Recognition: unknown
Seeing Isn't Believing: Mitigating Belief Inertia via Active Intervention in Embodied Agents
Pith reviewed 2026-05-10 06:20 UTC · model grok-4.3
The pith
Embodied agents improve decisions when they actively estimate expected outcomes, verify them against observations, and update their beliefs instead of clinging to initial assumptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
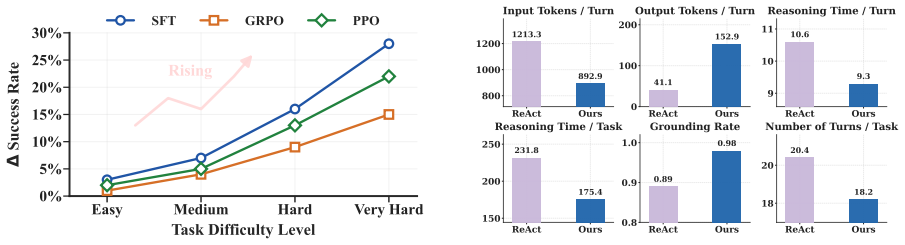
Belief inertia occurs when agents in embodied settings adhere to prior beliefs despite receiving explicit contradictory observations from the environment, which produces suboptimal actions. The Estimate-Verify-Update mechanism counters this by generating predictions of expected outcomes, verifying those predictions against actual feedback via structured reasoning, and actively revising prior beliefs to produce updated textual belief states. This intervention serves as a unified add-on that integrates into prompting-based and training-based agent frameworks and delivers measurable gains in task success across benchmarks.
What carries the argument
The Estimate-Verify-Update (EVU) mechanism, which forces agents to estimate outcomes, verify estimates against observations through explicit reasoning, and revise textual belief states.
If this is right
- Agents complete more tasks successfully on embodied benchmarks that require ongoing interaction with changing environments.
- Measured belief inertia decreases as agents begin to incorporate contradictory feedback into their reasoning.
- The same intervention improves performance whether agents reason via prompts alone or via additional training.
- Decision quality rises specifically in cases where observations diverge from what the agent initially expected.
Where Pith is reading between the lines
- The approach could be tested in physical robots to see whether explicit verification steps help handle noisy real-world sensor data.
- Explicit textual belief states produced by the mechanism might make agent reasoning easier for humans to inspect and debug.
- Similar verification loops could be applied to non-embodied language model tasks such as long-horizon planning or multi-turn dialogue.
- Incorporating the verification step as a training objective might produce agents that learn belief updating as an automatic skill.
Load-bearing premise
The formal probing analysis correctly isolates belief inertia as the primary cause of poor decisions rather than perception noise or planning mistakes.
What would settle it
Applying the Estimate-Verify-Update steps on the three benchmarks and observing no increase in task success rates together with no decrease in the belief inertia metrics measured by probing would falsify the central claim.
Figures












read the original abstract
Recent advancements in large language models (LLMs) have enabled agents to tackle complex embodied tasks through environmental interaction. However, these agents still make suboptimal decisions and perform ineffective actions, as they often overlook critical environmental feedback that differs from their internal beliefs. Through a formal probing analysis, we characterize this as belief inertia, a phenomenon where agents stubbornly adhere to prior beliefs despite explicit observations. To address this, we advocate active belief intervention, moving from passive understanding to active management. We introduce the Estimate-Verify-Update (EVU) mechanism, which empowers agents to predict expected outcomes, verify them against observations through explicit reasoning, and actively update prior beliefs based on the verification evidence. EVU is designed as a unified intervention mechanism that generates textual belief states explicitly, and can be integrated into both prompting-based and training-based agent reasoning methods. Extensive experiments across three embodied benchmarks demonstrate that EVU consistently yields substantial gains in task success rates. Further analyses validate that our approach effectively mitigates belief inertia, advancing the development of more robust embodied agents. Our code is available at https://github.com/WangHanLinHenry/EVU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-based embodied agents exhibit 'belief inertia'—stubborn adherence to prior beliefs despite contradictory observations—which is characterized via formal probing analysis as a key cause of suboptimal decisions. To address this, the authors introduce the Estimate-Verify-Update (EVU) mechanism: agents explicitly estimate expected outcomes, verify them against environmental observations through reasoning, and actively update textual belief states. EVU is presented as a unified intervention integrable with both prompting-based and training-based agent methods. Experiments across three embodied benchmarks report consistent gains in task success rates, with additional analyses claimed to validate mitigation of belief inertia. Code is released for reproducibility.
Significance. If the probing analysis isolates belief inertia as the dominant factor and the reported gains prove robust, this work offers a concrete, mechanism-level intervention for improving reliability in embodied agents beyond passive prompting or fine-tuning. The unified design applicable to multiple agent paradigms and the public code release are clear strengths that support reproducibility and extension. It contributes to the growing literature on failure modes in LLM agents by shifting from passive understanding to active belief management.
major comments (2)
- [Formal probing analysis and §4 (EVU mechanism)] The formal probing analysis (described in the method and analysis sections) characterizes belief inertia but provides no ablations, controls, or quantitative decomposition that rules out confounds such as planning errors or perception noise as primary drivers of suboptimal actions. Without such evidence, the diagnosis that belief inertia is the load-bearing cause—and thus that EVU is a targeted rather than general intervention—remains unestablished, directly affecting the justification for the proposed mechanism.
- [Experiments section and analysis] The experimental results claim 'substantial gains' across three benchmarks, yet the manuscript does not report effect sizes relative to strong baselines, error bars, or statistical significance tests that would confirm the improvements are attributable to belief-inertia mitigation rather than incidental reasoning boosts. This weakens the central empirical claim.
minor comments (2)
- [Abstract and Introduction] The abstract and introduction introduce 'belief inertia' and 'EVU' without referencing prior literature on belief updating or confirmation bias in agents; adding 2-3 targeted citations would strengthen the positioning.
- [§4 (EVU mechanism)] Notation for the textual belief states generated by EVU is introduced informally; a clear definition or pseudocode box would improve clarity for readers implementing the method.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, outlining specific revisions that will strengthen the manuscript's claims about the role of belief inertia and the benefits of the EVU mechanism.
read point-by-point responses
-
Referee: [Formal probing analysis and §4 (EVU mechanism)] The formal probing analysis (described in the method and analysis sections) characterizes belief inertia but provides no ablations, controls, or quantitative decomposition that rules out confounds such as planning errors or perception noise as primary drivers of suboptimal actions. Without such evidence, the diagnosis that belief inertia is the load-bearing cause—and thus that EVU is a targeted rather than general intervention—remains unestablished, directly affecting the justification for the proposed mechanism.
Authors: We acknowledge the value of additional controls to more rigorously isolate belief inertia. Our probing analysis manipulates belief states while attempting to hold planning and perception fixed, but we agree this does not fully decompose contributions from other factors. In the revised manuscript, we will add new ablation experiments that independently inject controlled planning errors and perception noise, then quantify their relative impact on suboptimal actions compared to belief inertia. This quantitative decomposition will better establish belief inertia as a primary driver and justify EVU as a targeted intervention. revision: yes
-
Referee: [Experiments section and analysis] The experimental results claim 'substantial gains' across three benchmarks, yet the manuscript does not report effect sizes relative to strong baselines, error bars, or statistical significance tests that would confirm the improvements are attributable to belief-inertia mitigation rather than incidental reasoning boosts. This weakens the central empirical claim.
Authors: We agree that effect sizes, error bars, and statistical tests are necessary to substantiate the empirical claims. The revised manuscript will include these: standardized effect sizes (Cohen's d) relative to baselines, error bars showing standard deviation across multiple random seeds, and statistical significance via paired t-tests (with p-values) to demonstrate that gains are significant and attributable to belief-inertia mitigation by EVU rather than general reasoning improvements. revision: yes
Circularity Check
No significant circularity; EVU is an additive empirical intervention
full rationale
The paper defines belief inertia via a formal probing analysis on agent behavior, then proposes the Estimate-Verify-Update (EVU) mechanism as a new textual intervention that can be plugged into prompting or training pipelines. No equations, parameter fits, or self-referential derivations appear; task-success gains are reported from experiments on three external benchmarks rather than from any quantity that reduces to the input metrics by construction. The central claims rest on empirical measurement and do not invoke self-citation chains or uniqueness theorems that would collapse the argument.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based agents can produce and maintain explicit textual representations of their internal beliefs.
invented entities (2)
-
belief inertia
no independent evidence
-
Estimate-Verify-Update (EVU) mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978. Pascale Fung, Yoram Bachrach, Asli Celikyilmaz, Kamalika Chaudhuri, Delong Chen, Willy Chung, Emmanuel Dupoux, Hongyu Gong, Hervé Jégou, Alessandro Lazaric, and 1 others. 2025. Embod- ied ai agents: Modeling the world.arXiv preprint arXiv:2506.22355. Wenlong Huang, ...
work page internal anchor Pith review arXiv 2025
-
[2]
arXiv preprint arXiv:2509.15061 , year=
Ask-to-clarify: Resolving instruction ambi- guity through multi-turn dialogue.arXiv preprint arXiv:2509.15061. Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingx- uan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, and 1 others. 2025. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556. We...
-
[3]
InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8494–8502
Virtualhome: Simulating household activities via programs. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8494–8502. Shuofei Qiao, Runnan Fang, Ningyu Zhang, Yuqi Zhu, Xiang Chen, Shumin Deng, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen. 2024. Agent planning with world knowledge model.Advances in Neural Info...
-
[4]
Embodied-reasoner: Synergizing visual search, reasoning, and action for embodied interactive tasks
Tree of thoughts: Deliberate problem solving with large language models.Advances in neural information processing systems, 36:11809–11822. Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning repres...
-
[5]
Belief Generation:The agent first generates a belief state content B based on a specific intervention strategyS
-
[6]
Put the apple in the fridge
Action Generation:The agent then generates the thought and action At conditioned on both the context and the generated belief. Formally, this process can be represented as: Ct StrategyS − − − − − → Bt − →At (9) where Bt varies depending on the definition of the strategyS. F.2 Strategy Instantiations Below, we detail the five strategies compared in the mai...
2025
-
[9]
task (obj) from (recep)
-
[10]
put (obj) in/on (recep)
-
[11]
toggle (obj) (recep)
-
[12]
clean (obj) with (recep)
-
[13]
heat (obj) with (recep)
-
[14]
Nothing happened
cool (obj) with (recep) where (obj) and (recep) correspond to objects and receptacles. After your each turn, the environment will give you immediate feedback based on which you plan your next few steps. If the environment output “Nothing happened”, that means the previous action is invalid and you should try more options. Your response should use the foll...
-
[16]
Do NOT list irrelevant objects
Belief State: State where the agent is, what it is holding, and the known status of goal-related objects. Do NOT list irrelevant objects. 3.Thought: Plan your future actions based on the updated belief. 4.Action: Output your next action. The available actions are:
-
[17]
put (obj) on (recep)
-
[18]
put (obj) in (recep)
-
[19]
pour (obj) into (recep)
-
[20]
Nothing happened
turn to (obj) After your each turn, the environment will give you immediate feedback based on which you plan your next few steps. If the environment output “Nothing happened”, that means the previous action is invalid and you should try more options. Your response should use the following format: Reason: <Analyze expectation vs. actual observation to upda...
-
[21]
What did you expect to see? What did you actually see? Does this confirm or contradict your previous belief?
Reason: Analyze the last action and the observation in one or two concise sentences. What did you expect to see? What did you actually see? Does this confirm or contradict your previous belief?
-
[22]
Do NOT list irrelevant objects
Belief State: State where the agent is, what it is holding, and the known status of goal-related objects. Do NOT list irrelevant objects. 3.Thought: Plan your future actions based on the updated belief. 4.Action: Output your next action. The available actions are: •open OBJ: open a container •close OBJ: close a container •activate OBJ: activate a device •...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.