Recognition: unknown
The Cost of Language: Centroid Erasure Exposes and Exploits Modal Competition in Multimodal Language Models
Pith reviewed 2026-05-10 13:21 UTC · model grok-4.3
The pith
Centroid replacement shows language representations overshadow vision in multimodal models, costing four times more accuracy when erased.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
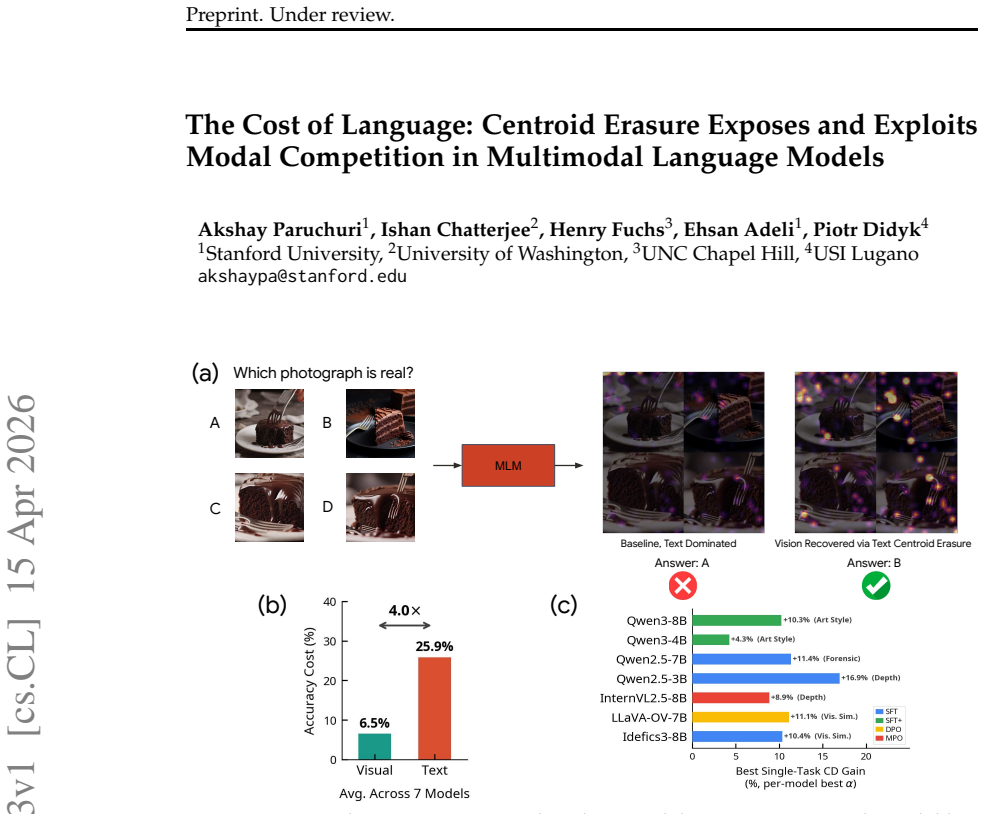
Replacing every token with its nearest K-means centroid erases modal-specific structure in a controlled way; doing so for text reduces accuracy four times more than doing so for vision across architectures, exposing a universal language-over-vision imbalance. This asymmetry can be exploited at inference time through text-centroid contrastive decoding, which recovers up to 16.9 percent accuracy and yields larger gains on standard fine-tuned models than on preference-optimized ones.
What carries the argument
Centroid replacement: collapsing each token to its nearest K-means centroid to remove modal structure while preserving token identity and model architecture.
If this is right
- The language-vision imbalance appears across three architecture families and seven models.
- Text-centroid contrastive decoding improves accuracy by up to 16.9 percent on individual tasks without any retraining.
- Standard fine-tuned models gain more from the intervention (+5.6 percent on average) than preference-optimized models (+1.5 percent on average).
- Modal competition is localized enough to be diagnosed and mitigated at inference time.
Where Pith is reading between the lines
- The same centroid probe could be applied to other input modalities such as audio to test whether language similarly overshadows them.
- Training objectives could be redesigned to penalize the observed language dominance before inference-time fixes are needed.
- The magnitude of the asymmetry might serve as a running diagnostic to compare how different multimodal training regimes balance modalities.
Load-bearing premise
Replacing tokens with their nearest K-means centroids removes only the intended modal dependence without introducing other uncontrolled changes to the model's computation or representation space.
What would settle it
A controlled test in which text-centroid erasure produces accuracy drops no larger than visual-centroid erasure, or in which contrastive decoding against the text-centroid reference fails to improve performance on visual tasks.
Figures








read the original abstract
Multimodal language models systematically underperform on visual perception tasks, yet the structure underlying this failure remains poorly understood. We propose centroid replacement, collapsing each token to its nearest K-means centroid, as a controlled probe for modal dependence. Across seven models spanning three architecture families, erasing text centroid structure costs 4$\times$ more accuracy than erasing visual centroid structure, exposing a universal imbalance where language representations overshadow vision even on tasks that demand visual reasoning. We exploit this asymmetry through text centroid contrastive decoding, recovering up to +16.9% accuracy on individual tasks by contrastively decoding against a text-centroid-erased reference. This intervention varies meaningfully with training approaches: standard fine-tuned models show larger gains (+5.6% on average) than preference-optimized models (+1.5% on average). Our findings suggest that modal competition is structurally localized, correctable at inference time without retraining, and quantifiable as a diagnostic signal to guide future multimodal training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces centroid replacement—collapsing each token to its nearest K-means centroid—as a controlled probe for modal dependence in multimodal language models. Across seven models from three architecture families, it finds that erasing text centroid structure costs 4× more accuracy than erasing visual centroid structure, revealing a universal language-over-vision imbalance even on visual-reasoning tasks. The authors exploit this asymmetry via text centroid contrastive decoding, recovering up to +16.9% accuracy, with larger gains for standard fine-tuned models (+5.6% avg.) than preference-optimized ones (+1.5% avg.).
Significance. If the central empirical claims hold after controls, the work offers a practical, inference-time diagnostic and correction for modal competition in multimodal LLMs, without retraining. The cross-model consistency (seven models, three families) and the contrastive decoding intervention provide a falsifiable, quantifiable signal that could guide future training objectives. It strengthens the case that language dominance is structurally localized and correctable at inference.
major comments (2)
- [§3 (Experimental Setup)] §3 (Experimental Setup): The claim that centroid replacement isolates modal dependence rests on the assumption that the perturbation is comparable across modalities. Because language and visual tokens typically occupy differently scaled regions, collapsing to nearest centroids necessarily alters second-moment statistics (variance, norms) unequally; without an ablation that matches mean L2 displacement or applies modality-scaled isotropic noise, the reported 4× accuracy gap could arise from differential sensitivity to compression rather than intrinsic language-over-vision bias.
- [Results] Results section: The abstract and main claims assert consistent directional effects with precise quantities (4× cost, +16.9% gain) across tasks and models, yet report no error bars, statistical tests, or run-to-run variance. This leaves the central quantitative assertions under-supported and weakens the universality conclusion.
minor comments (2)
- Specify whether K-means centroids are fit jointly across modalities or separately, and report sensitivity of the 4× ratio to the choice of K.
- Clarify the exact visual-reasoning tasks and confirm that performance drops are not driven by overall token-count reduction rather than modal erasure.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the robustness of our experimental design and the strength of our quantitative claims. We respond point by point below, providing substantive clarifications and indicating where we will revise the manuscript to address the concerns.
read point-by-point responses
-
Referee: [§3 (Experimental Setup)] The claim that centroid replacement isolates modal dependence rests on the assumption that the perturbation is comparable across modalities. Because language and visual tokens typically occupy differently scaled regions, collapsing to nearest centroids necessarily alters second-moment statistics (variance, norms) unequally; without an ablation that matches mean L2 displacement or applies modality-scaled isotropic noise, the reported 4× accuracy gap could arise from differential sensitivity to compression rather than intrinsic language-over-vision bias.
Authors: We agree that language and visual embeddings can occupy regions with different scales, which might lead to unequal effects from centroid collapse on second-moment statistics. Our method applies K-means independently to text tokens and visual tokens within each model's embedding space, with the number of centroids chosen to capture the dominant structure in each modality. The 4× disparity is replicated across seven models from three distinct architecture families, which would be unlikely if the gap were solely an artifact of differential compression sensitivity. To strengthen the isolation claim, we will add an ablation in the revised manuscript that normalizes both modalities to unit variance prior to clustering and reports the resulting accuracy drops, enabling a direct comparison of perturbation magnitude. revision: yes
-
Referee: The abstract and main claims assert consistent directional effects with precise quantities (4× cost, +16.9% gain) across tasks and models, yet report no error bars, statistical tests, or run-to-run variance. This leaves the central quantitative assertions under-supported and weakens the universality conclusion.
Authors: We concur that explicit reporting of variance and statistical tests would better support the reported quantities and the universality conclusion. The main results use fixed random seeds for K-means and decoding to ensure exact reproducibility, but K-means initialization can introduce variability. In the revised manuscript we will rerun the centroid-erasure experiments with multiple seeds (reporting means and standard deviations), and we will include error bars on the contrastive-decoding gains. We will also add paired statistical tests comparing baseline versus contrastive-decoding accuracies to substantiate the +16.9% peak and the average differences between fine-tuned and preference-optimized models. revision: yes
Circularity Check
No circularity: purely empirical probe with direct measurements
full rationale
The paper introduces centroid replacement as an experimental intervention and reports accuracy deltas from applying it to text vs. visual tokens across seven models. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-referential steps appear in the abstract or described method. Claims rest on controlled empirical comparisons rather than any reduction to inputs by construction. Self-citations (if present) are not invoked as load-bearing uniqueness theorems or ansatzes. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
free parameters (1)
- K (number of K-means centroids)
Reference graph
Works this paper leans on
-
[1]
Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687, 2026
Mohammad Asadi, Jack W O’Sullivan, Fang Cao, Tahoura Nedaee, Kamyar Fardi, Fei-Fei Li, Ehsan Adeli, and Euan Ashley. Mirage the illusion of visual understanding.arXiv preprint arXiv:2603.21687,
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InEuropean Conference on Computer Vision, pp. 19–35. Springer, 2024a. Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Du...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Hidden in plain sight: Vlms overlook their visual representations.arXiv preprint arXiv:2506.08008,
URLhttps://arxiv.org/abs/2506.08008. Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pp. 148–166. Springer,
-
[5]
The anatomy of a personal health agent.arXiv preprint arXiv:2508.20148.2025
A Ali Heydari, Ken Gu, Vidya Srinivas, Hong Yu, Zhihan Zhang, Yuwei Zhang, Akshay Paruchuri, Qian He, Hamid Palangi, Nova Hammerquist, et al. The anatomy of a personal health agent.arXiv preprint arXiv:2508.20148,
-
[6]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representa- tion hypothesis.arXiv preprint arXiv:2405.07987,
-
[7]
QingYuan Jiang, Longfei Huang, and Yang Yang. Rethinking multimodal learning from the perspective of mitigating classification ability disproportion.arXiv preprint arXiv:2502.20120,
-
[8]
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models.arXiv preprint arXiv:2503.03321,
-
[9]
Mitra, A., Khanpour, H., Rosset, C., and Awadallah, A
Andrew Lee, Melanie Weber, Fernanda Vi´egas, and Martin Wattenberg. Shared global and local geometry of language model embeddings.arXiv preprint arXiv:2503.21073,
-
[10]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326,
-
[11]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Wayne Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pp. 292–305,
2023
-
[12]
arXiv preprint arXiv:2510.08510 (2025)
Jiayun Luo, Wan-Cyuan Fan, Lyuyang Wang, Xiangteng He, Tanzila Rahman, Purang Abolmaesumi, and Leonid Sigal. To sink or not to sink: Visual information pathways in large vision-language models.arXiv preprint arXiv:2510.08510,
-
[13]
Mitigating hallucinations in large vision-language models (lvlms) via language-contrastive decoding (lcd)
Avshalom Manevich and Reut Tsarfaty. Mitigating hallucinations in large vision-language models (lvlms) via language-contrastive decoding (lcd). InFindings of the Association for Computational Linguistics: ACL 2024, pp. 6008–6022,
2024
-
[14]
Isabel Papadimitriou, Huangyuan Su, Thomas Fel, Sham Kakade, and Stephanie Gil. Inter- preting the linear structure of vision-language model embedding spaces.arXiv preprint arXiv:2504.11695,
-
[15]
arXiv preprint arXiv:2406.01506 , year=
Kiho Park, Yo Joong Choe, Yibo Jiang, and Victor Veitch. The geometry of categorical and hierarchical concepts in large language models.arXiv preprint arXiv:2406.01506,
-
[16]
Jianing Qi, Jiawei Liu, Hao Tang, and Zhigang Zhu. Beyond semantics: Rediscovering spatial awareness in vision-language models.arXiv preprint arXiv:2503.17349,
-
[17]
VLMs Need Words: Vision Language Models Ignore Visual Detail In Favor of Semantic Anchors
Haz Sameen Shahgir, Xiaofu Chen, Yu Fu, Erfan Shayegani, Nael Abu-Ghazaleh, Yova Kementchedjhieva, and Yue Dong. Vlms need words: Vision language models ignore visual detail in favor of semantic anchors.arXiv preprint arXiv:2604.02486,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
arXiv preprint arXiv:2401.05654 , year=
Shengbang Tong, Ellis Brown, Penghao Wu, Sanghyun Woo, Manoj Middepogu, Sai C Akula, Jihan Yang, Shusheng Yang, Adithya Iyer, Xichen Pan, et al. Cambrian-1: A fully open, vision-centric exploration of multimodal llms.Advances in Neural Information Processing Systems, 37:87310–87356, 2024a. Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and ...
-
[19]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models.arXiv preprint arXiv:2203.11171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Mitigating modal imbalance in multimodal reasoning.arXiv preprint arXiv:2510.02608,
Chen Henry Wu, Neil Kale, and Aditi Raghunathan. Mitigating modal imbalance in multimodal reasoning.arXiv preprint arXiv:2510.02608,
-
[21]
Yuxuan Xia, Siheng Wang, and Peng Li. Sdcd: Structure-disrupted contrastive decoding for mitigating hallucinations in large vision-language models.arXiv preprint arXiv:2601.03500,
-
[22]
Hao Yin, Guangzong Si, and Zilei Wang. The mirage of performance gains: Why contrastive decoding fails to mitigate object hallucinations in mllms?arXiv preprint arXiv:2504.10020,
-
[23]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479,
work page internal anchor Pith review arXiv
-
[24]
Under review
14 Preprint. Under review. A Evaluation Details A.1 Models and Implementation We evaluate seven instruction-tuned MLMs spanning four architecture families (Qwen (Bai et al., 2025), InternVL (Chen et al., 2024c), LLaVA (Li et al., 2024), Idefics (Laurenc ¸on et al., 2024)) and three training paradigms (SFT, DPO (Rafailov et al., 2023), SFT+, MPO (Zhu et al...
2025
-
[25]
Third, the 7B scale is a practical deployment sweet spot where our inference-time intervention is most actionable
Second, it is the most widely benchmarked open MLM at this scale in the visual-perception literature (Fu et al., 2024; 2025; Deng et al., 2025; Qi et al., 2025), making our results directly comparable to prior work. Third, the 7B scale is a practical deployment sweet spot where our inference-time intervention is most actionable. Fourth, we validate univer...
2024
-
[26]
we use a standardized protocol: 2,000 held-out MS-COCO images streamed with data seed 1337, K-means fit with seed 42, αcd=1.0. Visual and text tokens are separated by their position indices (visual tokens occupy contigu- ous positions after the vision encoder projection) and centroids are fitted independently for each modality. The choice of K=256 and N=2...
2048
-
[27]
To validate this choice against the number of fitting images N as well, we ran a 30-cell N×K scaling grid (Qwen2.5-VL-7B, αcd=1.0, per-task best αinterp). The landscape is essentially flat: mean best ∆= 5.2% ± 0.4% across all 30 cells with N∈ { 1K, 2K, 5K, 10K, 20K, 50K} and K∈ {128, 256, 512, 1024, 2048}, and no monotone trend in either direction. The si...
2048
-
[28]
could inject noise into the centroid fit and inflate the apparent sufficiency of text centroids. To rule out this confound, we refit both visual and text centroids on Qwen2.5-VL-7B under three exclusion variants applied to the 2,000-image COCO cache: (i)NO DEADdrops bottom-5% norm tokens; (ii)NO SINKdrops top-1% norm tokens; (iii)NO EITHERapplies both fil...
2025
-
[29]
recovers additional gains. Table 10:Wilson 95% confidence intervals (Qwen2.5-VL-7B, fixed αinterp=0.4, αcd=1.0, K=256).Greedy decoding produces deterministic predictions; intervals reflect finite-sample binomial uncertainty, not run-to-run variance. Cohen’sh clears the conventional “small” threshold of 0.2 on Visual Similarity and sits near it on Forensic...
2024
-
[30]
Task km=42 km=800 km=1337 km=2024 km=8320σ Forensic +11.4 +10.6 +13.6 +10.6 +12.1 1.3 Vis. Sim. +10.4 +9.6 +8.9 +8.9 +9.6 0.6 Art Style +6.8 +5.1 +6.0 +7.7 +5.1 1.1 Counting +2.5 +0.8 +2.5 +1.7 +2.5 0.7 Depth +1.6 +3.2 +0.8 +2.4 +1.6 0.8 Spatial +0 +0 +0 +0.7 +0 0.3 Mean+5.5 +4.9 +5.3 +5.3 +5.2 0.2 24 Preprint. Under review. Table 14:Variance decompositio...
2024
-
[31]
Under review
7/7+6.5+25.9 4×10 42 CV-Bench+MMStar+MMVP† 7/7 —+23.2 — 0 28 VPBench 7/7+3.7+11.4 3.1×3 14 MedBLINK (general) 7/7+5.0+9.7 1.9×11 56 MedBLINK (medical) 2/2+3.1+8.0 2.5×2 16 27 Preprint. Under review. Table 18:VPBench summary (7 models × 2 tasks = 14 points).The 3.1 × aggregate asymmetry (mean text cost +11.4%, mean visual cost +3.7%) replicates the BLINK f...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.