Recognition: unknown
Toward Reusability of AI Models Using Dynamic Updates of AI Documentation
Pith reviewed 2026-05-10 05:29 UTC · model grok-4.3
The pith
AI model documentation aligned with community templates from Hugging Face correlates with higher reuse via downloads and likes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
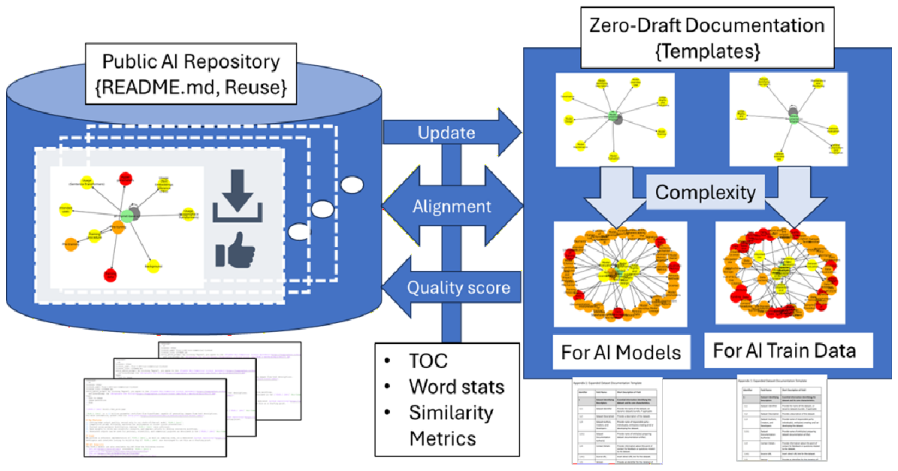
The central claim is that correlations exist between AI model reuse metrics such as downloads and likes from the Hugging Face repository and the alignment of their documentation with Zero Draft templates, as quantified using tables of contents and word statistics. The paper further establishes an infrastructure for regularly comparing AI documentation templates against community-standard practices derived from millions of uploaded models, thereby enabling agile, data-driven updates that reduce the temporal lag in documentation requirements and improve overall model reusability.
What carries the argument
Alignment scoring of model cards against Zero Draft templates via tables of contents and word statistics, paired with the infrastructure for periodic extraction of community practices from the Hugging Face repository to drive template updates.
If this is right
- Models whose documentation aligns more closely with current community-derived templates will exhibit increased downloads and likes.
- Documentation templates can be refreshed on a regular schedule by automatically comparing against patterns observed in millions of Hugging Face uploads.
- The lag between new AI best practices and their reflection in model cards will shorten through this data-driven process.
- Reusable AI models become the norm when documentation standards evolve directly from observed community usage rather than static expert templates.
Where Pith is reading between the lines
- Platforms could embed this alignment scoring directly into upload workflows to nudge developers toward higher-reuse documentation.
- The same extraction and comparison approach could extend to other AI model repositories or even software artifact sharing sites beyond Hugging Face.
- Over repeated update cycles, the resulting templates would reflect not just current but emerging practices as new model types appear in large numbers.
- Developers seeking greater visibility for their models might treat documentation quality as a measurable performance factor alongside accuracy.
Load-bearing premise
That tables of contents and word statistics provide a valid proxy for documentation quality whose alignment with community templates actually improves model reuse rather than merely correlating with other factors.
What would settle it
Finding no meaningful difference in download or like counts between models whose documentation scores high versus low on alignment with the Zero Draft templates would falsify the claimed link to reusability.
Figures















read the original abstract
This work addresses the challenge of disseminating reusable artificial intelligence (AI) models accompanied by AI documentation (a.k.a., AI model cards). The work is motivated by the large number of trained AI models that are not reusable due to the lack of (a) AI documentation and (b) the temporal lag between rapidly changing requirements on AI model reusability and those specified in various AI model cards. Our objectives are to shorten the lag time in updating AI model card templates and align AI documentation more closely with current AI best practices. Our approach introduces a methodology for delivering agile, data-driven, and community-based AI model cards. We use the Hugging Face (HF) repository of AI models, populated by a subset of the AI research and development community, and the AI consortium-based Zero Draft (ZD) templates for the AI documentation of AI datasets and AI models, as our test datasets. We also address questions about the value of AI documentation for AI reusability. Our work quantifies the correlations between AI model downloads/likes (i.e., AI model reuse metrics) from the HF repository and their documentation alignment with the ZD documentation templates using tables of contents and word statistics (i.e., AI documentation quality metrics). Furthermore, our work develops the infrastructure to regularly compare AI documentation templates against community-standard practices derived from millions of uploaded AI models in the Hugging Face repository. The impact of our work lies in introducing a methodology for delivering agile, data-driven, and community-based standards for documenting AI models and improving AI model reuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a data-driven methodology for dynamically updating AI model documentation (model cards) using the Hugging Face repository to align templates with community practices. It quantifies correlations between reuse metrics (downloads and likes) and documentation quality metrics (tables-of-contents alignment and word statistics with Zero Draft templates), and develops infrastructure for ongoing template comparisons against millions of uploaded models. The central objectives are to reduce lag in documentation updates and improve model reusability.
Significance. If the empirical correlations prove robust after proper validation and controls, the work could offer a practical infrastructure for community-driven, agile AI documentation standards that keep pace with evolving reusability requirements. The infrastructure component for regular comparisons represents a constructive engineering contribution. However, the current presentation provides insufficient methodological detail to evaluate whether the claimed benefits to reusability are supported.
major comments (3)
- [Abstract] Abstract and Approach sections: the quantification of correlations between downloads/likes and ToC/word-statistic alignment is asserted without any description of the underlying statistical procedures, sample sizes, selection criteria for the HF models analyzed, or controls for confounders such as model age, parameter count, task category, or uploader reputation.
- [Approach] Approach and Impact sections: tables of contents and word statistics are used as proxies for documentation quality and alignment with ZD templates, yet no human validation, inter-rater reliability assessment, or comparison against established documentation quality metrics is reported, leaving the validity of these surface metrics unestablished.
- [Impact] Impact statement: the claim that dynamic ZD updates will improve reusability is supported only by raw correlations; no before/after analysis of documentation changes, regression models with controls, or causal identification strategy is described, so the evidence cannot distinguish correlation from the asserted causal benefit.
minor comments (1)
- [Abstract] The abstract would be clearer if it explicitly stated the number of models examined and the precise definition of 'alignment' used in the correlation analysis.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, indicating where we will revise the manuscript to improve clarity, detail, and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract and Approach sections: the quantification of correlations between downloads/likes and ToC/word-statistic alignment is asserted without any description of the underlying statistical procedures, sample sizes, selection criteria for the HF models analyzed, or controls for confounders such as model age, parameter count, task category, or uploader reputation.
Authors: We appreciate the referee highlighting the need for greater methodological transparency. The Approach section does describe the overall correlation analysis between reuse metrics (downloads and likes) and documentation alignment metrics (ToC and word statistics), but we agree that explicit details on the statistical procedures, exact sample sizes, selection criteria applied to the Hugging Face models, and discussion of potential confounders are currently insufficient. In the revised manuscript we will expand the Approach section to specify the correlation methods used, report the precise sample size and filtering criteria, and include an explicit discussion of confounders along with any controls that can be applied from available metadata. revision: yes
-
Referee: [Approach] Approach and Impact sections: tables of contents and word statistics are used as proxies for documentation quality and alignment with ZD templates, yet no human validation, inter-rater reliability assessment, or comparison against established documentation quality metrics is reported, leaving the validity of these surface metrics unestablished.
Authors: We acknowledge that the validity of these scalable proxy metrics would be strengthened by validation against human judgments. The metrics were deliberately chosen for their ability to be computed automatically across millions of models, which is central to the proposed dynamic-update infrastructure. We will revise the Approach section to provide a fuller justification for these proxies, reference related literature on documentation quality assessment, and add a limitations subsection. We will also include a small-scale human evaluation on a sampled subset of models to report initial alignment between the automated metrics and human assessments of documentation quality. revision: partial
-
Referee: [Impact] Impact statement: the claim that dynamic ZD updates will improve reusability is supported only by raw correlations; no before/after analysis of documentation changes, regression models with controls, or causal identification strategy is described, so the evidence cannot distinguish correlation from the asserted causal benefit.
Authors: We agree that the presented evidence consists of observed correlations rather than causal identification. The manuscript positions the correlations as motivation for the proposed methodology and infrastructure rather than as proof of causal improvement in reusability. We will revise the Impact section to more precisely state that the associations suggest value in dynamic, community-driven updates while explicitly noting the correlational nature of the evidence and the absence of before/after or controlled analyses. We will also outline how the developed infrastructure could support such studies in future work. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper reports direct empirical correlations computed from the external Hugging Face repository (downloads/likes as reuse metrics) against alignment measures (tables of contents and word statistics) with separately defined ZD templates. No equations, fitted parameters, or predictions are described that reduce by construction to the same inputs. Community standards are extracted from HF data and applied outward to evaluate ZD alignment; this is a one-way data-driven comparison without self-definitional loops, self-citation load-bearing premises, or renamed known results. The methodology is self-contained against the stated external benchmarks and does not invoke uniqueness theorems or ansatzes from the authors' prior work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption AI documentation quality can be measured using tables of contents and word statistics
- domain assumption The Hugging Face repository represents community-standard practices for AI models
Reference graph
Works this paper leans on
-
[1]
Artificial intelligence index report 2025,
Y. Gil and R. Perrault, “Artificial intelligence index report 2025,” Tech. Rep., 2025. [Online]. Available: https://hai.stanford.edu/assets/files/hai ai index report 2025.pdf
2025
-
[2]
Shaping the future of learning: Ai in higher education,
T. Brodheim, “Shaping the future of learning: Ai in higher education,” May 2025. [Online]. Available: https://er.educause.edu/articles/sponsored/2025/5/ shaping-the-future-of-learning-ai-in-higher-education
2025
-
[3]
[Online]
Open Neural Network Exchange, “Onnx,” 2019. [Online]. Available: https://onnx.ai/
2019
-
[4]
Artificial intelligence-enabled medical devices,
FDA, “Artificial intelligence-enabled medical devices,” 2025. [On- line]. Available: https://www.fda.gov/medical-devices/software-medical-device-samd/ artificial-intelligence-enabled-medical-devices
2025
-
[5]
Ai model repository,
Hugging Face Team, “Ai model repository,” 2026. [Online]. Available: https://huggingface. co/models
2026
-
[6]
Extended outline: Proposed zero draft for a stan- dard on documentation of ai datasets and ai models,
NIST AI Consortium, “Extended outline: Proposed zero draft for a stan- dard on documentation of ai datasets and ai models,” Tech. Rep., Septem- ber 2025. [Online]. Available: https://www.nist.gov/artificial-intelligence/ai-research/ nists-ai-standards-zero-drafts-pilot-project-accelerate
2025
-
[7]
doi:10.48550/arXiv.1803.09010 arXiv:1803.09010 [cs]
T. Gebru, J. Morgenstern, B. Vecchione, J. W. Vaughan, H. Wallach, H. D. III, and K. Craw- ford, “Datasheets for datasets,”arXiv preprint arXiv:1803.09010, 2021
-
[8]
S. Holland, A. Hosny, S. Newman, J. Joseph, and K. Chmielinski, “The dataset nutrition label: A framework to drive higher data quality standards,”arXiv preprint arXiv:1805.03677, 2018
-
[9]
Model cards for model reporting,
M. Mitchellet al., “Model cards for model reporting,” inProceedings of the Conference on Fairness, Accountability, and Transparency, January 2019
2019
-
[10]
Model garden on vertex ai: curated set of 200+ available models,
Google Team, “Model garden on vertex ai: curated set of 200+ available models,” 2026. [Online]. Available: https://cloud.google.com/model-garden
2026
-
[11]
Llama models,
Facebook Team, “Llama models,” 2026. [Online]. Available: https://ai.meta.com/resources/ models-and-libraries/
2026
-
[12]
Model cards,
Hugging Face Team, “Model cards,” 2026. [Online]. Available: https://huggingface.co/docs/ hub/en/model-cards
2026
-
[13]
Kaggle models,
Kaggle Team, “Kaggle models,” 2026. [Online]. Available: https://www.kaggle.com/models 18 Figure 8: Number of downloads for the AI models in HF Subset 1
2026
-
[14]
Characterization of ai model configurations for model reuse,
P. Bajcsy, M. Majurski, T. E. C. IV, M. Carrasco, and W. Keyrouz, “Characterization of ai model configurations for model reuse,” inComputer Vision – ECCV 2022 Workshops. Springer-Verlag, 2022, pp. 454–469
2022
-
[15]
Natural language toolkit (nltk),
NLTK Team, “Natural language toolkit (nltk),” 2026. [Online]. Available: https: //www.nltk.org/
2026
-
[16]
200 words that containing most letter x,
Word Lucky, “200 words that containing most letter x,” 2026. [Online]. Available: https://www.wordlucky.com/words-with-most/x?
2026
-
[17]
Chapter two - quality assessment for big mobility data,
Y. Yao and H. Zhang, “Chapter two - quality assessment for big mobility data,” inHandbook of Mobility Data Mining. Elsevier, 2023, pp. 15–34
2023
-
[18]
A novel approach for the structural comparison of origin-destination matrices: Levenshtein distance,
K. N. Behara, A. Bhaskar, and E. Chung, “A novel approach for the structural comparison of origin-destination matrices: Levenshtein distance,”Transportation Research Part C: Emerging Technologies, vol. 111, pp. 513–530, 2020. A Datasets Figure 8 shows the number of downloads in HF Subset 1. This subset is created by sorting all AI models by the number of ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.