Recognition: unknown
(1D) Ordered Tokens Enable Efficient Test-Time Search
Pith reviewed 2026-05-10 11:03 UTC · model grok-4.3
The pith
Coarse-to-fine 1D token sequences improve test-time search scaling in autoregressive image generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
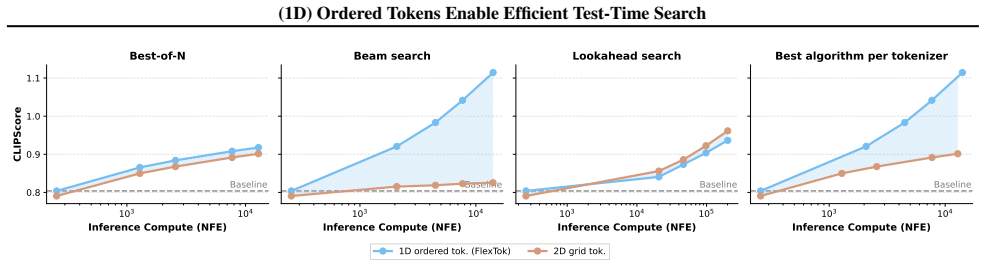
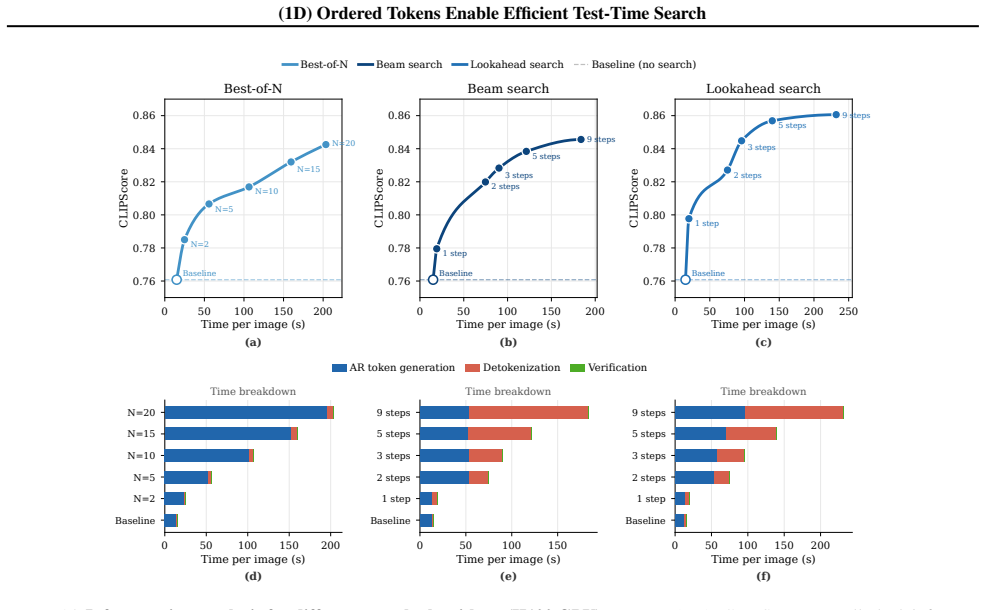
AR models trained on coarse-to-fine ordered tokens exhibit improved test-time scaling behavior compared to grid-based counterparts. Moreover, pure test-time search over token sequences can perform training-free text-to-image generation when guided by an image-text verifier. Classical search algorithms interact more effectively with the ordered structure, and the approach works across different verifiers and AR priors.
What carries the argument
Coarse-to-fine 1D token ordering, where each prefix of the sequence represents a progressively refined image that carries semantic meaning for verifier scoring.
Load-bearing premise
Intermediate states in coarse-to-fine token sequences carry semantic meaning that verifiers can reliably evaluate to steer generation.
What would settle it
An experiment where coarse-to-fine ordered tokens show no better scaling or search performance than grid tokens, or where verifiers cannot score partial sequences meaningfully, would falsify the claim.
Figures

























read the original abstract
Tokenization is a key component of autoregressive (AR) generative models, converting raw data into more manageable units for modeling. Commonly, tokens describe local information, such as regions of pixels in images or word pieces in text, and AR generation predicts these tokens in a fixed order. A worthwhile question is whether token structures affect the ability to steer the generation through test-time search, where multiple candidate generations are explored and evaluated by a verifier. Using image generation as our testbed, we hypothesize that recent 1D ordered tokenizers with coarse-to-fine structure can be more amenable to search than classical 2D grid structures. This is rooted in the fact that the intermediate states in coarse-to-fine sequences carry semantic meaning that verifiers can reliably evaluate, enabling effective steering during generation. Through controlled experiments, we find that AR models trained on coarse-to-fine ordered tokens exhibit improved test-time scaling behavior compared to grid-based counterparts. Moreover, we demonstrate that, thanks to the ordered structure, pure test-time search over token sequences (i.e., without training an AR model) can perform training-free text-to-image generation when guided by an image-text verifier. Beyond this, we systematically study how classical search algorithms (best-of-N, beam search, lookahead search) interact with different token structures, as well as the role of different verifiers and AR priors. Our results highlight the impact of token structure on inference-time scalability and provide practical guidance for test-time scaling in AR models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that autoregressive (AR) models for image generation benefit from 1D coarse-to-fine ordered tokenizers rather than classical 2D grid structures, because intermediate prefixes carry semantic meaning that enables effective verifier-guided test-time search. Through controlled experiments, AR models on coarse-to-fine tokens show improved scaling with search methods (best-of-N, beam search, lookahead). It further shows that pure test-time search over token sequences (no trained AR model) can perform training-free text-to-image generation when guided by an image-text verifier. The work systematically examines interactions between token structure, search algorithms, verifiers, and AR priors.
Significance. If the central claims hold after addressing controls, the result would be significant for test-time scaling in generative models: it would demonstrate that token ordering can make intermediate states more amenable to external guidance, allowing search to substitute for or augment learned priors. The training-free generation result is a notable strength, as is the systematic ablation of search algorithms and verifiers. These findings could inform tokenizer design for efficient inference without retraining.
major comments (2)
- [§4 (Experiments)] §4 (Experiments): The attribution of improved test-time scaling to the 1D coarse-to-fine ordering is not isolated from tokenizer-level differences. The reported comparisons train AR models on distinct tokenizers (coarse-to-fine 1D vs. 2D grid), which typically vary in codebook design, hierarchy, receptive field, and partial reconstruction fidelity. Any advantage in verifier-guided search could therefore stem from easier-to-evaluate intermediate states rather than ordering per se. A controlled ablation that holds the tokenizer fixed while varying only sequence order is needed to support the central claim.
- [§5.3 (Training-free generation)] §5.3 (Training-free generation): The mechanism for pure test-time search without a trained AR model is underspecified. It is unclear how candidate token sequences are proposed or expanded in the absence of an autoregressive prior, and therefore how the coarse-to-fine property is actually leveraged beyond the verifier. This detail is load-bearing for the claim that ordered structure alone enables training-free generation.
minor comments (3)
- [Abstract] The abstract states that experiments are 'controlled,' yet the tokenizer confound noted above is not addressed; a brief clarification of what variables were held fixed would improve transparency.
- [Throughout] Notation for 'coarse-to-fine' versus '1D ordered' should be defined consistently on first use and used uniformly throughout.
- [Figures] Figure captions would benefit from explicit mention of the token structure and search method shown in each panel to aid quick reading.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments help clarify the scope of our claims regarding token ordering and test-time search. We address each major comment below and will revise the manuscript to strengthen the presentation.
read point-by-point responses
-
Referee: [§4 (Experiments)] §4 (Experiments): The attribution of improved test-time scaling to the 1D coarse-to-fine ordering is not isolated from tokenizer-level differences. The reported comparisons train AR models on distinct tokenizers (coarse-to-fine 1D vs. 2D grid), which typically vary in codebook design, hierarchy, receptive field, and partial reconstruction fidelity. Any advantage in verifier-guided search could therefore stem from easier-to-evaluate intermediate states rather than ordering per se. A controlled ablation that holds the tokenizer fixed while varying only sequence order is needed to support the central claim.
Authors: We agree that the current experiments compare models trained on distinct tokenizers and that this leaves open the possibility of confounding factors beyond ordering. While the coarse-to-fine property is tightly coupled to the tokenizer design in practice, we acknowledge that a stricter isolation would better support the central claim. In the revised manuscript we will add a controlled ablation that fixes the underlying codebook and token vocabulary while varying only the sequence ordering (raster versus coarse-to-fine traversal), allowing us to attribute performance differences more directly to ordering. revision: yes
-
Referee: [§5.3 (Training-free generation)] §5.3 (Training-free generation): The mechanism for pure test-time search without a trained AR model is underspecified. It is unclear how candidate token sequences are proposed or expanded in the absence of an autoregressive prior, and therefore how the coarse-to-fine property is actually leveraged beyond the verifier. This detail is load-bearing for the claim that ordered structure alone enables training-free generation.
Authors: We thank the referee for highlighting this underspecification. In the training-free regime, partial sequences are expanded by sampling tokens from the codebook at each step; the coarse-to-fine ordering ensures that any prefix can be decoded into a semantically meaningful (low-resolution) image that the verifier can score. Selection among candidates is performed by a verifier-guided beam search that retains only high-scoring prefixes. We will expand §5.3 with a precise algorithmic description and pseudocode in the revision so that the procedure is fully reproducible. revision: yes
Circularity Check
No circularity: empirical hypothesis tested via controlled comparisons
full rationale
The paper advances a hypothesis that coarse-to-fine 1D token ordering improves test-time search amenability because intermediate prefixes carry semantic meaning, then validates it through experiments comparing AR models trained on distinct tokenizers and pure search without AR training. No equations, derivations, or first-principles results are presented that reduce to inputs by construction; there are no fitted parameters renamed as predictions, no self-definitional loops, and no load-bearing self-citations. The work is self-contained as an empirical study whose central claims rest on observable scaling behavior and generation quality rather than tautological reasoning.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intermediate states in coarse-to-fine sequences carry semantic meaning that verifiers can reliably evaluate
Reference graph
Works this paper leans on
-
[1]
URL https://api.semanticscholar. org/CorpusID:229297973. Fu, S., Tamir, N., Sundaram, S., Chai, L., Zhang, R., Dekel, T., and Isola, P. Dreamsim: Learning new dimensions of human visual similarity using synthetic data.arXiv preprint arXiv:2306.09344, 2023. Gallici, M. and Borde, H. S. d. O. Fine-tuning next-scale visual autoregressive models with group re...
-
[2]
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
URL https://api.semanticscholar. org/CorpusID:233296711. Ho, J. and Salimans, T. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022. Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hendricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models.arXiv pr...
-
[3]
Selftok: Discrete visual tokens of autoregression, by diffusion, and for reasoning, 2025
Accessed: 2026-04. Wang, B., Yue, Z., Zhang, F., Chen, S., Bi, L., Zhang, J., Song, X., Chan, K. Y ., Pan, J., Wu, W., Zhou, M., Lin, W., Pan, K., Zhang, S., Jia, L., Hu, W., Zhao, W., and Zhang, H. Discrete visual tokens of autoregression, by diffusion, and for reasoning. 2025. URL https: //arxiv.org/abs/2505.07538. Wang, P., Li, L., Shao, Z., Xu, R., Da...
-
[4]
a red apple
formulates diffusion denoising as a multi-step Markov Decision Process and applies policy gradients to fine-tune on downstream objectives. More recently, GRPO-based methods (Shao et al., 2024) have been adapted from LLMs to visual generation: DanceGRPO (Xue et al., 2025) and Flow-GRPO (Liu et al., 2025a) adapt GRPO to diffusion and flow-based models, AR-G...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.