Recognition: unknown
DepCap: Adaptive Block-Wise Parallel Decoding for Efficient Diffusion LM Inference
Pith reviewed 2026-05-10 08:47 UTC · model grok-4.3
The pith
DepCap adaptively sizes decoding blocks via last-block influence and selects conflict-free tokens for parallel steps to accelerate diffusion LM inference up to 5.63 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DepCap is a training-free framework that instantiates the cross-step signal as the influence of the last decoded block to adaptively determine how far the next block should extend, while identifying a conflict-free subset of tokens for safe parallel decoding within each block, enabling substantial inference acceleration with negligible quality degradation.
What carries the argument
Adaptive block partitioning based on cumulative last-block influence together with token-level conflict detection to enable safe parallel decoding.
If this is right
- DepCap achieves up to 5.63× speedup across multiple DLM backbones on reasoning and coding benchmarks with no significant performance degradation.
- The approach is plug-and-play and works with existing KV-cache strategies for block-wise DLM inference.
- An information-theoretic analysis shows that the cumulative last-block influence on a candidate block is approximately additive across tokens.
- The method applies to various diffusion language models without retraining.
Where Pith is reading between the lines
- The adaptive boundary rule could respond to varying sequence difficulty in real-time generation tasks.
- DepCap might combine with other acceleration techniques such as quantization for compounded speed gains.
- Similar last-block influence signals could be tested in non-diffusion sequence models that use block decoding.
- Longer sequences might show whether the additivity assumption holds or requires periodic resets.
Load-bearing premise
The influence of the last decoded block reliably indicates suitable boundaries for the next block and token-level conflict signals allow parallel decoding without quality loss.
What would settle it
Running the same benchmarks with fixed block sizes instead of adaptive last-block influence and observing that the adaptive version produces measurably lower quality at the same or higher speeds.
Figures

read the original abstract
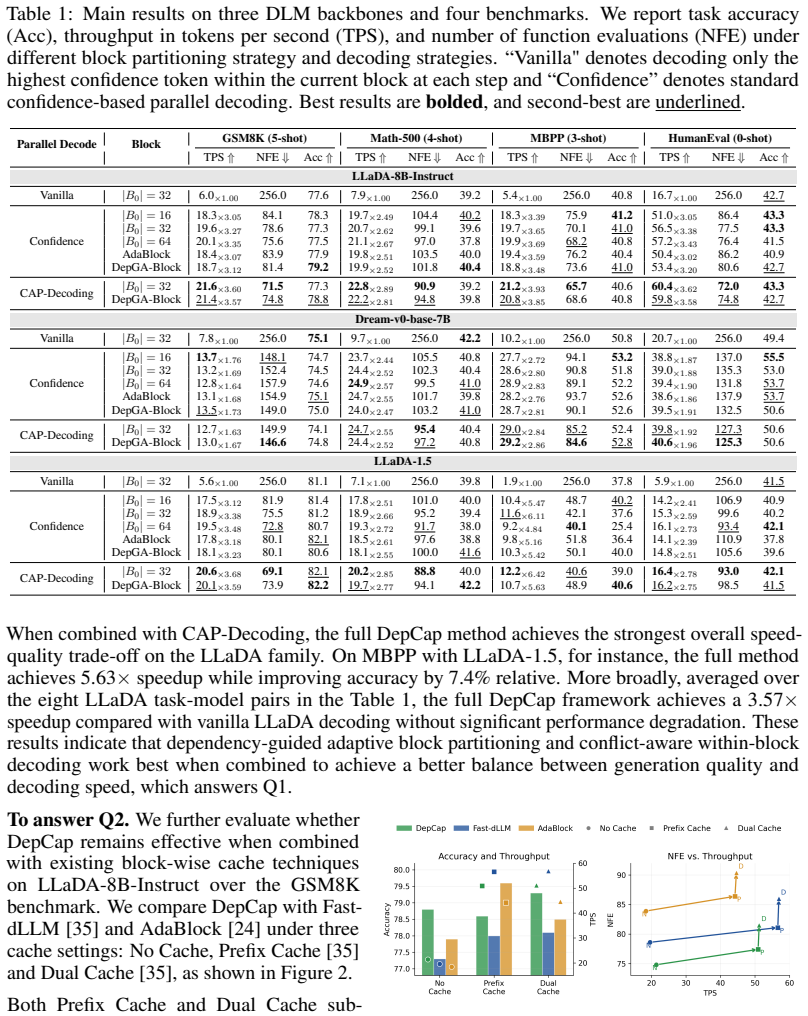
Diffusion language models (DLMs) have emerged as a promising alternative to autoregressive language generation due to their potential for parallel decoding and global refinement of the entire sequence. To unlock this potential, DLM inference must carefully balance generation quality and decoding speed. Recent block-wise DLM decoding methods improve this trade-off by performing diffusion-based decoding sequentially in blocks. However, existing methods typically rely on fixed block schedules or current-step local signals to determine block boundaries, and use conservative confidence-based parallel decoding to avoid conflicts, limiting the quality-speed trade-off. In this paper, we argue that block-wise DLM inference requires more suitable signals for its two core decisions: cross-step signals for determining block boundaries, and token-level conflict signals for parallel decoding. Based on this view, we propose DepCap, a training-free framework for efficient block-wise DLM inference. Specifically, DepCap instantiates the cross-step signal as the influence of the last decoded block and uses it to adaptively determine how far the next block should extend, while identifying a conflict-free subset of tokens for safe parallel decoding within each block, enabling substantial inference acceleration with negligible quality degradation. DepCap is a plug-and-play method applicable to various DLMs, and compatible with existing KV-cache strategies for block-wise DLM. An information-theoretic analysis further suggests that the cumulative last-block influence on a candidate block is approximately additive across tokens, supporting the proposed block-partitioning criterion. Experimental results show that DepCap achieves favorable speed-quality trade-offs across multiple DLM backbones and reasoning and coding benchmarks, with up to 5.63$\times$ speedup without significant performance degradation.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No significant circularity; derivation is self-contained and training-free
full rationale
The paper's core method (DepCap) is explicitly training-free and plug-and-play. Block boundaries are set using the influence of the last decoded block as a cross-step signal, and parallel decoding uses token-level conflict signals; neither reduces by construction to a fitted parameter or self-referential definition. The supporting information-theoretic analysis of additivity is presented as an independent justification for the partitioning criterion rather than a tautology. Empirical speedups (up to 5.63×) are reported on external benchmarks without any equations that rename a fit as a prediction. No self-citation chains, uniqueness theorems, or ansatzes are load-bearing in the provided derivation. This is the expected outcome for a heuristic inference-acceleration framework validated externally.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Cross-step signals from the last decoded block can be used to adaptively determine block boundaries.
- domain assumption Token-level conflict signals allow identification of a safe subset for parallel decoding within each block.
Reference graph
Works this paper leans on
-
[1]
Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and V olodymyr Kuleshov. Block diffusion: Interpolating between au- toregressive and diffusion language models. InProceedings of the 13th International Conference on Learning Representations, Singapore, Singapore, 2025
2025
-
[2]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. Struc- tured denoising diffusion models in discrete state-spaces. InAdvances in Neural Information Processing Systems 34, pages 17981–17993, Virtual Event, 2021
2021
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell I. Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V . Le, and Charles Sutton. Program synthesis with large language models.CoRR, abs/2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Learning to parallel: Accelerating diffusion large language models via adaptive parallel decoding
Wenrui Bao, Zhiben Chen, Dan Xu, and Yuzhang Shang. Learning to parallel: Accelerating diffusion large language models via adaptive parallel decoding. InProceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026
2026
-
[5]
LLaDA2.0: Scaling Up Diffusion Language Models to 100B
Tiwei Bie, Maosong Cao, Kun Chen, Lun Du, Mingliang Gong, Zhuochen Gong, Yanmei Gu, Jiaqi Hu, Zenan Huang, Zhenzhong Lan, Chengxi Li, Chongxuan Li, Jianguo Li, Zehuan Li, Huabin Liu, Lin Liu, Guoshan Lu, Xiaocheng Lu, Yuxin Ma, Jianfeng Tan, Lanning Wei, Ji-Rong Wen, Yipeng Xing, Xiaolu Zhang, Junbo Zhao, Da Zheng, Jun Zhou, Junlin Zhou, Zhanchao Zhou, Li...
work page internal anchor Pith review arXiv 2025
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
dParallel: Learnable parallel decoding for dLLMs
Zigeng Chen, Gongfan Fang, Xinyin Ma, Ruonan Yu, and Xinchao Wang. dParallel: Learnable parallel decoding for dLLMs. InProceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026
2026
-
[8]
Shuang Cheng, Yihan Bian, Dawei Liu, Linfeng Zhang, Qian Yao, Zhongbo Tian, Wenhai Wang, Qipeng Guo, Kai Chen, Biqing Qi, and Bowen Zhou. SDAR: A synergistic diffusion- autoregression paradigm for scalable sequence generation.CoRR, abs/2510.06303, 2025
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.CoRR, abs/2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
DiffuSeq: Sequence to sequence text generation with diffusion models
Shansan Gong, Mukai Li, Jiangtao Feng, Zhiyong Wu, and Lingpeng Kong. DiffuSeq: Sequence to sequence text generation with diffusion models. InProceedings of the 11th International Conference on Learning Representations, Kigali, Rwanda, 2023
2023
-
[11]
Scaling diffusion language models via adaptation from autoregressive models
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, Hao Peng, and Lingpeng Kong. Scaling diffusion language models via adaptation from autoregressive models. InProceedings of the 13th International Conference on Learning Representations, Singapore, Singapore, 2025
2025
-
[12]
DiffuCoder: Understanding and improving masked diffusion models for code generation
Shansan Gong, Ruixiang Zhang, Huangjie Zheng, Jiatao Gu, Navdeep Jaitly, Lingpeng Kong, and Yizhe Zhang. DiffuCoder: Understanding and improving masked diffusion models for code generation. InProceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026. 10
2026
-
[13]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems 33, Virtual Event, 2020
2020
-
[14]
Abdelfattah, Jae-sun Seo, Zhiru Zhang, and Udit Gupta
Zhanqiu Hu, Jian Meng, Yash Akhauri, Mohamed S. Abdelfattah, Jae-sun Seo, Zhiru Zhang, and Udit Gupta. Accelerating diffusion language model inference via efficient KV caching and guided diffusion. InProceedings of the 14th International Conference on Learning Representa- tions, Rio de Janeiro, Brazil, 2026
2026
-
[15]
Reinforcing the diffusion chain of lateral thought with diffusion language models
Zemin Huang, Zhiyang Chen, Zijun Wang, Tiancheng Li, and Guo-Jun Qi. Reinforcing the diffusion chain of lateral thought with diffusion language models. InAdvances in Neural Information Processing Systems 39, San Diego, CA, 2025
2025
-
[16]
Accelerating diffusion LLMs via adaptive parallel decoding
Daniel Israel, Guy Van den Broeck, and Aditya Grover. Accelerating diffusion LLMs via adaptive parallel decoding. InAdvances in Neural Information Processing Systems 39, San Diego, CA, 2025
2025
-
[17]
d2Cache: Accelerating diffusion-based LLMs via dual adaptive caching
Yuchu Jiang, Yue Cai, Xiangzhong Luo, Jiale Fu, Jiarui Wang, Chonghan Liu, and Xu Yang. d2Cache: Accelerating diffusion-based LLMs via dual adaptive caching. InProceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026
2026
-
[18]
Mercury: Ultra-fast language models based on diffusion, 2025
Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, Stefano Ermon, Aditya Grover, and V olodymyr Kuleshov. Mercury: Ultra-fast language models based on diffusion.CoRR, abs/2506.17298, 2025
-
[19]
Guanghao Li, Zhihui Fu, Min Fang, Qibin Zhao, Ming Tang, Chun Yuan, and Jun Wang. Dif- fuSpec: Unlocking diffusion language models for speculative decoding.CoRR, abs/2510.02358, 2025
-
[20]
A survey on diffusion language models,
Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. A survey on diffusion language models.CoRR, abs/2508.10875, 2025
-
[21]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. In Proceedings of the 12th International Conference on Learning Representations, Vienna, Austria, 2024
2024
-
[22]
Zhiyuan Liu, Yicun Yang, Yaojie Zhang, Junjie Chen, Chang Zou, Qingyuan Wei, Shaobo Wang, and Linfeng Zhang. dLLM-Cache: Accelerating diffusion large language models with adaptive caching.CoRR, abs/2506.06295, 2025
-
[23]
Discrete diffusion modeling by estimating the ratios of the data distribution
Aaron Lou, Chenlin Meng, and Stefano Ermon. Discrete diffusion modeling by estimating the ratios of the data distribution. InProceedings of the 41st International Conference on Machine Learning, pages 32819–32848, Vienna, Austria, 2024
2024
-
[24]
AdaBlock-dLLM: Semantic-aware diffusion LLM inference via adaptive block size
Guanxi Lu, Hao Mark Chen, Yuto Karashima, Zhican Wang, Daichi Fujiki, and Hongxiang Fan. AdaBlock-dLLM: Semantic-aware diffusion LLM inference via adaptive block size. In Proceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026
2026
-
[25]
Dsb: Dynamic sliding block scheduling for diffusion llms.arXiv preprint arXiv:2602.05992,
Lizhuo Luo, Shenggui Li, Yonggang Wen, and Tianwei Zhang. DSB: dynamic sliding block scheduling for diffusion LLMs.CoRR, abs/2602.05992, 2026
-
[26]
DAWN: dependency-aware fast inference for diffusion LLMs.CoRR, abs/2602.06953, 2026
Lizhuo Luo, Zhuoran Shi, Jiajun Luo, Zhi Wang, Shen Ren, Wenya Wang, and Tianwei Zhang. DAWN: dependency-aware fast inference for diffusion LLMs.CoRR, abs/2602.06953, 2026
-
[27]
dKV-Cache: The cache for diffusion language models
Xinyin Ma, Runpeng Yu, Gongfan Fang, and Xinchao Wang. dKV-Cache: The cache for diffusion language models. InAdvances in Neural Information Processing Systems 39, San Diego, CA, 2025
2025
-
[28]
Attention is all you need for KV cache in diffusion LLMs
Quan Nguyen-Tri, Mukul Ranjan, and Zhiqiang Shen. Attention is all you need for KV cache in diffusion LLMs. InProceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026. 11
2026
-
[29]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.CoRR, abs/2502.09992, 2025
work page internal anchor Pith review arXiv 2025
-
[30]
Deferred commitment decoding for diffusion language models.CoRR, abs/2601.02076, 2026
Yingte Shu, Yuchuan Tian, Chao Xu, Yunhe Wang, and Hanting Chen. Deferred commitment decoding for diffusion language models.CoRR, abs/2601.02076, 2026
-
[31]
Sparse-dLLM: Accelerating diffusion LLMs with dynamic cache eviction
Yuerong Song, Xiaoran Liu, Ruixiao Li, Zhigeng Liu, Zengfeng Huang, Qipeng Guo, Ziwei He, and Xipeng Qiu. Sparse-dLLM: Accelerating diffusion LLMs with dynamic cache eviction. InProceedings of the 40th AAAI Conference on Artificial Intelligence, pages 33038–33046, Singapore, Singapore, 2026
2026
-
[32]
Lipeng Wan, Junjie Ma, Jianhui Gu, Zeyang Liu, Xuyang Lu, and Xuguang Lan. GeoBlock: Inferring block granularity from dependency geometry in diffusion language models.CoRR, abs/2603.26675, 2026
-
[33]
Diffusion LLMs can do faster-than-AR inference via discrete diffusion forcing
Xu Wang, Chenkai Xu, Yijie Jin, Jiachun Jin, Hao Zhang, and Zhijie Deng. Diffusion LLMs can do faster-than-AR inference via discrete diffusion forcing. InProceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026
2026
-
[34]
Molchanov, Ping Luo, Song Han, and Enze Xie
Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo O. Molchanov, Ping Luo, Song Han, and Enze Xie. Fast-dLLM v2: Efficient block-diffusion LLM. InProceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026
2026
-
[35]
Fast-dLLM: Training-free acceleration of diffusion LLM by enabling KV cache and parallel decoding
Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie. Fast-dLLM: Training-free acceleration of diffusion LLM by enabling KV cache and parallel decoding. InProceedings of the 14th International Conference on Learning Representations, Rio de Janeiro, Brazil, 2026
2026
-
[36]
Dream 7B: Diffusion Large Language Models
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7B: Diffusion large language models.CoRR, abs/2508.15487, 2025
work page internal anchor Pith review arXiv 2025
-
[37]
Runpeng Yu, Qi Li, and Xinchao Wang. Discrete diffusion in large language and multimodal models: A survey.CoRR, abs/2506.13759, 2025
-
[38]
Yu Zhang, Xinchen Li, Jialei Zhou, Hongnan Ma, Zhongwei Wan, Yiwei Shi, Duoqian Miao, Qi Zhang, and Longbing Cao. Swordsman: Entropy-driven adaptive block partition for efficient diffusion language models.CoRR, abs/2602.04399, 2026
-
[39]
d1: Scaling reasoning in diffusion large language models via reinforcement learning
Siyan Zhao, Devaansh Gupta, Qinqing Zheng, and Aditya Grover. d1: Scaling reasoning in diffusion large language models via reinforcement learning. InAdvances in Neural Information Processing Systems 39, San Diego, CA, 2025
2025
-
[40]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Llada 1.5: Variance-reduced preference optimization for large language diffusion models.CoRR, abs/2505.19223, 2025. 12 A Detailed Theoretical Analysis A.1 Detailed Derivation We fix the decoded context c before the late...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.