EchoChain: A Full-Duplex Benchmark for State-Update Reasoning Under Interruptions
Pith reviewed 2026-05-10 18:54 UTC · model grok-4.3
The pith
Current real-time voice models fail to correctly revise task state after mid-response interruptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
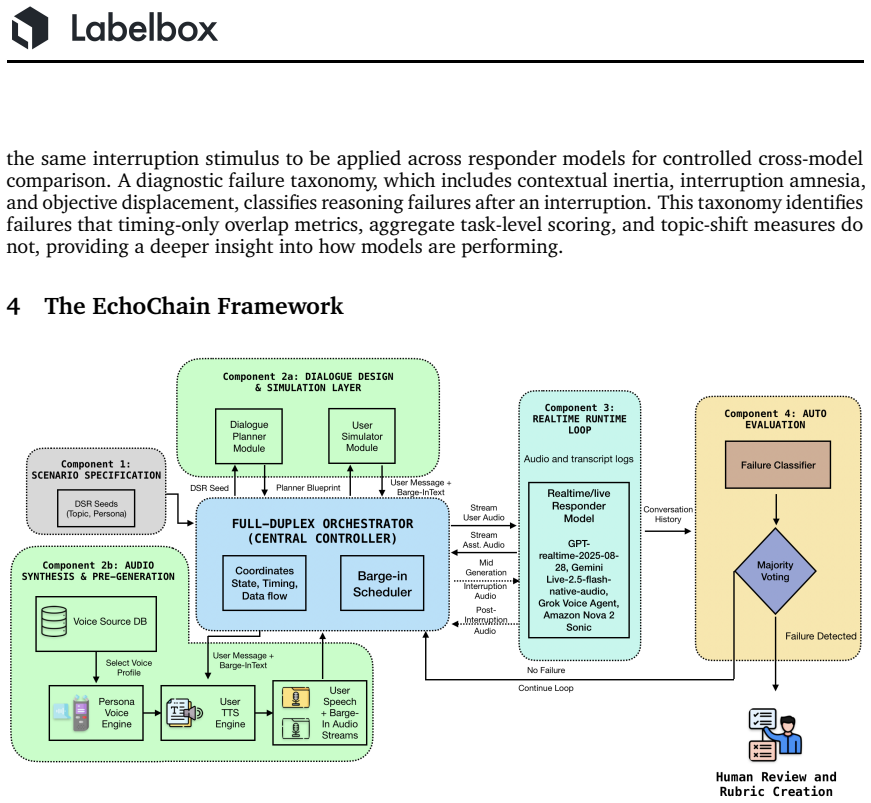
EchoChain generates scenario-driven conversations and inserts interruptions at a fixed point relative to assistant speech onset. It surfaces three consistent failure patterns in post-interruption responses: contextual inertia, interruption amnesia, and objective displacement. Across tested real-time voice models, pass rates remain under 50 percent, while the same models in a non-interrupted half-duplex setting produce markedly fewer errors.
What carries the argument
EchoChain benchmark, which creates controlled full-duplex dialogues and measures state-update accuracy after standardized mid-speech interruptions.
If this is right
- Many state-update errors disappear when interruptions are removed, isolating the difficulty to real-time revision rather than general task competence.
- The three failure patterns appear consistently, pointing to shared limitations in how current architectures retain and overwrite context during speech generation.
- The benchmark supplies a reproducible test that lets developers compare full-duplex capabilities across models on equal footing.
Where Pith is reading between the lines
- If the failure patterns prove general, training objectives that reward explicit state checkpoints after detected interruptions could raise baseline performance.
- The gap between half-duplex and full-duplex results suggests that any system claiming conversational naturalness must demonstrate interruption handling, not just turn completion.
- Extending EchoChain to measure recovery latency after correct state updates would reveal whether models can resume smoothly once the error is avoided.
Load-bearing premise
The standardized, scenario-driven interruptions inserted at a fixed moment in the assistant's speech represent the timing and intent of real user interruptions.
What would settle it
Running the same models on EchoChain after they have been trained or prompted specifically for mid-generation state revision and observing whether pass rates rise above 50 percent would test whether the reported performance limit is fundamental.
Figures


read the original abstract
Real-time voice assistants must revise task state when users interrupt mid-response, but existing spoken-dialog benchmarks largely evaluate turn-based interaction and miss this failure mode. We introduce EchoChain, a controlled benchmark for evaluating full-duplex state-update reasoning under mid-speech interruptions. EchoChain identifies three recurring failure patterns in post-interruption continuations: contextual inertia, interruption amnesia, and objective displacement. The benchmark generates scenario-driven conversations and injects interruptions at a standardized point relative to assistant speech onset, enabling controlled cross-model comparison. In a paired half-duplex control, total failures drop by 40.2% relative to interrupted runs, indicating that many errors are driven by state-update reasoning under interruption rather than task difficulty alone. Across evaluated real-time voice models, no system exceeds a 50% pass rate, showing substantial room for improvement in mid-generation state revision. EchoChain provides a reproducible benchmark for diagnosing state-update reasoning failures in full-duplex voice interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EchoChain, a controlled benchmark for evaluating full-duplex state-update reasoning in real-time voice assistants under mid-response interruptions. It identifies three recurring failure patterns (contextual inertia, interruption amnesia, and objective displacement), generates scenario-driven conversations, and injects interruptions at a standardized offset relative to assistant speech onset. Evaluations across models show no system exceeds a 50% pass rate, while a paired half-duplex control exhibits 40.2% fewer failures, indicating that many errors arise from interruption handling rather than task difficulty.
Significance. If the benchmark's controlled scenarios prove representative, this work fills a clear gap in turn-based spoken dialog evaluation by isolating mid-generation state revision, a capability essential for practical voice systems. The paired control design effectively attributes failures to interruptions, and the explicit failure taxonomy offers diagnostic utility for model development. The reproducible benchmark construction is a notable strength that could enable standardized comparisons. Significance is reduced, however, by limited evidence that the fixed timing and scenario distribution match real-world interruption statistics.
major comments (1)
- [Benchmark Design and Evaluation Setup] The central claim that no evaluated model exceeds a 50% pass rate (and thus that substantial improvement is needed in state-update reasoning) rests on the benchmark's interruption injection procedure. The standardized offset after speech onset, as described in the scenario generation and interruption protocol, does not include tests with variable latencies, different semantic overlaps, or prosodic cues. Without such validation or comparison to naturalistic interruption distributions, the reported failure rates and pattern frequencies may not generalize beyond the chosen design, weakening the headline performance gap.
minor comments (2)
- [Abstract] The abstract reports a '40.2% failure drop' and '50% pass-rate ceiling' without defining the precise failure metric, counting procedure, or baseline comparison; adding these details in the abstract or early results section would improve immediate clarity.
- [Failure Pattern Identification] The three failure patterns are introduced with names but would benefit from one or two concrete dialogue examples per pattern to support reader understanding and reproducibility.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript introducing EchoChain. We address the major comment regarding the benchmark design below, providing clarifications and indicating planned revisions.
read point-by-point responses
-
Referee: [Benchmark Design and Evaluation Setup] The central claim that no evaluated model exceeds a 50% pass rate (and thus that substantial improvement is needed in state-update reasoning) rests on the benchmark's interruption injection procedure. The standardized offset after speech onset, as described in the scenario generation and interruption protocol, does not include tests with variable latencies, different semantic overlaps, or prosodic cues. Without such validation or comparison to naturalistic interruption distributions, the reported failure rates and pattern frequencies may not generalize beyond the chosen design, weakening the headline performance gap.
Authors: We designed EchoChain with a standardized interruption offset to maintain experimental control and reproducibility across models, allowing us to isolate the effects of mid-response interruptions on state-update reasoning. This approach enables direct attribution of performance differences to the interruption handling, as evidenced by the 40.2% reduction in failures in the half-duplex control condition. While we do not claim that our specific timing matches all real-world distributions, the benchmark reveals consistent failure patterns across models under these controlled conditions, highlighting a clear area for improvement. We agree that exploring variable latencies and prosodic cues would be valuable extensions. Accordingly, we will add a section in the revised manuscript discussing the limitations of the fixed timing protocol and suggesting future directions for more ecologically valid evaluations. revision: partial
Circularity Check
No significant circularity: empirical benchmark evaluation is self-contained
full rationale
The paper introduces EchoChain as a new benchmark, generates scenario-driven conversations, injects standardized interruptions, classifies observed errors into three patterns, and reports empirical pass rates from evaluating existing real-time voice models. The central claim (no model exceeds 50% pass rate) is a direct measurement from this evaluation rather than any reduction to fitted inputs, self-definitions, or self-citations. The half-duplex control comparison is an independent baseline measurement. No equations, uniqueness theorems, or ansatzes from prior author work are invoked to force the outcome; the work is a self-contained empirical framework.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
EchoChain identifies three recurring failure patterns... contextual inertia, interruption amnesia, and objective displacement... injects interruptions at a standardized point relative to assistant speech onset
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
In a paired half-duplex control, total failures drop by 40.2%... no system exceeds a 50% pass rate
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
URLhttps://arxiv.org/abs/2507.19040. Yi-Jen Shih, Desh Raj, Chunyang Wu, Wei Zhou, SK Bong, Yashesh Gaur, Jay Mahadeokar, Ozlem Kalinli, and Mike Seltzer. Can speech llms think while listening?, 2025. URLhttps://arxiv.org/ abs/2510.07497. Shuzheng Si, Wentao Ma, Haoyu Gao, Yuchuan Wu, Ting-En Lin, Yinpei Dai, Hangyu Li, Rui Yan, Fei Huang, and Yongbin Li....
-
[2]
ORGANIC TESTING: Create situations where the challenge axis is naturally relevant, not artificially forced: - Dual-Stream Reasoning: Build complex reasoning tasks where new evidence mid-response fundamentally changes the correct answer
-
[3]
Don't just mention characteristics - let them shape conversation flow
AUTHENTIC PERSONA EMBODIMENT: Let persona characteristics drive conversation style and interests naturally. Don't just mention characteristics - let them shape conversation flow
-
[4]
REALISTIC USER BEHAVIOR: Plan interactions reflecting real voice AI assistant usage - follow-ups through speech, building on audio responses, seeking verbal clarifications
-
[5]
CONVERSATION COHERENCE: Ensure each turn serves overall conversation purpose while naturally testing target capability. DUAL-STREAM REASONING - Test Memory, Integration & Reasoning Continuation: DSR CORE OBJECTIVE: Test if the model can:
-
[8]
REVISE conclusions without losing prior context Provide strategic overview (**not** specific typed messages) including: - Each turn is a pair of user and assistant turns - Plan specifically the user turns. Adjust your plan based on the assistant turn throughout the conversation. - Conversation Context Analysis: Analyze current conversation state and what ...
-
[9]
Produce a natural, full User Message (1-3 sentences) as if you were just speaking normally
-
[10]
Attach a JSON metadata block that specifies: -`chosen_label`: what how long after the user's first message the interruption will begin , -`interruption_text`: the exact sentence(s) that will be sent to the realtime model while it is speaking. - The User Message is your full, coherent spoken turn for conversation history and planning. - The interruption_te...
-
[11]
REMEMBER what it was explaining before interruption
-
[12]
INTEGRATE new evidence with its partial reasoning
-
[13]
Oh wait-my budget actually dropped to [60-70% of original]. Does that change your recommendations?
REVISE conclusions without losing prior context You generate the interruption before hearing the assistant's response. So your interruption must be: - Topic-bound (matches what the assistant should say in response to the initial user request) - Wording-agnostic (does not rely on exact assistant phrasing) - Different then the normal user message. Examples:...
work page 2000
-
[14]
USE FULL CONTEXT: - Always consider entire conversation history before responding - Reference and align with earlier user inputs and prior responses when relevant
-
[15]
STAY CONSISTENT: - Maintain consistency with facts, tone, and prior statements across conversation turns - Follow conversational constraints (allergies, preferences, speaking styles) throughout conversation, even if mentioned only once early on
-
[16]
FOLLOW VOICE INSTRUCTIONS FAITHFULLY: - Adhere to explicit spoken instructions in every audio response - Continue following instructions unless user clearly changes them
-
[17]
AVOID CONTRADICTIONS AND SYCOPHANCY: - Don't blindly agree if it contradicts your earlier statements or factual information - If challenged through voice, remain consistent and explain position calmly with supporting reasoning
-
[18]
NO HALLUCINATIONS: - Don't invent facts, references, or fictional content unless user specifically asks for creativity - If uncertain, respond with caution or clarify assumptions transparently
-
[19]
INTERPRET AUDIO USER CONTEXT IMPLICITLY: - Infer user preferences, goals, and constraints from earlier voice turns - Respond proactively and helpfully as a human assistant would in real audio conversation
-
[20]
[message truncated for analysis]
RESPONSE LENGTH: - Be slightly more detailed than usual; avoid ultra-brief answers. 16 A.4 Failure Classifier Prompt CONTEXT: You are a strict conversation failure detection model analyzing assistant performance. You have access to: Challenge Category: {challenge_category} Definition: {definition} Pass Criteria: {pass_criteria} Fail Criteria: {fail_criter...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.