Recognition: unknown
HEALing Entropy Collapse: Enhancing Exploration in Few-Shot RLVR via Hybrid-Domain Entropy Dynamics Alignment
Pith reviewed 2026-05-10 05:18 UTC · model grok-4.3
The pith
Hybrid-domain entropy alignment enables few-shot RLVR to match or surpass full-shot performance with only 32 target samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
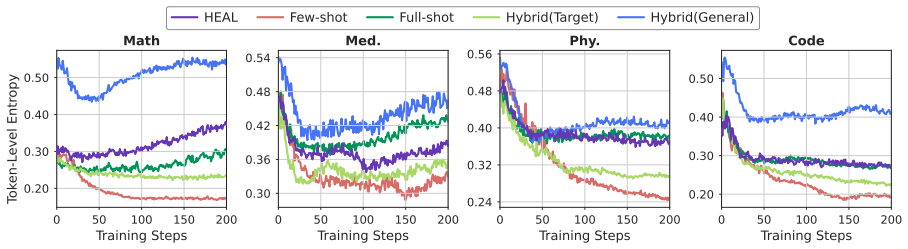
By selectively incorporating high-value general-domain data and aligning trajectory-level entropy dynamics between target and general domains via the Entropy Dynamics Alignment reward, HEAL mitigates entropy collapse in few-shot RLVR and transfers diverse exploration behaviors, achieving performance that matches or exceeds full-shot RLVR trained with 1K target-domain samples using only 32 samples.
What carries the argument
Entropy Dynamics Alignment (EDA), a reward mechanism that aligns both entropy magnitude and fine-grained variation across hybrid domains to encourage beneficial exploration.
Load-bearing premise
That selectively incorporating general-domain data and aligning entropy dynamics will transfer useful exploration without causing harmful biases or domain mismatch.
What would settle it
Training HEAL on a target domain where selected general data has mismatched entropy patterns and observing no improvement or degradation compared to standard few-shot RLVR.
Figures








read the original abstract
Reinforcement Learning with Verifiable Reward (RLVR) has proven effective for training reasoning-oriented large language models, but existing methods largely assume high-resource settings with abundant training data. In low-resource scenarios, RLVR is prone to more severe entropy collapse, which substantially limits exploration and degrades reasoning performance. To address this issue, we propose Hybrid-domain Entropy dynamics ALignment (HEAL), a framework tailored for few-shot RLVR. HEAL first selectively incorporates high-value general-domain data to promote more diverse exploration. Then, we introduce Entropy Dynamics Alignment (EDA), a reward mechanism that aligns trajectory-level entropy dynamics between the target and general domains, capturing both entropy magnitude and fine-grained variation. Through this alignment, EDA not only further mitigates entropy collapse but also encourages the policy to acquire more diverse exploration behaviors from the general domain. Experiments across multiple domains show that HEAL consistently improves few-shot RLVR performance. Notably, using only 32 target-domain samples, HEAL matches or even surpasses full-shot RLVR trained with 1K target-domain samples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HEAL, a hybrid-domain framework for few-shot Reinforcement Learning with Verifiable Reward (RLVR) in large language models. It selectively incorporates high-value general-domain data to promote exploration and introduces Entropy Dynamics Alignment (EDA), a reward mechanism that aligns trajectory-level entropy magnitude and fine-grained variation between target and general domains. The central claim is that this mitigates entropy collapse more effectively than standard few-shot RLVR, with experiments showing consistent gains across domains; notably, 32 target-domain samples with HEAL match or surpass full-shot RLVR trained on 1K target samples.
Significance. If the empirical equivalence between 32-shot HEAL and 1K-shot RLVR holds under rigorous controls, the work would be significant for low-resource RLVR settings, where data scarcity exacerbates entropy collapse and limits reasoning performance in LLMs. The hybrid-domain strategy and explicit focus on entropy dynamics provide a concrete mechanism for transferring exploration behaviors, potentially reducing reliance on large target-domain datasets while addressing a known failure mode in RL for reasoning models.
major comments (2)
- [Abstract] Abstract: The strongest claim—that HEAL with only 32 target samples matches or surpasses full-shot RLVR with 1K samples—is presented without any reference to baseline implementations, statistical significance tests, ablation results, or domain-similarity metrics. This absence is load-bearing, as the claim hinges on successful transfer without negative effects from general-domain data.
- [Abstract] Abstract: The EDA reward mechanism is described only at a high level ('aligns trajectory-level entropy dynamics... capturing both entropy magnitude and fine-grained variation') with no equations, loss formulation, or pseudocode. Without the precise definition, it is impossible to evaluate whether the alignment is causal for the reported gains or whether it risks pulling the policy toward incompatible general-domain modes.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for acknowledging the potential significance of HEAL in low-resource RLVR settings. We address each major comment point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The strongest claim—that HEAL with only 32 target samples matches or surpasses full-shot RLVR with 1K samples—is presented without any reference to baseline implementations, statistical significance tests, ablation results, or domain-similarity metrics. This absence is load-bearing, as the claim hinges on successful transfer without negative effects from general-domain data.
Authors: The abstract is intentionally concise and summarizes the primary result. The full manuscript details the baseline implementations and training protocols in Section 4.1, reports statistical significance testing (including p-values from paired t-tests) and ablation studies in Section 5, and provides domain-similarity metrics together with the selective data incorporation procedure in Section 4.2 to substantiate the absence of negative transfer. We agree that a brief pointer in the abstract would improve self-containment and will therefore revise the abstract to reference these supporting analyses. revision: partial
-
Referee: [Abstract] Abstract: The EDA reward mechanism is described only at a high level ('aligns trajectory-level entropy dynamics... capturing both entropy magnitude and fine-grained variation') with no equations, loss formulation, or pseudocode. Without the precise definition, it is impossible to evaluate whether the alignment is causal for the reported gains or whether it risks pulling the policy toward incompatible general-domain modes.
Authors: Abstracts conventionally omit equations and pseudocode for readability. The complete mathematical definition of EDA—including the trajectory-level entropy magnitude and variation alignment terms, the resulting reward formulation, the combined loss, and the alignment algorithm pseudocode—is provided in Section 3.2. We will revise the abstract to include a parenthetical reference directing readers to this formal specification. revision: yes
Circularity Check
No significant circularity in HEAL framework
full rationale
The paper presents HEAL as an empirical intervention for few-shot RLVR: selective incorporation of high-value general-domain data followed by a new reward mechanism (EDA) that aligns trajectory-level entropy magnitude and variation. No derivation chain, first-principles result, or prediction is claimed that reduces by construction to fitted inputs, self-definitions, or self-citations. Performance statements (e.g., 32-sample equivalence to 1K full-shot) are experimental outcomes, not tautological. The method is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption High-value general-domain data promotes more diverse exploration when selectively added to few-shot target data
- domain assumption Aligning trajectory-level entropy magnitude and variation transfers useful exploration behaviors across domains
invented entities (1)
-
Entropy Dynamics Alignment (EDA) reward mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
AMC Problems and Solutions , author =
-
[3]
Benchmarking Large Language Models on Answering and Explaining Challenging Medical Questions
Chen, Hanjie and Fang, Zhouxiang and Singla, Yash and Dredze, Mark. Benchmarking Large Language Models on Answering and Explaining Challenging Medical Questions. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2025
2025
-
[4]
Analogical problem solving , journal =. 1980 , issn =. doi:https://doi.org/10.1016/0010-0285(80)90013-4 , url =
-
[5]
Seed-grpo: Semantic entropy enhanced grpo for uncertainty-aware policy optimization , author=. arXiv preprint arXiv:2505.12346 , year=
-
[6]
Quantile advantage estimation for entropy-safe reasoning.arXiv preprint arXiv:2509.22611, 2025
Quantile Advantage Estimation for Entropy-Safe Reasoning , author=. arXiv preprint arXiv:2509.22611 , year=
-
[7]
Reasoning with exploration: An entropy perspective.arXiv preprint arXiv:2506.14758, 2025
Reasoning with exploration: An entropy perspective , author=. arXiv preprint arXiv:2506.14758 , year=
-
[8]
Group Sequence Policy Optimization
Group sequence policy optimization , author=. arXiv preprint arXiv:2507.18071 , year=
work page internal anchor Pith review arXiv
-
[9]
Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models , author=. arXiv preprint arXiv:2505.24864 , year=
-
[10]
One- shot entropy minimization,
One-shot entropy minimization , author=. arXiv preprint arXiv:2505.20282 , year=
-
[11]
The unreasonable effectiveness of entropy minimization in llm reasoning , author=. arXiv preprint arXiv:2505.15134 , year=
-
[12]
Advances in Neural Information Processing Systems , volume=
Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Advances in Neural Information Processing Systems , year=
Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models , author=. Advances in Neural Information Processing Systems , year=
-
[14]
arXiv preprint arXiv:2507.04766 , year=
Abench-physics: Benchmarking physical reasoning in llms via high-difficulty and dynamic physics problems , author=. arXiv preprint arXiv:2507.04766 , year=
-
[15]
arXiv preprint arXiv:2504.13950 , year=
Open-Medical-R1: How to Choose Data for RLVR Training at Medicine Domain , author=. arXiv preprint arXiv:2504.13950 , year=
-
[16]
Med-rlvr: Emerging medical reasoning from a 3b base model via reinforcement learning , author=. arXiv preprint arXiv:2502.19655 , year=
-
[17]
Process Reinforcement through Implicit Rewards
Process reinforcement through implicit rewards , author=. arXiv preprint arXiv:2502.01456 , year=
work page internal anchor Pith review arXiv
-
[18]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
2024 , url =
OpenAI , title =. 2024 , url =
2024
-
[20]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
work page internal anchor Pith review arXiv
-
[21]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review arXiv
-
[22]
Differential Smoothing Mitigates Sharpening and Improves LLM Reasoning , author=. arXiv preprint arXiv:2511.19942 , year=
-
[23]
Reasoning with sampling: Your base model is smarter than you think.arXiv preprint arXiv:2510.14901,
Reasoning with sampling: Your base model is smarter than you think , author=. arXiv preprint arXiv:2510.14901 , year=
-
[24]
Language models are injective and hence invertible.arXiv preprint arXiv:2510.15511, 2025
Language models are injective and hence invertible , author=. arXiv preprint arXiv:2510.15511 , year=
-
[25]
Jyothish Pari, Han Guo, Ekin Aky
Zweiger, Adam , journal=. Jyothish Pari, Han Guo, Ekin Aky
-
[26]
Agent learning via early experience.arXiv preprint arXiv:2510.08558, 2025
Agent learning via early experience , author=. arXiv preprint arXiv:2510.08558 , year=
-
[28]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Se-agent: Self-evolution trajectory optimization in multi-step reasoning with llm-based agents , author=. arXiv preprint arXiv:2508.02085 , year=
-
[30]
Native sparse attention: Hardware-aligned and natively trainable sparse attention, 2025 , author=
2025
-
[31]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Language models resist alignment: Evidence from data compression , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[32]
Findings of the Association for Computational Linguistics: ACL 2026 , year =
Orchestrating Tokens and Sequences: Dynamic Hybrid Policy Optimization for RLVR , author =. Findings of the Association for Computational Linguistics: ACL 2026 , year =
2026
-
[33]
SPEC-RL: Accelerating On-Policy Reinforcement Learning with Speculative Rollouts , author=. arXiv preprint arXiv:2509.23232 , year=
-
[34]
Confidence Is All You Need: Few-Shot RL Fine-Tuning of Language Models , author=. arXiv preprint arXiv:2506.06395 , year=
-
[35]
arXiv preprint arXiv:2506.03295 , year=
Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem , author=. arXiv preprint arXiv:2506.03295 , year=
-
[36]
Protoreasoning: Prototypes as the foundation for generalizable reasoning in llms
ProtoReasoning: Prototypes as the Foundation for Generalizable Reasoning in LLMs , author=. arXiv preprint arXiv:2506.15211 , year=
-
[37]
General- reasoner: Advancing llm reasoning across all domains.arXiv preprint arXiv:2505.14652,
General-reasoner: Advancing llm reasoning across all domains , author=. arXiv preprint arXiv:2505.14652 , year=
-
[38]
DuPO: Enabling Reliable LLM Self-Verification via Dual Preference Optimization , author=. arXiv preprint arXiv:2508.14460 , year=
-
[39]
arXiv preprint arXiv:2506.08011 , year=
Play to Generalize: Learning to Reason Through Game Play , author=. arXiv preprint arXiv:2506.08011 , year=
-
[40]
Beyond pass@ 1: Self-play with variational problem synthesis sustains rlvr , author=. arXiv preprint arXiv:2508.14029 , year=
-
[41]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
The entropy mechanism of reinforcement learning for reasoning language models , author=. arXiv preprint arXiv:2505.22617 , year=
work page internal anchor Pith review arXiv
-
[43]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
R-zero: Self-evolving reasoning llm from zero data , author=. arXiv preprint arXiv:2508.05004 , year=
work page internal anchor Pith review arXiv
-
[44]
arXiv preprint arXiv:2502.03387 , year=
Limo: Less is more for reasoning , author=. arXiv preprint arXiv:2502.03387 , year=
-
[45]
Reasoning or memorization? unreliable results of reinforcement learning due to data contamination , author=. arXiv preprint arXiv:2507.10532 , year=
-
[46]
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning , author=. arXiv preprint arXiv:2507.00432 , year=
-
[47]
Rlpr: Extrapolating rlvr to general domains without verifiers, 2025
RLPR: Extrapolating RLVR to General Domains without Verifiers , author=. arXiv preprint arXiv:2506.18254 , year=
-
[48]
Synlogic: Synthesizing verifiable reasoning data at scale for learning logical reasoning and beyond
SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond , author=. arXiv preprint arXiv:2505.19641 , year=
-
[49]
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. arXiv preprint arXiv:2506.01939 , year=
work page internal anchor Pith review arXiv
-
[50]
The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity , author=. arXiv preprint arXiv:2506.06941 , year=
-
[51]
Improving Data Efficiency for LLM Reinforcement Fine-tuning Through Difficulty-targeted Online Data Selection and Rollout Replay , author=. arXiv preprint arXiv:2506.05316 , year=
-
[52]
Spurious rewards: Rethinking training signals in RLVR.arXiv preprint arXiv:2506.10947,
Spurious rewards: Rethinking training signals in rlvr , author=. arXiv preprint arXiv:2506.10947 , year=
-
[53]
Learning to reason without external rewards.arXiv preprint arXiv:2505.19590, 2025
Learning to reason without external rewards , author=. arXiv preprint arXiv:2505.19590 , year=
-
[54]
Reinforcement learning finetunes small subnetworks in large language models, 2025
Reinforcement Learning Finetunes Small Subnetworks in Large Language Models , author=. arXiv preprint arXiv:2505.11711 , year=
-
[55]
arXiv preprint arXiv:2504.13592 , year=
Improving Generalization in Intent Detection: GRPO with Reward-Based Curriculum Sampling , author=. arXiv preprint arXiv:2504.13592 , year=
-
[56]
arXiv preprint arXiv:2505.07215 , year=
Measuring General Intelligence with Generated Games , author=. arXiv preprint arXiv:2505.07215 , year=
-
[57]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Absolute zero: Reinforced self-play reasoning with zero data , author=. arXiv preprint arXiv:2505.03335 , year=
work page internal anchor Pith review arXiv
-
[58]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[59]
Reinforcement learning for reasoning in large language models with one training example, 2025
Reinforcement learning for reasoning in large language models with one training example , author=. arXiv preprint arXiv:2504.20571 , year=
-
[60]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? , author=. arXiv preprint arXiv:2504.13837 , year=
-
[61]
VAPO: Efficient and Reliable Reinforcement Learning for Advanced Reasoning Tasks
Vapo: Efficient and reliable reinforcement learning for advanced reasoning tasks , author=. arXiv preprint arXiv:2504.05118 , year=
work page internal anchor Pith review arXiv
-
[62]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale, 2025 , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild , author=. arXiv preprint arXiv:2503.18892 , year=
work page internal anchor Pith review arXiv
-
[64]
arXiv , author=
DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv , author=. Preprint posted online on , volume=
-
[65]
2025 , journal=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , journal=
2025
-
[66]
0: Efficiently improving mathematical reasoning by training small data synthesis models , author=
Jiuzhang3. 0: Efficiently improving mathematical reasoning by training small data synthesis models , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
0: Efficiently improving mathematical reasoning by training small data synthesis models , author=
Jiuzhang3. 0: Efficiently improving mathematical reasoning by training small data synthesis models , author=. Advances in Neural Information Processing Systems , year=
-
[68]
Towards system 2 reasoning in llms: Learning how to think with meta chain-of-though,
Towards system 2 reasoning in llms: Learning how to think with meta chain-of-thought , author=. arXiv preprint arXiv:2501.04682 , year=
-
[69]
arXiv e-prints , pages=
The llama 3 herd of models , author=. arXiv e-prints , pages=
-
[70]
2024 , journal=
The Llama 3 Herd of Models , author=. 2024 , journal=
2024
-
[71]
2024 , journal =
Naman Jain and King Han and Alex Gu and Wen-Ding Li and Fanjia Yan and Tianjun Zhang and Sida Wang and Armando Solar-Lezama and Koushik Sen and Ion Stoica , title =. 2024 , journal =
2024
-
[72]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding , author=. arXiv preprint arXiv:2501.18362 , year=
-
[73]
2025 , url=
Xueguang Ma and Qian Liu and Dongfu Jiang and Ge Zhang and Zejun MA and Wenhu Chen , booktitle=. 2025 , url=
2025
-
[74]
Xueguang Ma and Qian Liu and Dongfu Jiang and Ge Zhang and Zejun MA and Wenhu Chen , journal=
-
[75]
Advances in Neural Information Processing Systems , year=
C-Eval: A Multi-Level Multi-Discipline Chinese Evaluation Suite for Foundation Models , author=. Advances in Neural Information Processing Systems , year=
-
[76]
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan. C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/...
-
[77]
C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge
Talmor, Alon and Herzig, Jonathan and Lourie, Nicholas and Berant, Jonathan. C ommonsense QA : A Question Answering Challenge Targeting Commonsense Knowledge. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019
2019
-
[78]
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review arXiv
-
[79]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Is Your Code Generated by Chat
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , journal =. Is Your Code Generated by Chat
-
[81]
Is Your Code Generated by Chat
Liu, Jiawei and Xia, Chunqiu Steven and Wang, Yuyao and Zhang, Lingming , booktitle =. Is Your Code Generated by Chat. 2023 , url =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.