Recognition: unknown
CoGR-MoE: Concept-Guided Expert Routing with Consistent Selection and Flexible Reasoning for Visual Question Answering
Pith reviewed 2026-05-10 07:06 UTC · model grok-4.3
The pith
CoGR-MoE uses semantics from answer options to guide expert selection in Mixture-of-Experts models, then reweights those experts with option features to create discriminative representations for contrastive option comparison in Visual Q&A.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CoGR-MoE incorporates semantics of the answer options to guide expert selection in the training phase. Option features are used to reweight the selected experts, producing discriminative representations for each candidate option. These option-level representations are further used for option comparison and optimized via contrastive learning, delivering strong performance across multiple VQA tasks.
What carries the argument
Concept-Guided Routing in MoE, where answer-option semantics direct expert selection during training and option features reweight the selected experts to form option-specific representations before contrastive comparison.
If this is right
- Expert selection becomes consistent within the same question type while still permitting flexible reasoning across different options.
- Each candidate answer receives its own reweighted expert representation that highlights discriminative features.
- Contrastive optimization on these representations improves the model's ability to rank correct answers over incorrect ones.
- The overall framework yields measurable gains on multiple VQA benchmarks without changing the underlying expert architecture.
Where Pith is reading between the lines
- The same guidance pattern could be tested on other multiple-choice multimodal tasks where answer semantics are available at training time.
- If option semantics prove noisy, the reweighting step might still stabilize routing even when the initial selection is imperfect.
- Applying the same two-stage routing to vision-language models outside VQA could reveal whether the consistency-flexibility trade-off is domain-specific.
Load-bearing premise
That semantics of the answer options can reliably guide expert selection in training and that option-feature reweighting will produce discriminative representations without introducing new instabilities or biases in routing.
What would settle it
Training an otherwise identical MoE model without the option-semantics guidance step and without the feature-reweighting step, then measuring whether accuracy on standard VQA benchmarks such as VQA-v2 or GQA drops by a statistically significant margin.
Figures




read the original abstract
Visual Question Answering (VQA) requires models to identify the correct answer options based on both visual and textual evidence. Recent Mixture-of-Experts (MoE) methods improve option reasoning by grouping similar concepts or routing based on examples. However, unstable routing can lead to inconsistent expert selection in the same question type, while overly stable routing may reduce flexibility. To address this, we propose Concept-Guided Routing framework (CoGR-MoE), which incorporates semantics of the answer options to guide expert selection in the training phase. Next, option features are used to reweight the selected experts, producing discriminative representations for each candidate option. These option-level representations are further used for option comparison and optimized via contrastive learning. The experimental results indicate that CoGR-MoE delivers strong performance across multiple VQA tasks, demonstrating the effectiveness of our approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CoGR-MoE, a Concept-Guided Routing framework for Mixture-of-Experts models in Visual Question Answering. It guides expert selection during training using semantics of answer options, reweights the selected experts with option features to produce discriminative representations, and optimizes the resulting option-level representations via contrastive learning for improved option comparison. The central claim is that this balances routing consistency and flexibility, yielding strong empirical performance across multiple VQA tasks.
Significance. If the empirical results hold under scrutiny, the work could meaningfully advance MoE routing strategies for multimodal reasoning by providing an explicit mechanism to stabilize expert selection without eliminating adaptability. The separation of routing guidance (option semantics) from representation refinement (reweighting + contrastive loss) is a clean architectural choice that may generalize beyond VQA.
minor comments (2)
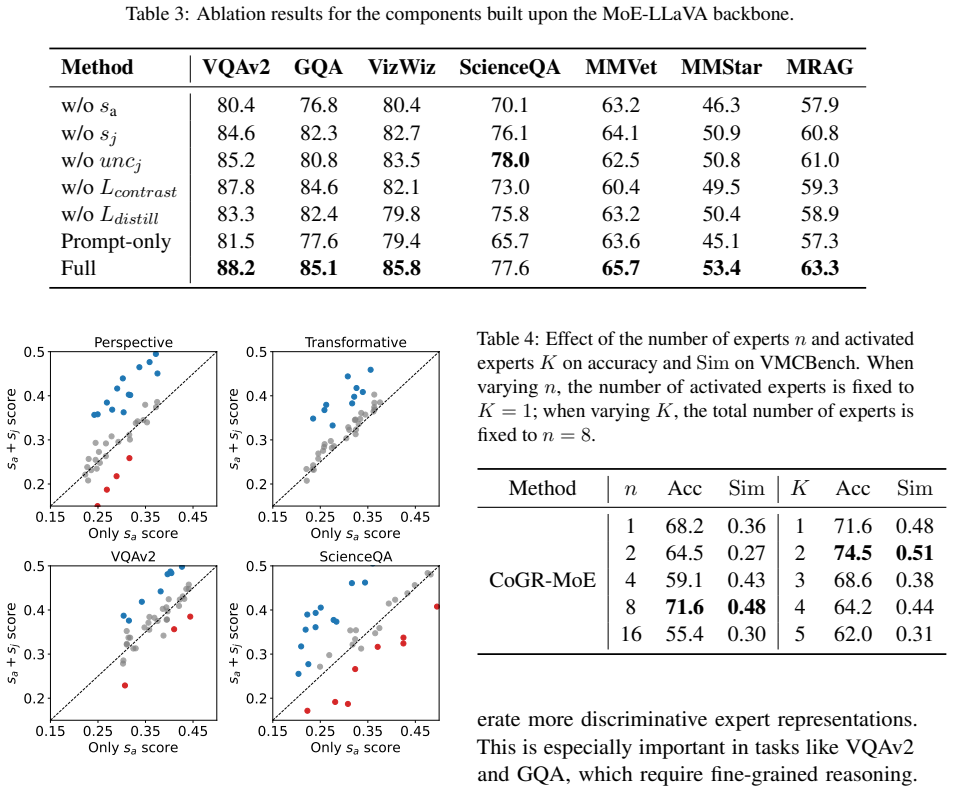
- The abstract asserts 'strong performance across multiple VQA tasks' without naming the datasets, baselines, or quantitative margins. The experiments section should include a clear table of results with standard VQA benchmarks (e.g., VQA-v2, GQA) and ablations on the routing and contrastive components to make the performance claim verifiable.
- Notation for the routing function and the option-feature reweighting operation is introduced in the abstract but not previewed with equation numbers; adding a brief methods overview with numbered equations would improve readability for readers unfamiliar with the specific MoE variant.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript, the recognition of the significance of the concept-guided routing mechanism, and the recommendation for minor revision. We appreciate the note that the separation of routing guidance from representation refinement represents a clean architectural choice.
Circularity Check
No significant circularity
full rationale
The paper introduces CoGR-MoE as a new framework that uses answer-option semantics to guide MoE expert routing during training, applies option-feature reweighting to produce representations, and optimizes via contrastive learning on those representations. These steps are motivated by addressing instability and inflexibility in prior MoE routing and are presented as independent architectural choices whose effectiveness is evaluated empirically on VQA benchmarks. No equations or derivations are shown that reduce the claimed performance or routing behavior to the inputs by construction, no fitted parameters are relabeled as predictions, and no load-bearing self-citations or uniqueness theorems are invoked. The derivation chain remains self-contained against external data and prior MoE literature.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Semantics of answer options can be used to guide expert selection during training without destabilizing the model
- domain assumption Option features can reweight selected experts to yield more discriminative representations for comparison
Reference graph
Works this paper leans on
-
[1]
Ekaterina Borisova, Nikolas Rauscher, and Georg Rehm. 2025. https://doi.org/10.18653/v1/2025.sdp-1.18 S ci VQA 2025: Overview of the first scientific visual question answering shared task . In Proceedings of the Fifth Workshop on Scholarly Document Processing (SDP 2025), pages 182--210, Vienna, Austria. Association for Computational Linguistics
-
[2]
Weilin Cai, Juyong Jiang, Fan Wang, Jing Tang, Sunghun Kim, and Jiayi Huang. 2025. https://doi.org/10.1109/tkde.2025.3554028 A survey on mixture of experts in large language models . IEEE Transactions on Knowledge and Data Engineering, page 1–20
-
[3]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. 2024. https://arxiv.org/abs/2403.20330 Are we on the right way for evaluating large vision-language models? Preprint, arXiv:2403.20330
work page internal anchor Pith review arXiv 2024
-
[4]
Long Chen, Yuhang Zheng, Yulei Niu, Hanwang Zhang, and Jun Xiao. 2023. https://doi.org/10.1109/TPAMI.2023.3290012 Counterfactual samples synthesizing and training for robust visual question answering . IEEE Trans. Pattern Anal. Mach. Intell. , 45(11):13218--13234
-
[5]
Anzhe Cheng, Shukai Duan, Shixuan Li, Chenzhong Yin, Mingxi Cheng, Heng Ping, Tamoghna Chattopadhyay, Sophia I Thomopoulos, Shahin Nazarian, Paul Thompson, and Paul Bogdan. 2025 a . https://arxiv.org/abs/2511.10971 Ermoe: Eigen-reparameterized mixture-of-experts for stable routing and interpretable specialization . Preprint, arXiv:2511.10971
-
[6]
YuJu Cheng, Yu-Chu Yu, Kai-Po Chang, and Yu-Chiang Frank Wang. 2025 b . https://doi.org/10.18653/v1/2025.acl-long.1492 Serial lifelong editing via mixture of knowledge experts . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 30888--30903, Vienna, Austria. Association for Computatio...
- [7]
- [8]
-
[9]
Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P
Danna Gurari, Qing Li, Abigale J. Stangl, Anhong Guo, Chi Lin, Kristen Grauman, Jiebo Luo, and Jeffrey P. Bigham. 2018. https://arxiv.org/abs/1802.08218 Vizwiz grand challenge: Answering visual questions from blind people . Preprint, arXiv:1802.08218
- [10]
- [11]
- [12]
- [13]
-
[14]
Drew A. Hudson and Christopher D. Manning. 2019. https://arxiv.org/abs/1902.09506 Gqa: A new dataset for real-world visual reasoning and compositional question answering . Preprint, arXiv:1902.09506
-
[15]
Byeong Su Kim, Jieun Kim, Deokwoo Lee, and Beakcheol Jang. 2025. https://doi.org/10.1145/3728635 Visual question answering: A survey of methods, datasets, evaluation, and challenges . ACM Comput. Surv., 57(10)
- [16]
- [17]
- [18]
-
[19]
Yunxin Li, Xinyu Chen, Shenyuan Jiang, Haoyuan Shi, Zhenyu Liu, Xuanyu Zhang, Nanhao Deng, Zhenran Xu, Yicheng Ma, Meishan Zhang, Baotian Hu, and Min Zhang. 2025 b . https://arxiv.org/abs/2511.12609 Uni-moe-2.0-omni: Scaling language-centric omnimodal large model with advanced moe, training and data . Preprint, arXiv:2511.12609
- [20]
- [21]
- [22]
-
[23]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024. https://arxiv.org/abs/2310.03744 Improved baselines with visual instruction tuning . Preprint, arXiv:2310.03744
work page internal anchor Pith review arXiv 2024
-
[24]
Pan Lu, Swaroop Mishra, Tony Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022 a . https://arxiv.org/abs/2209.09513 Learn to explain: Multimodal reasoning via thought chains for science question answering . Preprint, arXiv:2209.09513
- [25]
- [26]
-
[27]
Taishi Nakamura, Takuya Akiba, Kazuki Fujii, Yusuke Oda, Rio Yokota, and Jun Suzuki. 2025. https://openreview.net/forum?id=gx1wHnf5Vp Drop-upcycling: Training sparse mixture of experts with partial re-initialization . In The Thirteenth International Conference on Learning Representations
2025
- [28]
- [29]
- [30]
-
[31]
Leyang Shen, Gongwei Chen, Rui Shao, Weili Guan, and Liqiang Nie. 2024 b . Mome: Mixture of multimodal experts for generalist multimodal large language models. In Advances in Neural Information Processing Systems (NeurIPS)
2024
- [32]
-
[33]
Yujie Wei, Shiwei Zhang, Hangjie Yuan, Yujin Han, Zhekai Chen, Jiayu Wang, Difan Zou, Xihui Liu, Yingya Zhang, Yu Liu, and Hongming Shan. 2025. https://arxiv.org/abs/2510.24711 Routing matters in moe: Scaling diffusion transformers with explicit routing guidance . Preprint, arXiv:2510.24711
-
[34]
Zhiquan Wen, Yaowei Wang, Mingkui Tan, Qingyao Wu, and Qi Wu. 2023. https://doi.org/10.18653/v1/2023.findings-acl.432 Digging out discrimination information from generated samples for robust visual question answering . In Findings of the Association for Computational Linguistics: ACL 2023, pages 6910--6928, Toronto, Canada. Association for Computational L...
- [35]
- [36]
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. 2024. https://arxiv.org/abs/2308.02490 Mm-vet: Evaluating large multimodal models for integrated capabilities . Preprint, arXiv:2308.02490
work page internal anchor Pith review arXiv 2024
-
[39]
Yuhui Zhang, Yuchang Su, Yiming Liu, Xiaohan Wang, James Burgess, Elaine Sui, Chenyu Wang, Josiah Aklilu, Alejandro Lozano, Anjiang Wei, Ludwig Schmidt, and Serena Yeung-Levy. 2025. Automated generation of challenging multiple-choice questions for vision language model evaluation. In Conference on Computer Vision and Pattern Recognition (CVPR)
2025
- [40]
-
[41]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[42]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.