Recognition: no theorem link
Chinese Essay Rhetoric Recognition Using LoRA, In-context Learning and Model Ensemble
Pith reviewed 2026-05-15 01:10 UTC · model grok-4.3
The pith
LLMs using LoRA fine-tuning, in-context learning, JSON outputs and ensembles achieve first place in Chinese essay rhetoric recognition.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
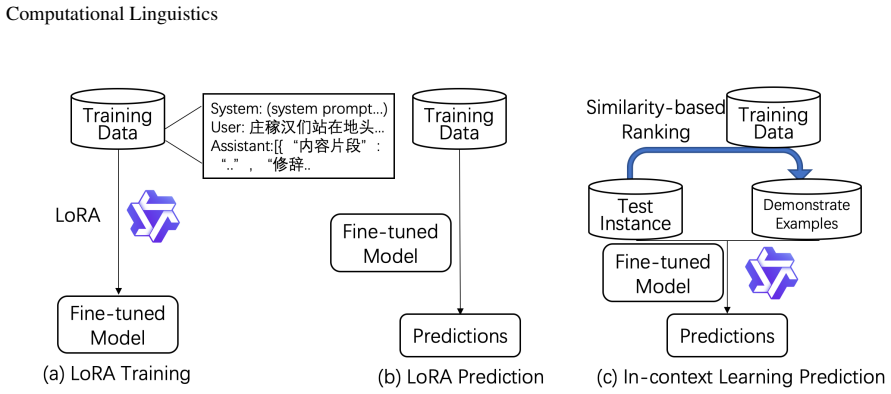
By applying LoRA-based fine-tuning and in-context learning to large language models, formulating recognition results as JSON with Chinese keys, and applying model ensemble methods, the system reaches the best performance on all three tracks of the CCL 2025 Chinese essay rhetoric recognition task and wins first prize.
What carries the argument
LoRA fine-tuning plus in-context examples that produce JSON-structured rhetoric labels, combined through model ensembles.
If this is right
- Rhetoric labels produced in JSON format can be fed directly into downstream automated essay scoring systems.
- Translating output keys to Chinese improves readability and integration for Chinese-language education tools.
- Ensemble methods raise robustness when individual models miss subtle rhetorical devices.
- The same adaptation pattern can be reused for other language-specific writing-analysis tasks without full retraining.
Where Pith is reading between the lines
- The approach may extend to real-time feedback loops in classroom writing platforms where teachers receive instant rhetoric breakdowns.
- Reducing reliance on massive fine-tuning datasets could make rhetoric recognition feasible for smaller institutions or less-resourced languages.
- If JSON outputs prove stable, similar structured prompting could be tested on related tasks such as argument mining or coherence detection in student texts.
Load-bearing premise
The specific mix of LoRA, selected in-context examples, JSON formatting, and ensembles will keep high accuracy on new student essays that differ from the competition data.
What would settle it
Run the same pipeline on a fresh collection of Chinese student essays collected outside the CCL 2025 dataset and measure whether accuracy drops below the reported competition scores.
Figures
read the original abstract
Rhetoric recognition is a critical component in automated essay scoring. By identifying rhetorical elements in student writing, AI systems can better assess linguistic and higher-order thinking skills, making it an essential task in the area of AI for education. In this paper, we leverage Large Language Models (LLMs) for the Chinese rhetoric recognition task. Specifically, we explore Low-Rank Adaptation (LoRA) based fine-tuning and in-context learning to integrate rhetoric knowledge into LLMs. We formulate the outputs as JSON to obtain structural outputs and translate keys to Chinese. To further enhance the performance, we also investigate several model ensemble methods. Our method achieves the best performance on all three tracks of CCL 2025 Chinese essay rhetoric recognition evaluation task, winning the first prize.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a pipeline for Chinese essay rhetoric recognition that integrates LoRA fine-tuning of LLMs, in-context learning with JSON-structured outputs (keys translated to Chinese), and multiple model-ensemble strategies. The central empirical claim is that this combination secured first place on all three tracks of the CCL 2025 competition.
Significance. If the reported competition result holds under the organizers' held-out evaluation, the work supplies concrete evidence that parameter-efficient adaptation plus structured prompting and ensembling can deliver state-of-the-art performance on a domain-specific classification task in educational NLP. The external validation supplied by the competition setting strengthens the practical significance for automated essay scoring.
major comments (1)
- [§4.2] §4.2 (Ensemble subsection): the description of how ensemble weights or voting thresholds were selected is insufficient to determine whether they were tuned on the official validation split or post-hoc on competition feedback; this directly affects the load-bearing claim that the reported first-place scores reflect the method rather than tuning artifacts.
minor comments (3)
- [§3.2] The prompt templates and exact JSON schema used for in-context learning should be reproduced verbatim in an appendix to support reproducibility.
- [Tables 2-4] Table captions in the results section should explicitly state the evaluation metric (e.g., macro-F1) and the three tracks being compared.
- [§5] A short error-analysis subsection or qualitative examples of misclassified rhetorical devices would clarify the remaining failure modes without altering the central claim.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work and the constructive comment on the ensemble description. We address the point below and will revise the manuscript to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Ensemble subsection): the description of how ensemble weights or voting thresholds were selected is insufficient to determine whether they were tuned on the official validation split or post-hoc on competition feedback; this directly affects the load-bearing claim that the reported first-place scores reflect the method rather than tuning artifacts.
Authors: We agree that the original description in §4.2 was insufficiently detailed on this point. The ensemble weights and voting thresholds were determined exclusively via grid search on the official validation split released by the CCL 2025 organizers, optimizing for macro-F1; no test-set information or post-submission competition feedback was used at any stage. We will revise §4.2 to explicitly document this procedure, including the search range, the validation-based selection criterion, and the final weights assigned to each model. This addition will confirm that the reported first-place results reflect the method evaluated on held-out data rather than tuning artifacts. revision: yes
Circularity Check
No significant circularity: empirical result on external competition data
full rationale
The paper describes an empirical pipeline combining LoRA fine-tuning, in-context learning, JSON output formatting, and model ensembles for Chinese rhetoric recognition. The central claim is first-place performance on the three tracks of the CCL 2025 competition, which supplies an independent held-out test set evaluated by organizers. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The result is therefore self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- LoRA rank and alpha
- Ensemble combination weights
axioms (1)
- domain assumption LLMs can integrate rhetoric knowledge through fine-tuning and prompting
Reference graph
Works this paper leans on
-
[1]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Nee- lakantan, et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1429–1434
Jointly identifying rhetoric and implicit emotions via multi-task learning. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 1429–1434. Todd Firsich and Anthony Rios
work page 2021
- [3]
-
[4]
Yuxuan Lai, Xiajing Wang, and Wenpeng Hu
Computational approaches to the detection of lesser-known rhetorical figures: A systematic survey and research challenges.arXiv preprint arXiv:2406.16674. Yuxuan Lai, Xiajing Wang, and Wenpeng Hu
-
[5]
InThe 2023 Conference on Empirical Methods in Natural Language Processing
Making large language models better data creators. InThe 2023 Conference on Empirical Methods in Natural Language Processing. Chunhong Li and Yongquan Li
work page 2023
-
[6]
InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6744–6759
Cerd: A comprehensive chinese rhetoric dataset for rhetorical understanding and generation in essays. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 6744–6759. Man Luo, Xin Xu, Yue Liu, Panupong Pasupat, and Mehran Kazemi
work page 2024
-
[7]
Structuredrag: Json response formatting with large language models
Structuredrag: Json response formatting with large language models.arXiv preprint arXiv:2408.11061. Computational Linguistics An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al
-
[8]
Qwen2.5 technical report.arXiv preprint arXiv:2412.15115. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Dawei Zhu, Qiusi Zhan, Zhejian Zhou, Yifan Song, Jiebin Zhang, and Sujian Li
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.