CAMO: An Agentic Framework for Automated Causal Discovery from Micro Behaviors to Macro Emergence in LLM Agent Simulations
Pith reviewed 2026-05-10 11:34 UTC · model grok-4.3
The pith
CAMO converts hypotheses about LLM agent interactions into computable causal graphs that trace micro behaviors to macro emergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAMO converts mechanistic hypotheses into computable factors grounded in simulation records and learns a compact causal representation centered on an emergent target Y. CAMO outputs a computable Markov boundary and a minimal upstream explanatory subgraph, yielding interpretable causal chains and actionable intervention levers. It also uses simulator-internal counterfactual probing to orient ambiguous edges and revise hypotheses when evidence contradicts the current view.
What carries the argument
The CAMO process of hypothesis-to-factor conversion, followed by construction of a Markov boundary and minimal upstream subgraph, with simulator-internal counterfactual probing to orient edges and revise the model.
Load-bearing premise
Mechanistic hypotheses about agent behaviors can be turned into factors that are reliably computable from simulation records, and internal counterfactual tests can correctly orient causal edges while revising hypotheses as needed.
What would settle it
Apply the discovered intervention levers in new simulation runs and check whether the observed changes in the emergent target Y align with the directions and strengths predicted by the causal graph.
Figures







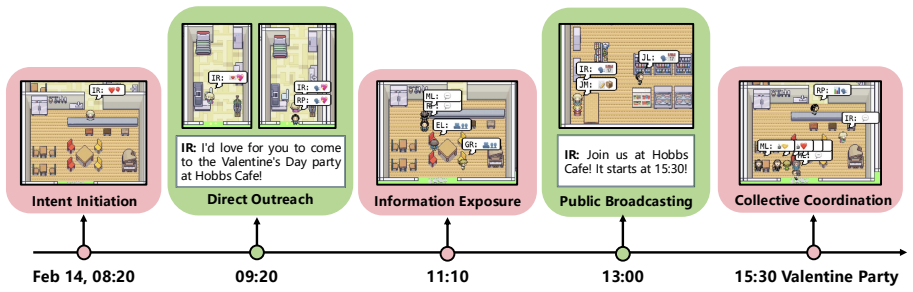


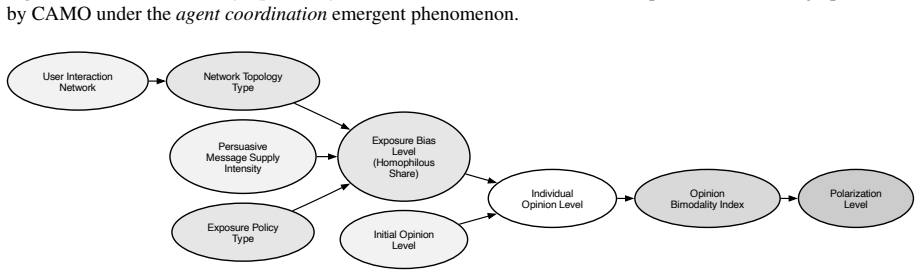

read the original abstract
LLM-empowered agent simulations are increasingly used to study social emergence, yet the micro-to-macro causal mechanisms behind macro outcomes often remain unclear. This is challenging because emergence arises from intertwined agent interactions and meso-level feedback and nonlinearity, making generative mechanisms hard to disentangle. To this end, we introduce \textbf{\textsc{CAMO}}, an automated \textbf{Ca}usal discovery framework from \textbf{M}icr\textbf{o} behaviors to \textbf{M}acr\textbf{o} Emergence in LLM agent simulations. \textsc{CAMO} converts mechanistic hypotheses into computable factors grounded in simulation records and learns a compact causal representation centered on an emergent target $Y$. \textsc{CAMO} outputs a computable Markov boundary and a minimal upstream explanatory subgraph, yielding interpretable causal chains and actionable intervention levers. It also uses simulator-internal counterfactual probing to orient ambiguous edges and revise hypotheses when evidence contradicts the current view. Experiments across four emergent settings demonstrate the promise of \textsc{CAMO}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CAMO, an agentic framework for automated causal discovery in LLM agent simulations. It converts mechanistic hypotheses into computable factors grounded in simulation records, learns a compact causal representation for an emergent target Y that yields a Markov boundary and minimal upstream explanatory subgraph, and employs simulator-internal counterfactual probing to orient ambiguous edges and revise hypotheses when contradicted by evidence. The approach is evaluated across four emergent settings to demonstrate its promise for yielding interpretable causal chains and actionable interventions.
Significance. If the implementation details hold, CAMO could meaningfully advance causal understanding of micro-to-macro emergence in agent-based LLM simulations, a domain where nonlinearity, feedback, and intertwined interactions typically obscure mechanisms. The framework's strengths include grounding in external simulation records, use of internal probing for orientation, and hypothesis revision, which together address limitations of static causal discovery methods and could provide falsifiable, intervention-oriented outputs.
major comments (2)
- [§3] §3 (Framework): The central claim that mechanistic hypotheses are converted into 'computable factors' without circularity or loss of fidelity is load-bearing for all downstream outputs (Markov boundary, subgraph, probing). The manuscript must specify the exact grounding procedure, including how simulation records are mapped to factors and what validation ensures non-self-referential definitions.
- [§5] §5 (Experiments): The four settings are said to demonstrate promise, but without reported quantitative metrics (e.g., edge orientation accuracy, subgraph minimality scores, or comparison against standard causal discovery baselines such as PC or NOTEARS on the same records), it is impossible to assess whether the Markov boundary and revision logic improve over alternatives or merely reproduce simulation artifacts.
minor comments (2)
- [Abstract] Abstract and §1: The four emergent settings are referenced but not named or briefly characterized; adding one sentence identifying them would improve accessibility.
- [Notation] Notation throughout: Symbols such as Y and the Markov boundary are introduced but should be accompanied by a short table or explicit first-use definitions to avoid ambiguity for readers outside causal inference.
Simulated Author's Rebuttal
Thank you for the detailed and constructive referee report. We appreciate the recognition of CAMO's potential to advance causal understanding in LLM agent simulations. Below, we provide point-by-point responses to the major comments and describe the revisions we plan to implement.
read point-by-point responses
-
Referee: [§3] §3 (Framework): The central claim that mechanistic hypotheses are converted into 'computable factors' without circularity or loss of fidelity is load-bearing for all downstream outputs (Markov boundary, subgraph, probing). The manuscript must specify the exact grounding procedure, including how simulation records are mapped to factors and what validation ensures non-self-referential definitions.
Authors: We agree that a precise specification of the grounding procedure is essential to substantiate the framework's claims. The current manuscript outlines the high-level process but does not provide sufficient implementation details. In the revised version, we will expand Section 3 with a dedicated subsection on 'Hypothesis Grounding and Factor Computation'. This will include: (1) the formal mapping from natural language hypotheses to computable factors using simulation record schemas, (2) examples of how specific record fields (e.g., agent states, interaction logs) are used to instantiate factors, and (3) validation criteria such as consistency checks against the original hypothesis text and cross-validation with held-out simulation runs to prevent self-referential or circular definitions. We will also include pseudocode for the grounding algorithm. revision: yes
-
Referee: [§5] §5 (Experiments): The four settings are said to demonstrate promise, but without reported quantitative metrics (e.g., edge orientation accuracy, subgraph minimality scores, or comparison against standard causal discovery baselines such as PC or NOTEARS on the same records), it is impossible to assess whether the Markov boundary and revision logic improve over alternatives or merely reproduce simulation artifacts.
Authors: We acknowledge that the experimental section currently focuses on qualitative demonstration of interpretable causal chains across the four settings rather than quantitative benchmarks. This choice was made to highlight the framework's ability to handle complex, emergent phenomena where ground-truth causal structures are not always straightforward to define. However, we agree that quantitative evaluation would allow better assessment of performance. In the revision, we will augment §5 with quantitative metrics, including edge orientation accuracy where ground truth is available from the simulation design, measures of subgraph minimality (e.g., number of nodes/edges relative to full graph), and comparisons to baselines such as the PC algorithm and NOTEARS applied to aggregated simulation records. We will discuss any necessary adaptations for these methods to the dynamic, non-i.i.d. nature of agent simulation data. If certain metrics prove infeasible due to the lack of explicit ground truth in some settings, we will clearly state the limitations. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents CAMO as a framework that converts mechanistic hypotheses into computable factors grounded in external simulation records, learns a compact causal representation for an emergent target Y, and applies simulator-internal counterfactual probing to orient edges and revise hypotheses. No equations, self-citations, or derivation steps are shown that reduce the central outputs (Markov boundary, minimal upstream subgraph) to fitted parameters or prior self-referential definitions by construction. The claims remain dependent on the soundness of factor grounding and probing protocols rather than tautological equivalence to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.