Recognition: unknown
From Zero to Detail: A Progressive Spectral Decoupling Paradigm for UHD Image Restoration with New Benchmark
Pith reviewed 2026-05-10 09:21 UTC · model grok-4.3
The pith
A progressive spectral decoupling into zero-, low-, and high-frequency stages with cooperative sub-networks achieves superior UHD image restoration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By decomposing UHD image restoration into zero-frequency enhancement, low-frequency restoration, and high-frequency refinement, the ERR framework integrates ZFE for holistic mappings, LFR for coarse-scale reconstruction, and HFR with FW-KAN for detail recovery, delivering superior performance across UHD restoration tasks on the new LSUHDIR benchmark as confirmed by experiments and module ablations.
What carries the argument
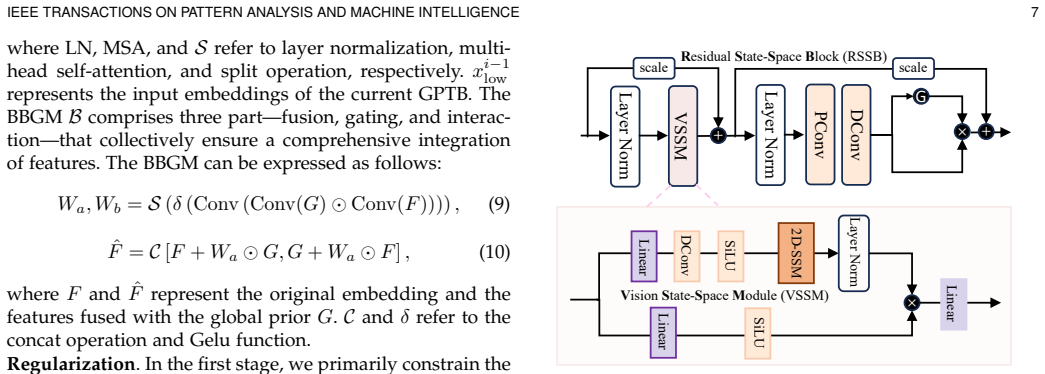
The ERR framework that couples a zero-frequency enhancer (ZFE) using global priors, a low-frequency restorer (LFR) focused on coarse information, and a high-frequency refiner (HFR) employing frequency-windowed Kolmogorov-Arnold Network (FW-KAN) to handle fine textures through progressive spectral decoupling.
If this is right
- The ZFE, LFR, and HFR modules each address distinct frequency bands and their removal reduces overall restoration quality according to the ablations.
- The LSUHDIR dataset provides a standardized large-scale testbed that future methods can use for fair comparison on diverse UHD scenes.
- The frequency-windowed Kolmogorov-Arnold Network component enables targeted recovery of intricate high-frequency details that standard convolutions struggle with.
- The overall pipeline supports multiple restoration tasks including denoising, deblurring, and enhancement while maintaining efficiency through specialization.
Where Pith is reading between the lines
- The progressive frequency separation could extend naturally to video sequences by applying the same staged processing across frames to maintain temporal consistency.
- Replacing traditional layers with frequency-windowed Kolmogorov-Arnold Networks in other high-resolution vision models might reduce parameter counts while preserving detail fidelity.
- The benchmark construction process highlights the need for content-diverse UHD data in other domains such as satellite or medical imaging.
Load-bearing premise
That breaking the restoration into separate zero-, low-, and high-frequency stages with dedicated sub-networks will reliably outperform existing single-network end-to-end methods on varied UHD images.
What would settle it
Quantitative comparison of the ERR method against leading end-to-end UHD restoration models on the LSUHDIR dataset using standard metrics such as PSNR, SSIM, and LPIPS to measure whether the staged approach yields measurable gains.
Figures





















read the original abstract
Ultra-high-definition (UHD) image restoration poses unique challenges due to the high spatial resolution, diverse content, and fine-grained structures present in UHD images. To address these issues, we introduce a progressive spectral decomposition for the restoration process, decomposing it into three stages: zero-frequency \textbf{enhancement}, low-frequency \textbf{restoration}, and high-frequency \textbf{refinement}. Based on this formulation, we propose a novel framework, \textbf{ERR}, which integrates three cooperative sub-networks: the zero-frequency enhancer (ZFE), the low-frequency restorer (LFR), and the high-frequency refiner (HFR). The ZFE incorporates global priors to learn holistic mappings, the LFR reconstructs the main content by focusing on coarse-scale information, and the HFR adopts our proposed frequency-windowed Kolmogorov-Arnold Network (FW-KAN) to recover fine textures and intricate details for high-fidelity restoration. To further advance research in UHD image restoration, we also construct a large-scale, high-quality benchmark dataset, \textbf{LSUHDIR}, comprising 82{,}126 UHD images with diverse scenes and rich content. Our proposed methods demonstrate superior performance across a range of UHD image restoration tasks, and extensive ablation studies confirm the contribution and necessity of each module. Project page: https://github.com/NJU-PCALab/ERR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a progressive spectral decoupling paradigm for UHD image restoration that decomposes the process into zero-frequency enhancement (ZFE for global priors), low-frequency restoration (LFR for coarse content), and high-frequency refinement (HFR using a proposed frequency-windowed Kolmogorov-Arnold Network for fine details). These are integrated into the ERR framework with three cooperative sub-networks. The work also introduces the LSUHDIR benchmark dataset containing 82,126 diverse UHD images and claims superior performance across UHD restoration tasks, with ablations confirming the necessity of each module.
Significance. If the empirical results hold after controlling for capacity, the work would offer a structured frequency-aware approach to UHD restoration that could improve detail recovery over monolithic end-to-end networks, while the new large-scale dataset would provide a valuable community resource for high-resolution image restoration research.
major comments (2)
- [Abstract] Abstract: The central claim of superior performance due to progressive spectral decoupling is not isolated from the increased model capacity introduced by deploying three distinct sub-networks (ZFE, LFR, HFR). Without explicit comparisons to capacity-matched or scaled baselines (e.g., single-network models with equivalent parameters or FLOPs), gains cannot be confidently attributed to the frequency-specific stages rather than total compute.
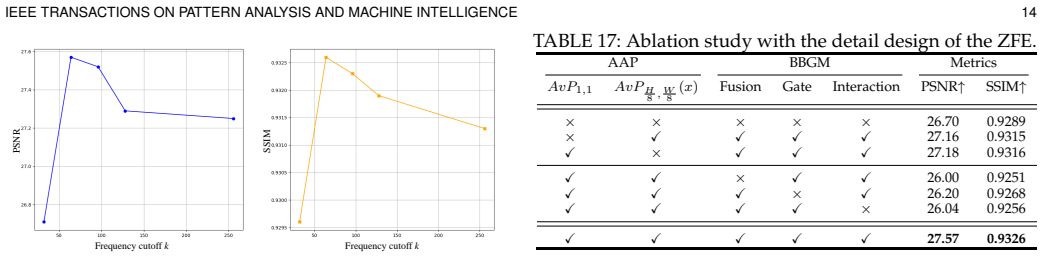
- [Ablation studies] Ablation studies: The manuscript states that ablations confirm the contribution and necessity of each module, yet provides no indication that these controls hold total parameter count or FLOPs fixed across variants. This leaves open the possibility that observed improvements stem from added capacity rather than the cooperative spectral decomposition.
minor comments (1)
- [Abstract] The acronym ERR is introduced without expansion in the abstract, which reduces immediate clarity for readers unfamiliar with the framework.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of superior performance due to progressive spectral decoupling is not isolated from the increased model capacity introduced by deploying three distinct sub-networks (ZFE, LFR, HFR). Without explicit comparisons to capacity-matched or scaled baselines (e.g., single-network models with equivalent parameters or FLOPs), gains cannot be confidently attributed to the frequency-specific stages rather than total compute.
Authors: We acknowledge that the current presentation does not isolate the contribution of progressive spectral decoupling from the total model capacity of the three-subnetwork architecture. While the design intentionally assigns specialized roles—ZFE for global priors, LFR for coarse content, and HFR with the frequency-windowed KAN for fine details—the referee is correct that direct attribution requires capacity-controlled comparisons. In the revised manuscript we will add experiments comparing ERR against single-network baselines scaled to match both parameter count and FLOPs, allowing readers to evaluate whether the frequency-specific stages provide benefits beyond increased compute. revision: yes
-
Referee: [Ablation studies] Ablation studies: The manuscript states that ablations confirm the contribution and necessity of each module, yet provides no indication that these controls hold total parameter count or FLOPs fixed across variants. This leaves open the possibility that observed improvements stem from added capacity rather than the cooperative spectral decomposition.
Authors: We agree that the ablation studies as currently reported do not hold total parameter count or FLOPs fixed, which limits the strength of claims about the necessity of the cooperative spectral decomposition. The existing ablations demonstrate the effect of removing or altering individual sub-networks, but do not adjust architecture dimensions to equalize capacity. We will revise the ablation section to include capacity-matched variants (e.g., by scaling channel widths or depths in ablated models) and report both parameter counts and FLOPs, thereby providing clearer evidence that performance differences arise from the frequency-aware design rather than capacity differences. revision: yes
Circularity Check
No circularity: empirical architecture and benchmark validation
full rationale
The paper proposes an empirical framework (ERR) that decomposes UHD restoration into zero-, low-, and high-frequency stages implemented via cooperative sub-networks (ZFE, LFR, HFR with FW-KAN) plus a new dataset (LSUHDIR). Superiority claims rest on external benchmark comparisons and internal ablations, not on any equation or parameter that reduces to its own fitted inputs by construction. No self-citation load-bearing uniqueness theorems, no ansatz smuggled via prior work, and no renaming of known results as new derivations appear in the provided text. The derivation chain is a standard engineering pipeline whose outputs are falsifiable against independent test sets.
Axiom & Free-Parameter Ledger
free parameters (1)
- network hyperparameters and training schedule
axioms (1)
- domain assumption UHD images can be meaningfully decomposed into zero-, low-, and high-frequency components that can be restored independently by specialized sub-networks.
Forward citations
Cited by 1 Pith paper
-
L2P: Unlocking Latent Potential for Pixel Generation
L2P repurposes pre-trained LDMs for direct pixel generation via large-patch tokenization and shallow-layer training on synthetic data, matching source performance with 8-GPU training and enabling native 4K output.
Reference graph
Works this paper leans on
-
[1]
Embedding fourier for ultra-high-definition low-light image enhancement
C. Li, C.-L. Guo, M. Zhou, Z. Liang, S. Zhou, R. Feng, and C. C. Loy, “Embedding Fourier for ultra-high-definition low-light image enhancement,”arXiv preprint arXiv:2302.11831, 2023
-
[2]
Towards ef- ficient and scale-robust ultra-high-definition image demoiréing,
X. Yu, P . Dai, W. Li, L. Ma, J. Shen, J. Li, and X. Qi, “Towards ef- ficient and scale-robust ultra-high-definition image demoiréing,” inProc. Eur. Conf. Comput. Vis. (ECCV), 2022, pp. 646–662
2022
-
[3]
Ultra-high-definition image dehazing via multi-guided bilateral learning,
Z. Zheng, W. Ren, X. Cao, X. Hu, T. Wang, F. Song, and X. Jia, “Ultra-high-definition image dehazing via multi-guided bilateral learning,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 16 180–16 189
2021
-
[4]
Multi- scale separable network for ultra-high-definition video deblur- ring,
S. Deng, W. Ren, Y. Yan, T. Wang, F. Song, and X. Cao, “Multi- scale separable network for ultra-high-definition video deblur- ring,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 14 030–14 039
2021
-
[5]
UHDNeRF: Ultra-high-definition neural radiance fields,
Q. Li, F. Li, J. Guo, and Y. Guo, “UHDNeRF: Ultra-high-definition neural radiance fields,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 23 097–23 108
2023
-
[6]
Ultra-high resolution segmentation via boundary-enhanced patch-merging transformer,
H. Sun, Y. Zhang, L. Xu, S. Jin, and Y. Chen, “Ultra-high resolution segmentation via boundary-enhanced patch-merging transformer,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2025, pp. 7087–7095
2025
-
[7]
Correlation matching transformation Transformers for UHD image restoration,
C. Wang, J. Pan, W. Wang, G. Fu, S. Liang, M. Wang, X.-M. Wu, and J. Liu, “Correlation matching transformation Transformers for UHD image restoration,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2024, pp. 5336–5344
2024
-
[8]
Towards ultra-high-definition image deraining: A benchmark and an effi- cient method,
H. Chen, X. Chen, C. Wu, Z. Zheng, J. Pan, and X. Fu, “Towards ultra-high-definition image deraining: A benchmark and an effi- cient method,”IEEE Trans. Multimedia (TMM), pp. 1–13, 2026
2026
-
[9]
SwinIR: Image restoration using Swin Transformer,
J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, and R. Timofte, “SwinIR: Image restoration using Swin Transformer,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 1833–1844
2021
-
[10]
Restormer: Efficient Transformer for high-resolution image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, and M.- H. Yang, “Restormer: Efficient Transformer for high-resolution image restoration,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 5728–5739
2022
-
[11]
Learn- ing multi-scale spatial-frequency features for image denoising,
X. Zhao, C. Zhao, X. Hu, H. Zhang, Y. Tai, and J. Yang, “Learn- ing multi-scale spatial-frequency features for image denoising,” arXiv preprint arXiv:2506.16307, 2025
-
[12]
More realistic and accurate precipitation nowcasting with conditional rectified flow transformers,
Y. Zhou, C. Zhao, F. Ji, R. Hang, Q. Liu, and X.-T. Yuan, “More realistic and accurate precipitation nowcasting with conditional rectified flow transformers,”Engineering Applications of Artificial Intelligence, vol. 165, p. 113402, 2026
2026
-
[13]
Multi-cropping contrastive learning and domain consistency for unsupervised image-to-image translation,
C. Zhao, W.-L. Cai, Z. Yuan, and C.-W. Hu, “Multi-cropping contrastive learning and domain consistency for unsupervised image-to-image translation,”IET Image Processing, vol. 19, no. 1, p. e70006, 2025
2025
-
[14]
O-mamba: O- shape state-space model for underwater image enhancement,
C. Dong, C. Zhao, W. Cai, B. Yang, and Y. Guo, “O-mamba: O- shape state-space model for underwater image enhancement,” inChinese Conference on Pattern Recognition and Computer Vision (PRCV). Springer, 2025, pp. 168–182
2025
-
[15]
Cycle contrastive adver- sarial learning with structural consistency for unsupervised high- quality image deraining transformer,
C. Zhao, W. Cai, C. Hu, and Z. Yuan, “Cycle contrastive adver- sarial learning with structural consistency for unsupervised high- quality image deraining transformer,”Neural Networks, vol. 178, p. 106428, 2024
2024
-
[16]
Spectral normalization and dual contrastive regularization for image-to-image translation,
C. Zhao, W.-L. Cai, and Z. Yuan, “Spectral normalization and dual contrastive regularization for image-to-image translation,” The Visual Computer, vol. 41, no. 1, pp. 129–140, 2025
2025
-
[17]
R. Xie, C. Zhao, K. Zhang, Z. Zhang, J. Zhou, J. Yang, and Y. Tai, “Addsr: Accelerating diffusion-based blind super- resolution with adversarial diffusion distillation,”arXiv preprint arXiv:2404.01717, 2024
-
[18]
Exploiting multimodal spatial-temporal patterns for video object tracking,
X. Hu, Y. Tai, X. Zhao, C. Zhao, Z. Zhang, J. Li, B. Zhong, and J. Yang, “Exploiting multimodal spatial-temporal patterns for video object tracking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 4, 2025, pp. 3581–3589
2025
-
[19]
Ultrahr-100k: Enhancing uhr image synthesis with a large-scale high-quality dataset,
C. Zhao, E. Ci, Y. Xu, T. Fan, S. Guan, Y. Ge, J. Yang, and Y. Tai, “Ultrahr-100k: Enhancing uhr image synthesis with a large-scale high-quality dataset,”Advances in Neural Information Processing Systems, 2025
2025
-
[20]
C. Zhao, J. Chen, H. Li, Z. Kang, S. Lu, X. Wei, K. Zhang, J. Yang, and Y. Tai, “Luve: Latent-cascaded ultra-high-resolution video generation with dual frequency experts,”arXiv preprint arXiv:2602.11564, 2026
-
[21]
TF-ICON: Diffusion- based training-free cross-domain image composition,
S. Lu, Y. Liu, and A. W.-K. Kong, “TF-ICON: Diffusion- based training-free cross-domain image composition,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023, pp. 2294–2305
2023
-
[22]
Learning a physical- aware diffusion model based on Transformer for underwater image enhancement,
C. Zhao, C. Dong, W. Cai, and Y. Wang, “Learning a physical- aware diffusion model based on Transformer for underwater image enhancement,”IEEE Trans. Geosci. Remote Sens. (TGRS), vol. 64, pp. 1–14, 2026
2026
-
[23]
Adapt or perish: Adaptive sparse Transformer with attentive feature refinement for image restoration,
S. Zhou, D. Chen, J. Pan, J. Shi, and J. Yang, “Adapt or perish: Adaptive sparse Transformer with attentive feature refinement for image restoration,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 2952–2963
2024
-
[24]
Efficient and explicit modelling of image hierar- chies for image restoration,
Y. Li, Y. Fan, X. Xiang, D. Demandolx, R. Ranjan, R. Timofte, and L. Van Gool, “Efficient and explicit modelling of image hierar- chies for image restoration,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2023, pp. 18 278–18 289
2023
-
[25]
Distilling semantic priors from SAM to efficient image restoration models,
Q. Zhang, X. Liu, W. Li, H. Chen, J. Liu, J. Hu, Z. Xiong, C. Yuan, and Y. Wang, “Distilling semantic priors from SAM to efficient image restoration models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 25 409–25 419
2024
-
[26]
HomoFormer: Homogenized Transformer for image shadow removal,
J. Xiao, X. Fu, Y. Zhu, D. Li, J. Huang, K. Zhu, and Z.-J. Zha, “HomoFormer: Homogenized Transformer for image shadow removal,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 25 617–25 626
2024
-
[27]
Migc: Multi- instance generation controller for text-to-image synthesis,
D. Zhou, Y. Li, F. Ma, X. Zhang, and Y. Yang, “Migc: Multi- instance generation controller for text-to-image synthesis,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 6818–6828
2024
-
[28]
Mace: Mass IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 17 concept erasure in diffusion models,
S. Lu, Z. Wang, L. Li, Y. Liu, and A. W.-K. Kong, “Mace: Mass IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 17 concept erasure in diffusion models,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 6430–6440
2024
-
[29]
Rethinking 3d convolution inℓ p-norm space,
L. Zhang, Y. Zhong, J. Wang, Z. Min, L. Liuet al., “Rethinking 3d convolution inℓ p-norm space,” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[30]
Gapt-dar: Category-level garments pose tracking via integrated 2d deformation and 3d reconstruction,
L. Zhang, M. Xu, J. Wang, Q. Yu, L. Yang, Y. Li, C. Lu, R. Wang, and L. Liu, “Gapt-dar: Category-level garments pose tracking via integrated 2d deformation and 3d reconstruction,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 22 638–22 647
2025
-
[31]
Rˆ 2-art: Category-level articulation pose estimation from single rgb image via cascade render strategy,
L. Zhang, H. Jiang, Y. Huo, Y. Zhong, J. Wang, X. Wang, R. Wang, and L. Liu, “Rˆ 2-art: Category-level articulation pose estimation from single rgb image via cascade render strategy,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 9, 2025, pp. 9985–9993
2025
-
[32]
Vocapter: Voting- based pose tracking for category-level articulated object via inter- frame priors,
L. Zhang, Z. Han, Y. Zhong, Q. Yu, X. Wuet al., “Vocapter: Voting- based pose tracking for category-level articulated object via inter- frame priors,” inACM Multimedia 2024, 2024
2024
-
[33]
U-cope: Taking a further step to universal 9d category-level object pose estimation,
L. Zhang, W. Meng, Y. Zhong, B. Kong, M. Xu, J. Du, X. Wang, R. Wang, and L. Liu, “U-cope: Taking a further step to universal 9d category-level object pose estimation,” inEuropean Conference on Computer Vision. Springer, 2025, pp. 254–270
2025
-
[34]
D. Zhou, M. Li, Z. Yang, Y. Lu, Y. Xu, Z. Wang, Z. Huang, and Y. Yang, “Bidedpo: Conditional image generation with simultaneous text and condition alignment,”arXiv preprint arXiv:2511.19268, 2025
-
[35]
Wave-Mamba: Wavelet state space model for ultra-high-definition low-light image en- hancement,
W. Zou, H. Gao, W. Yang, and T. Liu, “Wave-Mamba: Wavelet state space model for ultra-high-definition low-light image en- hancement,” inProc. ACM Int. Conf. Multimedia (ACM MM), 2024, pp. 1534–1543
2024
-
[36]
Ultra- high-definition low-light image enhancement: A benchmark and Transformer-based method,
T. Wang, K. Zhang, T. Shen, W. Luo, B. Stenger, and T. Lu, “Ultra- high-definition low-light image enhancement: A benchmark and Transformer-based method,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2023, pp. 2654–2662
2023
-
[37]
arXiv preprint arXiv:2305.10028 , year=
D. Zhou, Z. Yang, and Y. Yang, “Pyramid diffusion models for low-light image enhancement,”arXiv preprint arXiv:2305.10028, 2023
-
[38]
Migc++: Advanced multi-instance generation controller for image synthesis,
D. Zhou, Y. Li, F. Ma, Z. Yang, and Y. Yang, “Migc++: Advanced multi-instance generation controller for image synthesis,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[39]
D. Zhou, J. Xie, Z. Yang, and Y. Yang, “3dis: Depth-driven decoupled instance synthesis for text-to-image generation,”arXiv preprint arXiv:2410.12669, 2024
-
[40]
Dreamrenderer: Taming multi-instance attribute control in large-scale text-to-image mod- els,
D. Zhou, M. Li, Z. Yang, and Y. Yang, “Dreamrenderer: Taming multi-instance attribute control in large-scale text-to-image mod- els,”arXiv preprint arXiv:2503.12885, 2025
-
[41]
D. Zhou, J. Xie, Z. Yang, and Y. Yang, “3dis-flux: simple and efficient multi-instance generation with dit rendering,”arXiv preprint arXiv:2501.05131, 2025
-
[42]
R. Xu, D. Zhou, F. Ma, and Y. Yang, “Contextgen: Contextual lay- out anchoring for identity-consistent multi-instance generation,” arXiv preprint arXiv:2510.11000, 2025
-
[43]
PhyEdit: Towards Real-World Object Manipulation via Physically-Grounded Image Editing
R. Xu, D. Zhou, X. Shen, F. Ma, and Y. Yang, “Phyedit: Towards real-world object manipulation via physically-grounded image editing,”arXiv preprint arXiv:2604.07230, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Learning non-uniform-sampling for ultra-high-definition image enhancement,
W. Yu, Q. Zhu, N. Zheng, J. Huang, M. Zhou, and F. Zhao, “Learning non-uniform-sampling for ultra-high-definition image enhancement,” inProc. ACM Int. Conf. Multimedia (ACM MM), 2023, pp. 1412–1421
2023
-
[45]
P-BiC: Ultra-high-definition image moiré patterns removal via patch bilateral compensation,
Z. Xiao, Z. Lu, and X. Wang, “P-BiC: Ultra-high-definition image moiré patterns removal via patch bilateral compensation,” in Proc. ACM Int. Conf. Multimedia (ACM MM), 2024, pp. 8365–8373
2024
-
[46]
DreamUHD: Frequency enhanced variational autoencoder for ultra-high- definition image restoration,
Y. Liu, D. Li, J. Xiao, Y. Bao, S. Xu, and X. Fu, “DreamUHD: Frequency enhanced variational autoencoder for ultra-high- definition image restoration,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2025, pp. 5712–5720
2025
-
[47]
Neural discrimination-prompted Transformers for efficient UHD image restoration and enhancement,
C. Wang, J. Pan, L. Wang, W. Wang, and Y. Yang, “Neural discrimination-prompted Transformers for efficient UHD image restoration and enhancement,”Int. J. Comput. Vis. (IJCV), vol. 134, no. 3, p. 84, 2026
2026
-
[48]
Deep learning-driven ultra-high-definition image restoration: A survey,
L. Wang, W. Zhou, C. Wang, K.-M. Lam, Z. Su, and J. Pan, “Deep learning-driven ultra-high-definition image restoration: A survey,”arXiv preprint arXiv:2505.16161, 2025
-
[49]
Empowering resampling operation for ultra-high- definition image enhancement with model-aware guidance,
W. Yu, J. Huang, B. Li, K. Zheng, Q. Zhu, M. Zhou, and F. Zhao, “Empowering resampling operation for ultra-high- definition image enhancement with model-aware guidance,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2024, pp. 25 722–25 731
2024
-
[50]
Signals and the frequency domain,
C.-Z. Lee, “Signals and the frequency domain,” https://web.stanford.edu/class/archive/engr/engr40m.1178/ slides/signals.pdf, 2017
2017
-
[51]
Multi-scale progressive fusion network for single image deraining,
K. Jiang, Z. Wang, P . Yi, C. Chen, B. Huang, Y. Luo, J. Ma, and J. Jiang, “Multi-scale progressive fusion network for single image deraining,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2020, pp. 8346–8355
2020
-
[52]
Multi-stage progressive image restoration,
S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan, M.-H. Yang, and L. Shao, “Multi-stage progressive image restoration,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021, pp. 14 821–14 831
2021
-
[53]
Benchmarking ultra-high-definition image super- resolution,
K. Zhang, D. Li, W. Luo, W. Ren, B. Stenger, W. Liu, H. Li, and M.-H. Yang, “Benchmarking ultra-high-definition image super- resolution,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 14 769–14 778
2021
-
[54]
Ultra-high-definition image restoration: New benchmarks and a dual interaction prior-driven solution,
L. Wang, C. Wang, J. Pan, X. Liu, W. Zhou, X. Sun, W. Wang, and Z. Su, “Ultra-high-definition image restoration: New benchmarks and a dual interaction prior-driven solution,”IEEE Trans. Circuits Syst. Video Technol. (TCSVT), vol. 36, no. 2, pp. 2052–2068, 2026
2052
-
[55]
From zero to detail: Deconstructing ultra-high-definition image restoration from progressive spectral perspective,
C. Zhao, Z. Chen, Y. Xu, E. Gu, J. Li, Z. Yi, Q. Wang, J. Yang, and Y. Tai, “From zero to detail: Deconstructing ultra-high-definition image restoration from progressive spectral perspective,” inProc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2025, pp. 17 935–17 946
2025
-
[56]
RefineAnything: Multimodal Region-Specific Refinement for Perfect Local Details
D. Zhou, Y. Li, Z. Yang, and Y. Yang, “Refineanything: Multi- modal region-specific refinement for perfect local details,”arXiv preprint arXiv:2604.06870, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
Image super-resolution using deep convolutional networks,
C. Dong, C. C. Loy, K. He, and X. Tang, “Image super-resolution using deep convolutional networks,”IEEE Trans. Pattern Anal. Mach. Intell. (TP AMI), vol. 38, no. 2, pp. 295–307, 2015
2015
-
[58]
Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising,
K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang, “Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising,”IEEE Trans. Image Process. (TIP), vol. 26, no. 7, pp. 3142–3155, 2017
2017
-
[59]
Robust watermarking using generative priors against image editing: From benchmarking to advances
S. Lu, Z. Zhou, J. Lu, Y. Zhu, and A. W.-K. Kong, “Robust wa- termarking using generative priors against image editing: From benchmarking to advances,”arXiv preprint arXiv:2410.18775, 2024
-
[60]
Eraseanything: Enabling concept erasure in rec- tified flow transformers,
D. Gao, S. Lu, W. Zhou, J. Chu, J. Zhang, M. Jia, B. Zhang, Z. Fan, and W. Zhang, “Eraseanything: Enabling concept erasure in rec- tified flow transformers,” inForty-second International Conference on Machine Learning, 2025
2025
-
[61]
Set you straight: Auto- steering denoising trajectories to sidestep unwanted concepts,
L. Li, S. Lu, Y. Ren, and A. W.-K. Kong, “Set you straight: Auto- steering denoising trajectories to sidestep unwanted concepts,” in Proceedings of the 33rd ACM International Conference on Multimedia, 2025, pp. 9257–9266
2025
-
[62]
arXiv preprint arXiv:2510.02253 (2025)
Z. Zhou, S. Lu, S. Leng, S. Zhang, Z. Lian, X. Yu, and A. W.- K. Kong, “Dragflow: Unleashing dit priors with region based supervision for drag editing,”arXiv preprint arXiv:2510.02253, 2025
-
[63]
Exposing and defending the achilles’ heel of video mixture-of-experts,
S. Wang, Q. Liu, Y. Lyu, N. Li, Z. He, and C. Shan, “Exposing and defending the achilles’ heel of video mixture-of-experts,”arXiv preprint arXiv:2602.01369, 2026
-
[64]
Efficient robustness assessment via adversarial spatial-temporal focus on videos,
X. Wei, S. Wang, and H. Yan, “Efficient robustness assessment via adversarial spatial-temporal focus on videos,”IEEE Trans. Pattern Anal. Mach. Intell. (TP AMI), vol. 45, no. 9, pp. 10 898–10 912, 2023
2023
-
[65]
Fast adversarial training with weak-to-strong spatial- temporal consistency in the frequency domain on videos,
S. Wang, H. Liu, Y. Lyu, X. Hu, Z. He, W. Wang, C. Shan, and L. Wang, “Fast adversarial training with weak-to-strong spatial- temporal consistency in the frequency domain on videos,”IEEE Transactions on Information Forensics and Security, vol. 21, pp. 681– 696, 2025
2025
-
[66]
Runawayevil: Jailbreaking the image-to-video gener- ative models,
S. Wang, R. Qian, Y. Lyu, Q. Liu, L. Zou, J. Qin, S. Liu, and C. Shan, “Runawayevil: Jailbreaking the image-to-video gener- ative models,”arXiv preprint arXiv:2512.06674, 2025
-
[67]
FCANet: Frequency channel attention networks,
Z. Qin, P . Zhang, F. Wu, and X. Li, “FCANet: Frequency channel attention networks,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021, pp. 783–792
2021
-
[68]
Frequency separation for real-world super-resolution,
M. Fritsche, S. Gu, and R. Timofte, “Frequency separation for real-world super-resolution,” inProc. IEEE/CVF Int. Conf. Comput. Vis. Worksh. (ICCVW), 2019, pp. 3599–3608
2019
-
[69]
Intriguing findings of frequency selection for image deblurring,
X. Mao, Y. Liu, F. Liu, Q. Li, W. Shen, and Y. Wang, “Intriguing findings of frequency selection for image deblurring,” inProc. AAAI Conf. Artif. Intell. (AAAI), 2023, pp. 1905–1913. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 18
2023
-
[70]
Diffusion model for camouflaged object detection,
Z. Chen, R. Gao, T.-Z. Xiang, and F. Lin, “Diffusion model for camouflaged object detection,”arXiv preprint arXiv:2308.00303, 2023
-
[71]
Ragd: Regional-aware diffusion model for text-to- image generation,
Z. Chen, Y. Li, H. Wang, Z. Chen, Z. Jiang, J. Li, Q. Wang, J. Yang, and Y. Tai, “Ragd: Regional-aware diffusion model for text-to- image generation,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 19 331–19 341
2025
-
[72]
arXiv preprint arXiv:2503.23461 (2025)
N. Du, Z. Chen, S. Gao, Z. Chen, X. Chen, Z. Jiang, J. Yang, and Y. Tai, “Textcrafter: Accurately rendering multiple texts in complex visual scenes,”arXiv preprint arXiv:2503.23461, 2025
-
[73]
Dip: Taming diffusion models in pixel space
Z. Chen, J. Zhu, X. Chen, J. Zhang, X. Hu, H. Zhao, C. Wang, J. Yang, and Y. Tai, “Dip: Taming diffusion models in pixel space,” arXiv preprint arXiv:2511.18822, 2025
-
[74]
Adaptive guid- ance learning for camouflaged object detection,
Z. Chen, X. Zhang, T.-Z. Xiang, and Y. Tai, “Adaptive guid- ance learning for camouflaged object detection,”arXiv preprint arXiv:2405.02824, 2024
-
[75]
arXiv preprint arXiv:2509.21278 , year=
S. Lu, Z. Lian, Z. Zhou, S. Zhang, C. Zhao, and A. W.-K. Kong, “Does FLUX already know how to perform physically plausible image composition?”arXiv preprint arXiv:2509.21278, 2025
-
[76]
A general spatial-frequency learning framework for multimodal image fusion,
M. Zhou, J. Huang, K. Yan, D. Hong, X. Jia, J. Chanussot, and C. Li, “A general spatial-frequency learning framework for multimodal image fusion,”IEEE Trans. Pattern Anal. Mach. Intell. (TP AMI), vol. 47, no. 7, pp. 5281–5298, 2025
2025
-
[77]
Toward sufficient spatial-frequency interaction for gradient-aware underwater im- age enhancement,
C. Zhao, W. Cai, C. Dong, and Z. Zeng, “Toward sufficient spatial-frequency interaction for gradient-aware underwater im- age enhancement,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process. (ICASSP), 2024, pp. 3220–3224
2024
-
[78]
Image restoration via fre- quency selection,
Y. Cui, W. Ren, X. Cao, and A. Knoll, “Image restoration via fre- quency selection,”IEEE Trans. Pattern Anal. Mach. Intell. (TP AMI), vol. 46, no. 2, pp. 1093–1108, 2023
2023
-
[79]
Resolution-robust large mask inpainting with Fourier convolutions,
R. Suvorov, E. Logacheva, A. Mashikhin, A. Remizova, A. Ashukha, A. Silvestrov, N. Kong, H. Goka, K. Park, and V . Lempitsky, “Resolution-robust large mask inpainting with Fourier convolutions,” inProc. IEEE/CVF Winter Conf. Appl. Com- put. Vis. (WACV), 2022, pp. 2149–2159
2022
-
[80]
Fourmer: An efficient global modeling paradigm for image restoration,
M. Zhou, J. Huang, C.-L. Guo, and C. Li, “Fourmer: An efficient global modeling paradigm for image restoration,” inProc. Int. Conf. Mach. Learn. (ICML), 2023, pp. 42 589–42 601
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.