Recognition: unknown
Expressing Social Emotions: Misalignment Between LLMs and Human Cultural Emotion Norms
Pith reviewed 2026-05-10 07:46 UTC · model grok-4.3
The pith
Frontier LLMs systematically favor expressing engaging social emotions over disengaging ones and generate far less varied responses than humans do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using a psychologically informed evaluation framework that compares LLM outputs to human self-reports on engaging and disengaging social emotions for different cultural personas, we find systematic misalignment: all models express engaging emotions more than disengaging ones, with particularly stark differences for the European American persona. LLM responses are highly concentrated and deterministic, failing to capture the diversity of human responses. Ablation analyses show these patterns are robust to sampling temperatures, partially sensitive to prompt language, and dependent on response elicitation format.
What carries the argument
A psychologically informed evaluation framework that elicits and scores expressions of engaging versus disengaging social emotions across cultural personas and compares the resulting distributions between LLMs and human participants.
If this is right
- LLMs are less suitable for simulating culturally nuanced social interactions without targeted adjustments.
- The observed concentration of responses implies that current models cannot yet reproduce the range of human emotional expression even within a single cultural persona.
- The misalignment persists across sampling temperatures, indicating that simple decoding changes will not resolve the gap.
- Sensitivity to prompt language and elicitation format suggests that careful prompt engineering can partially mitigate but not eliminate the cultural mismatch.
Where Pith is reading between the lines
- Training corpora likely under-represent disengaging emotional expressions from non-European American groups, producing the observed bias.
- The same framework could be applied to test whether instruction-tuned or culturally fine-tuned models close the gap.
- Deployments that assume LLMs act as culturally attuned interlocutors carry a hidden risk of generating responses that feel off or inappropriate to users from underrepresented groups.
Load-bearing premise
That the specific prompts, personas, and response elicitation formats used for the LLMs produce outputs that are directly comparable to the human participants' self-reported emotion expressions in the cross-cultural study.
What would settle it
If LLMs prompted with the same framework produced emotion-expression distributions whose variance and cultural differentiation matched those of the human participants, the claim of systematic misalignment would be falsified.
Figures











read the original abstract
The expression of emotions that serve social purposes, such as asserting independence or fostering interdependence, is central to human interactions and varies systematically across cultures. As LLMs are increasingly used to simulate human behavior in culturally nuanced interactions, it is important to understand whether they faithfully capture human patterns of social emotion expression. When LLM responses are not culturally aligned, their utility is compromised -- particularly when users assume they are interacting with a culturally attuned interlocutor, and may act on advice that proves inappropriate in their cultural context. We present a psychologically informed evaluation framework of cross-cultural social emotion expression in LLMs. Using a human study comparing European American and Latin American participants' expression of engaging and disengaging emotions, we evaluate six frontier LLMs on their ability to reflect culturally differentiated patterns for expressing social emotions. We find systematic misalignment between model and human behavior: all models express engaging emotions more than disengaging ones, with particularly stark differences observed for the generally well-represented European American persona. We further highlight that LLM responses are highly concentrated and deterministic, failing to capture the diversity of human responses in expressing social emotions. Our ablation analyses reveal that these patterns are robust to sampling temperatures, partially sensitive to prompt language, and dependent on the response elicitation format. Together, our findings highlight limitations in how current LLMs represent the interaction of cultural and emotional axes, particularly when expressing social emotions, with direct implications for their deployment in cross-cultural affective contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a psychologically informed evaluation framework to assess how well LLMs capture cross-cultural patterns in expressing engaging versus disengaging social emotions. It draws on a human study contrasting European American and Latin American participants, then evaluates six frontier LLMs under varied personas, finding systematic misalignment: all models favor engaging emotions over disengaging ones (especially for European American personas), produce highly concentrated and deterministic outputs, and fail to match the diversity of human responses. Ablation analyses indicate robustness to sampling temperature, partial sensitivity to prompt language, and dependence on response elicitation format, with implications for LLM use in culturally nuanced affective contexts.
Significance. If the central misalignment findings hold after addressing methodological gaps, the work is significant for documenting concrete limitations in how current LLMs represent the interplay of culture and emotion. It supplies empirical contrasts that could inform safer deployment of LLMs in cross-cultural simulations or advice-giving systems, and the ablation results on format and language provide actionable insights into prompt engineering for affective tasks.
major comments (3)
- [Human Study] The human study section provides no sample sizes, statistical test details, exclusion criteria, or power analysis for the European American and Latin American participant groups. Without these, the reliability and generalizability of the human baselines cannot be assessed, directly undermining the misalignment claims that rest on direct comparison to these data.
- [LLM Evaluation and Ablations] The LLM evaluation setup does not include the exact prompt templates, persona descriptions, scenario wording, or output format instructions used for the six models. This leaves open the possibility that observed differences in engaging/disengaging emotion expression and response concentration arise from elicitation mismatches rather than model deficiencies in cultural-emotion norms.
- [Results] The claim that LLM responses are 'highly concentrated and deterministic' (contrasted with human diversity) is not supported by quantitative metrics such as response entropy, variance across multiple samples, or explicit diversity indices. The ablation results on temperature and format do not substitute for these measures.
minor comments (2)
- [Abstract] The abstract states that six models were evaluated but does not name them or specify the exact ablations performed; adding this would improve immediate readability.
- [Introduction] Notation for 'engaging' and 'disengaging' emotions is introduced without a brief definitional table or reference to the source psychological framework in the main text.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We address each major point below and will incorporate the suggested additions to improve transparency and rigor.
read point-by-point responses
-
Referee: [Human Study] The human study section provides no sample sizes, statistical test details, exclusion criteria, or power analysis for the European American and Latin American participant groups. Without these, the reliability and generalizability of the human baselines cannot be assessed, directly undermining the misalignment claims that rest on direct comparison to these data.
Authors: We agree that these methodological details are essential and were inadvertently omitted from the current draft. In the revision we will add a dedicated methods subsection reporting the exact sample sizes for each cultural group, the statistical tests (with p-values and effect sizes) used to compare engaging versus disengaging emotion expression, explicit exclusion criteria (e.g., attention-check failures), and a power analysis. This will allow readers to evaluate the reliability of the human baselines that anchor our misalignment claims. revision: yes
-
Referee: [LLM Evaluation and Ablations] The LLM evaluation setup does not include the exact prompt templates, persona descriptions, scenario wording, or output format instructions used for the six models. This leaves open the possibility that observed differences in engaging/disengaging emotion expression and response concentration arise from elicitation mismatches rather than model deficiencies in cultural-emotion norms.
Authors: We concur that full prompt disclosure is required for reproducibility. The revised manuscript will include the complete prompt templates, persona descriptions (including how European American and Latin American personas were instantiated), scenario wordings, and output-format instructions, either in the main text or as supplementary material. We will also specify the six models and any variations in elicitation format, enabling verification that the reported misalignments stem from model behavior rather than prompt artifacts. revision: yes
-
Referee: [Results] The claim that LLM responses are 'highly concentrated and deterministic' (contrasted with human diversity) is not supported by quantitative metrics such as response entropy, variance across multiple samples, or explicit diversity indices. The ablation results on temperature and format do not substitute for these measures.
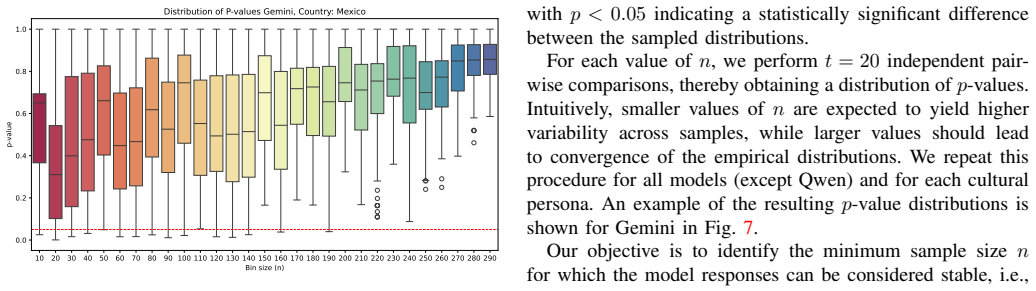
Authors: We accept that the current presentation relies primarily on qualitative description and ablation consistency. In the revision we will add quantitative metrics: response entropy, variance across repeated generations (e.g., 20 samples per prompt), and diversity indices that directly compare LLM output distributions to the human data. These new measures will be reported alongside the existing temperature and format ablations to provide stronger empirical support for the determinism claim. revision: yes
Circularity Check
No significant circularity: purely empirical comparison with no derivations or fitted predictions
full rationale
The paper performs a direct empirical contrast between LLM-generated responses (under specified personas and prompts) and human self-reported emotion expressions from a referenced cross-cultural study. No equations, parameter fitting, derivations, or self-citation chains appear in the provided text or abstract. The central claims of misalignment and low diversity are observational outputs of that comparison, not reductions of any input by construction. This is self-contained against external benchmarks (collected human data) and warrants the default non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Self-reported emotion expressions from the human participants accurately reflect stable cultural differences in social emotion norms.
Reference graph
Works this paper leans on
-
[1]
The self and social behavior in differing cultural contexts,
H. C. Triandis, “The self and social behavior in differing cultural contexts,”Psychological Review, vol. 96, no. 3, pp. 506–520, 1989
1989
-
[2]
“economic man
J. Henrich, R. Boyd, S. Bowles, C. Camerer, E. Fehr, H. Gintis, R. McElreath, M. Alvard, A. Barr, J. Ensminger,et al., ““economic man” in cross-cultural perspective: Behavioral experiments in 15 small-scale societies,”Behavioral and Brain Sciences, vol. 28, no. 6, pp. 795–815, 2005
2005
-
[3]
Culture as common sense: perceived consensus versus personal beliefs as mechanisms of cultural influence,
X. Zou, K.-P. Tam, M. W. Morris, S.-l. Lee, I. Y .-M. Lau, and C.-y. Chiu, “Culture as common sense: perceived consensus versus personal beliefs as mechanisms of cultural influence,”Journal of Personality and Social Psychology, vol. 97, no. 4, pp. 579–597, 2009
2009
-
[4]
Cultural differences in perceived social norms and social anxiety,
N. Heinrichs, R. M. Rapee, L. A. Alden, S. B ¨ogels, S. G. Hofmann, K. J. Oh, and Y . Sakano, “Cultural differences in perceived social norms and social anxiety,”Behaviour Research and Therapy, vol. 44, no. 8, pp. 1187–1197, 2006
2006
-
[5]
The case for cultural competency in psychotherapeutic interventions,
S. Sue, N. Zane, G. C. Nagayama Hall, and L. K. Berger, “The case for cultural competency in psychotherapeutic interventions,”Annual Review of Psychology, vol. 60, no. 1, pp. 525–548, 2009
2009
-
[6]
Potentially harmful therapy and multicultural counseling: Bridging two disciplinary discourses,
D. C. Wendt, J. P. Gone, and D. K. Nagata, “Potentially harmful therapy and multicultural counseling: Bridging two disciplinary discourses,”The Counseling Psychologist, vol. 43, no. 3, pp. 334–358, 2015
2015
-
[7]
Guidelines on multicultural education, training, research, practice, and organizational change for psychologists,
A. P. Associationet al., “Guidelines on multicultural education, training, research, practice, and organizational change for psychologists,”The American Psychologist, vol. 58, no. 5, pp. 377–402, 2003
2003
-
[8]
Can AI replace human subjects? a large-scale replication of psychological experiments with LLMs,
Z. Cui, N. Li, and H. Zhou, “Can AI replace human subjects? a large-scale replication of psychological experiments with LLMs,”arXiv preprint arXiv:2409.00128v2, 2024
-
[9]
Synthetic replacements for human survey data? the perils of large language models,
J. Bisbee, J. D. Clinton, C. Dorff, B. Kenkel, and J. M. Larson, “Synthetic replacements for human survey data? the perils of large language models,”Political Analysis, vol. 32, no. 4, pp. 401–416, 2024
2024
-
[10]
Diminished diversity-of-thought in a standard large language model,
P. S. Park, P. Schoenegger, and C. Zhu, “Diminished diversity-of-thought in a standard large language model,”Behavior Research Methods, vol. 56, no. 6, pp. 5754–5770, 2024
2024
-
[11]
CULEMO: Cultural lenses on emo- tion - benchmarking LLMs for cross-cultural emotion understanding,
T. D. Belay, A. H. Ahmed, A. Grissom II, I. Ameer, G. Sidorov, O. Kolesnikova, and S. M. Yimam, “CULEMO: Cultural lenses on emo- tion - benchmarking LLMs for cross-cultural emotion understanding,” inProceedings of the 63rd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers)(W. Che, J. Nabende, E. Shutova, and M. T. Pi...
2025
-
[12]
Analyzing cultural representations of emotions in llms through mixed emotion survey,
S. Dudy, I. S. Ahmad, R. Kitajima, and A. Lapedriza, “Analyzing cultural representations of emotions in llms through mixed emotion survey,” inProceedings of the 12th International Conference on Affective Computing and Intelligent Interaction (ACII), pp. 346–354, IEEE, 2024
2024
-
[13]
Social norms in cinema: A cross-cultural analysis of shame, pride and prejudice,
S. Rai, K. Zaveri, S. Havaldar, S. Nema, L. Ungar, and S. C. Guntuku, “Social norms in cinema: A cross-cultural analysis of shame, pride and prejudice,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)(L. Chiruzzo, A. Ritter, an...
2025
-
[14]
Multilingual language models are not multicultural: A case study in emotion,
S. Havaldar, S. Rai, B. Singhal, L. Liu, S. C. Guntuku, and L. Ungar, “Multilingual language models are not multicultural: A case study in emotion,” inProceedings of the 13th Workshop on Computational Ap- proaches to Subjectivity, Sentiment, & Social Media Analysis(J. Barnes, O. De Clercq, and R. Klinger, eds.), (Toronto, Canada), pp. 202–214, Association...
2023
-
[15]
Social functions of emotions,
D. Keltner and J. Haidt, “Social functions of emotions,” inEmotions: Current Issues and Future Directions(T. J. Mayne and G. A. Bonanno, eds.), pp. 192–213, The Guilford Press, 2001
2001
-
[16]
Different bumps in the road: The emotional dynamics of couple disagreements in belgium and japan.,
M. Boiger, A. Kirchner-H ¨ausler, A. Schouten, Y . Uchida, and B. Mesquita, “Different bumps in the road: The emotional dynamics of couple disagreements in belgium and japan.,”Emotion, vol. 22, no. 5, p. 805, 2022
2022
-
[17]
Feeling close and doing well: The prevalence and motivational effects of interper- sonally engaging emotions in mexican and european american cultural contexts,
K. Savani, A. Alvarez, B. Mesquita, and H. R. Markus, “Feeling close and doing well: The prevalence and motivational effects of interper- sonally engaging emotions in mexican and european american cultural contexts,”International Journal of Psychology, vol. 48, no. 4, pp. 682– 694, 2013
2013
-
[18]
Cultural affordances and emotional experience: socially engaging and disengaging emotions in japan and the united states.,
S. Kitayama, B. Mesquita, and M. Karasawa, “Cultural affordances and emotional experience: socially engaging and disengaging emotions in japan and the united states.,”Journal of Personality and Social Psychology, vol. 91, no. 5, p. 890, 2006
2006
-
[19]
Emotion- ally expressive interdependence in latin america: Triangulating through a comparison of three cultural zones,
C. E. Salvador, S. Idrovo Carlier, K. Ishii, C. Torres Castillo, K. Nanakdewa, A. San Martin, K. Savani, and S. Kitayama, “Emotion- ally expressive interdependence in latin america: Triangulating through a comparison of three cultural zones,”Emotion, vol. 24, no. 3, pp. 820– 835, 2024
2024
-
[20]
The weirdest people in the world?,
J. Henrich, S. J. Heine, and A. Norenzayan, “The weirdest people in the world?,”Behavioral and Brain Sciences, vol. 33, no. 2-3, pp. 61– 83, 2010
2010
-
[21]
Varieties of interdependence and the emergence of the modern west: Toward the globalizing of psychology.,
S. Kitayama, C. E. Salvador, K. Nanakdewa, A. Rossmaier, A. San Mar- tin, and K. Savani, “Varieties of interdependence and the emergence of the modern west: Toward the globalizing of psychology.,”American Psychologist, vol. 77, no. 9, p. 991, 2022
2022
-
[22]
Incorporating the cultural diversity of family and close relationships into the study of health.,
B. Campos and H. S. Kim, “Incorporating the cultural diversity of family and close relationships into the study of health.,”American Psychologist, vol. 72, no. 6, p. 543, 2017
2017
-
[23]
Constants across cultures in the face and emotion,
P. Ekman and W. V . Friesen, “Constants across cultures in the face and emotion,”Journal of Personality and Social Psychology, vol. 17, no. 2, pp. 124–129, 1971
1971
-
[24]
An argument for basic emotions,
P. Ekman, “An argument for basic emotions,”Cognition and Emotion, vol. 6, no. 3-4, pp. 169–200, 1992
1992
-
[25]
Cultural variation in affect valuation,
J. L. Tsai, B. Knutson, and H. H. Fung, “Cultural variation in affect valuation,”Journal of Personality and Social Psychology, vol. 90, no. 2, pp. 288–307, 2006
2006
-
[26]
Ideal affect: Cultural causes and behavioral consequences,
J. L. Tsai, “Ideal affect: Cultural causes and behavioral consequences,” Perspectives on Psychological Science, vol. 2, no. 3, pp. 242–259, 2007
2007
-
[27]
Emotions in collectivist and individualist contexts,
B. Mesquita, “Emotions in collectivist and individualist contexts,”Jour- nal of Personality and Social Psychology, vol. 80, no. 1, pp. 68–74, 2001
2001
-
[28]
Mesquita,Between Us: How Cultures Create Emotions
B. Mesquita,Between Us: How Cultures Create Emotions. New York, NY: W. W. Norton & Company, 2022
2022
-
[29]
Cultural similarities and differences in display rules,
D. Matsumoto, “Cultural similarities and differences in display rules,” Motivation and Emotion, vol. 14, no. 3, pp. 195–214, 1990
1990
-
[30]
Culture, emotion regu- lation, and adjustment,
D. Matsumoto, S. H. Yoo, and S. Nakagawa, “Culture, emotion regu- lation, and adjustment,”Journal of Personality and Social Psychology, vol. 94, no. 6, pp. 925–937, 2008
2008
-
[31]
Seeing race, feeling bias: Emotion stereotyping in multimodal language models,
M. Kamruzzaman, A. C. Curry, A. Cercas Curry, and F. M. Plaza-del Arco, “Seeing race, feeling bias: Emotion stereotyping in multimodal language models,” inFindings of the Association for Computational Lin- guistics: EMNLP 2025(C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, eds.), (Suzhou, China), pp. 7317–7351, Association for Computational...
2025
-
[32]
arXiv preprint arXiv:2601.13024
C. Dai, Y . Shen, J. Hu, Z. Gao, J. Li, Y . Jiang, Y . Wang, L. Liu, and Z. Ge, “Tears or cheers? benchmarking llms via culturally elicited distinct affective responses,”arXiv preprint arXiv:2601.13024, 2026
-
[33]
Aware yet biased: Investigating emotional reasoning and appraisal bias in large language models,
A. N. Tak, J. Gratch, and K. R. Scherer, “Aware yet biased: Investigating emotional reasoning and appraisal bias in large language models,”IEEE Transactions on Affective Computing, vol. 16, no. 4, pp. 2871–2880, 2025
2025
-
[34]
Cultural bias and cultural alignment of large language models,
Y . Tao, O. Viberg, R. C. Baker, and R. F. Kizilcec, “Cultural bias and cultural alignment of large language models,”PNAS Nexus, vol. 3, no. 9, pp. 1–9, 2024
2024
-
[35]
H. Yu, S. Jeong, S. Pawar, J. Shin, J. Jin, J. Myung, A. Oh, and I. Au- genstein, “Entangled in representations: Mechanistic investigation of cul- tural biases in large language models,”arXiv preprint arXiv:2508.08879, 2026
-
[36]
Having beer after prayer? measuring cultural bias in large language models,
T. Naous, M. J. Ryan, A. Ritter, and W. Xu, “Having beer after prayer? measuring cultural bias in large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)(L.-W. Ku, A. Martins, and V . Srikumar, eds.), (Bangkok, Thailand), pp. 16366–16393, Association for Computational Lingui...
2024
-
[37]
From word to world: Evaluate and mitigate culture bias in LLMs via word association test,
X. Dai, L. Zhou, B. Wang, and H. Li, “From word to world: Evaluate and mitigate culture bias in LLMs via word association test,” in Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, eds.), (Suzhou, China), pp. 24510–24526, Association for Computational Lingu...
2025
-
[38]
Towards realistic evaluation of cultural value alignment in large lan- guage models: Diversity enhancement for survey response simulation,
H. Liu, Y . Cao, X. Wu, C. Qiu, J. Gu, M. Liu, and D. Hershcovich, “Towards realistic evaluation of cultural value alignment in large lan- guage models: Diversity enhancement for survey response simulation,” Information Processing & Management, vol. 62, no. 4, p. 104099, 2025
2025
-
[39]
Divine LLaMAs: Bias, stereotypes, stigmatization, and emo- tion representation of religion in large language models,
F. M. Plaza-del Arco, A. C. Curry, S. Paoli, A. Cercas Curry, and D. Hovy, “Divine LLaMAs: Bias, stereotypes, stigmatization, and emo- tion representation of religion in large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2024(Y . Al- Onaizan, M. Bansal, and Y .-N. Chen, eds.), (Miami, Florida, USA), pp. 4346–4366, A...
2024
-
[40]
Generative language models exhibit social identity biases,
T. Hu, Y . Kyrychenko, S. Rathje, N. Collier, S. van der Linden, and J. Roozenbeek, “Generative language models exhibit social identity biases,”Nature Computational Science, vol. 5, pp. 65–75, 2025
2025
-
[41]
From anger to joy: How nationality personas shape emotion attribution in large language models,
M. Kamruzzaman, A. Al Monsur, G. L. Kim, and A. Chhabra, “From anger to joy: How nationality personas shape emotion attribution in large language models,” inProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Lin- guistics(K. Inui, S. ...
2025
-
[42]
The strong pull of prior knowledge in large language models and its impact on emotion recognition,
G. Chochlakis, A. Potamianos, K. Lerman, and S. Narayanan, “The strong pull of prior knowledge in large language models and its impact on emotion recognition,” in2024 12th International Conference on Affective Computing and Intelligent Interaction (ACII), pp. 318–326, 2024
2024
-
[43]
Analyzing Cultural Representations of Emotions in LLMs Through Mixed Emotion Survey ,
S. Dudy, I. S. Ahmad, R. Kitajima, and A. Lapedriza, “ Analyzing Cultural Representations of Emotions in LLMs Through Mixed Emotion Survey ,” in2024 12th International Conference on Affective Computing and Intelligent Interaction (ACII), (Los Alamitos, CA, USA), pp. 346– 354, IEEE Computer Society, Sept. 2024
2024
-
[44]
SemEval-2007 task 14: Affective text,
C. Strapparava and R. Mihalcea, “SemEval-2007 task 14: Affective text,” inProceedings of the Fourth International Workshop on Semantic Evaluations (SemEval-2007)(E. Agirre, L. M `arquez, and R. Wicen- towski, eds.), (Prague, Czech Republic), pp. 70–74, Association for Computational Linguistics, June 2007
2007
-
[45]
SemEval-2018 task 1: Affect in tweets,
S. Mohammad, F. Bravo-Marquez, M. Salameh, and S. Kiritchenko, “SemEval-2018 task 1: Affect in tweets,” inProceedings of the 12th International Workshop on Semantic Evaluation(M. Apidianaki, S. M. Mohammad, J. May, E. Shutova, S. Bethard, and M. Carpuat, eds.), (New Orleans, Louisiana), pp. 1–17, Association for Computational Linguistics, June 2018
2018
-
[46]
Recursive deep models for semantic compositionality over a sentiment treebank,
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Ng, and C. Potts, “Recursive deep models for semantic compositionality over a sentiment treebank,” inProceedings of the 2013 Conference on Empirical Methods in Natural Language Processing(D. Yarowsky, T. Baldwin, A. Korhonen, K. Livescu, and S. Bethard, eds.), (Seattle, Washington, USA), pp. 163...
2013
-
[47]
Thumbs up? sentiment clas- sification using machine learning techniques,
B. Pang, L. Lee, and S. Vaithyanathan, “Thumbs up? sentiment clas- sification using machine learning techniques,” inProceedings of the 2002 Conference on Empirical Methods in Natural Language Processing (EMNLP 2002), pp. 79–86, Association for Computational Linguistics, July 2002
2002
-
[48]
Text-based emotion inference and empathetic response: Evaluating the capabilities of large language models relative to human counselors,
Q. Zhou, L. Hu, J. Yan, Y . Cai, and Y . Zhang, “Text-based emotion inference and empathetic response: Evaluating the capabilities of large language models relative to human counselors,”Computers in Human Behavior Reports, vol. 21, p. 100904, 2025
2025
-
[49]
Beyond context to cognitive appraisal: Emotion reasoning as a theory of mind benchmark for large language models,
G. C. Yeo and K. Jaidka, “Beyond context to cognitive appraisal: Emotion reasoning as a theory of mind benchmark for large language models,” inFindings of the Association for Computational Linguistics: ACL 2025(W. Che, J. Nabende, E. Shutova, and M. T. Pilehvar, eds.), (Vienna, Austria), pp. 26517–26525, Association for Computational Linguistics, July 2025
2025
-
[50]
Do ma- chines think emotionally? cognitive appraisal analysis of large language models,
S. Bhattacharyya, L. Craig, T. Dilliraj, J. Li, and J. Z. Wang, “Do ma- chines think emotionally? cognitive appraisal analysis of large language models,”arXiv preprint arXiv:2508.05880, 2025
-
[51]
Third-person appraisal agent: Simulating human emotional reasoning in text with large language models,
S. Hong, J. Sun, and H. Chen, “Third-person appraisal agent: Simulating human emotional reasoning in text with large language models,” in Findings of the Association for Computational Linguistics: EMNLP 2025(C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, eds.), (Suzhou, China), pp. 23684–23701, Association for Computational Linguistics, Nov. 2025
2025
-
[52]
Emotion-llamav2 and mmeverse: A new framework and benchmark for multimodal emotion understanding,
X. Peng, J. Chen, Z. Cheng, B. Peng, F. Wu, Y . Dong, S. Tu, Q. Hu, H. Huang, Y . Lin, J.-Y . He, K. Wang, Z. Lian, and Z.-Q. Cheng, “Emotion-llamav2 and mmeverse: A new framework and benchmark for multimodal emotion understanding,”arXiv preprint arXiv:2601.16449, 2026
-
[53]
Evaluating vision-language models for emotion recognition,
S. Bhattacharyya and J. Z. Wang, “Evaluating vision-language models for emotion recognition,” inFindings of the Association for Computa- tional Linguistics: NAACL 2025, pp. 1798–1820, 2025
2025
-
[54]
DeepPavlov at SemEval-2024 task 3: Multimodal large language models in emotion reasoning,
J. Belikova and D. Kosenko, “DeepPavlov at SemEval-2024 task 3: Multimodal large language models in emotion reasoning,” inPro- ceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024)(A. K. Ojha, A. S. Do ˘gru¨oz, H. Tayyar Madabushi, G. Da San Martino, S. Rosenthal, and A. Ros ´a, eds.), (Mexico City, Mexico), pp. 1747–1757, Asso...
2024
-
[55]
A technique for the measurement of attitudes,
R. Likert, “A technique for the measurement of attitudes,”Archives of Psychology, vol. 22, no. 140, pp. 1–55, 1932
1932
-
[56]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi,et al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney,et al., “Openai o1 system card,”arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen,et al., “Gem- ini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,”arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
M. Abdin, J. Aneja, H. Behl, S. Bubeck, R. Eldan, S. Gunasekar, M. Harrison, R. J. Hewett, M. Javaheripi, P. Kauffmann,et al., “Phi-4 technical report,”arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review arXiv 2024
-
[60]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, L. R. Lavaud, M.-A. Lachaux, P. Stock, T. L. Scao, T. Lavril, T. Wang, T. Lacroix, and W. E. Sayed, “Mistral 7B,”arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[61]
Q. Team, “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
On a test of whether one of two random variables is stochastically larger than the other,
H. B. Mann and D. R. Whitney, “On a test of whether one of two random variables is stochastically larger than the other,”The Annals of Mathematical Statistics, pp. 50–60, 1947
1947
-
[63]
Markov processes over denumerable products of spaces, describing large systems of automata,
L. N. Vaserstein, “Markov processes over denumerable products of spaces, describing large systems of automata,”Problemy Peredachi Informatsii, vol. 5, no. 3, pp. 64–72, 1969
1969
-
[64]
The Correlation between Relatives on the Supposition of Mendelian Inheritance,
R. A. Fisher, “The Correlation between Relatives on the Supposition of Mendelian Inheritance,”Earth and Environmental Science Transactions of the Royal Society of Edinburgh, vol. 52, no. 2, pp. 399–433, 1919
1919
-
[65]
Culture’s consequences: International differences in work- related values,
G. Hofstede, “Culture’s consequences: International differences in work- related values,”Beverly Hills, 1980
1980
-
[66]
Multilingual != multicultural: Evaluating gaps between multilingual capabilities and cultural alignment in LLMs,
J. H. Rystrøm, H. R. Kirk, and S. Hale, “Multilingual != multicultural: Evaluating gaps between multilingual capabilities and cultural alignment in LLMs,” inProceedings of Interdisciplinary Workshop on Observa- tions of Misunderstood, Misguided and Malicious Use of Language Models(P. Przybyła, M. Shardlow, C. Colombatto, and N. Inie, eds.), (Varna, Bulgar...
2025
-
[67]
Artificial hivemind: The open-ended homogeneity of language models (and beyond),
L. Jiang, Y . Chai, M. Li, M. Liu, R. Fok, N. Dziri, Y . Tsvetkov, M. Sap, and Y . Choi, “Artificial hivemind: The open-ended homogeneity of language models (and beyond),” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[68]
Strategic Algorithmic Monoculture: Experimental Evidence from Coordination Games
G. Ballestero, H. Hosseini, S. Khanna, and R. I. Shorrer, “Strategic algo- rithmic monoculture: Experimental evidence from coordination games,” arXiv preprint arXiv:2604.09502, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[69]
Towards understanding sycophancy in language models,
M. Sharma, M. Tong, T. Korbak, D. Duvenaud, A. Askell, S. R. Bowman, E. DURMUS, Z. Hatfield-Dodds, S. R. Johnston, S. M. Kravec,et al., “Towards understanding sycophancy in language models,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[70]
Validity problems comparing values across cultures and possible solutions,
K. Peng, R. E. Nisbett, and N. Y . Wong, “Validity problems comparing values across cultures and possible solutions,”Psychological Methods, vol. 2, no. 4, pp. 329–344, 1997
1997
-
[71]
Machine bias. how do generative language models answer opinion polls?,
J. Boelaert, S. Coavoux, ´E. Ollion, I. Petev, and P. Pr ¨ag, “Machine bias. how do generative language models answer opinion polls?,”Sociological Methods & Research, vol. 54, no. 3, pp. 1156–1196, 2025
2025
-
[72]
Llm voting: Human choices and ai collective decision-making,
J. C. Yang, D. Dailisan, M. Korecki, C. I. Hausladen, and D. Helbing, “Llm voting: Human choices and ai collective decision-making,” in Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, vol. 7, pp. 1696–1708, 2024
2024
-
[73]
M. Peeperkorn, T. Kouwenhoven, D. Brown, and A. Jordanous, “Is temperature the creativity parameter of large language models?,”arXiv preprint arXiv:2405.00492, 2024
-
[74]
Culture’s consequences: International differences in work-related values,
W. J. Lonner, J. W. Berry, and G. H. Hofstede, “Culture’s consequences: International differences in work-related values,”University of Illinois at Urbana-Champaign’s Academy for Entrepreneurial Leadership His- torical Research Reference in Entrepreneurship, 1980
1980
-
[75]
Cultural psychology: Beyond east and west,
S. Kitayama and C. E. Salvador, “Cultural psychology: Beyond east and west,”Annual Review of Psychology, vol. 75, no. 1, pp. 495–526, 2024
2024
-
[76]
Coefficient Alpha and the Internal Structure of Tests,
L. J. Cronbach, “Coefficient Alpha and the Internal Structure of Tests,” Psychometrika, vol. 16, no. 3, pp. 297–334, 1951. APPENDIX A. Additional Details on Human Study In this section, we provide additional details about the original human study that our analysis draws upon [19]. Situations for analysis.The human study uses 4 scenarios to ask for partici...
1951
-
[77]
Engaging Vs. Disengaging Emotions:Here, we present additional evidence of misalignment found in expression of engaging emotions, as opposed to disengaging emotions, per- taining to the hypotheses[H1a]and[H1b]from the human results. First, we present the full plots of distributional comparison for all models in Fig. 8. The alignment of each model here foll...
-
[78]
Closeness
Situational Comparison:The original human study [19], within the broader claims of expressivity, also studied gran- ular differences in expressivity, within each type of situation (valence = positive, negative×sociality = personal, social). Similar to the original study, we analyzeinterdependence dominanceat the situation level—by calculating the differen...
-
[79]
Inter-Model Homogeneity:Here, we present the com- plete Pearson correlation values calculated between each pair of models, and for each model with the human distribution, depicted in Fig. 12. Note that the values are calculated over the entire space of responses, across all emotions and cultures. G. Modifying Sampling Temperatures
-
[80]
Note that for GPT-o4, which is a reasoning model, only the default temperature setting is allowed to be set
Exact Temperature Values for Models:For each model studied, we begin with the highest possible temperature setting and check the quality of responses. Note that for GPT-o4, which is a reasoning model, only the default temperature setting is allowed to be set. Also for two of the open- source models, Phi and Mistral, we study a wide range of temperatures, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.