Recognition: unknown
MCPO: Mastery-Consolidated Policy Optimization for Large Reasoning Models
Pith reviewed 2026-05-10 07:01 UTC · model grok-4.3
The pith
MCPO fixes vanishing advantages and shrinking weights in GRPO to consolidate mastery in LLM reasoning training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MCPO adds a hinge-KL regularizer that activates only on mastered prompts to limit harmful policy changes between gradient steps, together with a query-weighting scheme that assigns higher optimization priority to majority-correct prompts. When applied on top of GRPO-style objectives, this combination raises pass@1 scores across three mathematical reasoning benchmarks while simultaneously increasing pass@k, showing that stronger mastery consolidation also expands the set of correct solutions found.
What carries the argument
A hinge-KL regularizer restricted to mastered prompts combined with upward reweighting of majority-correct prompts.
If this is right
- Pass@1 accuracy rises consistently on mathematical reasoning benchmarks.
- Pass@k metrics also increase, indicating greater solution diversity rather than reduced exploration.
- Mastery on high-accuracy prompts is preserved instead of forgotten through uncontrolled drift.
- Optimization effort is redirected toward prompts that are close to but not yet at full correctness.
Where Pith is reading between the lines
- The same hinge-KL and reweighting pattern could be tested on non-mathematical verifiable-reward tasks such as code generation or formal theorem proving.
- If mastery consolidation reliably increases diversity, future RLVR methods might deliberately strengthen rather than weaken signals on near-mastered examples.
- The approach suggests that explicit control of policy drift on saturated prompts may be more effective than uniform KL penalties across all data.
Load-bearing premise
The two GRPO issues of vanishing advantages on mastered prompts and shrinking query weights on majority-correct prompts are the main obstacles to good consolidation, and the new hinge-KL term plus reweighting will not create instabilities or lower sample efficiency.
What would settle it
Running the identical models and three benchmarks with MCPO versus standard GRPO and finding no gain in pass@1 or a drop in pass@k would falsify the claim that the proposed fixes improve both mastery and diversity.
Figures






read the original abstract
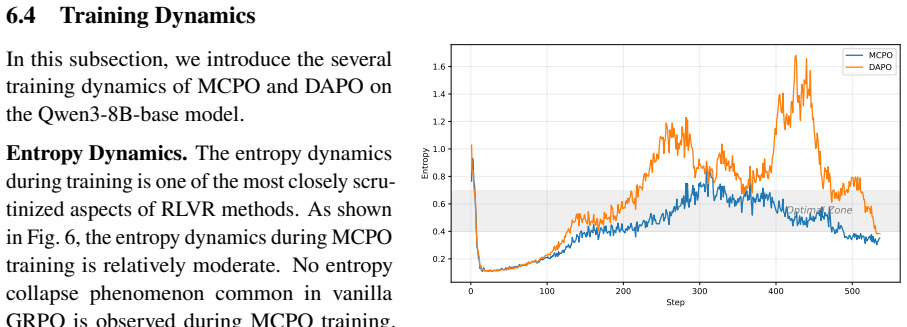
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a promising approach to improve the reasoning abilities of Large Language Models (LLMs). Among RLVR algorithms, Group Relative Policy Optimization (GRPO) and its variants have demonstrated strong performance and high training efficiency. However, GRPO-style objectives exhibit two issues on high accuracy prompts including mastered prompts (rollout accuracy =1) and majority-correct prompts (rollout accuracy in (0.5,1)). For mastered prompts, group-relative advantages vanish, yielding no training signal and unconstrained policy drift that can cause forgetting. For majority-correct prompts, the induced query weight shrinks as accuracy increases, weakening consolidation from partial correctness to mastery. To alleviate this, we propose Mastery-Consolidated Policy Optimization (MCPO), which introduces (i) a hinge-KL regularizer applied exclusively to mastered prompts to bound harmful policy drift between successive gradient steps, and (ii) a weighting mechanism that prioritizes majority-correct prompts to better allocate optimization effort. Extensive experiments across three mathematical benchmarks demonstrate that MCPO consistently improves pass@1 performance. Counter-intuitively, rather than restricting exploration, MCPO boosts pass@k metrics, indicating that mastery consolidation further catalyzes solution diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mastery-Consolidated Policy Optimization (MCPO) to address two identified limitations of Group Relative Policy Optimization (GRPO) in RLVR for LLMs: vanishing group-relative advantages on mastered prompts (rollout accuracy=1), which removes training signal and permits unconstrained drift/forgetting, and shrinking query weights on majority-correct prompts (accuracy in (0.5,1)), which weakens consolidation. MCPO introduces a hinge-KL regularizer applied only to mastered prompts and a reweighting scheme that prioritizes majority-correct prompts. Experiments on three mathematical benchmarks are reported to show consistent pass@1 gains and, counter-intuitively, improved pass@k, suggesting that better mastery consolidation also increases solution diversity.
Significance. If the performance gains are robust and causally attributable to the proposed mechanisms rather than implementation details or post-hoc selection, MCPO would offer a practical, low-overhead refinement to GRPO-style RLVR that improves both accuracy and diversity without additional sampling cost. The counter-intuitive pass@k result, if replicated, would be noteworthy for the RL-for-reasoning literature.
major comments (4)
- [§3.1–3.2] §3.1–3.2: The central causal claim—that vanishing advantages on mastered prompts and shrinking weights on majority-correct prompts are the primary drivers of suboptimal consolidation and forgetting in GRPO—is asserted without isolating evidence. No training curves, per-prompt accuracy trajectories, or direct GRPO-vs-MCPO comparisons on drift/forgetting metrics are provided to show that GRPO actually forgets mastered items while MCPO prevents it.
- [§4.3 and Table 2] §4.3 and Table 2: The reported pass@1 and pass@k improvements lack component ablations (hinge-KL alone, reweighting alone, both). Without these, it is impossible to attribute gains to mastery consolidation rather than incidental changes in effective learning rate or regularization strength.
- [§4.1, Eq. (7)–(9)] §4.1, Eq. (7)–(9): The hinge-KL term is defined to activate only when rollout accuracy=1, yet no analysis is given of how often this condition occurs during training or whether the hinge threshold introduces new instabilities (e.g., sudden on/off regularization) that could offset the intended stabilization.
- [§4.2] §4.2: The reweighting mechanism is claimed to allocate more optimization effort to majority-correct prompts, but no sample-efficiency or gradient-norm statistics are reported to confirm that this does not simply reduce effective batch size or slow overall progress on hard prompts.
minor comments (2)
- [Abstract and §1] Abstract and §1: Quantitative results (absolute pass@1 deltas, number of runs, error bars, statistical significance) are absent from the abstract and only summarized in the main text; this makes it difficult for readers to assess effect size immediately.
- [§5] §5: The three benchmarks are named but no details on prompt difficulty distribution, number of test items, or whether the same prompts were used for training and evaluation are supplied, complicating reproducibility.
Simulated Author's Rebuttal
We sincerely thank the referee for the careful reading and constructive feedback on our manuscript. The comments identify key areas where additional empirical support would strengthen the claims about MCPO. We address each major comment point by point below and have revised the manuscript to incorporate the requested analyses and ablations.
read point-by-point responses
-
Referee: [§3.1–3.2] The central causal claim—that vanishing advantages on mastered prompts and shrinking weights on majority-correct prompts are the primary drivers of suboptimal consolidation and forgetting in GRPO—is asserted without isolating evidence. No training curves, per-prompt accuracy trajectories, or direct GRPO-vs-MCPO comparisons on drift/forgetting metrics are provided to show that GRPO actually forgets mastered items while MCPO prevents it.
Authors: We agree that direct isolating evidence is needed to support the causal mechanisms. In the revised manuscript, we will add training curves showing advantage vanishing and policy drift on mastered prompts under GRPO, per-prompt accuracy trajectories over training, and side-by-side GRPO-vs-MCPO comparisons on forgetting metrics such as policy divergence on previously mastered items. revision: yes
-
Referee: [§4.3 and Table 2] The reported pass@1 and pass@k improvements lack component ablations (hinge-KL alone, reweighting alone, both). Without these, it is impossible to attribute gains to mastery consolidation rather than incidental changes in effective learning rate or regularization strength.
Authors: We acknowledge the value of component ablations for causal attribution. We will add these experiments to the revised version, reporting results for hinge-KL alone, reweighting alone, and the full MCPO combination on the same benchmarks to isolate the contribution of each mechanism to the observed pass@1 and pass@k gains. revision: yes
-
Referee: [§4.1, Eq. (7)–(9)] The hinge-KL term is defined to activate only when rollout accuracy=1, yet no analysis is given of how often this condition occurs during training or whether the hinge threshold introduces new instabilities (e.g., sudden on/off regularization) that could offset the intended stabilization.
Authors: We will include a new analysis of hinge-KL activation frequency across training steps and benchmarks. We will also report stability metrics such as loss variance and policy divergence to evaluate whether the on/off nature of the hinge introduces instabilities, and discuss any observed effects or adjustments in the revised manuscript. revision: yes
-
Referee: [§4.2] The reweighting mechanism is claimed to allocate more optimization effort to majority-correct prompts, but no sample-efficiency or gradient-norm statistics are reported to confirm that this does not simply reduce effective batch size or slow overall progress on hard prompts.
Authors: We agree that supporting statistics are necessary. In the revision, we will report gradient-norm distributions and effective sample-size calculations under the reweighting scheme, along with learning curves for hard prompts, to demonstrate that prioritization improves consolidation without reducing overall progress or effective batch size on difficult examples. revision: yes
Circularity Check
No circularity: empirical proposal with independent experimental validation
full rationale
The paper identifies two GRPO issues via analysis of advantages and query weights on high-accuracy prompts, proposes MCPO fixes (hinge-KL regularizer on mastered prompts plus reweighting), and reports pass@1/pass@k gains on three benchmarks. No equations, derivations, or self-citations appear in the provided text that reduce the method or claims to self-definition, fitted inputs renamed as predictions, or load-bearing self-citation chains. The central claims rest on external benchmark results rather than tautological reductions, making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. OpenAI O1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in Neural Information Processing Systems, 35:27730–27744, 2022
2022
-
[4]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[5]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in AI safety.arXiv preprint arXiv:1606.06565, 2016
work page internal anchor Pith review arXiv 2016
-
[6]
Scaling laws for reward model overoptimization
Leo Gao, John Schulman, and Jacob Hilton. Scaling laws for reward model overoptimization. In International Conference on Machine Learning, pages 10835–10866, 2023
2023
-
[7]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Learning to summarize with human feedback.Advances in Neural Information Processing Systems, 33:3008–3021, 2020
Nisan Stiennon, Long Ouyang, Jeffrey Wu, Daniel Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F Christiano. Learning to summarize with human feedback.Advances in Neural Information Processing Systems, 33:3008–3021, 2020
2020
-
[9]
Human-level control through deep reinforcement learning.Nature, 518:529–533, 2015
VolodymyrMnih,KorayKavukcuoglu,DavidSilver,AndreiARusu,JoelVeness,MarcGBellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.Nature, 518:529–533, 2015
2015
-
[10]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. DAPO: An open-source LLM reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. 12
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
Dcpo: Dynamic clipping policy optimization.arXiv preprint arXiv:2509.02333, 2025
Shihui Yang, Chengfeng Dou, Peidong Guo, Kai Lu, Qiang Ju, Fei Deng, and Rihui Xin. DCPO: Dynamic clipping policy optimization.arXiv preprint arXiv:2509.02333, 2025
-
[13]
KaiyuanChen,GuangminZheng,JinWang,XiaobingZhou,andXuejieZhang. SAPO:Self-adaptive process optimization makes small reasoners stronger.arXiv preprint arXiv:2601.20312, 2026
-
[14]
Ode analysis of stochastic gradient methods with optimism and anchoring for minimax problems
ErnestKRyu,KunYuan,andWotaoYin. Odeanalysisofstochasticgradientmethodswithoptimism and anchoring for minimax problems.arXiv preprint arXiv:1905.10899, 2019
-
[15]
Li, G., Lin, M., Galanti, T., Tu, Z., and Yang, T
Gang Li, Ming Lin, Tomer Galanti, Zhengzhong Tu, and Tianbao Yang. DisCO: Reinforcing large reasoning models with discriminative constrained optimization.arXiv preprint arXiv:2505.12366, 2025
-
[16]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[17]
JoshAchiam, StevenAdler, SandhiniAgarwal, LamaAhmad, IlgeAkkaya, FlorenciaLeoniAleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y. Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, et al. Kimi K2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review arXiv 2026
-
[21]
GLM-5: from Vibe Coding to Agentic Engineering
Aohan Zeng, Xin Lv, Zhenyu Hou, Zhengxiao Du, Qinkai Zheng, Bin Chen, Da Yin, Chendi Ge, Chenghua Huang, Chengxing Xie, et al. GLM-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review arXiv 2026
-
[22]
Kimi K2: Open Agentic Intelligence
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, et al. Kimi K2: Open agentic intelligence.arXiv preprint arXiv:2507.20534, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan,HuayuChen,WeizeChen,etal. Theentropymechanismofreinforcementlearningforreasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Quantile advantage estimation for entropy-safe reasoning.arXiv preprint arXiv:2509.22611, 2025
Junkang Wu, Kexin Huang, Jiancan Wu, An Zhang, Xiang Wang, and Xiangnan He. Quantile advantage estimation for entropy-safe reasoning.arXiv preprint arXiv:2509.22611, 2025
-
[25]
Xiao Liang, Zhongzhi Li, Yeyun Gong, Yelong Shen, Ying Nian Wu, Zhijiang Guo, and Weizhu Chen. Beyond pass@1: Self-play with variational problem synthesis sustains rlvr.arXiv preprint arXiv:2508.14029, 2025. 13
-
[26]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@k training for adaptively balancing exploration and exploitation of large reasoning models. arXiv preprint arXiv:2508.10751, 2025
-
[27]
Geometric-mean policy optimization
Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shaohan Huang, Lei Cui, Qixiang Ye, Fang Wan, and Furu Wei. Geometric-mean policy optimization. In The International Conference on Learning Representations, 2026
2026
-
[28]
Thanh-Long V Le, Myeongho Jeon, Kim Vu, Viet Lai, and Eunho Yang. No prompt left behind: Exploiting zero-variance prompts in LLM reinforcement learning via entropy-guided advantage shaping.arXiv preprint arXiv:2509.21880, 2025
-
[29]
NGRPO: Negative-enhanced group relative policy optimization.arXiv preprint arXiv:2509.18851, 2025
Gongrui Nan, Siye Chen, Jing Huang, Mengyu Lu, Dexun Wang, Chunmei Xie, Weiqi Xiong, Xianzhou Zeng, Qixuan Zhou, Yadong Li, et al. NGRPO: Negative-enhanced group relative policy optimization.arXiv preprint arXiv:2509.18851, 2025
-
[30]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page Pith review arXiv 2025
-
[31]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational Conference on Machine Learning, pages 1861–1870, 2018
2018
-
[32]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xionghui Chen, Jianxin Yang, Zhenru Zhang, et al. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning.arXiv preprint arXiv:2506.01939, 2025
work page internal anchor Pith review arXiv 2025
-
[33]
Haizhong Zheng, Yang Zhou, Brian R. Bartoldson, Bhavya Kailkhura, Fan Lai, Jiawei Zhao, and BeidiChen. Actonlywhenitpays: EfficientreinforcementlearningforLLMreasoningviaselective rollouts.arXiv preprint arXiv:2506.02177, 2025
-
[34]
Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[35]
Hybridflow: A flexible and efficient RLHF framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient RLHF framework. InProceedings of the European Conference on Computer Systems, page 1279–1297, 2025
2025
-
[36]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. 14 A Appendix A.1 Proof of the Query Weight in MCPO Assume binary rewards 𝑅(𝑥, 𝑦) ∈ {0,1} and a non-degenerate rollout group for a prompt𝑥, i.e., 0< 𝑝(𝑥)<1 . Let the MCPO advantage be defined as Eq. (12) in the main article, with the scaling fu...
work page internal anchor Pith review Pith/arXiv arXiv 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.