Recognition: unknown
MADE: A Living Benchmark for Multi-Label Text Classification with Uncertainty Quantification of Medical Device Adverse Events
Pith reviewed 2026-05-10 11:16 UTC · model grok-4.3
The pith
A living benchmark for multi-label classification of medical device adverse event reports reveals clear trade-offs between predictive accuracy and reliable uncertainty quantification across model types.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MADE is a living MLTC benchmark derived from medical device adverse event reports that is updated continuously with newly published reports and evaluated under strict temporal splits to prevent contamination. Systematic baselines on encoder and decoder models demonstrate that smaller discriminatively fine-tuned decoders achieve the strongest head-to-tail accuracy while maintaining competitive UQ, generative fine-tuning delivers the most reliable UQ, large reasoning models improve performance on rare labels yet exhibit surprisingly weak UQ, and self-verbalized confidence is not a reliable proxy for uncertainty.
What carries the argument
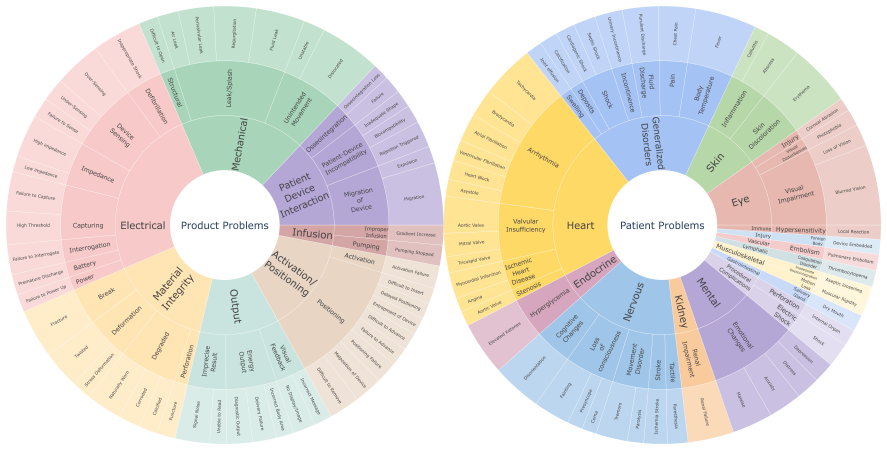
The MADE benchmark, a living collection of hierarchical long-tailed multi-label medical device adverse event reports paired with a strict temporal split evaluation protocol.
If this is right
- Smaller discriminatively fine-tuned decoder models provide the best practical balance of head-to-tail accuracy and uncertainty quantification for this task.
- Generative fine-tuning should be preferred when reliable uncertainty estimates are the primary requirement.
- Large reasoning models can be used to improve coverage of rare labels but require additional uncertainty calibration techniques.
- Self-verbalized confidence cannot be trusted as a substitute for entropy- or consistency-based uncertainty methods.
Where Pith is reading between the lines
- Healthcare deployment choices may need to trade accuracy for trustworthy uncertainty depending on whether the priority is overall correctness or safe human oversight of low-confidence cases.
- The living update mechanism allows future testing of whether models can handle genuinely novel adverse event patterns that did not exist in earlier data.
- The observed weakness in uncertainty quantification for large reasoning models suggests that scaling alone does not solve calibration issues in long-tailed multi-label medical settings.
Load-bearing premise
Continuous addition of new reports together with strict temporal splits fully prevents training data contamination, and the hierarchical labels accurately reflect real-world dependencies and imbalances.
What would settle it
A model trained only on reports published before a given cutoff date achieving equal or higher accuracy and UQ calibration on reports published after that cutoff would indicate that temporal splits failed to block contamination.
Figures




read the original abstract
Machine learning in high-stakes domains such as healthcare requires not only strong predictive performance but also reliable uncertainty quantification (UQ) to support human oversight. Multi-label text classification (MLTC) is a central task in this domain, yet remains challenging due to label imbalances, dependencies, and combinatorial complexity. Existing MLTC benchmarks are increasingly saturated and may be affected by training data contamination, making it difficult to distinguish genuine reasoning capabilities from memorization. We introduce MADE, a living MLTC benchmark derived from {m}edical device {ad}verse {e}vent reports and continuously updated with newly published reports to prevent contamination. MADE features a long-tailed distribution of hierarchical labels and enables reproducible evaluation with strict temporal splits. We establish baselines across more than 20 encoder- and decoder-only models under fine-tuning and few-shot settings (instruction-tuned/reasoning variants, local/API-accessible). We systematically assess entropy-/consistency-based and self-verbalized UQ methods. Results show clear trade-offs: smaller discriminatively fine-tuned decoders achieve the strongest head-to-tail accuracy while maintaining competitive UQ; generative fine-tuning delivers the most reliable UQ; large reasoning models improve performance on rare labels yet exhibit surprisingly weak UQ; and self-verbalized confidence is not a reliable proxy for uncertainty. Our work is publicly available at https://hhi.fraunhofer.de/aml-demonstrator/made-benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MADE, a living benchmark for multi-label text classification derived from medical device adverse event reports. It is continuously updated with new reports and uses strict temporal splits to prevent training data contamination. The work establishes baselines across more than 20 encoder- and decoder-only models under fine-tuning and few-shot settings, systematically evaluates entropy-/consistency-based and self-verbalized UQ methods, and reports empirical trade-offs: smaller discriminatively fine-tuned decoders achieve strongest head-to-tail accuracy with competitive UQ; generative fine-tuning yields most reliable UQ; large reasoning models improve on rare labels but show weak UQ; and self-verbalized confidence is not a reliable proxy.
Significance. If the results hold after addressing verification gaps, this benchmark would be a useful contribution to NLP for high-stakes healthcare applications by tackling label imbalance, hierarchical dependencies, and contamination issues that saturate existing MLTC datasets. The living design and public release enable ongoing reproducible evaluation. The focus on UQ alongside accuracy is relevant for oversight in medical domains. No machine-checked proofs or parameter-free derivations are present, but the empirical scope on real-world long-tailed data is a strength if properly documented.
major comments (2)
- Abstract: The abstract asserts specific performance trade-offs across models and UQ methods but supplies no methods details, statistical tests, error bars, or data characteristics (e.g., number of reports, label hierarchy depth, or imbalance ratios), leaving major gaps that prevent verification of the central claims about model superiority and UQ reliability.
- Abstract: The claim that strict temporal splits combined with continuous updating effectively prevents training data contamination is load-bearing for all reported results, yet no evidence is provided of model training data cutoffs versus test report dates or decontamination audits such as n-gram overlap or embedding similarity checks. This is especially critical for API and large reasoning models whose pre-training may include overlapping medical corpora.
minor comments (2)
- The abstract uses '{m}edical device {ad}verse {e}vent' which appears to be a formatting artifact for acronym expansion; clarify in the full text.
- Ensure the full manuscript defines all UQ methods (entropy, consistency, self-verbalized) with explicit formulas or pseudocode to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of clarity and verifiability in our presentation of the MADE benchmark. We address each major comment below and indicate the revisions planned for the manuscript.
read point-by-point responses
-
Referee: Abstract: The abstract asserts specific performance trade-offs across models and UQ methods but supplies no methods details, statistical tests, error bars, or data characteristics (e.g., number of reports, label hierarchy depth, or imbalance ratios), leaving major gaps that prevent verification of the central claims about model superiority and UQ reliability.
Authors: We agree that the abstract prioritizes high-level claims over granular details. In the revised version, we will expand the abstract to include key data characteristics drawn from Section 2 of the manuscript, such as the scale of the report collection, the depth of the hierarchical label taxonomy, and the long-tailed imbalance ratios. We will also explicitly reference that all quantitative results in the paper include error bars computed over multiple runs and appropriate statistical tests for model comparisons. Full methodological specifications for the models, fine-tuning procedures, and UQ methods remain in Sections 3 and 4 to preserve abstract readability. These additions will directly support verification of the reported trade-offs. revision: yes
-
Referee: Abstract: The claim that strict temporal splits combined with continuous updating effectively prevents training data contamination is load-bearing for all reported results, yet no evidence is provided of model training data cutoffs versus test report dates or decontamination audits such as n-gram overlap or embedding similarity checks. This is especially critical for API and large reasoning models whose pre-training may include overlapping medical corpora.
Authors: We recognize the critical importance of substantiating the contamination-resistance claim. The manuscript details the temporal splitting protocol in Section 3.2, which assigns reports to train/validation/test partitions strictly according to their publication dates, ensuring test reports postdate any feasible training cutoff for the models we evaluate. For the open-source models we fine-tune, we have now added explicit documentation of these dates along with n-gram overlap and embedding similarity audits against known pre-training corpora. In the revision, we will incorporate these checks into a new subsection. For proprietary API models and large reasoning models, however, pre-training data and exact cutoffs are not disclosed by the providers, so exhaustive audits are not feasible on our side. We will add a clear limitations statement acknowledging this constraint while noting that the temporal split still provides a practical and reproducible safeguard for the benchmark's ongoing use. revision: partial
- Complete decontamination audits for closed-source API and large reasoning models, as their pre-training data and cutoffs are not publicly available.
Circularity Check
Empirical benchmark paper with no derivations or self-referential steps
full rationale
The paper introduces the MADE benchmark dataset from medical device adverse event reports and reports empirical results from evaluating over 20 models under fine-tuning and few-shot settings using standard accuracy and uncertainty quantification metrics. No equations, derivations, fitted parameters, or predictive claims appear in the abstract or described full text; all reported trade-offs (e.g., smaller decoders on head-to-tail accuracy, generative fine-tuning on UQ) are direct outputs of external model evaluations on temporally split data rather than reductions to internal definitions or self-citations. The living benchmark design and strict temporal splits are explicit construction choices for contamination resistance, not derived quantities. No self-citation load-bearing, uniqueness theorems, or ansatz smuggling are invoked. The work is therefore self-contained against external benchmarks and model evaluations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Medical device adverse event reports provide a representative corpus with hierarchical long-tailed labels suitable for MLTC and UQ evaluation.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing reasoning capa- bility in LLMs via reinforcement learning.Preprint, arXiv:2501.12948. Chunyuan Deng, Yilun Zhao, Xiangru Tang, Mark Ger- stein, and Arman Cohan. 2024. Investigating data contamination in modern benchmarks for large lan- guage models. InProceedings of the 2024 Confer- ence of the North American Chapter of the Asso...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
SGDR: Stochastic Gradient Descent with Warm Restarts
Hierarchical deep learning for multi-label im- balanced text classification of economic literature. Applied Soft Computing, 176:113189. Zhen Lin, Shubhendu Trivedi, and Jimeng Sun. 2024. Generating with confidence: Uncertainty quantifica- tion for black-box large language models.Transac- tions on Machine Learning Research. S. Lloyd. 1982. Least squares qu...
work page Pith review arXiv 2024
-
[3]
Large language models do multi-label classifi- cation differently.Preprint, arXiv:2505.17510. Jenish Maharjan, Anurag Garikipati, Navan Preet Singh, Leo Cyrus, Mayank Sharma, Madalina Ciobanu, Gina Barnes, Rahul Thapa, Qingqing Mao, and Ri- tankar Das. 2024. OpenMedLM: prompt engineer- ing can out-perform fine-tuning in medical question- answering with op...
-
[4]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
UMAP: Uniform manifold approximation and projection for dimension reduction.Preprint, arXiv:1802.03426. Bálint Mucsányi, Michael Kirchhof, and Seong Joon Oh. 2024. Benchmarking uncertainty disentangle- ment: Specialized uncertainties for specialized tasks. Advances in neural information processing systems, 37:50972–51038. James Mullenbach, Sarah Wiegreffe...
work page internal anchor Pith review arXiv 2024
-
[5]
T., Zhang, S., Carignan, D., Edgar, R., Fusi, N., King, N., Larson, J., Li, Y., Liu, W., et al
Can generalist foundation models outcom- pete special-purpose tuning? Case study in medicine. arXiv preprint arXiv:2311.16452. Jaya Ojha, Oriana Presacan, Pedro G. Lind, Eric Mon- teiro, and Anis Yazidi. 2025. Navigating uncertainty: A user-perspective survey of trustworthiness of AI in healthcare.ACM Transactions on Computing for Healthcare, 6(3):1–32. T...
-
[6]
JRC Eurovoc indexer JEX - a freely available multi-label categorisation tool. InProceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), pages 798– 805, Istanbul, Turkey. European Language Resources Association (ELRA). Pingjie Tang, Meng Jiang, Bryan (Ning) Xia, Jed W. Pitera, Jeffrey Welser, and Nitesh V . Chawla...
-
[7]
Seq vs Seq: An open suite of paired encoders and decoders.Preprint, arXiv:2507.11412. Jiageng Wu, Bowen Gu, Ren Zhou, Kevin Xie, Doug Snyder, Yixing Jiang, Valentina Carducci, Richard Wyss, Rishi J Desai, Emily Alsentzer, Leo Anthony Celi, Adam Rodman, Sebastian Schneeweiss, Jonathan H. Chen, Santiago Romero- Brufau, Kueiyu Joshua Lin, and Jie Yang. 2025....
-
[8]
Benchmarking benchmark leakage in large language models.Preprint, arXiv:2404.18824. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. Qwen3 technical report.Prepri...
-
[9]
We have not found official information on the knowledge cutoff dates for DeepSeek-R1, Qwen3, and Kimi K2 (released in January, April, and July 2025, respectively)
was pre-trained including on the ‘DOLMino mix 1124’ dataset (OLMo et al., 2025, which men- tions data from September 2024), among other data sources. We have not found official information on the knowledge cutoff dates for DeepSeek-R1, Qwen3, and Kimi K2 (released in January, April, and July 2025, respectively). Llama-3.3-Nemotron-49B- v1.5 used post-trai...
2025
-
[10]
few - shot
and K-means clustering (Lloyd, 1982) and named with GPT-5. Table A.1 compares a hierarchical loss (HYDRA, Karl and Scherp, 2025) with standard binary cross- entropy for Ettin models. Instead of training a single classification head over the entire label space, HYDRA partitions labels by their hierarchy level and assigns a dedicated classification head to ...
1982
-
[11]
A " are Medical Device Problems . - Labels that start with
The taxonomy of labels is provided within the < labels > tag . - Labels are separated by newlines ; a definition for the label is provided . - We are in a 3 - level hierarchical multi - label classification setting - this means that when a child label ( such as A040507 ) is selected , the parent label ( A0405 ) and grandparent label ( A04 ) must also be s...
-
[12]
few - shot
There are 10 " few - shot " examples included in the <few - shot - examples > tag . - Each example includes a report and its corresponding labels . - The examples included in the <few - shot - examples > tag were chosen using a K - Nearest Neighbours algorithm which picked reports similar in content to the text which needs classifying . The labels shown f...
-
[13]
- Assign all labels that are relevant
Your goal is to classify the text provided within the < classification - text > tag . - Assign all labels that are relevant . - You can choose multiple labels , a single label , or no labels if none apply . - Always use the exact label names from the label list provided in the taxonomy under the < labels > tag . Do not invent new labels or modify existing...
-
[14]
For example : A04 A0405 A040507 E01 E0101 # IMPORTANT * In your final output , you must not include any extra text , explanations , or formatting outside the label list
Provide your output as a list of labels , each on a new line . For example : A04 A0405 A040507 E01 E0101 # IMPORTANT * In your final output , you must not include any extra text , explanations , or formatting outside the label list . Only return the list of labels separated by newlines .* """ Type/modelMacro F1↑J↑ PRR↑ρ↓ECE + ↓ Overall Head Medium Tail ET...
-
[15]
First , familiarize yourself with the label definitions : < labels > A01 : Patient Device Interaction Problem - Problem related to the interaction between the patient and the device . A0101 : Patient - Device Incompatibility - Problem associated with the interaction between the patient's physiology or anatomy and the device that affects the patient and / ...
-
[16]
Review these few - shot examples of similar reports and their corresponding labels : <few - shot - examples > { EXAMPLES } </ few - shot - examples >
-
[17]
"" A.7.3 Variation With Self-Verbalized Confidence
Now , carefully classify the following report : < classification - text > { C L A S S I F I C A T I O N _ T E X T } </ classification - text >""" A.7.3 Variation With Self-Verbalized Confidence """ ... - Assign all labels that are relevant . - You can choose multiple labels , a single label , or no labels if none apply . - Always use the exact label names...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.