Recognition: unknown
Test-Time Perturbation Learning with Delayed Feedback for Vision-Language-Action Models
Pith reviewed 2026-05-10 05:51 UTC · model grok-4.3
The pith
PDF improves Vision-Language-Action models at test time by using delayed feedback to adjust action predictions and reduce overfitting to spurious correlations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PDF is a verifier-free test-time adaptation framework that mitigates trajectory overfitting in frozen Vision-Language-Action models through uncertainty-based data augmentation combined with action voting and an adaptive budget scheduler, while a lightweight perturbation module retrospectively corrects action logits using delayed feedback signals to improve decision stability.
What carries the argument
The lightweight perturbation module that learns to adjust the base model's action logits retrospectively from delayed feedback.
If this is right
- Vision-Language-Action models reach higher task success without retraining the original weights.
- The same gains appear across both robotic manipulation and game-playing domains.
- An adaptive scheduler keeps the added computation from growing unbounded during long episodes.
- The approach works without a separate verifier or ground-truth labels at test time.
Where Pith is reading between the lines
- The delayed-feedback correction could be useful in real-world settings where action outcomes are observed only after a delay.
- Similar retrospective adjustment might help other sequence models that suffer from training-trajectory bias.
- Accurate uncertainty estimates are required for the augmentation step to target the right predictions.
Load-bearing premise
Trajectory overfitting to spurious action-entity correlations is the dominant source of fragility to environmental shifts, and uncertainty augmentation plus delayed-feedback correction can fix it without introducing new instabilities.
What would settle it
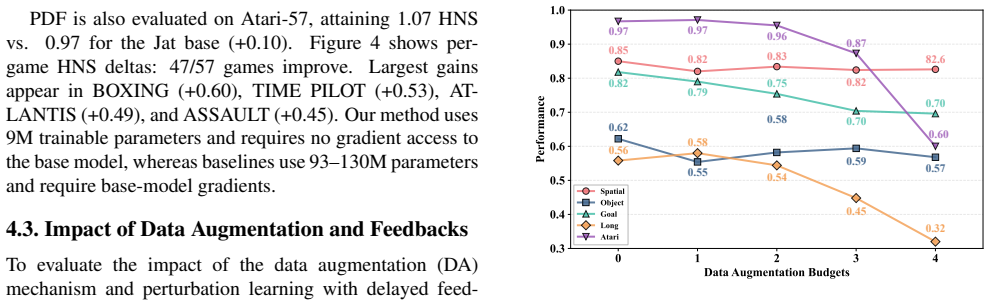
Running PDF on the LIBERO or Atari benchmarks and observing no gain or a drop in success rate relative to the vanilla Vision-Language-Action model on tasks that include small object-pose changes would falsify the claimed benefit.
Figures





read the original abstract
Vision-Language-Action models (VLAs) achieve remarkable performance in sequential decision-making but remain fragile to subtle environmental shifts, such as small changes in object pose. We attribute this brittleness to trajectory overfitting, where VLAs over-attend to the spurious correlation between actions and entities, then reproduce memorized action patterns. We propose Perturbation learning with Delayed Feedback (PDF), a verifier-free test-time adaptation framework that improves decision performance without fine-tuning the base model. PDF mitigates the spurious correlation through uncertainty-based data augmentation and action voting, while an adaptive scheduler allocates augmentation budgets to balance performance and efficiency. To further improve stability, PDF learns a lightweight perturbation module that retrospectively adjusts action logits guided by delayed feedback, correcting overconfidence issue. Experiments on LIBERO (+7.4\% success rate) and Atari (+10.3 human normalized score) demonstrate consistent gains of PDF in task success over vanilla VLA and VLA with test-time adaptation, establishing a practical path toward reliable test-time adaptation in multimodal decision-making agents. The code is available at \href{https://github.com/zhoujiahuan1991/CVPR2026-PDF}{https://github.com/zhoujiahuan1991/CVPR2026-PDF}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
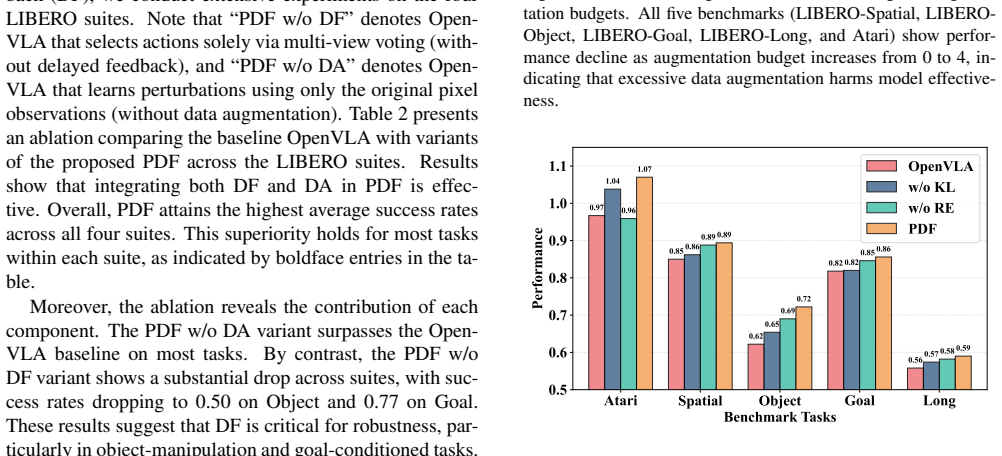
Summary. The paper proposes Perturbation learning with Delayed Feedback (PDF), a verifier-free test-time adaptation framework for Vision-Language-Action (VLA) models. It attributes model brittleness to trajectory overfitting that produces spurious correlations and overconfident actions. PDF combines uncertainty-based data augmentation with action voting, an adaptive scheduler to allocate augmentation budgets, and a lightweight perturbation module trained retrospectively on delayed feedback to adjust action logits. Experiments report gains of +7.4% success rate on LIBERO and +10.3 human-normalized score on Atari over vanilla VLA and other test-time adaptation baselines, with public code released.
Significance. If the empirical results hold under rigorous validation, the work provides a practical, training-free route to improving robustness of multimodal decision-making agents. The public code release is a clear strength that supports reproducibility and follow-on research in test-time adaptation.
major comments (3)
- [Experiments] Experiments section: the central performance claims (+7.4% success rate on LIBERO, +10.3 HNS on Atari) are reported without error bars, number of evaluation seeds, ablation tables, or statistical significance tests. This directly undermines assessment of whether the gains are reliable and load-bearing for the paper's empirical contribution.
- [Introduction and §3] Introduction and §3 (Method): the attribution of brittleness primarily to trajectory overfitting is presented as the motivating assumption, yet no direct evidence, diagnostic experiments, or comparison against alternative failure modes (e.g., visual encoder limitations or policy architecture) is provided to establish that this is the dominant factor.
- [§3.3] §3.3 (Perturbation module): the description of how delayed feedback is used to train the lightweight module and whether it requires ground-truth signals at test time is insufficient to verify the verifier-free claim and to confirm that the module does not introduce new instabilities.
minor comments (1)
- [Abstract] Abstract: the phrase 'correcting overconfidence issue' should read 'correcting the overconfidence issue' for grammatical consistency.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each of the major comments below and outline the revisions we plan to make.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central performance claims (+7.4% success rate on LIBERO, +10.3 HNS on Atari) are reported without error bars, number of evaluation seeds, ablation tables, or statistical significance tests. This directly undermines assessment of whether the gains are reliable and load-bearing for the paper's empirical contribution.
Authors: We agree that the absence of error bars, details on the number of evaluation seeds, ablation tables, and statistical significance tests weakens the empirical claims. In the revised manuscript, we will include results averaged over multiple random seeds (at least 5), report standard deviations as error bars, expand the ablation studies, and include statistical significance tests (e.g., paired t-tests) to demonstrate that the reported improvements are reliable. We will also make the evaluation protocol clearer. revision: yes
-
Referee: [Introduction and §3] Introduction and §3 (Method): the attribution of brittleness primarily to trajectory overfitting is presented as the motivating assumption, yet no direct evidence, diagnostic experiments, or comparison against alternative failure modes (e.g., visual encoder limitations or policy architecture) is provided to establish that this is the dominant factor.
Authors: The attribution to trajectory overfitting stems from our empirical observations that VLAs often replicate training trajectories under minor environmental changes, leading to spurious correlations. However, we acknowledge the lack of direct diagnostic evidence in the current manuscript. We will add diagnostic experiments in the revised version, including attention visualization, controlled perturbation tests, and comparisons to isolate trajectory overfitting from other potential issues such as visual encoder limitations. This will provide stronger support for our motivating assumption. revision: yes
-
Referee: [§3.3] §3.3 (Perturbation module): the description of how delayed feedback is used to train the lightweight module and whether it requires ground-truth signals at test time is insufficient to verify the verifier-free claim and to confirm that the module does not introduce new instabilities.
Authors: We apologize for the lack of clarity in §3.3. The lightweight perturbation module is trained retrospectively using delayed feedback obtained from the environment after action execution (e.g., task completion signals or reward signals), without any ground-truth action labels or external verifiers. This preserves the verifier-free property as it relies solely on standard environment interactions. We will revise the section to include a detailed explanation, pseudocode for the training process, and an analysis of potential instabilities with corresponding mitigation strategies to ensure stability. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical test-time adaptation method (PDF) for VLAs that combines uncertainty-based augmentation, action voting, an adaptive scheduler, and a lightweight perturbation module trained on delayed feedback. No equations, derivations, or parameter-fitting steps are presented that reduce the reported performance gains to quantities defined by construction from the method's own inputs. The central claims rest on experimental results from LIBERO and Atari rather than self-referential definitions, fitted-input predictions, or load-bearing self-citations. The approach is self-contained as an engineering contribution with public code.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption VLAs achieve performance but remain fragile to subtle environmental shifts due to trajectory overfitting and spurious correlations between actions and entities.
Reference graph
Works this paper leans on
-
[1]
Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling
Marc G. Bellemare, Yavar Naddaf, Joel Veness, and Michael Bowling. The arcade learning environment: An evaluation platform for general agents.J. Artif. Intell. Res., 47:253– 279, 2013
2013
-
[2]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π0: A visio...
work page internal anchor Pith review arXiv 2024
-
[3]
Dokania, Philip H
Arslan Chaudhry, Marcus Rohrbach, Mohamed Elhoseiny, Thalaiyasingam Ajanthan, Puneet K. Dokania, Philip H. S. Torr, and Marc’Aurelio Ranzato. On tiny episodic memories in continual learning, 2019
2019
-
[4]
arXiv preprint arXiv:2506.08440 (2025)
Zengjue Chen, Runliang Niu, He Kong, and Qi Wang. TGRPO :fine-tuning vision-language-action model via trajectory-wise group relative policy optimization.CoRR, abs/2506.08440, 2025
-
[5]
Diffusion policy: Visuomotor policy learning via action dif- fusion.Int
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.Int. J. Robotics Res., 44(10-11):1684–1704, 2025
2025
-
[6]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision- language-action models.arXiv preprint arXiv:2510.13626, 2025
work page internal anchor Pith review arXiv 2025
-
[7]
Jack of all trades, mas- ter of some, a multi-purpose transformer agent.CoRR, abs/2402.09844, 2024
Quentin Gallou ´edec, Edward Beeching, Cl ´ement Romac, and Emmanuel Dellandr ´ea. Jack of all trades, mas- ter of some, a multi-purpose transformer agent.CoRR, abs/2402.09844, 2024
-
[8]
Sanketi, Dorsa Sadigh, Chelsea Finn, and Sergey Levine
Dibya Ghosh, Homer Rich Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Quan Vuong, Ted Xiao, Pannag R. Sanketi, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InRobotics: Science and Systems XX, Delft, The ...
2024
-
[9]
An embodied generalist agent in 3d world
Jiangyong Huang, Silong Yong, Xiaojian Ma, Xiongkun Linghu, Puhao Li, Yan Wang, Qing Li, Song-Chun Zhu, Baoxiong Jia, and Siyuan Huang. An embodied generalist agent in 3d world. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27,
2024
-
[10]
OpenReview.net, 2024
2024
-
[11]
Suhyeok Jang, Dongyoung Kim, Changyeon Kim, Young- suk Kim, and Jinwoo Shin. Verifier-free test-time sampling for vision language action models.CoRR, abs/2510.05681, 2025
-
[12]
Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Paul Foster, Pannag R. Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model. InConference on Robot Learning, 6-9 ...
2024
-
[13]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and suc- cess.CoRR, abs/2502.19645, 2025
work page internal anchor Pith review arXiv 2025
-
[14]
Test-time adaptation for online vision-language navigation with feedback-based reinforcement learning
Sungjune Kim, Gyeongrok Oh, Heeju Ko, Daehyun Ji, Dongwook Lee, Byung-Jun Lee, Sujin Jang, and Sang- pil Kim. Test-time adaptation for online vision-language navigation with feedback-based reinforcement learning. In Forty-second International Conference on Machine Learn- ing, 2025
2025
-
[15]
Jacky Kwok, Christopher Agia, Rohan Sinha, Matthew Fout- ter, Shulu Li, Ion Stoica, Azalia Mirhoseini, and Marco Pavone. Robomonkey: Scaling test-time sampling and verification for vision-language-action models.CoRR, abs/2506.17811, 2025
-
[16]
Test-time adaptation with binary feedback.CoRR, abs/2505.18514, 2025
Taeckyung Lee, Sorn Chottananurak, Junsu Kim, Jinwoo Shin, Taesik Gong, and Sung-Ju Lee. Test-time adaptation with binary feedback.CoRR, abs/2505.18514, 2025
-
[17]
Metavla: Unified meta co-training for efficient embodied adaption.CoRR, abs/2510.05580, 2025
Chen Li, Zhantao Yang, Han Zhang, Fangyi Chen, Chenchen Zhu, Anudeepsekhar Bolimera, and Marios Savvides. Metavla: Unified meta co-training for efficient embodied adaption.CoRR, abs/2510.05580, 2025
-
[18]
SimpleVLA-RL: Scaling VLA Training via Reinforcement Learning
Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Zhaohui Yang, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, Dehui Wang, Dingxiang Luo, Yuchen Fan, Youbang Sun, Jia Zeng, Jiangmiao Pang, Shanghang Zhang, Yu Wang, Yao Mu, Bowen Zhou, and Ning Ding. Simplevla- rl: Scaling VLA training via reinforcement learning.CoRR, abs/2509.09674, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
JARVIS-VLA: post-training large-scale vision language models to play visual games with keyboards and mouse
Muyao Li, Zihao Wang, Kaichen He, Xiaojian Ma, and Yi- tao Liang. JARVIS-VLA: post-training large-scale vision language models to play visual games with keyboards and mouse. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 17878–17899. Association for Computational Linguistics, 2025
2025
-
[20]
Vision-language foun- dation models as effective robot imitators
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, Hang Li, and Tao Kong. Vision-language foun- dation models as effective robot imitators. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024
2024
-
[21]
LIBERO: benchmarking knowl- edge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: benchmarking knowl- edge transfer for lifelong robot learning. InAdvances in Neu- ral Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023
2023
-
[22]
Packnet: Adding mul- tiple tasks to a single network by iterative pruning
Arun Mallya and Svetlana Lazebnik. Packnet: Adding mul- tiple tasks to a single network by iterative pruning. In2018 IEEE Conference on Computer Vision and Pattern Recog- nition, CVPR 2018, Salt Lake City, UT, USA, June 18- 22, 2018, pages 7765–7773. Computer Vision Foundation / IEEE Computer Society, 2018
2018
-
[23]
Steering your generalists: Improving robotic foun- dation models via value guidance
Mitsuhiko Nakamoto, Oier Mees, Aviral Kumar, and Sergey Levine. Steering your generalists: Improving robotic foun- dation models via value guidance. InConference on Robot Learning, 6-9 November 2024, Munich, Germany, pages 4996–5013. PMLR, 2024
2024
-
[24]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. Spatialvla: Exploring spa- tial representations for visual-language-action model.CoRR, abs/2501.15830, 2025
work page internal anchor Pith review arXiv 2025
-
[25]
Scott E. Reed, Konrad Zolna, Emilio Parisotto, Ser- gio G´omez Colmenarejo, Alexander Novikov, Gabriel Barth- Maron, Mai Gimenez, Yury Sulsky, Jackie Kay, Jost Tobias Springenberg, Tom Eccles, Jake Bruce, Ali Razavi, Ashley Edwards, Nicolas Heess, Yutian Chen, Raia Hadsell, Oriol Vinyals, Mahyar Bordbar, and Nando de Freitas. A general- ist agent.Trans. M...
2022
-
[26]
Introduc- ing rfm-1: Giving robots human-like reason-ing capabilities, 2024
A Sohn, A Nagabandi, C Florensa, D Adelberg, D Wu, H Fa- rooq, I Clavera, J Welborn, J Chen, N Mishra, et al. Introduc- ing rfm-1: Giving robots human-like reason-ing capabilities, 2024
2024
-
[27]
Lingo-2: Driving with natural language, 2024
Waywe Research Team et al. Lingo-2: Driving with natural language, 2024
2024
-
[28]
Ol- shausen, and Trevor Darrell
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno A. Ol- shausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Aus- tria, May 3-7, 2021. OpenReview.net, 2021
2021
-
[29]
Any-point trajectory modeling for policy learning
Chuan Wen, Xingyu Lin, John Ian Reyes So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajectory modeling for policy learning. InRobotics: Science and Sys- tems XX, Delft, The Netherlands, July 15-19, 2024, 2024
2024
-
[30]
SCAP: transductive test-time adaptation via supportive clique-based attribute prompting
Chenyu Zhang, Kunlun Xu, Zichen Liu, Yuxin Peng, and Jiahuan Zhou. SCAP: transductive test-time adaptation via supportive clique-based attribute prompting. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 30032–30041. Computer Vision Foundation / IEEE, 2025
2025
-
[31]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action mod- els
Qingqing Zhao, Yao Lu, Moo Jin Kim, Zipeng Fu, Zhuoyang Zhang, Yecheng Wu, Zhaoshuo Li, Qianli Ma, Song Han, Chelsea Finn, Ankur Handa, Tsung-Yi Lin, Gordon Wet- zstein, Ming-Yu Liu, and Donglai Xiang. Cot-vla: Visual chain-of-thought reasoning for vision-language-action mod- els. InIEEE/CVF Conference on Computer Vision and Pat- tern Recognition, CVPR 20...
2025
-
[32]
3d- vla: A 3d vision-language-action generative world model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d- vla: A 3d vision-language-action generative world model. InForty-first International Conference on Machine Learn- ing, ICML 2024, Vienna, Austria, July 21-27, 2024. Open- Review.net, 2024
2024
-
[33]
Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies
Ruijie Zheng, Yongyuan Liang, Shuaiyi Huang, Jianfeng Gao, Hal Daum ´e III, Andrey Kolobov, Furong Huang, and Jianwei Yang. Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies. In The Thirteenth International Conference on Learning Repre- sentations, ICLR 2025, Singapore, April 24-28, 2025. Open- Review.net, 2025
2025
-
[34]
Jiahuan Zhou, Chao Zhu, Zhenyu Cui, Zichen Liu, Xu Zou, and Gang Hua. Class-aware domain knowledge fu- sion and fission for continual test-time adaptation.CoRR, abs/2510.12150, 2025
-
[35]
Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Sermanet, Pannag R
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, Quan Vuong, Vincent Vanhoucke, Huong T. Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Sermanet, Pannag R. Sanketi, Grecia Salazar, Michael S. Ryoo, Krista Reymann, Kanishka Rao, Karl Pertsch, Igor Mordatch, Henryk Michalew...
2023
-
[36]
Psydo-Code We provide a brief overview of the training pipeline out- lined in Algorithm 1, which implements PDF. Algorithm 1Perturbation Learning with Delayed Feedback (PDF) Require:Pretrained VLA parametersϕ(frozen); Perturba- tion head parametersθ(trainable); maximum augmen- tation budgetN max; bufferD. 1:foreach episodedo 2:foreach timesteptdo 3:Observ...
-
[37]
Additional Experiments Results on Atari 57 Table 4 presents the detailed results of PDF and JAT on the full Atari 57 benchmark. Games ID JAT (Raw Score) JAT (Human Normalized Score)PDF (Raw Score) PDF (Human Normalized Score) ALIEN 22 1427.9 ± 540.28 0.17 2034.4 ± 560.47 0.26 AMIDAR 34 105 ± 76.93 0.06 150.2 ± 57.05 0.08 ASSAULT 4 1627.57 ± 799.09 2.7 186...
2034
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.