Recognition: unknown
Momentum Stability and Adaptive Control in Stochastic Reconfiguration
Pith reviewed 2026-05-10 04:17 UTC · model grok-4.3
The pith
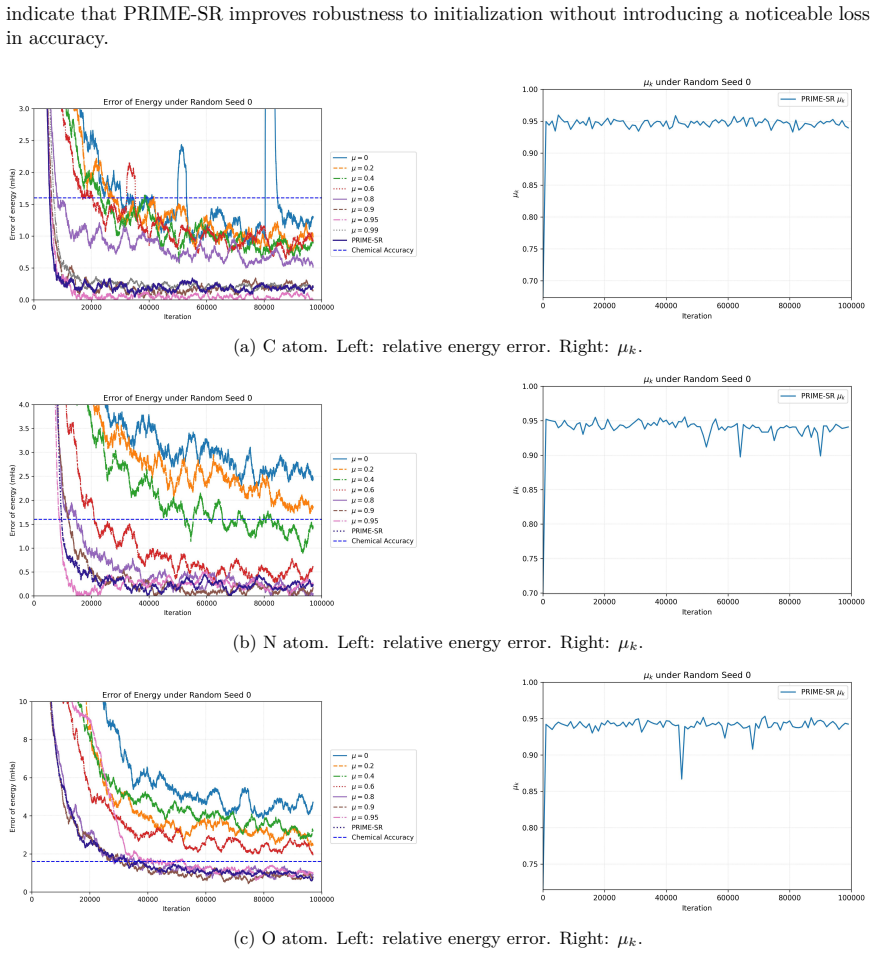
Momentum below 1 guarantees convergence in stochastic reconfiguration while value 1 can cause divergence along kernel directions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
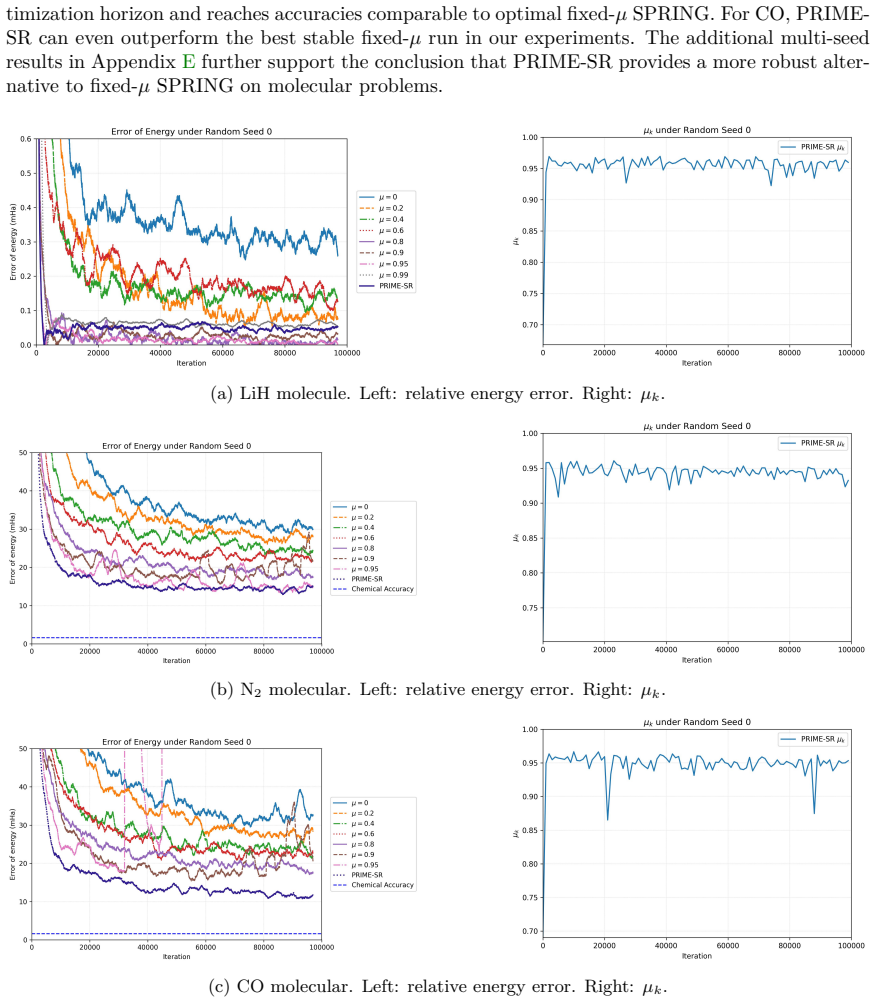
The authors establish convergence guarantees for the momentum parameter satisfying 0 ≤ μ < 1 under mild assumptions, and they construct explicit counterexamples in which μ = 1 produces divergence through uncontrolled growth along kernel-related directions whenever the step-size sequence is not summable. Motivated by the gap between these two regimes, they introduce PRIME-SR, a momentum-adaptive variant of stochastic reconfiguration that estimates effective spectral dimension and subspace overlap from sampled data to adjust μ automatically, thereby attaining accuracy comparable to optimally tuned SPRING while improving robustness across variational Monte Carlo tasks.
What carries the argument
The momentum parameter μ inside the update rule of subsampled projected-increment natural gradient descent (SPRING), which interpolates between successive preconditioned directions and whose value relative to 1 determines whether the iteration remains bounded or grows along the kernel of the Fisher-like matrix.
Load-bearing premise
The convergence claims rest on unspecified mild assumptions about the landscape and sampling, while the adaptive method assumes that effective spectral dimension and subspace overlap can be estimated reliably from finite batches without introducing fresh instabilities.
What would settle it
A controlled linear test problem containing a nontrivial kernel in which μ = 1 with non-summable steps produces visible divergence, or a standard VMC benchmark in which PRIME-SR fails to reach the accuracy of the best manually tuned SPRING run.
Figures

















read the original abstract
Variational Monte Carlo (VMC) combined with expressive neural network wavefunctions has become a powerful route to high-accuracy ground-state calculations, yet its practical success hinges on efficient and stable wavefunction optimization. While stochastic reconfiguration (SR) provides a geometry-aware preconditioner motivated by imaginary-time evolution, its Kaczmarz-inspired variant, subsampled projected-increment natural gradient descent (SPRING), achieves state-of-the-art empirical performance. However, the effectiveness of SPRING is highly sensitive to the choice of a momentum-like parameter $\mu$. The original sensitivity of $\mu$ and the instability observed at $\mu=1$, have remained unclear. In this work, we clarify the distinct mechanisms governing the regimes $\mu<1$ and $\mu=1$. We establish convergence guarantees for $0\le\mu<1$ under mild assumptions, and construct counterexamples showing that $\mu=1$ can induce divergence via uncontrolled growth along kernel-related directions when the step-size is not summable. Motivated by these theoretical insights and numerical observations, we further propose \textit{Principal Range Informed MomEntum SR} (PRIME-SR), a tuning-free momentum-adaptive SR method based on effective spectral dimension and subspace overlap. PRIME-SR achieves performance comparable to optimally tuned SPRING while significantly improving robustness in VMC optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript analyzes momentum stability in stochastic reconfiguration (SR) and its subsampled projected-increment variant (SPRING) for neural-network variational Monte Carlo (VMC) optimization. It establishes convergence guarantees for the momentum parameter in the regime 0 ≤ μ < 1 under mild assumptions, constructs counterexamples demonstrating divergence at μ = 1 via uncontrolled growth along kernel-related directions when the step-size is not summable, and proposes the tuning-free adaptive method PRIME-SR that estimates effective spectral dimension and subspace overlap to achieve performance comparable to optimally tuned SPRING while improving robustness.
Significance. If the convergence guarantees hold under the stated mild assumptions and PRIME-SR proves stable on realistic noisy, rank-deficient Fisher metrics, the work would provide both theoretical clarification of a known practical instability and a practical adaptive algorithm for VMC. The explicit counterexamples for the μ = 1 case constitute a clear strength, as they isolate the mechanism of divergence without relying on fitted quantities.
major comments (3)
- [Abstract and §3] Abstract and §3 (convergence analysis): the convergence guarantees for 0 ≤ μ < 1 are asserted under 'mild assumptions' on the SR metric, stochastic gradient noise, and step-size summability, yet the precise statements of these assumptions, any proof sketches, and verification that they bound variance or exclude amplification along near-zero eigenvalues of the sampled Fisher matrix are absent; without these the transfer to finite-sample neural VMC cannot be assessed.
- [§4 and §5] §4 (counterexamples) and §5 (PRIME-SR): the μ = 1 divergence counterexamples are constructed in the deterministic setting, but the adaptive PRIME-SR estimator of effective spectral dimension and subspace overlap is applied to the same noisy Monte Carlo samples; no analysis is given of how estimation error or rank deficiency in the sampled metric could introduce new instabilities not covered by the existing guarantees.
- [§5.2] §5.2 (numerical experiments): the claim that PRIME-SR 'significantly improves robustness' is supported only by performance comparable to optimally tuned SPRING; without ablations on the sensitivity of the spectral-dimension estimator to sample size or noise level, the robustness advantage remains unverified.
minor comments (2)
- [§5.1] Notation for the effective spectral dimension and subspace overlap in the PRIME-SR rule should be defined explicitly before its use in the algorithm box.
- [Figure 2] Figure captions for the divergence trajectories should state the precise step-size schedule and matrix conditioning used in the counterexamples.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important points for clarification and additional verification. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (convergence analysis): the convergence guarantees for 0 ≤ μ < 1 are asserted under 'mild assumptions' on the SR metric, stochastic gradient noise, and step-size summability, yet the precise statements of these assumptions, any proof sketches, and verification that they bound variance or exclude amplification along near-zero eigenvalues of the sampled Fisher matrix are absent; without these the transfer to finite-sample neural VMC cannot be assessed.
Authors: We agree that the assumptions require explicit statement. In the revised manuscript we will add a dedicated subsection in §3 that lists the precise assumptions on the SR metric (positive-definiteness bounds away from zero eigenvalues), the stochastic gradient noise (bounded variance), and step-size summability. We will also include a proof sketch that shows how these conditions control the variance term and preclude amplification along near-zero eigenvalues of the sampled Fisher matrix, thereby clarifying applicability to finite-sample neural VMC. revision: yes
-
Referee: [§4 and §5] §4 (counterexamples) and §5 (PRIME-SR): the μ = 1 divergence counterexamples are constructed in the deterministic setting, but the adaptive PRIME-SR estimator of effective spectral dimension and subspace overlap is applied to the same noisy Monte Carlo samples; no analysis is given of how estimation error or rank deficiency in the sampled metric could introduce new instabilities not covered by the existing guarantees.
Authors: The deterministic counterexamples in §4 are deliberately constructed to isolate the divergence mechanism at μ=1 that arises from uncontrolled growth along kernel directions when the step-size is not summable. PRIME-SR adapts μ using estimates computed from the same noisy samples; while this is consistent with practical VMC usage, we acknowledge that a rigorous propagation analysis of estimation error under rank deficiency is not supplied. In the revision we will add a discussion paragraph in §5 that addresses possible new instabilities and notes that our existing numerical experiments showed no such instabilities. A complete theoretical treatment of the estimator error bounds lies beyond the present scope. revision: partial
-
Referee: [§5.2] §5.2 (numerical experiments): the claim that PRIME-SR 'significantly improves robustness' is supported only by performance comparable to optimally tuned SPRING; without ablations on the sensitivity of the spectral-dimension estimator to sample size or noise level, the robustness advantage remains unverified.
Authors: We agree that targeted ablations would strengthen the robustness claim. In the revised §5.2 we will include additional experiments that systematically vary Monte Carlo sample size and noise level while monitoring the spectral-dimension estimator. These results will demonstrate that the estimator remains stable and that PRIME-SR retains its performance advantage, thereby verifying the robustness improvement beyond mere comparability to tuned SPRING. revision: yes
- A rigorous analysis of how estimation error or rank deficiency in the sampled metric could introduce new instabilities in PRIME-SR.
Circularity Check
No significant circularity: convergence claims and adaptive method rest on independent analysis
full rationale
The paper presents convergence guarantees for μ<1 under mild assumptions and constructs explicit counterexamples for μ=1, neither of which reduces to a fitted parameter or self-referential definition. PRIME-SR is motivated by these results plus numerical observations and introduces a new adaptive rule based on estimated spectral dimension; no equation or claim is shown to be equivalent to its inputs by construction. Self-citations to prior SPRING work are present but not load-bearing for the new stability theorems or the adaptive estimator. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mild assumptions sufficient for convergence when 0 ≤ μ < 1
invented entities (1)
-
PRIME-SR adaptive rule
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Convergence of variational monte carlo simulation and scale-invariant pre-training
Nilin Abrahamsen, Zhiyan Ding, Gil Goldshlager, and Lin Lin. Convergence of variational monte carlo simulation and scale-invariant pre-training. Journal of Computational Physics , 513:113140, 2024
2024
-
[2]
Anti-symmetric barron functions and their approximation with sums of determinants
Nilin Abrahamsen and Lin Lin. Anti-symmetric barron functions and their approximation with sums of determinants. Journal of Computational Physics , page 114118, 2025
2025
-
[3]
Functional neural wavefunction optimization
Victor Armegioiu, Juan Carrasquilla, Siddhartha Mishra, Johannes Müller, Jannes Nys, Marius Zeinhofer, and Hang Zhang. Functional neural wavefunction optimization. arXiv preprint arXiv:2507.10835, 2025
-
[4]
Quantum Monte Carlo approaches for correlated systems
Federico Becca and Sandro Sorella. Quantum Monte Carlo approaches for correlated systems . Cambridge University Press, 2017
2017
-
[5]
Bradbury, R
J. Bradbury, R. Frostig, P. Hawkins, M. J. Johnson, C. Leary, D. Maclaurin, G. Necula, A. Paszke, J. VanderPlas, S. Wanderman-Milne, and Q. Zhang. JAX: Composable transforma- tions of Python+NumPy programs. http://github.com/jax-ml/jax, 2018
2018
-
[6]
Carleo and M
G. Carleo and M. Troyer. Solving the quantum many-body problem with artificial neural networks. Science, 355(6325):602–606, 2017
2017
-
[7]
Empowering deep neural quantum states through efficient opti- mization
Ao Chen and Markus Heyl. Empowering deep neural quantum states through efficient opti- mization. Nature Physics , 20(9):1476–1481, 2024. 24
2024
-
[8]
Deanna and T
N. Deanna and T. Joel A. Paved with good intentions: analysis of a randomized block Kaczmarz method. Linear Algebra and its Applications , 441:199–221, 2014
2014
-
[9]
Quantum monte carlo simulations of solids
William MC Foulkes, Lubos Mitas, RJ Needs, and Guna Rajagopal. Quantum monte carlo simulations of solids. Reviews of Modern Physics , 73(1):33, 2001
2001
-
[10]
Goldshlager, N
G. Goldshlager, N. Abrahamsen, and L. Lin. A Kaczmarz-inspired approach to accelerate the optimization of neural network wavefunctions. Journal of Computational Physics , 516:113351, 2024
2024
-
[11]
Solving the hubbard model with neural quantum states, 2025
Yuntian Gu, Wenrui Li, Heng Lin, Bo Zhan, Ruichen Li, Yifei Huang, Di He, Yantao Wu, Tao Xiang, Mingpu Qin, Liwei Wang, and Dingshun Lv. Solving the hubbard model with neural quantum states, 2025
2025
-
[12]
Hermann, Z
J. Hermann, Z. Schätzle, and F. Noé. Deep-neural-network solution of the electronic Schrödinger equation. Nature Chemistry , 12(10):891–897, 2020
2020
-
[13]
Ab initio quantum chemistry with neural-network wavefunctions
Jan Hermann, James Spencer, Kenny Choo, Antonio Mezzacapo, W Matthew C Foulkes, David Pfau, Giuseppe Carleo, and Frank Noé. Ab initio quantum chemistry with neural-network wavefunctions. Nature Reviews Chemistry , 7(10):692–709, 2023
2023
-
[14]
Juergen Hinze. Mc-scf. i. the multi-configuration self-consistent-field method. The Journal of Chemical Physics , 59(12):6424–6432, 1973
1973
-
[15]
Karczmarz
S. Karczmarz. Angenaherte auflosung von systemen linearer glei-chungen. Bull. Int. Acad. Pol. Sic. Let., Cl. Sci. Math. Nat. , pages 355–357, 1937
1937
-
[16]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[17]
Accelerated natural gradient method for parametric manifold optimization, 2025
Chenyi Li, Shuchen Zhu, Zhonglin Xie, and Zaiwen Wen. Accelerated natural gradient method for parametric manifold optimization, 2025
2025
-
[18]
A computational framework for neural network-based variational monte carlo with forward laplacian
Ruichen Li, Haotian Ye, Du Jiang, Xuelan Wen, Chuwei Wang, Zhe Li, Xiang Li, Di He, Ji Chen, Weiluo Ren, et al. A computational framework for neural network-based variational monte carlo with forward laplacian. Nature Machine Intelligence , 6(2):209–219, 2024
2024
-
[19]
Convergence analysis of stochastic gradient descent with mcmc estimators
Tianyou Li, Fan Chen, Huajie Chen, and Zaiwen Wen. Convergence analysis of stochastic gradient descent with mcmc estimators. arXiv preprint arXiv:2303.10599 , 2023
-
[20]
J. Lin, G. Goldshlager, N. Abrahamsen, and L. Lin. VMCNet: Framework for training first- quantized neural network wavefunctions using VMC, built on JAX, 2024
2024
-
[21]
Explicitly antisymmetrized neural network layers for variational monte carlo simulation
Jeffmin Lin, Gil Goldshlager, and Lin Lin. Explicitly antisymmetrized neural network layers for variational monte carlo simulation. Journal of Computational Physics , 474:111765, 2023
2023
-
[22]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[23]
Martens and R
J. Martens and R. Grosse. Optimizing neural networks with Kronecker-factored approximate curvature. In International Conference on Machine Learning , pages 2408–2417. PMLR, 2015
2015
-
[24]
Ground state of liquid he 4
William Lauchlin McMillan. Ground state of liquid he 4. Physical Review, 138(2A):A442, 1965
1965
-
[25]
Wasserstein quantum monte carlo: a novel approach for solving the quan- tum many-body schrödinger equation
Kirill Neklyudov, Jannes Nys, Luca Thiede, Juan Carrasquilla, Qiang Liu, Max Welling, and Alireza Makhzani. Wasserstein quantum monte carlo: a novel approach for solving the quan- tum many-body schrödinger equation. Advances in Neural Information Processing Systems , 36:63461–63482, 2023. 25
2023
-
[26]
Numerical optimization
Jorge Nocedal. Numerical optimization. Springer Ser. Oper. Res. Financ. Eng./Springer , 2006
2006
-
[27]
D. Pfau, J. S. Spencer, A. G. D. G. Matthews, and W. M. C. Foulkes. Ab initio solution of the many-electron Schrödinger equation with deep neural networks. Physical Review Research, 2(3), 2020
2020
-
[28]
A simple linear algebra identity to optimize large-scale neural network quantum states
Riccardo Rende, Luciano Loris Viteritti, Lorenzo Bardone, Federico Becca, and Sebastian Goldt. A simple linear algebra identity to optimize large-scale neural network quantum states. Communications Physics , 7(1):260, 2024
2024
-
[29]
The method of configuration interaction
Isaiah Shavitt. The method of configuration interaction. In Methods of electronic structure theory, pages 189–275. Springer, 1977
1977
-
[30]
S. Sorella. Green function Monte Carlo with stochastic reconfiguration. Physical Review Letters, 80(20):4558, 1998
1998
-
[31]
S. Sorella. Generalized Lanczos algorithm for variational quantum Monte Carlo. Physical Review B, 64(2):024512, 2001
2001
-
[32]
Quantum natural gradient
James Stokes, Josh Izaac, Nathan Killoran, and Giuseppe Carleo. Quantum natural gradient. Quantum, 4:269, 2020
2020
-
[33]
Energy and variance optimization of many-body wave func- tions
CJ Umrigar and Claudia Filippi. Energy and variance optimization of many-body wave func- tions. Physical review letters , 94(15):150201, 2005
2005
-
[34]
Vicentini, D
F. Vicentini, D. Hofmann, A. Szabó, D. Wu, C. Roth, C. Giuliani, G. Pescia, J. Nys, V. Vargas- Calderón, N. Astrakhantsev, and G. Carleo. NetKet 3: Machine Learning Toolbox for Many- Body Quantum Systems. SciPost Phys. Codebases , page 7, 2022
2022
-
[35]
A self-attention ansatz for ab-initio quantum chemistry
Ingrid von Glehn, James S Spencer, and David Pfau. A self-attention ansatz for ab-initio quantum chemistry. In The Eleventh International Conference on Learning Representations
-
[36]
Lower bound on the representation complexity of antisymmetric tensor product functions
Yuyang Wang, Yukuan Hu, and Xin Liu. Lower bound on the representation complexity of antisymmetric tensor product functions. SCIENCE CHINA Mathematics , 2026
2026
-
[37]
Optimization of neural network wave functions in variational monte carlo
Yuyang Wang and Xin Liu. Optimization of neural network wave functions in variational monte carlo. The Innovation Informatics , pages 100025–1, 2025
2025
-
[38]
Rayleigh-gauss-newton optimization with enhanced sampling for variational monte carlo
Robert J Webber and Michael Lindsey. Rayleigh-gauss-newton optimization with enhanced sampling for variational monte carlo. Physical Review Research, 4(3):033099, 2022
2022
-
[39]
o(n2) representation of general continuous anti-symmetric function
Haotian Ye, Ruichen Li, Yuntian Gu, Yiping Lu, Di He, and Liwei Wang. o(n2) representation of general continuous anti-symmetric function. arXiv preprint arXiv:2402.15167 , 2024
-
[40]
A blocked linear method for optimizing large parameter sets in variational monte carlo
Luning Zhao and Eric Neuscamman. A blocked linear method for optimizing large parameter sets in variational monte carlo. Journal of chemical theory and computation , 13(6):2604–2611, 2017
2017
-
[41]
Stochastic recon- figuration with warm-started svd, 2025
Dexuan Zhou, Huajie Chen, Cheuk Hin Ho, Xin Liu, and Christoph Ortner. Stochastic recon- figuration with warm-started svd, 2025
2025
-
[42]
A multilevel method for many-electron schrödinger equations based on the atomic cluster expansion
Dexuan Zhou, Huajie Chen, Cheuk Hin Ho, and Christoph Ortner. A multilevel method for many-electron schrödinger equations based on the atomic cluster expansion. SIAM Journal on Scientific Computing , 46(1):A105–A129, 2024. 26 A Proof of Theorem 3.1 To prove Theorem 3.1, we first establish the following lemmas. Lemma A.1. Under Assumption 3.1, for any θ 2 ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.