tasks to a single network by iterative pruning
Arun Mallya and Svetlana Lazebnik. Packnet: Adding mul- tiple tasks to a single network by iterative pruning. InPro- ceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 7765–7773, 2018. 3
2018
-
[22]
Piggy- back: Adapting a single network to multiple tasks by learn- ing to mask weights
Arun Mallya, Dillon Davis, and Svetlana Lazebnik. Piggy- back: Adapting a single network to multiple tasks by learn- ing to mask weights. InProceedings of the European con- ference on computer vision (ECCV), pages 67–82, 2018. 3
2018
-
[23]
Catastrophic inter- ference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic inter- ference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, pages 109–165. Elsevier, 1989. 2
1989
-
[24]
Learning to remember: A synaptic plasticity driven framework for continual learning
Oleksiy Ostapenko, Mihai Puscas, Tassilo Klein, Patrick Jah- nichen, and Moin Nabi. Learning to remember: A synaptic plasticity driven framework for continual learning. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11321–11329, 2019. 3
2019
-
[25]
Continual lifelong learning with 9 neural networks: A review.Neural networks, 113:54–71,
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with 9 neural networks: A review.Neural networks, 113:54–71,
-
[26]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Milden- hall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022. 2
work page internal anchor Pith review arXiv 2022
-
[27]
Chao Qi, Jianqin Yin, Meng Chen, Yingchun Niu, and Yuan Sun. Boosting the class-incremental learning in 3d point clouds via zero-collection-cost basic shape pre- training.arXiv preprint arXiv:2504.08412, 2025. 3
-
[28]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017. 2, 7
2017
-
[29]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 2, 4, 6, 1
2021
-
[30]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE con- ference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017. 2, 3
2001
-
[31]
Continual learning in 3d point clouds: Employing spectral techniques for exemplar selec- tion
Hossein Resani, Behrooz Nasihatkon, and Moham- madreza Alimoradi Jazi. Continual learning in 3d point clouds: Employing spectral techniques for exemplar selec- tion. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 2921–2931. IEEE, 2025. 3
2025
-
[32]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
2022
-
[33]
Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Raz- van Pascanu, and Raia Hadsell. Progressive neural networks. arXiv preprint arXiv:1606.04671, 2016. 3
work page internal anchor Pith review arXiv 2016
-
[34]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022. 2
2022
-
[35]
Continual learning with deep generative replay.Advances in neural information processing systems, 30, 2017
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay.Advances in neural information processing systems, 30, 2017. 3
2017
- [36]
-
[37]
Using shape to categorize: Low-shot learning with an explicit shape bias
Stefan Stojanov, Anh Thai, and James M Rehg. Using shape to categorize: Low-shot learning with an explicit shape bias. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 1798–1808, 2021. 2, 4, 1
2021
-
[38]
Create your world: Lifelong text-to- image diffusion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(9):6454–6470, 2024
Gan Sun, Wenqi Liang, Jiahua Dong, Jun Li, Zhengming Ding, and Yang Cong. Create your world: Lifelong text-to- image diffusion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(9):6454–6470, 2024. 3
2024
-
[39]
Rethinking the inception archi- tecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception archi- tecture for computer vision. InProceedings of the IEEE con- ference on computer vision and pattern recognition, pages 2818–2826, 2016. 7
2016
-
[40]
arXiv preprint arXiv:2309.16653 , year=
Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. Dreamgaussian: Generative gaussian splatting for effi- cient 3d content creation.arXiv preprint arXiv:2309.16653,
-
[41]
Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior
Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. Make-it-3d: High-fidelity 3d creation from a single image with diffusion prior. InPro- ceedings of the IEEE/CVF international conference on com- puter vision, pages 22819–22829, 2023. 2
2023
-
[42]
The surprising positive knowledge transfer in contin- ual 3d object shape reconstruction
Anh Thai, Stefan Stojanov, Zixuan Huang, and James M Rehg. The surprising positive knowledge transfer in contin- ual 3d object shape reconstruction. In2022 International Conference on 3D Vision (3DV), pages 209–218. IEEE,
-
[43]
Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.Advances in neural information processing systems, 36: 8406–8441, 2023
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distilla- tion.Advances in neural information processing systems, 36: 8406–8441, 2023. 2
2023
-
[44]
Memory replay gans: Learning to generate new categories without forgetting.Advances in neural information processing systems, 31, 2018
Chenshen Wu, Luis Herranz, Xialei Liu, Joost Van De Wei- jer, Bogdan Raducanu, et al. Memory replay gans: Learning to generate new categories without forgetting.Advances in neural information processing systems, 31, 2018. 3
2018
-
[45]
Structured 3d latents for scalable and versatile 3d gen- eration
Jianfeng Xiang, Zelong Lv, Sicheng Xu, Yu Deng, Ruicheng Wang, Bowen Zhang, Dong Chen, Xin Tong, and Jiaolong Yang. Structured 3d latents for scalable and versatile 3d gen- eration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21469–21480, 2025. 2, 4, 5, 6, 1
2025
-
[46]
Explicit inductive bias for transfer learning with convolutional net- works
LI Xuhong, Yves Grandvalet, and Franck Davoine. Explicit inductive bias for transfer learning with convolutional net- works. InInternational conference on machine learning, pages 2825–2834. PMLR, 2018. 6, 1
2018
-
[47]
Contin- ual learning through synaptic intelligence
Friedemann Zenke, Ben Poole, and Surya Ganguli. Contin- ual learning through synaptic intelligence. InInternational conference on machine learning, pages 3987–3995. PMLR,
-
[48]
Static-dynamic co-teaching for class-incremental 3d object detection
Na Zhao and Gim Hee Lee. Static-dynamic co-teaching for class-incremental 3d object detection. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3436– 3445, 2022. 2, 3
2022
-
[49]
Sdcot++: Improved static-dynamic co- teaching for class-incremental 3d object detection.IEEE Transactions on Image Processing, 2024
Na Zhao, Peisheng Qian, Fang Wu, Xun Xu, Xulei Yang, and Gim Hee Lee. Sdcot++: Improved static-dynamic co- teaching for class-incremental 3d object detection.IEEE Transactions on Image Processing, 2024. 2
2024
-
[50]
Ziyuan Zhao, Mingxi Xu, Peisheng Qian, Ramanpreet Singh Pahwa, and Richard Chang. Da-cil: Towards domain adap- tive class-incremental 3d object detection.arXiv preprint arXiv:2212.02057, 2022. 3 10 ReConText3D: Replay-based Continual Text-to-3D Generation Supplementary Material This supplementary document provides additional de- tails supporting the main ...
-
[51]
Additional Details on Toys4K-CL Bench- mark In this section, we present the additional details regarding ourToys4K-CL Benchmark. Benchmark details.Toys4K-CL consists of 45 base and 45 novel classes selected to maximize semantic diversity while preserving the natural long-tailed distribution of the Toys4K dataset [37]. Based on an analysis of the dataset’s...
-
[52]
Figure 8 shows that our count-aware allocation mitigates long-tail bias by allowing smooth budget growth while preventing large classes from monopolizing memory
Additional Details on ReConText3D Replay Creation Our ReConText3D replay strategy provides a principled balance between semantic coverage and class proportion- ality of the replayed examplers. Figure 8 shows that our count-aware allocation mitigates long-tail bias by allowing smooth budget growth while preventing large classes from monopolizing memory
-
[53]
Base-class performance.Table 3 reports class-wise CLIP [29] scores on base-class assets for bothTRELLIS- XL[45] (left) andShap-E[13] (right) across the base- lines
Additional Quantitative Results In this section, we provide detailed class-wise CLIP scores for both base and novel categories on the Toys4K-CL benchmark, complementing the aggregated results in the main paper. Base-class performance.Table 3 reports class-wise CLIP [29] scores on base-class assets for bothTRELLIS- XL[45] (left) andShap-E[13] (right) acros...
-
[54]
Additional Qualitative Results In this section, we provide extended qualitative compar- isons. While CLIP scores are a useful metric for semantic alignment, qualitative inspection remains essential for as- sessing geometric fidelity, texture realism, structural consis- tency, and the extent of catastrophic forgetting in continual text-to-3D generation. Ba...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.