Recognition: unknown
Beyond a Single Frame: Multi-Frame Spatially Grounded Reasoning Across Volumetric MRI
Pith reviewed 2026-05-10 08:12 UTC · model grok-4.3
The pith
Supervised fine-tuning with bounding box supervision improves vision-language model grounding on multi-frame volumetric MRI.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the SGMRI-VQA benchmark, built from expert radiologist annotations with frame-indexed bounding boxes and hierarchical tasks, demonstrates that supervised fine-tuning of Qwen3-VL-8B using bounding box supervision consistently improves grounding performance over strong zero-shot baselines, pointing to targeted spatial supervision as an effective route to grounded clinical reasoning in volumetric imaging.
What carries the argument
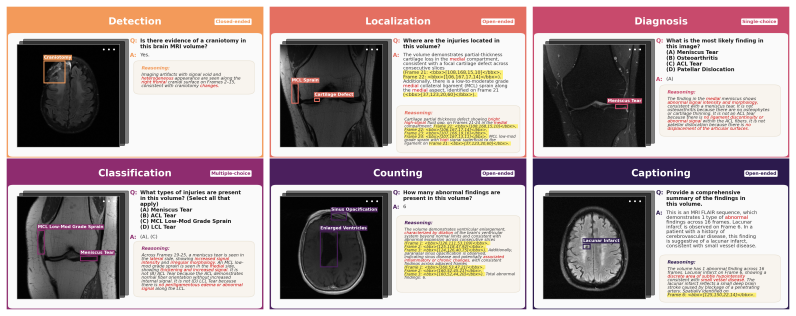
The SGMRI-VQA benchmark, which supplies clinician-aligned chain-of-thought traces together with frame-indexed bounding box coordinates across detection, localization, counting/classification, and captioning tasks on volumetric MRI.
If this is right
- Models trained this way can better identify and localize findings that extend across only a subset of slices rather than treating every frame in isolation.
- Hierarchical task design allows systematic measurement of progress from simple detection to joint what-where-across-frames reasoning.
- Bounding-box supervision offers a concrete training signal that transfers to improved captioning and classification accuracy on the same volumes.
- The approach scales to both brain and knee studies, suggesting applicability across different anatomical regions in clinical MRI.
Where Pith is reading between the lines
- Similar bounding-box supervision could be applied to CT or PET volumes to test whether the gains generalize beyond MRI.
- Reducing dependence on expert annotations might be achieved by generating synthetic multi-frame traces from existing single-frame labels.
- Integration into diagnostic workflows could let clinicians query models for both the answer and the exact slices used as evidence.
Load-bearing premise
Expert radiologist annotations in the fastMRI+ dataset supply reliable frame-indexed bounding boxes and clinician-aligned reasoning traces that accurately reflect multi-frame spatial relationships.
What would settle it
A replication study on a fresh set of MRI volumes with independently verified annotations in which the fine-tuned Qwen3-VL-8B shows no improvement or worse grounding performance than zero-shot baselines.
Figures







read the original abstract
Spatial reasoning and visual grounding are core capabilities for vision-language models (VLMs), yet most medical VLMs produce predictions without transparent reasoning or spatial evidence. Existing benchmarks also evaluate VLMs on isolated 2D images, overlooking the volumetric nature of clinical imaging, where findings can span multiple frames or appear on only a few slices. We introduce Spatially Grounded MRI Visual Question Answering (SGMRI-VQA), a 41,307-pair benchmark for multi-frame, spatially grounded reasoning on volumetric MRI. Built from expert radiologist annotations in the fastMRI+ dataset across brain and knee studies, each QA pair includes a clinician-aligned chain-of-thought trace with frame-indexed bounding box coordinates. Tasks are organized hierarchically across detection, localization, counting/classification, and captioning, requiring models to jointly reason about what is present, where it is, and across which frames it extends. We benchmark 10 VLMs and show that supervised fine-tuning of Qwen3-VL-8B with bounding box supervision consistently improves grounding performance over strong zero-shot baselines, indicating that targeted spatial supervision is an effective path toward grounded clinical reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the SGMRI-VQA benchmark of 41,307 QA pairs derived from expert radiologist annotations on fastMRI+ volumetric brain and knee MRI studies. Each pair supplies a clinician-aligned chain-of-thought trace together with frame-indexed bounding-box coordinates. The authors benchmark ten VLMs and report that supervised fine-tuning of Qwen3-VL-8B with explicit bounding-box supervision yields consistent gains in multi-frame spatial grounding over strong zero-shot baselines.
Significance. If the quantitative gains and annotation quality can be verified, the work would be a useful addition to medical vision-language modeling by supplying the first large-scale benchmark that explicitly requires models to reason across multiple slices of a volume and to output spatially grounded evidence. The hierarchical task structure (detection, localization, counting/classification, captioning) offers a principled way to dissect different facets of 3D clinical reasoning.
major comments (3)
- [Abstract] Abstract: the central claim that supervised fine-tuning 'consistently improves grounding performance' is presented without any numerical results, error bars, statistical tests, or description of the evaluation protocol (metrics, IoU thresholds, frame-selection criteria). This omission prevents assessment of the magnitude and reliability of the reported improvement.
- [Dataset construction section] Dataset construction section: no inter-annotator agreement, validation set, or error analysis is reported for the frame-indexed bounding boxes and CoT traces that constitute the ground truth. Because the SFT objective directly optimizes against these annotations, unquantified noise or systematic frame-selection errors would render the claimed gains over zero-shot baselines unreliable.
- [Experiments section] Experiments section: the manuscript compares only against zero-shot baselines and does not report the precise metrics used for multi-frame grounding (e.g., per-frame IoU, volume-level overlap), the train/validation/test split sizes, or full per-model scores. These details are required to substantiate the claim that bounding-box supervision is the decisive factor.
minor comments (1)
- [Abstract] The abstract could briefly state the primary quantitative metric (e.g., mean IoU or accuracy) used to measure grounding performance so that readers immediately grasp the scale of improvement.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for recognizing the potential value of SGMRI-VQA as a benchmark for multi-frame spatially grounded reasoning in volumetric MRI. We address each major comment below and have revised the manuscript to provide the requested details and clarifications.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that supervised fine-tuning 'consistently improves grounding performance' is presented without any numerical results, error bars, statistical tests, or description of the evaluation protocol (metrics, IoU thresholds, frame-selection criteria). This omission prevents assessment of the magnitude and reliability of the reported improvement.
Authors: We agree that the abstract would benefit from quantitative support and protocol details to substantiate the central claim. In the revised manuscript, we have updated the abstract to include key numerical results on grounding improvements, a brief description of the evaluation metrics and IoU thresholds, frame-selection criteria, and references to error bars and statistical tests reported in the main text. revision: yes
-
Referee: [Dataset construction section] Dataset construction section: no inter-annotator agreement, validation set, or error analysis is reported for the frame-indexed bounding boxes and CoT traces that constitute the ground truth. Because the SFT objective directly optimizes against these annotations, unquantified noise or systematic frame-selection errors would render the claimed gains over zero-shot baselines unreliable.
Authors: We acknowledge the importance of quantifying annotation quality for the ground truth used in SFT. The revised dataset construction section now includes inter-annotator agreement metrics for bounding boxes and CoT traces, details on the validation set employed during annotation, and an error analysis addressing potential frame-selection issues. These additions address concerns about unquantified noise. revision: yes
-
Referee: [Experiments section] Experiments section: the manuscript compares only against zero-shot baselines and does not report the precise metrics used for multi-frame grounding (e.g., per-frame IoU, volume-level overlap), the train/validation/test split sizes, or full per-model scores. These details are required to substantiate the claim that bounding-box supervision is the decisive factor.
Authors: We agree that additional experimental details are needed to fully support the claims. The revised experiments section now specifies the precise multi-frame grounding metrics (per-frame IoU and volume-level overlap), reports the train/validation/test split sizes, and provides full per-model scores for all ten VLMs. We have also added clarifications and ablations to highlight the role of bounding-box supervision. revision: yes
Circularity Check
No circularity: empirical benchmark and direct performance comparison
full rationale
The paper's core contribution is the construction of the SGMRI-VQA benchmark (41,307 pairs) from existing fastMRI+ expert annotations, followed by empirical benchmarking of 10 VLMs and a direct comparison showing SFT gains over zero-shot baselines. No mathematical derivations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the reported chain. The improvement is measured on the introduced tasks without reducing to input tautologies or ansatzes smuggled via prior work. This is a standard empirical dataset-plus-evaluation setup whose results stand or fall on annotation quality and experimental controls, not on any internal reduction to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert radiologist annotations in fastMRI+ provide accurate frame-indexed bounding boxes and clinician-aligned chain-of-thought traces.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2407.04106 (2024)
Asma Alkhaldi, Raneem Alnajim, Layan Alabdullatef, Rawan Alyahya, Jun Chen, Deyao Zhu, Ahmed Alsinan, and Mohamed Elhoseiny. Minigpt-med: Large language model as a general interface for radiology diagnosis.arXiv preprint arXiv:2407.04106,
-
[3]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Hritik Bansal, Daniel Israel, Siyan Zhao, Shufan Li, Tung Nguyen, and Aditya Grover. Med- max: Mixed-modal instruction tuning for training biomedical assistants.arXiv preprint arXiv:2412.12661,
-
[5]
Guo Chen, Zhiqi Li, Shihao Wang, Jindong Jiang, Yicheng Liu, Lidong Lu, De-An Huang, Wonmin Byeon, Matthieu Le, Tuomas Rintamaki, et al. Eagle 2.5: Boosting long-context post-training for frontier vision-language models.arXiv preprint arXiv:2504.15271,
-
[6]
PathVQA: 30000+ Questions for Medical Visual Question Answering
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering.arXiv preprint arXiv:2003.10286,
work page internal anchor Pith review arXiv 2003
-
[7]
Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600, 2025
Jun Ma, Zongxin Yang, Sumin Kim, Bihui Chen, Mohammed Baharoon, Adibvafa Fallahpour, Reza Asakereh, Hongwei Lyu, and Bo Wang. Medsam2: Segment anything in 3d medical images and videos.arXiv preprint arXiv:2504.03600,
-
[8]
Dang H Nguyen, Hieu H Pham, and Hao T Nguyen. Vindr-cxr-vqa: A visual question an- swering dataset for explainable chest x-ray analysis with multi-task learning.arXiv preprint arXiv:2511.00504,
-
[9]
Rexvqa: A large-scale visual question answering benchmark for generalist chest x-ray understanding
Ankit Pal, Jung-Oh Lee, Xiaoman Zhang, Malaikannan Sankarasubbu, Seunghyeon Roh, Won Jung Kim, Meesun Lee, and Pranav Rajpurkar. Rexvqa: A large-scale visual question answering benchmark for generalist chest x-ray understanding. InBiocomputing 2026: Proceedings of the Pacific Symposium, pages 251–264. World Scientific,
2026
-
[10]
URL https://arxiv.org/abs/2408. 00714. Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroensri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, Cían Hughes, Charles Lau, et al. Medgemma technical report. arXiv preprint arXiv:2507.05201,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Haotian Xue, Yunhao Ge, Yu Zeng, Zhaoshuo Li, Ming-Yu Liu, Yongxin Chen, and Jiaojiao Fan. Point-it-out: Benchmarking embodied reasoning for vision language models in multi-stage visual grounding.arXiv preprint arXiv:2509.25794,
-
[14]
arXiv preprint arXiv:2505.16964 (2025)
Suhao Yu, Haojin Wang, Juncheng Wu, Luyang Luo, Jingshen Wang, Cihang Xie, Pranav Rajpurkar, Carl Yang, Yang Yang, Kang Wang, et al. Medframeqa: A multi-image medical vqa benchmark for clinical reasoning.arXiv preprint arXiv:2505.16964,
-
[15]
BERTScore: Evaluating Text Generation with BERT
URLhttps://arxiv.org/abs/1904.09675. Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-vqa: Visual instruction tuning for medical visual question answering.arXiv preprint arXiv:2305.10415,
work page internal anchor Pith review arXiv 1904
-
[16]
LLaVA-Video: Video Instruction Tuning With Synthetic Data
12 Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava-video: Video instruction tuning with synthetic data.arXiv preprint arXiv:2410.02713,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.