Recognition: unknown
SpaceMind: A Modular and Self-Evolving Embodied Vision-Language Agent Framework for Autonomous On-orbit Servicing
Pith reviewed 2026-05-10 12:38 UTC · model grok-4.3
The pith
SpaceMind shows that modular decomposition and experience-based skill evolution allow vision-language agents to reliably perform on-orbit servicing tasks even under degraded conditions and transfer directly to hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
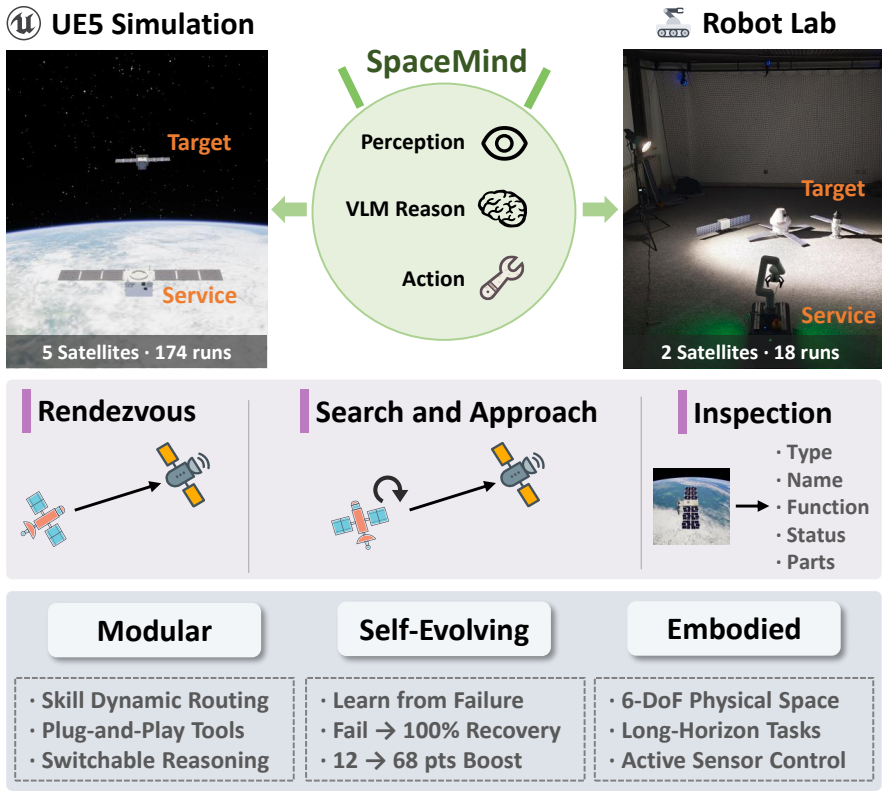
SpaceMind is presented as a modular and self-evolving embodied vision-language model agent framework designed specifically for autonomous on-orbit servicing. The framework decomposes knowledge, tools, and reasoning into three independently extensible dimensions: skill modules with dynamic routing, Model Context Protocol (MCP) tools with configurable profiles, and injectable reasoning-mode skills. An MCP-Redis interface layer supports operation across simulation and physical hardware using the same codebase. The Skill Self-Evolution mechanism distills operational experience into persistent skill files without the need for model fine-tuning. Validation through extensive testing demonstrates 90
What carries the argument
The Skill Self-Evolution mechanism that distills operational experience into persistent skill files without model fine-tuning, together with the decomposition into skill modules, MCP tools, and reasoning modes.
If this is right
- Under nominal conditions all reasoning modes achieve 90-100% navigation success.
- The Prospective mode succeeds in search-and-approach tasks under degraded conditions where other modes fail.
- The agent recovers from failure in four of six groups after a single failed episode, including cases of complete failure to 100% success.
- Inspection scores improve from 12 to 59 out of 100 through self-evolution.
- The same code achieves 100% rendezvous success on a physical robot with no modifications.
Where Pith is reading between the lines
- The design could support continuous skill building during extended orbital missions by accumulating experience over many episodes.
- Similar modular self-evolution might apply to other embodied agents operating in unpredictable settings such as deep-sea or disaster zones.
- The interface between simulation and hardware suggests faster iteration cycles for developing space robotics before launch.
Load-bearing premise
That the modular decomposition into skill modules, MCP tools, and reasoning modes combined with the Skill Self-Evolution mechanism will generalize beyond the specific five satellites, three task types, and lab conditions tested.
What would settle it
Testing the agent on a new satellite configuration or task type outside the original five satellites and three tasks and observing that it fails to recover from failures or maintain 90-100% success after applying self-evolution.
Figures





read the original abstract
Autonomous on-orbit servicing demands embodied agents that perceive through visual sensors, reason about 3D spatial situations, and execute multi-phase tasks over extended horizons. We present SpaceMind, a modular and self-evolving vision-language model (VLM) agent framework that decomposes knowledge, tools, and reasoning into three independently extensible dimensions: skill modules with dynamic routing, Model Context Protocol (MCP) tools with configurable profiles, and injectable reasoning-mode skills. An MCP-Redis interface layer enables the same codebase to operate across simulation and physical hardware without modification, and a Skill Self-Evolution mechanism distills operational experience into persistent skill files without model fine-tuning. We validate SpaceMind through 192 closed-loop runs across five satellites, three task types, and two environments, a UE5 simulation and a physical laboratory, deliberately including degraded conditions to stress-test robustness. Under nominal conditions all modes achieve 90--100% navigation success; under degradation, the Prospective mode uniquely succeeds in search-and-approach tasks where other modes fail. A self-evolution study shows that the agent recovers from failure in four of six groups from a single failed episode, including complete failure to 100% success and inspection scores improving from 12 to 59 out of 100. Real-world validation confirms zero-code-modification transfer to a physical robot with 100% rendezvous success. Code: https://github.com/wuaodi/SpaceMind
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpaceMind, a modular embodied VLM agent framework for autonomous on-orbit servicing that decomposes capabilities into extensible skill modules with dynamic routing, MCP tools with configurable profiles, and injectable reasoning modes. An MCP-Redis interface supports unmodified code execution across UE5 simulation and physical hardware, while a Skill Self-Evolution mechanism distills experience into persistent skill files without fine-tuning. Validation consists of 192 closed-loop runs across five satellites, three task types, and two environments (simulation and lab), including degraded conditions; nominal navigation success is 90-100%, Prospective mode succeeds uniquely under degradation, self-evolution recovers performance in four of six groups (e.g., 0% to 100% success, inspection scores from 12 to 59), and zero-modification sim-to-real transfer yields 100% rendezvous success.
Significance. If the reported empirical results hold under the tested conditions, the work demonstrates a practical, reproducible pathway for self-improving embodied agents in space robotics without retraining, addressing key challenges of long-horizon 3D reasoning and hardware-agnostic deployment. The provision of a public code repository, concrete metrics from 192 runs with degradation and recovery tests, and explicit sim-to-real transfer without code changes are notable strengths that support reproducibility and falsifiability. This could inform future autonomous servicing systems, though generalization beyond the specific satellites, tasks, and lab setup remains an open question.
major comments (2)
- [Validation experiments] The validation section reports 90-100% nominal success and unique Prospective-mode robustness under degradation, but does not specify the exact baselines (e.g., standard VLM prompting or non-modular agents), statistical tests for significance, or data exclusion criteria; this makes it difficult to quantify the contribution of the modular decomposition and MCP layer to the headline performance numbers.
- [Skill Self-Evolution mechanism] The self-evolution study claims recovery from failure in four of six groups after a single episode, including complete failure to 100% success; however, the precise mechanism for updating persistent skill files, the definition of 'failure' thresholds, and whether improvements were measured over multiple independent trials are not detailed enough to assess if the gains are robust or task-specific.
minor comments (2)
- [Results] The abstract and results text use ranges (90--100%) without per-condition breakdowns or variance; adding a table with per-mode, per-environment success rates and standard deviations would improve clarity.
- [System architecture] The MCP-Redis interface is described as enabling zero-modification transfer, but the paper does not discuss latency, synchronization, or failure modes of the Redis layer under real-time constraints typical of on-orbit hardware.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment of SpaceMind. We address each major comment below with clarifications and proposed revisions to enhance transparency and reproducibility.
read point-by-point responses
-
Referee: [Validation experiments] The validation section reports 90-100% nominal success and unique Prospective-mode robustness under degradation, but does not specify the exact baselines (e.g., standard VLM prompting or non-modular agents), statistical tests for significance, or data exclusion criteria; this makes it difficult to quantify the contribution of the modular decomposition and MCP layer to the headline performance numbers.
Authors: We agree that explicit baseline comparisons and statistical details were insufficiently described. In the revised manuscript we will add a new subsection (Section 5.3) and Table 3 that directly compares SpaceMind against two baselines: (1) a standard VLM agent using direct prompting with the identical backbone and no modular routing, and (2) a non-modular agent with fixed tool sets. All 192 runs are reported with no data exclusions; this will be stated explicitly. Because the UE5 simulation is deterministic under nominal conditions, we will report mean success rates together with 95% confidence intervals rather than formal hypothesis tests, and we will link the full per-run dataset in the public repository. These additions will allow readers to isolate the contribution of the modular decomposition and MCP layer. revision: yes
-
Referee: [Skill Self-Evolution mechanism] The self-evolution study claims recovery from failure in four of six groups after a single episode, including complete failure to 100% success; however, the precise mechanism for updating persistent skill files, the definition of 'failure' thresholds, and whether improvements were measured over multiple independent trials are not detailed enough to assess if the gains are robust or task-specific.
Authors: We thank the referee for requesting greater precision. The update mechanism works by having the agent parse the failed episode’s trajectory, extract critical decision sequences, and write them as a new JSON skill file that is persisted via the MCP-Redis layer; no VLM parameters are modified. Failure is defined as a success rate below 30% on the first run of a given group. The reported recoveries (four of six groups) were each obtained from a single failed episode followed by one evolved run; we did not perform multiple independent trials per group. We will insert an algorithm box and pseudocode in Section 4.3 that fully specifies the distillation procedure and the exact thresholds. While the six groups already span different satellites and task types, we acknowledge that additional repeated trials would further strengthen claims of robustness; the current design prioritizes demonstrating rapid single-episode adaptation under realistic resource constraints. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents a modular VLM agent framework whose central claims rest entirely on direct empirical validation through 192 closed-loop experimental runs in simulation and physical hardware, with reported success rates, recovery metrics, and zero-modification transfer. No mathematical derivations, equations, fitted parameters, or uniqueness theorems appear in the provided text. The architecture (skill modules, MCP tools, reasoning modes, Skill Self-Evolution) is described as an engineering design and then tested, without any step that reduces a claimed prediction or result back to its own inputs by construction or self-citation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embodied VLM agents can be decomposed into independently extensible skill modules, MCP tools, and reasoning-mode skills
- ad hoc to paper Operational experience can be distilled into persistent skill files that improve future performance without model fine-tuning
invented entities (2)
-
Model Context Protocol (MCP) tools with configurable profiles
no independent evidence
-
Skill Self-Evolution mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Orbital debris quarterly news.Orbital Debris Quarterly News (ODQN), 24(JSC-E-DAA-TN77633), 2020
Phillip Anz-Meador. Orbital debris quarterly news.Orbital Debris Quarterly News (ODQN), 24(JSC-E-DAA-TN77633), 2020
2020
-
[2]
On-orbit servicing, assembly, and manufacturing (osam) state of play, 2021
Dale Arney, Richard Sutherland, John Mulvaney, Devon Steinkoenig, Christopher Stockdale, and Mason Farley. On-orbit servicing, assembly, and manufacturing (osam) state of play, 2021. NASA OSAM state-of-play report
2021
-
[3]
Flores-Abad, O
A. Flores-Abad, O. Ma, K. Pham, and S. Ulrich. A review of space robotics technologies for on-orbit servicing.Progress in Aerospace Sciences, 68:1–26, 2014
2014
-
[4]
On-orbit servicing, assembly, and manufacturing 2 (osam-2)
Jennifer Harbaugh and B Dunbar. On-orbit servicing, assembly, and manufacturing 2 (osam-2). STMD: Tech Demo Missions, 2022
2022
-
[5]
The clearspace-1 mission: Esa and clearspace team up to remove debris
Robin Biesbroek, Sarmad Aziz, Andrew Wolahan, Stefano Cipolla, Muriel Richard-Noca, and Luc Piguet. The clearspace-1 mission: Esa and clearspace team up to remove debris. InProc. 8th eur. conf. Sp. debris, pages 1–3, 2021
2021
-
[6]
Removede- bris: An in-orbit active debris removal demonstration mission.Acta Astronautica, 127:448–463, 2016
Jason L Forshaw, Guglielmo S Aglietti, Nimal Navarathinam, Haval Kadhem, Thierry Salmon, Aurélien Pisseloup, Eric Joffre, Thomas Chabot, Ingo Retat, Robert Axthelm, et al. Removede- bris: An in-orbit active debris removal demonstration mission.Acta Astronautica, 127:448–463, 2016
2016
-
[7]
Language models are spacecraft operators.arXiv preprint arXiv:2404.00413, 2024
VictorRodriguez-Fernandez, AlejandroCarrasco, JasonCheng, EliScharf, PengMunSiew, and Richard Linares. Language models are spacecraft operators.arXiv preprint arXiv:2404.00413, 2024
-
[8]
Vi- sual language models as operator agents in the space domain
Alejandro Carrasco, Marco Nedungadi, Victor Rodriguez-Fernandez, and Richard Linares. Vi- sual language models as operator agents in the space domain. InAIAA SCITECH 2025 Forum, page 1543, 2025
2025
-
[9]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
2024
-
[10]
Model context protocol (mcp): Landscape, security threats, and future research directions.ACM Transactions on Software Engineering and Methodology, 2025
Xinyi Hou, Yanjie Zhao, Shenao Wang, and Haoyu Wang. Model context protocol (mcp): Landscape, security threats, and future research directions.ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[11]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[12]
Aspacecraftdatasetfordetection, segmentation and parts recognition
HoangAnhDung, BoChen, andTat-JunChin. Aspacecraftdatasetfordetection, segmentation and parts recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2012–2019, 2021
2012
-
[13]
3d component segmentation network and dataset for non-cooperative spacecraft.Aerospace, 9(5):248, 2022
Guangyuan Zhao, Xue Wan, Yaolin Tian, Yadong Shao, and Shengyang Li. 3d component segmentation network and dataset for non-cooperative spacecraft.Aerospace, 9(5):248, 2022. 21
2022
-
[14]
Yadong Shao, Aodi Wu, Shengyang Li, Leizheng Shu, Xue Wan, Yuanbin Shao, and Junyan Huo. Satellite component semantic segmentation: Video dataset and real-time pyramid at- tention and decoupled attention network.IEEE Transactions on Aerospace and Electronic Systems, 59(6):7315–7333, 2023
2023
-
[15]
Satellite pose estimation challenge: Dataset, competition design, and results.IEEE Transactions on Aerospace and Electronic Systems, 56(5):4083–4098, 2020
Mate Kisantal, Sumant Sharma, Tae Ha Park, Dario Izzo, Marcus Märtens, and Simone D’Amico. Satellite pose estimation challenge: Dataset, competition design, and results.IEEE Transactions on Aerospace and Electronic Systems, 56(5):4083–4098, 2020
2020
-
[16]
Speed+: Next-generation dataset for spacecraft pose estimation across domain gap
Tae Ha Park, Marcus Märtens, Gurvan Lecuyer, Dario Izzo, and Simone D’Amico. Speed+: Next-generation dataset for spacecraft pose estimation across domain gap. In2022 IEEE aerospace conference (AERO), pages 1–15. IEEE, 2022
2022
-
[17]
Robust multi-task learning and online refinement for spacecraft pose estimation across domain gap.Advances in Space Research, 73(11):5726–5740, 2024
Tae Ha Park and Simone D’Amico. Robust multi-task learning and online refinement for spacecraft pose estimation across domain gap.Advances in Space Research, 73(11):5726–5740, 2024
2024
-
[18]
A survey on deep learning-based monocular spacecraft pose estimation: Current state, limitations and prospects.Acta Astronautica, 212:339–360, 2023
Leo Pauly, Wassim Rharbaoui, Carl Shneider, Arunkumar Rathinam, Vincent Gaudilliere, and Djamila Aouada. A survey on deep learning-based monocular spacecraft pose estimation: Current state, limitations and prospects.Acta Astronautica, 212:339–360, 2023
2023
-
[19]
Space-llava: a vision-language model adapted to extraterrestrial applications,
Matthew Foutter, Praneet Bhoj, Rohan Sinha, Amine Elhafsi, Somrita Banerjee, Christopher Agia, Justin Kruger, Tommaso Guffanti, Daniele Gammelli, Simone D’Amico, et al. Adapting a foundation model for space-based tasks.arXiv preprint arXiv:2408.05924, 2024
-
[20]
Tool learning with foundation models.ACM Computing Surveys, 57(4):1–40, 2024
Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Xu- anhe Zhou, Yufei Huang, Chaojun Xiao, et al. Tool learning with foundation models.ACM Computing Surveys, 57(4):1–40, 2024
2024
-
[21]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
2022
-
[22]
Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
2023
-
[23]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu, et al. PaLM-E: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review arXiv 2023
-
[24]
M. Ahn, A. Brohan, N. Brown, Y. Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gober, K. Gopalakrishnan, et al. Do as I can, not as I say: Grounding language in robotic affordances. InConference on Robot Learning (CoRL), 2022
2022
-
[25]
Huang, F
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florence, A. Zeng, J. Tompson, I. Mordatch, Y. Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models. InConference on Robot Learning (CoRL), 2023
2023
-
[26]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choro- manski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, et al. Rt-2: Vision- language-action models transfer web knowledge to robotic control, 2023.URL https://arxiv. org/abs/2307.15818, 1:2, 2024. 22
work page internal anchor Pith review arXiv 2023
-
[27]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review arXiv 2024
-
[28]
GPT-Driver: Learning to Drive with GPT
Jiageng Mao, Yuxi Qian, Junjie Ye, Hang Zhao, and Yue Wang. Gpt-driver: Learning to drive with gpt.arXiv preprint arXiv:2310.01415, 2023
work page internal anchor Pith review arXiv 2023
-
[29]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[30]
A. Zhao, D. Huang, Q. Xu, M. Lin, Y. Liu, and G. Huang. ExpeL: LLM agents are experiential learners. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, 2024
2024
-
[31]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review arXiv 2023
-
[32]
Airsim: High-fidelity visual and physical simulation for autonomous vehicles
Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. Airsim: High-fidelity visual and physical simulation for autonomous vehicles. InField and service robotics: Results of the 11th international conference, pages 621–635. Springer, 2017
2017
-
[33]
Spacesense- bench: A large-scale multi-modal benchmark for spacecraft perception and pose estimation
Aodi Wu, Jianhong Zuo, Zeyuan Zhao, Xubo Luo, Ruisuo Wang, and Xue Wan. Spacesense- bench: A large-scale multi-modal benchmark for spacecraft perception and pose estimation. arXiv preprint arXiv:2603.09320, 2026
-
[34]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 23
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.