Recognition: unknown
MathNet: a Global Multimodal Benchmark for Mathematical Reasoning and Retrieval
Pith reviewed 2026-05-10 04:06 UTC · model grok-4.3
The pith
MathNet dataset shows even top AI models struggle with Olympiad math problems and retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
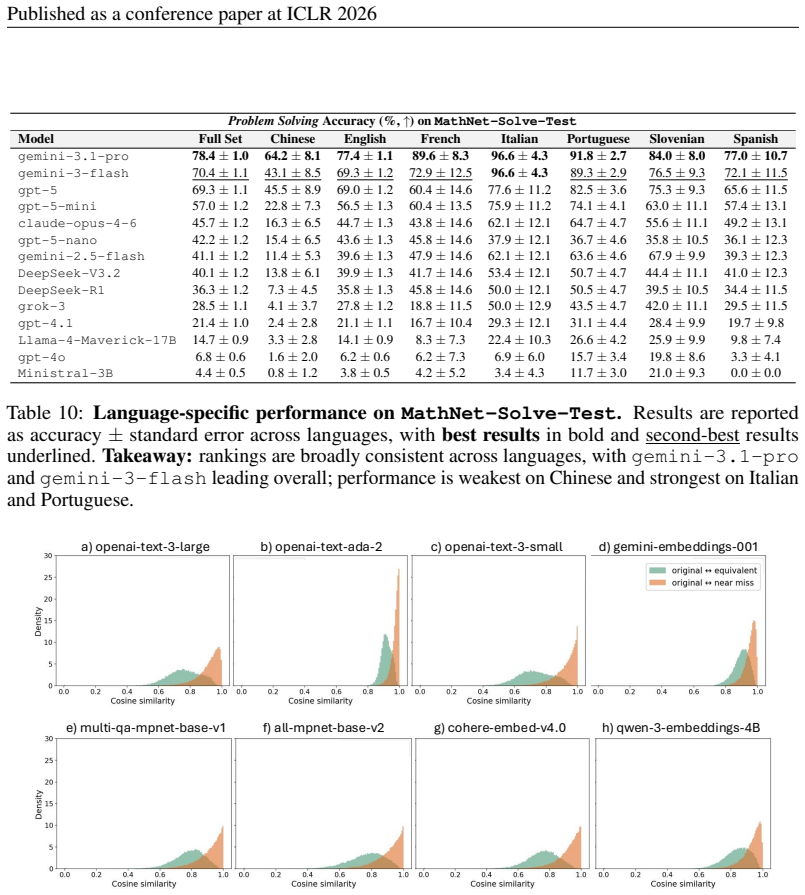
MathNet is the largest high-quality Olympiad dataset with the first benchmark for mathematical problem retrieval using human-curated equivalent and similar problem pairs. State-of-the-art reasoning models remain challenged on the tasks, while retrieval-augmented generation yields performance gains of up to 12% when retrieval quality is high.
What carries the argument
The MathNet dataset and its retrieval benchmark of mathematically equivalent and structurally similar problem pairs curated by human experts.
If this is right
- State-of-the-art models need significant improvements to reliably solve Olympiad-level problems.
- Retrieval quality is critical for the success of retrieval-augmented approaches in mathematical tasks.
- The multilingual aspect allows evaluation of models across different languages and cultural contexts in math.
- Embedding models require better methods to capture mathematical equivalence beyond surface similarity.
Where Pith is reading between the lines
- MathNet could serve as a training resource to develop specialized mathematical AI systems.
- Similar benchmarks might be developed for other domains like physics or programming to test retrieval-augmented reasoning.
- Automated methods for generating equivalent problems could help scale such datasets further without heavy human curation.
Load-bearing premise
Human experts accurately and consistently identify pairs of mathematically equivalent and structurally similar problems without selection bias or judgment errors.
What would settle it
A new model achieving over 95% accuracy on the problem solving benchmark or perfect retrieval of all equivalent problems would indicate the challenges are overstated.
Figures





read the original abstract
Mathematical problem solving remains a challenging test of reasoning for large language and multimodal models, yet existing benchmarks are limited in size, language coverage, and task diversity. We introduce MathNet, a high-quality, large-scale, multimodal, and multilingual dataset of Olympiad-level math problems together with a benchmark for evaluating mathematical reasoning in generative models and mathematical retrieval in embedding-based systems. MathNet spans 47 countries, 17 languages, and two decades of competitions, comprising 30,676 expert-authored problems with solutions across diverse domains. In addition to the core dataset, we construct a retrieval benchmark consisting of mathematically equivalent and structurally similar problem pairs curated by human experts. MathNet supports three tasks: (i) Problem Solving, (ii) Math-Aware Retrieval, and (iii) Retrieval-Augmented Problem Solving. Experimental results show that even state-of-the-art reasoning models (78.4% for Gemini-3.1-Pro and 69.3% for GPT-5) remain challenged, while embedding models struggle to retrieve equivalent problems. We further show that retrieval-augmented generation performance is highly sensitive to retrieval quality; for example, DeepSeek-V3.2-Speciale achieves gains of up to 12%, obtaining the highest scores on the benchmark. MathNet provides the largest high-quality Olympiad dataset together with the first benchmark for evaluating mathematical problem retrieval, and we publicly release both the dataset and benchmark at https://mathnet.mit.edu.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MathNet, a large-scale, multimodal, multilingual dataset comprising 30,676 expert-authored Olympiad-level math problems from 47 countries and 17 languages over two decades. It establishes benchmarks for three tasks: problem solving, math-aware retrieval using human-curated pairs of mathematically equivalent and structurally similar problems, and retrieval-augmented problem solving. The results demonstrate that state-of-the-art models achieve at most 78.4% on problem solving (Gemini-3.1-Pro) and 69.3% (GPT-5), embedding models struggle with retrieval, and retrieval-augmented generation can provide gains of up to 12%, with the dataset and benchmark publicly released.
Significance. Should the human curation of the retrieval pairs prove reliable upon validation, this work would offer significant value by providing the largest high-quality Olympiad math dataset to date and the first benchmark specifically for mathematical problem retrieval. The findings on model challenges and the benefits of RAG in this domain could inform advancements in mathematical reasoning systems. The public release supports further research and reproducibility in the field.
major comments (2)
- [Retrieval benchmark construction] The manuscript describes the retrieval benchmark as consisting of 'mathematically equivalent and structurally similar problem pairs curated by human experts' but does not specify the criteria for equivalence, the number of experts per pair, or inter-annotator agreement metrics. This information is essential to substantiate the claims regarding the difficulty for embedding models and the sensitivity of RAG performance to retrieval quality, as unvalidated labels may introduce bias or noise affecting the reported results.
- [Experimental results on RAG] The performance gains from retrieval-augmented generation, such as the up to 12% improvement for DeepSeek-V3.2-Speciale, are reported without accompanying statistical significance tests, standard errors, or details on evaluation variance across multiple runs. This makes it difficult to determine whether the gains are robust or could be due to chance, particularly given the central role of RAG in the benchmark.
minor comments (1)
- [Abstract] The mention of 'GPT-5' should be clarified, as it may refer to a specific model version or be a typographical reference to an existing model like GPT-4o.
Simulated Author's Rebuttal
We are grateful to the referee for their detailed and constructive review of our manuscript. Their comments have helped us identify areas where the paper can be strengthened, particularly regarding the transparency of the retrieval benchmark construction and the statistical rigor of the RAG experiments. We address each major comment below and commit to making the necessary revisions.
read point-by-point responses
-
Referee: [Retrieval benchmark construction] The manuscript describes the retrieval benchmark as consisting of 'mathematically equivalent and structurally similar problem pairs curated by human experts' but does not specify the criteria for equivalence, the number of experts per pair, or inter-annotator agreement metrics. This information is essential to substantiate the claims regarding the difficulty for embedding models and the sensitivity of RAG performance to retrieval quality, as unvalidated labels may introduce bias or noise affecting the reported results.
Authors: We thank the referee for pointing out this gap in our description. The manuscript indeed provides only a brief mention of the human curation without elaborating on the process. We will revise the relevant section to include a detailed account of the curation protocol. This will specify the criteria for mathematical equivalence and structural similarity, the number of experts per pair, and the inter-annotator agreement metrics from our curation process. These additions will provide the necessary validation for the benchmark's quality and support our conclusions on model performance and RAG sensitivity. revision: yes
-
Referee: [Experimental results on RAG] The performance gains from retrieval-augmented generation, such as the up to 12% improvement for DeepSeek-V3.2-Speciale, are reported without accompanying statistical significance tests, standard errors, or details on evaluation variance across multiple runs. This makes it difficult to determine whether the gains are robust or could be due to chance, particularly given the central role of RAG in the benchmark.
Authors: We agree that reporting statistical measures is crucial for establishing the reliability of the RAG gains. The current results are based on single-run evaluations, which limits the assessment of variance. In the revised manuscript, we will include standard errors and results from statistical significance tests computed over multiple evaluation runs to demonstrate the robustness of the gains, ensuring the improvements are not due to chance. revision: yes
Circularity Check
No circularity: benchmark and results are direct empirical evaluations on newly collected data.
full rationale
The paper introduces a new dataset of 30,676 Olympiad problems and a retrieval benchmark built from human-curated equivalent/similar pairs, then reports direct model performance numbers (e.g., Gemini 78.4%, RAG gains up to 12%). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All claims rest on the external collection and evaluation process rather than any internal reduction to the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models , author=. arXiv preprint arXiv:2410.07985 , year=
work page internal anchor Pith review arXiv
-
[2]
Foundations and Trends
Mathematical Information Retrieval: Search and Question Answering , author=. Foundations and Trends. 2025 , publisher=
2025
-
[3]
Siyue Zhang, Yilun Zhao, Liyuan Geng, Arman Cohan, Anh Tuan Luu, and Chen Zhao
RaDeR: Reasoning-aware Dense Retrieval Models , author=. arXiv preprint arXiv:2505.18405 , year=
-
[4]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Hugging Face repository , volume=
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions , author=. Hugging Face repository , volume=
-
[6]
Big-math: A large-scale, high-quality math dataset for reinforcement learning in language models , author=. arXiv preprint arXiv:2502.17387 , year=
-
[7]
OlympiadBench: A Challenging Benchmark for Promoting AGI with Olympiad-Level Bilingual Multimodal Scientific Problems , author=. arXiv preprint arXiv:2402.14008 , year=
work page internal anchor Pith review arXiv
-
[8]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts , author=. arXiv preprint arXiv:2310.02255 , year=
work page internal anchor Pith review arXiv
-
[9]
2022 , howpublished=
ChatGPT , author=. 2022 , howpublished=
2022
-
[10]
2023 , howpublished=
GPT-4 Technical Report , author=. 2023 , howpublished=
2023
-
[11]
2023 , howpublished=
Claude 2 , author=. 2023 , howpublished=
2023
-
[12]
NeurIPS , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. NeurIPS , year=
-
[13]
NeurIPS , year=
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , author=. NeurIPS , year=
-
[14]
2023 , howpublished=
Google Bard , author=. 2023 , howpublished=
2023
-
[15]
2020 , howpublished=
EasyOCR , author=. 2020 , howpublished=
2020
-
[16]
2023 , howpublished=
IDEFICS: An Open Multimodal Model , author=. 2023 , howpublished=
2023
-
[17]
2023 , howpublished=
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality , author=. 2023 , howpublished=
2023
-
[18]
2023 , howpublished=
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models , author=. 2023 , howpublished=
2023
-
[19]
2023 , howpublished=
LLaMA-Adapter V2: Parameter-Efficient Visual Instruction Model , author=. 2023 , howpublished=
2023
-
[20]
2023 , howpublished=
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , author=. 2023 , howpublished=
2023
-
[21]
2023 , howpublished=
Visual Instruction Tuning , author=. 2023 , howpublished=
2023
-
[22]
2023 , howpublished=
LLaVAR: Enhanced Visual Instruction Tuning for Text-Rich Image Understanding , author=. 2023 , howpublished=
2023
-
[23]
, author=
Dense Passage Retrieval for Open-Domain Question Answering. , author=. EMNLP (1) , pages=
-
[24]
Unsupervised Dense Information Retrieval with Contrastive Learning
Unsupervised dense information retrieval with contrastive learning , author=. arXiv preprint arXiv:2112.09118 , year=
work page internal anchor Pith review arXiv
-
[25]
SIGIR , year=
ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT , author=. SIGIR , year=
-
[26]
arXiv preprint arXiv:2109.10086(2021)
SPLADE v2: Sparse lexical and expansion model for information retrieval , author=. arXiv preprint arXiv:2109.10086 , year=
-
[27]
NeurIPS , year=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. NeurIPS , year=
-
[28]
arXiv preprint arXiv:2007.01852 , year=
Language-agnostic BERT Sentence Embedding , author=. arXiv:2007.01852 , year=
-
[29]
NTCIR-11 , year=
NTCIR-11 Math-2 Task Overview , author=. NTCIR-11 , year=
-
[30]
NTCIR-12 , year=
NTCIR-12 MathIR Task Overview , author=. NTCIR-12 , year=
-
[31]
NTCIR-12 , year=
Tangent-3 at the NTCIR-12 MathIR Task , author=. NTCIR-12 , year=
-
[32]
Indexing and Searching Mathematics in Digital Libraries (MIaS) , author=
-
[33]
arXiv preprint arXiv:2308.13418 , year=
Nougat: Neural Optical Understanding for Academic Documents , author=. arXiv:2308.13418 , year=
-
[34]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[35]
FLoC/IJCAR , year=
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics , author=. FLoC/IJCAR , year=
-
[36]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
2025 , date =
Thang Luong and Edward Lockhart , title =. 2025 , date =
2025
-
[38]
Measuring Multimodal Mathematical Reasoning with
Wang, Ke and Pan, Junting and Shi, Weikang and Lu, Zimu and Ren, Houxing and Zhou, Aojun and Zhan, Mingjie and Li, Hongsheng , booktitle =. Measuring Multimodal Mathematical Reasoning with
-
[39]
Proceedings of the 41st International Conference on Machine Learning (ICML), PMLR , year =
SciBench: Evaluating College-Level Scientific Problem-Solving Abilities of Large Language Models , author =. Proceedings of the 41st International Conference on Machine Learning (ICML), PMLR , year =
-
[40]
Li, Haonan and Zhang, Yixuan and Koto, Fajri and Yang, Yifei and Zhao, Hai and Gong, Yeyun and Duan, Nan and Baldwin, Timothy , booktitle =
-
[41]
International Conference on Learning Representations (ICLR) , year =
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations (ICLR) , year =
-
[42]
Advances in Neural Information Processing Systems , volume=
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and others , booktitle =
-
[44]
Zhong, Wanjun and Cui, Ruixiang and Liang, Sai and others , booktitle =
-
[45]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Have llms advanced enough? a challenging problem solving benchmark for large language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[46]
2025 , eprint=
dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model , author=. 2025 , eprint=
2025
-
[47]
2026 , eprint=
Multimodal OCR: Parse Anything from Documents , author=. 2026 , eprint=
2026
-
[48]
A survey on llm-as-a-judge , author=. arXiv preprint arXiv:2411.15594 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent
Huang, Zhen and Wang, Zengzhi and Xia, Shijie and Li, Xuefeng and Zou, Haoyang and Xu, Ruijie and Fan, Run-Ze and Ye, Lyumanshan and Chern, Ethan and Ye, Yixin and others , journal =. OlympicArena: Benchmarking Multi-discipline Cognitive Reasoning for Superintelligent
-
[50]
Gao, Bofei and Song, Feifan and Yang, Zhe and Cai, Zefan and Miao, Yibo and Dong, Qingxiu and Li, Lei and Ma, Chenghao and Chen, Liang and Xu, Runxin and others , journal =. Omni-
-
[51]
arXiv preprint arXiv:2509.18383 , year=
Godel Test: Can Large Language Models Solve Easy Conjectures? , author=. arXiv preprint arXiv:2509.18383 , year=
-
[52]
2013 , howpublished =
Gillespie, Maria , title =. 2013 , howpublished =
2013
-
[53]
Proceedings of the European Conference on Information Retrieval (ECIR) , year =
Advancing Math Formula Search Using Diverse Structural Features , author =. Proceedings of the European Conference on Information Retrieval (ECIR) , year =
-
[54]
Findings of the Association for Computational Linguistics (ACL) , year =
Reasoning in Large Language Models Through Symbolic Math Word Problems , author =. Findings of the Association for Computational Linguistics (ACL) , year =
-
[55]
arXiv preprint arXiv:2508.17580 , year=
UQ: Assessing Language Models on Unsolved Questions , author=. arXiv preprint arXiv:2508.17580 , year=
-
[56]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
Matharena: Evaluating llms on uncontaminated math competitions , author=. arXiv preprint arXiv:2505.23281 , year=
work page internal anchor Pith review arXiv
-
[57]
Leveraging online olympiad-level math problems for llms training and contamination-resistant evaluation , author=. arXiv preprint arXiv:2501.14275 , year=
-
[58]
International Conference of the Cross-Language Evaluation Forum for European Languages , pages=
Overview of ARQMath 2020: CLEF lab on answer retrieval for questions on math , author=. International Conference of the Cross-Language Evaluation Forum for European Languages , pages=. 2020 , organization=
2020
-
[59]
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models
Challenging the Boundaries of Reasoning: An Olympiad-Level Math Benchmark for Large Language Models , author=. arXiv preprint arXiv:2503.21380 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Towards Robust Mathematical Reasoning , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[61]
Solving inequality proofs with large language models.CoRR, abs/2506.07927, 2025
Solving Inequality Proofs with Large Language Models , author=. arXiv preprint arXiv:2506.07927 , year=
-
[62]
Deepseekmath-v2: Towards self-verifiable mathematical reasoning,
DeepSeekMath-V2: Towards Self-Verifiable Mathematical Reasoning , author=. arXiv preprint arXiv:2511.22570 , year=
-
[63]
European Conference on Information Retrieval , pages=
Advancing Math Formula Search Using Diverse Structural and Symbolic Representations , author=. European Conference on Information Retrieval , pages=. 2025 , organization=
2025
-
[64]
arXiv preprint arXiv:2105.00377 , year=
Mathbert: A pre-trained model for mathematical formula understanding , author=. arXiv preprint arXiv:2105.00377 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.