Recognition: unknown
Step-level Denoising-time Diffusion Alignment with Multiple Objectives
Pith reviewed 2026-05-10 13:10 UTC · model grok-4.3
The pith
A step-level RL formulation lets diffusion models balance multiple objectives exactly at denoising time with no approximation error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
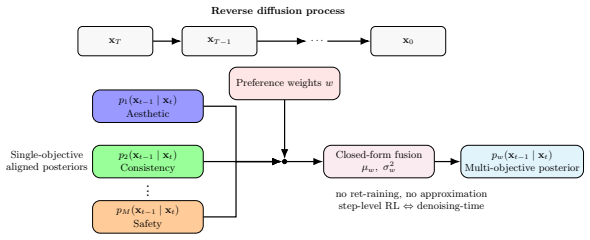
By reformulating RL fine-tuning at the step level, the optimal reverse denoising distribution for multiple objectives can be obtained in closed form directly from the mean and variance of single-objective base models. This denoising-time objective is exactly equivalent to the step-level RL fine-tuning, with no approximation error introduced.
What carries the argument
The step-level RL formulation that renders the optimal policy tractable, enabling closed-form expression of the multi-objective reverse process.
If this is right
- The optimal denoising distribution balances multiple objectives without requiring access to reward gradients during alignment.
- Alignment can be performed retraining-free by fusing base models at inference time.
- The method introduces no approximation error compared to full RL fine-tuning.
- It provides a way to handle pluralistic human preferences in diffusion generation.
- Numerical experiments show superior performance over prior denoising-time approaches.
Where Pith is reading between the lines
- This equivalence might allow dynamic switching between objectives during the generation process without additional computation.
- The framework could be extended to other iterative generative models that use reverse processes.
- It suggests that many alignment problems in generative AI can be solved through careful reformulation to enable closed-form solutions rather than optimization.
- Reducing the need for reward access could make alignment more practical in scenarios where rewards are expensive to evaluate.
Load-bearing premise
The step-level RL formulation makes identifying the optimal policy tractable for diffusion models without needing direct reward access or gradients.
What would settle it
Running both the MSDDA denoising process and a full step-level RL fine-tuned diffusion model on the same set of prompts and comparing whether the generated distributions match exactly in terms of mean and variance at each step.
Figures







read the original abstract
Reinforcement learning (RL) has emerged as a powerful tool for aligning diffusion models with human preferences, typically by optimizing a single reward function under a KL regularization constraint. In practice, however, human preferences are inherently pluralistic, and aligned models must balance multiple downstream objectives, such as aesthetic quality and text-image consistency. Existing multi-objective approaches either rely on costly multi-objective RL fine-tuning or on fusing separately aligned models at denoising time, but they generally require access to reward values (or their gradients) and/or introduce approximation error in the resulting denoising objectives. In this paper, we revisit the problem of RL fine-tuning for diffusion models and address the intractability of identifying the optimal policy by introducing a step-level RL formulation. Building on this, we further propose Multi-objective Step-level Denoising-time Diffusion Alignment (MSDDA), a retraining-free framework for aligning diffusion models with multiple objectives, obtaining the optimal reverse denoising distribution in closed form, with mean and variance expressed directly in terms of single-objective base models. We prove that this denoising-time objective is exactly equivalent to the step-level RL fine-tuning, introducing no approximation error. Moreover, we provide numerical results, which indicate our method outperforms existing denoising-time approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a step-level RL formulation to address the intractability of optimal policies in diffusion model alignment. Building on this, it proposes MSDDA, a retraining-free denoising-time framework for multi-objective alignment that derives the optimal reverse process p(x_{t-1}|x_t) in closed form, with mean and variance expressed directly from single-objective base models. The central claim is a proof that this denoising-time objective is exactly equivalent to the step-level RL fine-tuning objective with no approximation error, and experiments show it outperforms prior denoising-time fusion methods.
Significance. If the exact equivalence holds without unstated assumptions on reward decomposition or value functions, the result would be significant: it offers a principled, training-free route to pluralistic preference alignment that avoids both costly multi-objective RL and the approximation errors of existing fusion techniques. The closed-form mean/variance construction is a practical strength, and the numerical outperformance (if robust) would strengthen the case for step-level reformulations in diffusion RL.
major comments (3)
- [§3 and Theorem 1] §3 (Step-level RL formulation) and Theorem 1 (equivalence proof): The derivation claims exact equivalence between the denoising-time objective and step-level RL fine-tuning for terminal rewards defined only on x_0. However, mapping a terminal reward to per-step rewards or value functions generally requires either additive decomposition or Bellman recursion; the manuscript does not explicitly state or verify the conditions under which this mapping introduces no approximation, leaving open whether the closed-form result holds only under additional (unstated) assumptions on the reward structure.
- [§4] §4 (Closed-form derivation): The optimal reverse distribution is expressed via mean and variance of single-objective base models. It is unclear whether this expression remains exact when the base models themselves were trained with different KL regularization strengths or when the multi-objective weights are non-linear; a concrete counter-example or sensitivity analysis would strengthen the claim that no approximation error is introduced.
- [Experiments] Experimental section (numerical results): The reported outperformance over existing denoising-time approaches is promising, but the evaluation does not include an ablation on the step-level reward decomposition itself or a direct comparison against the original terminal-reward RL objective (when tractable). Without these controls it is difficult to isolate whether gains come from the exact equivalence or from other implementation choices.
minor comments (2)
- [§2-3] Notation for the step-level value function and the multi-objective fusion weights should be introduced earlier and used consistently across equations to improve readability.
- [Abstract and §1] The abstract states 'no approximation error' but the main text should include a short remark on the scope of this claim (e.g., linearity of objectives) to prevent over-generalization by readers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below, providing clarifications on the theoretical assumptions and outlining revisions to improve the manuscript.
read point-by-point responses
-
Referee: [§3 and Theorem 1] §3 (Step-level RL formulation) and Theorem 1 (equivalence proof): The derivation claims exact equivalence between the denoising-time objective and step-level RL fine-tuning for terminal rewards defined only on x_0. However, mapping a terminal reward to per-step rewards or value functions generally requires either additive decomposition or Bellman recursion; the manuscript does not explicitly state or verify the conditions under which this mapping introduces no approximation, leaving open whether the closed-form result holds only under additional (unstated) assumptions on the reward structure.
Authors: In the step-level RL formulation of §3, the terminal reward R(x_0) is mapped by setting per-step rewards r_t = 0 for all t > 0 and r_0 = R(x_0). The value function at each step is the expected terminal reward under the forward diffusion process. Because the diffusion model is Markovian, this expectation admits an exact closed-form expression that propagates the terminal reward backward without requiring additive decomposition or additional Bellman recursion beyond the standard denoising dynamics. Theorem 1 then shows that the resulting optimal reverse process is identical to the multi-objective denoising-time objective. We agree that the manuscript would benefit from an explicit statement of these conditions. We will add a clarifying paragraph in §3 that details the reward mapping and states the conditions (Markov property of the diffusion process and terminal reward on x_0) under which the equivalence holds with zero approximation error. revision: yes
-
Referee: [§4] §4 (Closed-form derivation): The optimal reverse distribution is expressed via mean and variance of single-objective base models. It is unclear whether this expression remains exact when the base models themselves were trained with different KL regularization strengths or when the multi-objective weights are non-linear; a concrete counter-example or sensitivity analysis would strengthen the claim that no approximation error is introduced.
Authors: The closed-form expressions for the mean and variance in §4 are obtained by linearly combining the optimal reverse processes of the individual single-objective base models. Because each base model already encodes its own KL regularization strength in its learned distribution, the combination remains exact irrespective of whether the base models used identical or differing KL coefficients. The current framework assumes linear weighting of objectives, which is the standard setting for multi-objective alignment; non-linear weights fall outside the scope and would generally require approximation. We will add a remark in §4 noting this scope limitation. In addition, we will include a sensitivity analysis in the revised experimental section that varies the KL strengths of the base models and reports the resulting performance, thereby demonstrating robustness of the exact equivalence. revision: partial
-
Referee: [Experiments] Experimental section (numerical results): The reported outperformance over existing denoising-time approaches is promising, but the evaluation does not include an ablation on the step-level reward decomposition itself or a direct comparison against the original terminal-reward RL objective (when tractable). Without these controls it is difficult to isolate whether gains come from the exact equivalence or from other implementation choices.
Authors: We agree that additional controls would help isolate the source of the gains. A direct comparison against the original terminal-reward RL objective is computationally intractable for high-dimensional diffusion models—the very intractability that motivates the step-level reformulation. For the ablation on step-level reward decomposition, we will add a new experiment in the revised manuscript that compares MSDDA against a baseline employing an approximate (non-exact) per-step reward decomposition. This control will allow readers to attribute performance differences specifically to the exact equivalence between the denoising-time objective and the step-level RL objective. revision: yes
Circularity Check
Step-level reformulation enables exact equivalence proof without definitional circularity
full rationale
The paper introduces a step-level RL formulation specifically to address the intractability of the optimal policy for diffusion models, then derives a closed-form denoising-time objective for multi-objective alignment and proves its exact equivalence to that step-level RL fine-tuning. This equivalence is presented as a derived result rather than a definitional identity, with the step-level view motivated independently by the need for tractability. No load-bearing self-citations, fitted parameters renamed as predictions, or ansatzes smuggled via prior work are evident in the provided claims. The multi-objective fusion via mean/variance of base models follows from the closed-form result. The derivation chain remains self-contained against external benchmarks, yielding only minor (non-load-bearing) risk of circularity at the level of the reformulation choice itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Universal guidance for diffusion models
Arpit Bansal, Hong-Min Chu, Avi Schwarzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Universal guidance for diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 843–852, 2023
2023
-
[2]
Training Diffusion Models with Reinforcement Learning
Kevin Black, Michael Janner, Yilun Du, Ilya Kostrikov, and Sergey Levine. Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301, 2023
work page internal anchor Pith review arXiv 2023
-
[3]
Three-way trade-off in multi-objective learning: Optimization, generalization and conflict-avoidance.Advances in Neural Information Processing Systems, 36:70045–70093, 2023
Lisha Chen, Heshan Fernando, Yiming Ying, and Tianyi Chen. Three-way trade-off in multi-objective learning: Optimization, generalization and conflict-avoidance.Advances in Neural Information Processing Systems, 36:70045–70093, 2023
2023
-
[4]
Min Cheng, Fatemeh Doudi, Dileep Kalathil, Mohammad Ghavamzadeh, and Panganamala R Kumar. Diffusion blend: Inference-time multi-preference alignment for diffusion models.arXiv preprint arXiv:2505.18547, 2025
-
[5]
Directly fine-tuning diffusion models on differentiable rewards.arXiv preprint arXiv:2309.17400,
Kevin Clark, Paul Vicol, Kevin Swersky, and David J Fleet. Directly fine-tuning diffusion models on differentiable rewards.arXiv preprint arXiv:2309.17400, 2023
-
[6]
Multiple-gradient descent algorithm (mgda) for multiobjective optimization.Comptes Rendus Mathematique, 350(5-6):313–318, 2012
Jean-Antoine Désidéri. Multiple-gradient descent algorithm (mgda) for multiobjective optimization.Comptes Rendus Mathematique, 350(5-6):313–318, 2012
2012
-
[7]
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models.Advances in Neural Information Processing Systems, 36:79858–79885, 2023
2023
-
[8]
Training-free multi-objective diffusion model for 3d molecule generation
Xu Han, Caihua Shan, Yifei Shen, Can Xu, Han Yang, Xiang Li, and Dongsheng Li. Training-free multi-objective diffusion model for 3d molecule generation. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[9]
Optimizing prompts for text-to-image generation.Advances in Neural Information Processing Systems, 36:66923–66939, 2023
Yaru Hao, Zewen Chi, Li Dong, and Furu Wei. Optimizing prompts for text-to-image generation.Advances in Neural Information Processing Systems, 36:66923–66939, 2023
2023
-
[10]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[11]
Stochastic solutions for linear inverse problems using the prior implicit in a denoiser.Advances in Neural Information Processing Systems, 34:13242–13254, 2021
Zahra Kadkhodaie and Eero Simoncelli. Stochastic solutions for linear inverse problems using the prior implicit in a denoiser.Advances in Neural Information Processing Systems, 34:13242–13254, 2021
2021
-
[12]
Vila: Learning image aesthetics from user comments with vision-language pretraining
Junjie Ke, Keren Ye, Jiahui Yu, Yonghui Wu, Peyman Milanfar, and Feng Yang. Vila: Learning image aesthetics from user comments with vision-language pretraining. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10041–10051, 2023
2023
-
[13]
Test-time alignment of diffusion models without reward over-optimization, 2025
Sunwoo Kim, Minkyu Kim, and Dongmin Park. Test-time alignment of diffusion models without reward over-optimization.arXiv preprint arXiv:2501.05803, 2025
-
[14]
Variational diffusion models.Advances in neural information processing systems, 34:21696–21707, 2021
Diederik Kingma, Tim Salimans, Ben Poole, and Jonathan Ho. Variational diffusion models.Advances in neural information processing systems, 34:21696–21707, 2021
2021
-
[15]
Aligning Text-to-Image Models using Human Feedback
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing Du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, and Shixiang Shane Gu. Aligning text-to-image models using human feedback.arXiv preprint arXiv:2302.12192, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Xiner Li, Yulai Zhao, Chenyu Wang, Gabriele Scalia, Gokcen Eraslan, Surag Nair, Tommaso Biancalani, Shuiwang Ji, Aviv Regev, Sergey Levine, et al. Derivative-free guidance in continuous and discrete diffusion models with soft value-based decoding.arXiv preprint arXiv:2408.08252, 2024. 12
-
[17]
Decoding-time realignment of language models
Tianlin Liu, Shangmin Guo, Leonardo Bianco, Daniele Calandriello, Quentin Berthet, Felipe Llinares, Jessica Hoffmann, Lucas Dixon, Michal Valko, and Mathieu Blondel. Decoding-time realignment of language models. arXiv preprint arXiv:2402.02992, 2024
-
[18]
Deradiff: Denoising time realignment of diffusion models, 2026
Ratnavibusena Don Shahain Manujith, Teoh Tze Tzun, Kenji Kawaguchi, and Yang Zhang. Deradiff: Denoising time realignment of diffusion models, 2026
2026
-
[19]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[20]
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[21]
Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards.Advances in Neural Information Processing Systems, 36:71095–71134, 2023
Alexandre Rame, Guillaume Couairon, Corentin Dancette, Jean-Baptiste Gaya, Mustafa Shukor, Laure Soulier, and Matthieu Cord. Rewarded soups: towards pareto-optimal alignment by interpolating weights fine-tuned on diverse rewards.Advances in Neural Information Processing Systems, 36:71095–71134, 2023
2023
-
[22]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents.arXiv preprint arXiv:2204.06125, 1(2):3, 2022
work page internal anchor Pith review arXiv 2022
-
[23]
A survey of multi-objective sequential decision-making.Journal of Artificial Intelligence Research, 48:67–113, 2013
Diederik M Roijers, Peter Vamplew, Shimon Whiteson, and Richard Dazeley. A survey of multi-objective sequential decision-making.Journal of Artificial Intelligence Research, 48:67–113, 2013
2013
-
[24]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[25]
Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
2022
-
[26]
Trust region policy optimiza- tion
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimiza- tion. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
2015
-
[27]
Decoding- time language model alignment with multiple objectives.Advances in Neural Information Processing Systems, 37:48875–48920, 2024
Ruizhe Shi, Yifang Chen, Yushi Hu, Alisa Liu, Hanna Hajishirzi, Noah A Smith, and Simon S Du. Decoding- time language model alignment with multiple objectives.Advances in Neural Information Processing Systems, 37:48875–48920, 2024
2024
-
[28]
Code: Blockwise control for denoising diffusion models.arXiv preprint arXiv:2502.00968, 2025
Anuj Singh, Sayak Mukherjee, Ahmad Beirami, and Hadi Jamali-Rad. Code: Blockwise control for denoising diffusion models.arXiv preprint arXiv:2502.00968, 2025
-
[29]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In Francis Bach and David Blei, editors,Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 2256–2265, Lille, France, 07–09 Jul 2015. PMLR
2015
-
[30]
Loss-guided diffusion models for plug-and-play controllable generation
Jiaming Song, Qinsheng Zhang, Hongxu Yin, Morteza Mardani, Ming-Yu Liu, Jan Kautz, Yongxin Chen, and Arash Vahdat. Loss-guided diffusion models for plug-and-play controllable generation. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Mac...
2023
-
[31]
Masatoshi Uehara, Yulai Zhao, Tommaso Biancalani, and Sergey Levine. Understanding reinforcement learning- based fine-tuning of diffusion models: A tutorial and review.arXiv preprint arXiv:2407.13734, 2024
-
[32]
Diffusion model alignment using direct preference optimization
Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik. Diffusion model alignment using direct preference optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8228–8238, 2024
2024
-
[33]
Theoretical study of conflict-avoidant multi-objective reinforcement learning.IEEE Transactions on Information Theory, 2025
Yudan Wang, Peiyao Xiao, Hao Ban, Kaiyi Ji, and Shaofeng Zou. Theoretical study of conflict-avoidant multi-objective reinforcement learning.IEEE Transactions on Information Theory, 2025
2025
-
[34]
Human preference score: Better aligning text-to-image models with human preference
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score: Better aligning text-to-image models with human preference. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2096–2105, 2023
2096
-
[35]
Direction-oriented multi-objective learning: Simple and provable stochastic algorithms.Advances in Neural Information Processing Systems, 36:4509–4533, 2023
Peiyao Xiao, Hao Ban, and Kaiyi Ji. Direction-oriented multi-objective learning: Simple and provable stochastic algorithms.Advances in Neural Information Processing Systems, 36:4509–4533, 2023
2023
-
[36]
Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[37]
A generalized algorithm for multi-objective reinforcement learning and policy adaptation.Advances in neural information processing systems, 32, 2019
Runzhe Yang, Xingyuan Sun, and Karthik Narasimhan. A generalized algorithm for multi-objective reinforcement learning and policy adaptation.Advances in neural information processing systems, 32, 2019
2019
-
[38]
Tfg: Unified training-free guidance for diffusion models.Advances in Neural Information Processing Systems, 37:22370–22417, 2024
Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Y Zou, and Stefano Ermon. Tfg: Unified training-free guidance for diffusion models.Advances in Neural Information Processing Systems, 37:22370–22417, 2024
2024
-
[39]
Freedom: Training-free energy-guided conditional diffusion model
Jiwen Yu, Yinhuai Wang, Chen Zhao, Bernard Ghanem, and Jian Zhang. Freedom: Training-free energy-guided conditional diffusion model. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 23174–23184, October 2023
2023
-
[40]
Token-level direct preference optimization, 2024
Yongcheng Zeng, Guoqing Liu, Weiyu Ma, Ning Yang, Haifeng Zhang, and Jun Wang. Token-level direct preference optimization.arXiv preprint arXiv:2404.11999, 2024
-
[41]
MGDA converges under generalized smoothness, provably
Qi Zhang, Peiyao Xiao, Shaofeng Zou, and Kaiyi Ji. MGDA converges under generalized smoothness, provably. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[42]
Anchor-changing regularized natural policy gradient for multi-objective reinforcement learning.Advances in neural information processing systems, 35:13584– 13596, 2022
Ruida Zhou, Tao Liu, Dileep Kalathil, PR Kumar, and Chao Tian. Anchor-changing regularized natural policy gradient for multi-objective reinforcement learning.Advances in neural information processing systems, 35:13584– 13596, 2022. 14 A Derivation of Lemma 1 In this section, we provide the proof to derive the step-level DPO objective. For each x0:T , we h...
2022
-
[43]
T−1X t=0 Aπpre(sw t , aw t )− T−1X t=0 Aπpre(sl t, al t) #! =−E (xw 0 ,xl 0)∼D logσ TE t∼U(0,T−1),x w 0:T ∼q(xw 0:T |xw 0 ),xl 0:T ∼q(xl 0:T |xl 0)
=σ(r(x w 0 )−r(x l 0)). Based on the BT model and Eq. (11), we can write the loss as −E(xw 0 ,xl 0)∼D logσ r(xw 0 )−r(x l 0) =−E (xw 0 ,xl 0)∼D logσ Exw 0:T ∼q(xw 0:T |xw 0 ),xl 0:T ∼q(xl 0:T |xl 0)[r(xw 0 )−r(x l 0)] =−E (xw 0 ,xl 0)∼D logσ Exw 0:T ∼q(xw 0:T |xw 0 ),xl 0:T ∼q(xl 0:T |xl 0) " Vπpre(sw 0 ) + T−1X t=0 Aπpre(sw t , aw t ) −V πpre(sl 0)− T−1X...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.