Recognition: 2 theorem links
· Lean TheoremMatched-Learning-Rate Analysis of Attention Drift and Transfer Retention in Fine-Tuned CLIP
Pith reviewed 2026-05-13 23:20 UTC · model grok-4.3
The pith
At matched learning rates, LoRA keeps far more of CLIP's original zero-shot accuracy than full fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
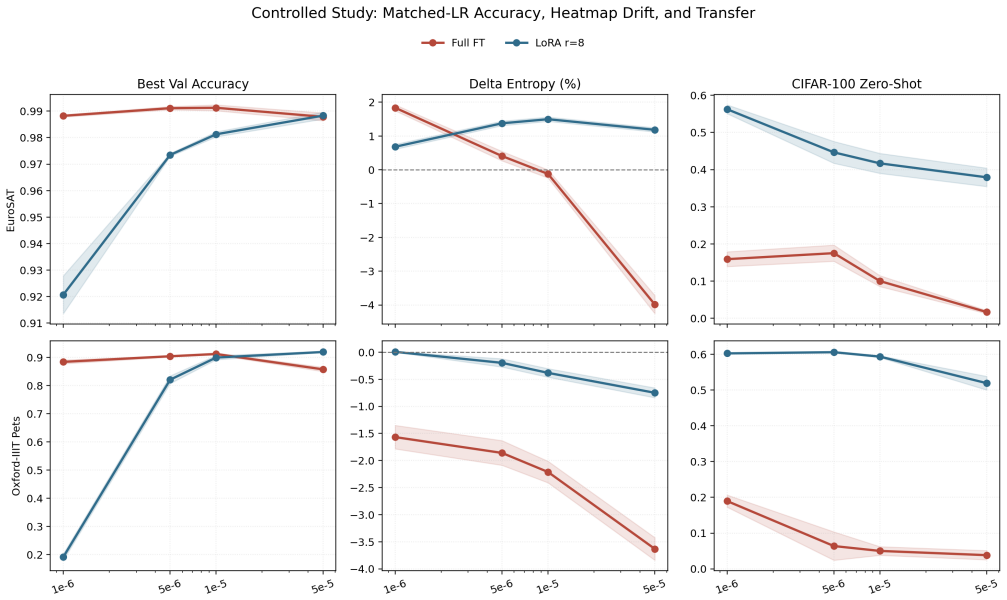
At matched learning rates the paper shows LoRA produces less structural change in attention and retains substantially higher zero-shot transfer than full fine-tuning, averaging 45.13 percent versus 11.28 percent CIFAR-100 accuracy after EuroSAT adaptation and 58.01 percent versus 8.54 percent after Pets adaptation. Learning-rate scale modulates the difference: full fine-tuning shifts from mild entropy increase at the lowest rate to clear contraction at the highest, while LoRA stays entropy-positive throughout the grid. On Pets a low-rate regime also appears in which LoRA underfits in-domain, so simple method averages can mask when each approach is competitive.
What carries the argument
The matched-learning-rate grid of four shared values applied equally to full fine-tuning and LoRA, paired with attention-entropy, patch-to-patch, rollout, and CKA measurements to quantify representation drift.
If this is right
- LoRA becomes the stronger default when the goal is to keep broad zero-shot capability after domain adaptation.
- Attention entropy remains a useful descriptive diagnostic of how much the original representation survives, even if it does not explain transfer outcomes causally.
- Low learning-rate LoRA can underfit in-domain on some datasets, so practitioners must still tune rate separately from method choice.
- Method comparisons that ignore learning-rate matching will systematically overstate the transfer penalty of full fine-tuning.
Where Pith is reading between the lines
- The same matched-rate protocol could be applied to other parameter-efficient methods such as adapters or prompt tuning to map their drift profiles.
- If attention stability at matched rates proves consistent across model sizes, it would support using LoRA as a low-risk way to adapt large vision-language models without sacrificing generality.
- Extending the grid to even lower or higher rates on more diverse downstream tasks would test whether the preservation gap narrows outside the current operating window.
Load-bearing premise
That the four chosen learning rates and two datasets are representative enough for the method comparison to generalize, and that attention-drift metrics reliably indicate representation preservation without needing a causal link to transfer.
What would settle it
A replication on additional datasets such as ImageNet or CIFAR-10 that finds full fine-tuning retaining equal or higher zero-shot accuracy than LoRA at the same learning rates would falsify the preservation advantage.
Figures

read the original abstract
CLIP adaptation can improve in-domain accuracy while degrading out-of-domain transfer, but comparisons between Full Fine-Tuning (Full FT) and LoRA are often confounded by different learning-rate conventions. We study how adaptation method and optimization scale jointly shape attention drift and transfer retention in CLIP using a controlled matched-learning-rate comparison of Full FT and LoRA. The completed matrix contains 80 runs on CLIP ViT-B/32 across EuroSAT and Oxford-IIIT Pets, spanning four shared learning rates ($10^{-6}$, $5{\times}10^{-6}$, $10^{-5}$, $5{\times}10^{-5}$) and five seeds, and evaluates attention-drift metrics, best validation accuracy, and adapter-aware CIFAR-100 zero-shot accuracy. Learning rate strongly modulates structural change: on EuroSAT, Full FT moves from mild entropy broadening at $10^{-6}$ to marked contraction at $5{\times}10^{-5}$, whereas LoRA remains entropy-positive across the full matched grid. At matched learning rates, LoRA preserves substantially more zero-shot transfer than Full FT, averaging $45.13\%$ versus $11.28\%$ CIFAR-100 accuracy on EuroSAT and $58.01\%$ versus $8.54\%$ on Pets. Oxford-IIIT Pets also reveals a regime effect: low-learning-rate LoRA underfits in-domain, so method-only averages can obscure when LoRA becomes competitive. Supporting rollout, patch-to-patch, and CKA analyses are directionally consistent with the controlled matrix. Overall, matched-learning-rate evaluation materially changes the interpretation of Full FT versus LoRA, and attention drift is most useful as a descriptive diagnostic of representation preservation rather than a causal explanation of transfer behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a controlled matched-learning-rate comparison of Full FT and LoRA on CLIP ViT-B/32 (80 runs across EuroSAT and Oxford-IIIT Pets, four shared LRs from 10^{-6} to 5×10^{-5}, five seeds) shows LoRA preserves substantially more zero-shot CIFAR-100 transfer (45.13% vs 11.28% on EuroSAT; 58.01% vs 8.54% on Pets), with learning rate modulating attention-drift metrics (entropy, rollout, patch-to-patch, CKA) and attention drift serving as a descriptive diagnostic of representation preservation rather than a causal mediator.
Significance. If the empirical patterns hold, the work demonstrates that mismatched learning-rate conventions have confounded prior Full FT vs. LoRA comparisons and supplies a reproducible multi-seed matrix for evaluating structural change versus transfer retention in vision-language models. The explicit regime-effect observation on Pets and the directional consistency of attention metrics are useful contributions to the adapter literature.
major comments (3)
- [Abstract] Abstract: the headline averages (45.13% vs 11.28%, 58.01% vs 8.54%) are reported without standard deviations, error bars, or any statistical test despite the five-seed design; this leaves the central claim of “substantially more” preservation only weakly supported.
- [Abstract] Abstract and experimental matrix: the comparison rests on exactly two datasets and four learning rates; the paper itself notes a regime effect on Pets where low-LR LoRA underfits, yet provides no additional datasets, higher/lower LRs, or cross-task validation to establish that the observed gap is representative rather than slice-specific.
- [Abstract] Abstract: attention-drift metrics are presented only as “directionally consistent” diagnostics with no quantitative correlation, mediation analysis, or ablation showing they causally mediate the transfer gap; this weakens their claimed utility beyond description.
minor comments (2)
- [Abstract] Define “adapter-aware CIFAR-100 zero-shot accuracy” explicitly and state how it differs from standard zero-shot evaluation.
- All figures and tables reporting accuracies or drift metrics should include per-condition standard deviations given the multi-seed protocol.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline averages (45.13% vs 11.28%, 58.01% vs 8.54%) are reported without standard deviations, error bars, or any statistical test despite the five-seed design; this leaves the central claim of “substantially more” preservation only weakly supported.
Authors: We agree that variability measures are needed to support the claims. The experiments used five seeds, so in the revised version we will report standard deviations alongside the headline averages in the abstract, add error bars to all relevant figures, and include a statistical test (e.g., paired t-test across seeds) to quantify the significance of the LoRA vs. Full FT differences. revision: yes
-
Referee: [Abstract] Abstract and experimental matrix: the comparison rests on exactly two datasets and four learning rates; the paper itself notes a regime effect on Pets where low-LR LoRA underfits, yet provides no additional datasets, higher/lower LRs, or cross-task validation to establish that the observed gap is representative rather than slice-specific.
Authors: The controlled matched-LR design on two datasets was chosen to isolate method effects while highlighting the Pets regime effect. We will expand the discussion to explicitly address scope limitations and note that the patterns hold across the four LRs, but we cannot add new datasets or LRs without further experiments. revision: partial
-
Referee: [Abstract] Abstract: attention-drift metrics are presented only as “directionally consistent” diagnostics with no quantitative correlation, mediation analysis, or ablation showing they causally mediate the transfer gap; this weakens their claimed utility beyond description.
Authors: We position the metrics strictly as descriptive diagnostics of representation change, as stated in the abstract, and do not claim they causally mediate transfer. Directional consistency is shown to link structural metrics to retention outcomes. We will add Pearson correlations between drift metrics and CIFAR-100 accuracy in the revision to strengthen the descriptive evidence, but mediation analysis remains outside the current scope. revision: partial
Circularity Check
No circularity: purely empirical comparison with no derivations or self-referential reductions
full rationale
The paper reports results from 80 controlled experimental runs on CLIP ViT-B/32 using a fixed grid of four matched learning rates and two datasets. All reported quantities (CIFAR-100 zero-shot accuracies, entropy metrics, CKA, etc.) are direct averages or observations from those runs. No equations, fitted parameters, uniqueness theorems, or self-citations are invoked to derive any claim; the central comparison is simply the observed difference between Full FT and LoRA under identical optimization settings. The work therefore contains no load-bearing step that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
At matched learning rates, LoRA preserves substantially more zero-shot transfer than Full FT, averaging 45.13% versus 11.28% CIFAR-100 accuracy on EuroSAT
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
CLS-to-patch entropy, ERF@0.95, Gini concentration, Head diversity
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Unifiedqa: Crossing format boundaries with a single QA system.CoRR, abs/2005.00700, 2020a
Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4190–4197, 2020. doi: 10.18653/v1/2020. acl-main.385. URLhttps://aclanthology.org/2020.acl-main.385/
-
[2]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, 2021
work page 2021
-
[3]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7):2217–2226, 2019
work page 2019
-
[4]
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian Journal of Statistics, 6(2): 65–70, 1979
work page 1979
-
[5]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9
work page 2022
-
[6]
Sarthak Jain and Byron C. Wallace. Attention is not explanation. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 3543–3556, 2019. doi: 10.18653/v1/N19-1357. URL https:// aclanthology.org/N19-1357/
-
[7]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3519–3529, 2019. URLhttps://proceedings.mlr.press/ v97/kornblith19a.html
work page 2019
-
[8]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[9]
Fine-tuning can distort pretrained features and underperform out-of-distribution
Ananya Kumar, Aditi Raghunathan, Rob Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=UYneFzXSJWh. 10
work page 2022
-
[10]
Wenjie Luo, Yujia Li, Raquel Urtasun, and Richard Zemel. Understanding the effective receptive field in deep convolutional neural networks.arXiv preprint arXiv:1701.04128, 2017. URL https://arxiv.org/abs/1701. 04128
-
[11]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. Indian Conference on Computer Vision, Graphics and Image Processing, 2008
work page 2008
-
[12]
Parkhi, Andrea Vedaldi, Andrew Zisserman, and C
Omkar M. Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V. Jawahar. Cats and dogs. InIEEE Conference on Computer Vision and Pattern Recognition, pages 3498–3505, 2012
work page 2012
-
[13]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision.arXiv preprint arXiv:2103.00020, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
Attention is not not explanation
Sarah Wiegreffe and Yuval Pinter. Attention is not not explanation. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pages 11–20, 2019. doi: 10.18653/v1/D19-1002. URL https://aclanthology.org/D19-1002/
-
[15]
arXiv preprint arXiv:2109.01903 , year=
Mitchell Wortsman, Gabriel Ilharco, JongWookKim, Mike Li, SimonKornblith, Rebecca Roelofs, RaphaelGontijo Lopes, Hannaneh Hajishirzi, Ali Farhadi, Hongseok Namkoong, and Ludwig Schmidt. Robust fine-tuning of zero-shot models.arXiv preprint arXiv:2109.01903, 2021. URLhttps://arxiv.org/abs/2109.01903. 11
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.