Recognition: unknown
SpikeMLLM: Spike-based Multimodal Large Language Models via Modality-Specific Temporal Scales and Temporal Compression
Pith reviewed 2026-05-10 16:25 UTC · model grok-4.3
The pith
SpikeMLLM turns multimodal LLMs into spiking networks that keep near-original accuracy while slashing timesteps and energy use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
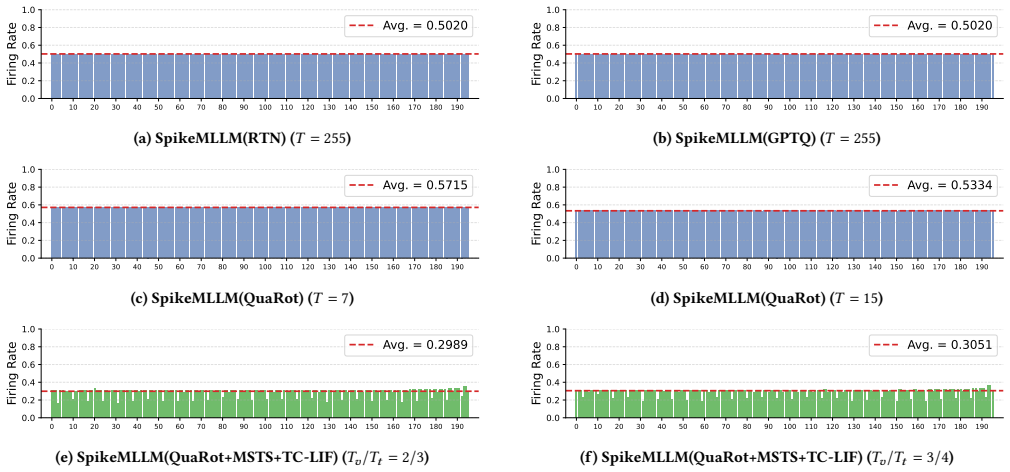
SpikeMLLM unifies existing ANN quantization methods inside the spiking representation space and adds Modality-Specific Temporal Scales guided by Modality Evolution Discrepancy together with Temporally Compressed LIF neurons; this combination reduces timestep count from L-1 to log2(L)-1 while the resulting models retain near-lossless performance on multimodal tasks and run efficiently on neuromorphic-style accelerators.
What carries the argument
Modality-Specific Temporal Scales (MSTS) guided by Modality Evolution Discrepancy (MED) paired with Temporally Compressed LIF (TC-LIF) neurons; these assign modality-appropriate spike rates and collapse the number of simulation steps required for each forward pass.
If this is right
- Performance gaps stay below 0.72 percent on InternVL2-8B and 1.19 percent on Qwen2VL-72B even after reducing timestep count to three-quarters of the original length.
- A dedicated RTL accelerator built for the spike datapath delivers 9.06 times higher throughput and 25.8 times better power efficiency than an FP16 GPU baseline.
- The approach opens deployment of large multimodal models on power-limited or edge neuromorphic hardware without retraining from scratch.
Where Pith is reading between the lines
- The same modality-aware timing rule could be applied to other spiking pipelines that mix continuous and discrete signals.
- Combining the temporal compression with additional event sparsity techniques would likely push energy savings further on real neuromorphic chips.
- Hardware-algorithm co-design of this form may become standard for making any large multimodal system run on low-power substrates.
Load-bearing premise
The benchmarks used are sensitive enough to reveal any loss of cross-modal reasoning that the spiking conversion and compression might introduce.
What would settle it
Test the same converted models on a new multimodal task that demands fine-grained temporal alignment across modalities, such as counting events in synchronized video-audio clips, and check whether the accuracy gap widens beyond the one-percent range reported.
Figures










read the original abstract
Multimodal Large Language Models (MLLMs) have achieved remarkable progress but incur substantial computational overhead and energy consumption during inference, limiting deployment in resource-constrained environments. Spiking Neural Networks (SNNs), with their sparse event-driven computation, offer inherent energy efficiency advantages on neuromorphic hardware, yet extending them to MLLMs faces two key challenges: heterogeneous modalities make uniform spike encoding insufficient, and high-resolution image inputs amplify timestep unfolding overhead. We propose SpikeMLLM, the first spike-based framework for MLLMs, which unifies existing ANN quantization methods in the spiking representation space and incorporates Modality-Specific Temporal Scales (MSTS) guided by Modality Evolution Discrepancy (MED) and Temporally Compressed LIF (TC-LIF) for timestep compression from T=L-1 to T=log2(L)-1. Experiments on four representative MLLMs across diverse multimodal benchmarks show that SpikeMLLM maintains near-lossless performance under aggressive timestep compression (Tv/Tt=3/4), with average gaps of only 0.72% and 1.19% relative to the FP16 baseline on InternVL2-8B and Qwen2VL-72B. We further develop a dedicated RTL accelerator tailored to the spike-driven datapath, observing 9.06x higher throughput and 25.8x better power efficiency relative to an FP16 GPU baseline under a deployment-oriented co-design setting, suggesting the promise of algorithm-hardware co-design for efficient multimodal intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpikeMLLM, the first spike-based framework for multimodal large language models. It unifies ANN quantization methods into the spiking domain and adds two components: Modality-Specific Temporal Scales (MSTS) guided by Modality Evolution Discrepancy (MED) and Temporally Compressed LIF (TC-LIF) neurons that reduce timesteps from T = L-1 to T = log2(L)-1. Experiments on four MLLMs (including InternVL2-8B and Qwen2VL-72B) across multimodal benchmarks report near-lossless accuracy under Tv/Tt = 3/4 compression (average gaps 0.72 % and 1.19 % vs. FP16), together with a custom RTL accelerator delivering 9.06× throughput and 25.8× power-efficiency gains over an FP16 GPU baseline.
Significance. If the empirical claims hold after the requested clarifications, the work would be significant for energy-efficient deployment of large multimodal models on neuromorphic hardware. The algorithm-hardware co-design, including the dedicated RTL datapath, is a concrete strength that goes beyond pure algorithmic conversion and provides measurable efficiency numbers.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the reported 0.72 % and 1.19 % average gaps are aggregate figures only. No per-task variance, no breakdown by cross-modal reasoning subtasks, and no spike-rate alignment metrics are supplied, leaving open the possibility that modality desynchronization under MSTS is masked by the averaging.
- [Methods] Methods section (MSTS and TC-LIF definitions): the claim that MSTS guided by MED plus TC-LIF compression preserves cross-modal temporal correspondence rests on the assumption that vision and text spikes remain aligned for attention; the manuscript provides no explicit analysis or ablation of spike-timing statistics between modalities at Tv/Tt = 3/4.
- [Experiments] Experiments section: the paper does not report an ablation comparing MSTS against a uniform temporal scale across modalities. Such a control is load-bearing for the central claim that modality-specific scales are required to achieve the near-lossless result.
minor comments (2)
- [Abstract] The acronym MED is introduced in the abstract without expansion.
- [Hardware section] The hardware results would be strengthened by reporting the exact FPGA or ASIC technology node and the area overhead of the RTL accelerator.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on our work introducing SpikeMLLM. We address each major comment in detail below, committing to revisions that enhance the clarity and robustness of our claims regarding performance preservation and the role of MSTS.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the reported 0.72 % and 1.19 % average gaps are aggregate figures only. No per-task variance, no breakdown by cross-modal reasoning subtasks, and no spike-rate alignment metrics are supplied, leaving open the possibility that modality desynchronization under MSTS is masked by the averaging.
Authors: We thank the referee for highlighting this. While the primary results focus on aggregate performance to demonstrate overall near-lossless behavior, we recognize the value of detailed breakdowns. In the revised manuscript, we will include per-task accuracy tables with variance, breakdowns for cross-modal reasoning subtasks, and spike-rate alignment metrics to explicitly address potential modality desynchronization concerns. revision: yes
-
Referee: [Methods] Methods section (MSTS and TC-LIF definitions): the claim that MSTS guided by MED plus TC-LIF compression preserves cross-modal temporal correspondence rests on the assumption that vision and text spikes remain aligned for attention; the manuscript provides no explicit analysis or ablation of spike-timing statistics between modalities at Tv/Tt = 3/4.
Authors: The near-lossless performance on multimodal benchmarks serves as indirect evidence for preserved temporal correspondence. Nevertheless, to directly validate the assumption, we will incorporate an explicit analysis of spike-timing statistics and inter-modality alignment at the compressed timestep ratio in the revised Methods and Experiments sections. revision: yes
-
Referee: [Experiments] Experiments section: the paper does not report an ablation comparing MSTS against a uniform temporal scale across modalities. Such a control is load-bearing for the central claim that modality-specific scales are required to achieve the near-lossless result.
Authors: We agree that an ablation study comparing MSTS to a uniform temporal scale is essential to substantiate the necessity of modality-specific scales. We will add this ablation experiment, including quantitative comparisons on the same benchmarks, to the revised Experiments section. revision: yes
Circularity Check
No circularity; empirical framework validated on external benchmarks
full rationale
The paper introduces SpikeMLLM as an algorithmic framework that unifies ANN quantization methods into spiking representations, adds Modality-Specific Temporal Scales guided by Modality Evolution Discrepancy, and applies Temporally Compressed LIF for timestep reduction. All load-bearing claims rest on direct experimental measurements across four MLLMs and diverse multimodal benchmarks, reporting concrete performance gaps (0.72% and 1.19%) and hardware metrics relative to FP16 baselines. No equations, parameters, or uniqueness theorems are defined in terms of the target outputs, no self-citations serve as load-bearing premises, and no fitted quantities are relabeled as predictions. The derivation chain is therefore self-contained and externally falsifiable.
Axiom & Free-Parameter Ledger
free parameters (1)
- Timestep compression ratio Tv/Tt =
3/4
axioms (1)
- domain assumption Spiking neural networks can unify ANN quantization methods in the spiking representation space without loss of representational power
invented entities (2)
-
Modality-Specific Temporal Scales (MSTS)
no independent evidence
-
Temporally Compressed LIF (TC-LIF)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
SpikingBrain2.0: Brain-Inspired Foundation Models for Efficient Long-Context and Cross-Platform Inference
SpikingBrain2.0 is a 5B hybrid spiking-Transformer that recovers most base model performance while delivering 10x TTFT speedup at 4M context and supporting over 10M tokens on limited GPUs via dual sparse attention and...
Reference graph
Works this paper leans on
-
[1]
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. 2024. QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs. InAdvances in Neural Information Processing Systems, Vol. 37
2024
-
[2]
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Frontier Large Vision- Language Model with Versatile Abilities.arXiv preprint arXiv:2308.12966(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Malyaban Bal and Abhronil Sengupta. 2024. SpikingBERT: Distilling BERT to Train Spiking Language Models Using Implicit Differentiation. InAAAI Confer- ence on Artificial Intelligence. 8
2024
-
[4]
Yongqiang Cao, Yang Chen, and Deepak Khosla. 2015. Spiking Deep Convolu- tional Neural Networks for Energy-Efficient Object Recognition.International Journal of Computer Vision113, 1 (2015), 54–66
2015
-
[5]
Guoming Chen, Zhuoxian Qian, Dong Zhang, Shuang Qiu, and Ruqi Zhou. 2025. Enhancing Robustness Against Adversarial Attacks in Multimodal Emotion Recognition with Spiking Transformers.IEEE Access(2025)
2025
-
[6]
Zhe Chen, Weiyun Wang, Hao Tian, Shenglong Ye, Zhangwei Gao, Erfei Cui, Wenwen Tong, Kongzhi Hu, Jiapeng Luo, Zheng Ma, et al. 2024. How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open- Source Suites.arXiv preprint arXiv:2404.16821
work page internal anchor Pith review arXiv 2024
-
[7]
Mike Davies et al. 2018. Loihi: A neuromorphic manycore processor with on-chip learning.IEEE Micro38, 1 (2018), 82–99
2018
-
[8]
Jason K Eshraghian, Max Ward, Emre O Neftci, Xinxin Wang, Gregor Lenz, Girish Dwivedi, Mohammed Bennamoun, Doo Seok Jeong, and Wei D Lu. 2023. Training spiking neural networks using lessons from deep learning.Proc. IEEE 111, 9 (2023), 1016–1054
2023
-
[9]
Wei Fang, Yanqi Chen, Jianhao Ding, Zhaofei Yu, Timothée Masquelier, Ding Chen, Liwei Huang, Huihui Zhou, Guoqi Li, and Yonghong Tian. 2023. Spiking- jelly: An open-source machine learning infrastructure platform for spike-based intelligence.Science Advances9, 40 (2023), eadi1480
2023
-
[10]
Wei Fang, Zhaofei Yu, Yanqi Chen, Timothée Masquelier Huang, and Yonghong Tian. 2021. Deep residual learning in spiking neural networks.Advances in Neural Information Processing Systems34 (2021), 21056–21069
2021
-
[11]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2023. GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. InInternational Conference on Learning Representations
2023
-
[12]
Charlotte Frenkel, David Bol, and Giacomo Indiveri. 2023. Bottom-up and top- down approaches for the design of neuromorphic processing systems: Tradeoffs and synergies between natural and artificial intelligence.Proc. IEEE111, 9 (2023), 1490–1514. doi:10.1109/JPROC.2023.3272498
-
[13]
Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. 2023. MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models.arXiv preprint arXiv:2306.13394(2023)
work page internal anchor Pith review arXiv 2023
-
[14]
Lingyue Guo, Zeyu Gao, Jinye Qu, Suiwu Zheng, Runhao Jiang, Yanfeng Lu, and Hong Qiao. 2023. Transformer-based spiking neural networks for multimodal audiovisual classification.IEEE Transactions on Cognitive and Developmental Systems16, 3 (2023), 1077–1086
2023
-
[15]
Ming Guo, Wenrui Li, Chao Wang, Yuxin Ge, and Chongjun Wang. 2024. SMILE: Spiking multi-modal interactive label-guided enhancement network for emotion recognition. InIEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6
2024
-
[16]
Yufei Guo, Yuanpei Chen, Xiaode Liu, Weihang Peng, Yuhan Zhang, Xuhui Huang, and Zhe Ma. 2024. Ternary Spike: Learning Ternary Spikes for Spiking Neural Networks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 12244–12252
2024
- [17]
- [18]
-
[19]
Yifan Hu, Huajin Tang, and Gang Pan. 2023. Spiking deep residual networks.IEEE Transactions on Neural Networks and Learning Systems34, 8 (2023), 5200–5205
2023
-
[20]
Yang-Zhi Hu, Qian Zheng, Xudong Jiang, and Gang Pan. 2023. Fast-SNN: Fast Spiking Neural Network by Converting Quantized ANN.IEEE Transactions on Pattern Analysis and Machine Intelligence45 (2023), 14546–14562
2023
-
[21]
Intel Labs. 2021. Taking Neuromorphic Computing to the Next Level with Loihi
2021
-
[22]
Accessed: 2026-01-13
https://download.intel.com/newsroom/2021/neuromorphic-computing-loihi- 2-brief.pdf. Accessed: 2026-01-13
2021
-
[23]
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, An- drew Howard, Hartwig Adam, and Dmitry Kalenichenko. 2018. Quantization and training of neural networks for efficient integer-arithmetic-only inference. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2704–2713
2018
-
[24]
Vineyard, Tej Pandit, Cory Merkel, Rajkumar Kubendran, James B
Dhireesha Kudithipudi, Catherine Schuman, Craig M. Vineyard, Tej Pandit, Cory Merkel, Rajkumar Kubendran, James B. Aimone, Garrick Orchard, Christian Mayr, Ryad Benosman, Joe Hays, Cliff Young, Chiara Bartolozzi, Amitava Ma- jumdar, Suma George Cardwell, Melika Payvand, Sonia Buckley, Shruti Kulkarni, Hector A. Gonzalez, Gert Cauwenberghs, Chetan Singh Th...
2025
-
[25]
Zhenxin Lei, Man Yao, Jiakui Hu, Xinhao Luo, Yanye Lu, Bo Xu, and Guoqi Li
-
[26]
InProceedings of the AAAI Conference on Artificial Intelligence, Vol
Spike2Former: Efficient Spiking Transformer for High-performance Image Segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 1364–1372
-
[27]
Guoqi Li, Lei Deng, Huajing Tang, Gang Pan, Yonghong Tian, Kaushik Roy, and Wolfgang Maass. 2023. Brain inspired computing: A systematic survey and future trends.Authorea Preprints(2023)
2023
-
[28]
Shiyao Li, Yingchun Hu, Xuefei Ning, Xihui Liu, Ke Hong, Xiaotao Jia, Xiuhong Li, Yaqi Yan, Pei Ran, Guohao Dai, Shengen Yan, Huazhong Yang, and Yu Wang
-
[29]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
MBQ: Modality-Balanced Quantization for Large Vision-Language Mod- els. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
-
[30]
Qianhui Liu, Dong Xing, Lang Feng, Huajin Tang, and Gang Pan. 2022. Event- based multimodal spiking neural network with attention mechanism. InICASSP. IEEE, 8922–8926
2022
-
[31]
Xu Liu, Na Xia, Jinxing Zhou, Zhangbin Li, and Dan Guo. 2025. Towards Energy- efficient Audio-visual Classification via Multimodal Interactive Spiking Neural Network.ACM Transactions on Multimedia Computing, Communications, and Applications(2025). doi:10.1145/3721981
-
[32]
Yuliang Liu, Zhang Li, Mingxin Huang, Biao Yang, Wenwen Yu, Chunyuan Li, Xu- Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. 2024. OCRBench: on the hidden mystery of OCR in large multimodal models.Science China Information Sciences67, 12 (2024). doi:10.1007/s11432-024-4235-6
-
[33]
Zechun Liu, Wenhan Luo, Baoyuan Wu, Xiaoyan Yang, Wei Liu, and Kwang-Ting Cheng. 2020. Bi-Real Net: Binarizing Deep Network Towards Real-Network Performance.International Journal of Computer Vision128 (2020), 202–219
2020
-
[34]
Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, and Vikas Chandra. 2024. LLM-QAT: Data-Free Quantization Aware Training for Large Language Models. InFindings of the Association for Computational Linguistics: ACL 2024. 467–484
2024
-
[35]
Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, Kai-Wei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022. Learn to explain: Multimodal reasoning via thought chains for science question answering.Ad- vances in Neural Information Processing Systems35 (2022), 2507–2521
2022
-
[36]
Xinhao Luo, Man Yao, Yuhong Chou, Bo Xu, and Guoqi Li. 2024. Integer- Valued Training and Spike-Driven Inference Spiking Neural Network for High- Performance and Energy-Efficient Object Detection. InEuropean Conference on Computer Vision. Springer, 253–272
2024
-
[37]
Shixian Ma, Jing Pei, Wenxin Zhang, et al . 2022. Neuromorphic computing chip with spatiotemporal elasticity for multi-intelligent-tasking robots.Science Robotics7 (2022), eabk2948
2022
-
[38]
Wolfgang Maass. 1997. Networks of spiking neurons: the third generation of neural network models.Neural networks10, 9 (1997), 1659–1671
1997
-
[39]
Minesh Mathew, Dimosthenis Karatzas, and CV Jawahar. 2021. DocVQA: A dataset for VQA on document images. InW ACV. 2200–2209
2021
-
[40]
Paul A Merolla, John V Arthur, Rodrigo Alvarez-Icaza, Andrew S Cassidy, et al
-
[41]
A million spiking-neuron integrated circuit with a scalable communication network and interface.Science345 (2014), 668–673
2014
-
[42]
IEEE Signal Processing Magazine 36, 51–63
Emre O. Neftci, Hesham Mostafa, and Friedemann Zenke. 2019. Surrogate Gradient Learning in Spiking Neural Networks: Bringing the Power of Gradient- Based Optimization to Spiking Neural Networks.IEEE Signal Processing Magazine 36, 6 (2019), 51–63. doi:10.1109/MSP.2019.2931595
-
[43]
Jing Pei et al. 2019. Towards artificial general intelligence with hybrid Tianjic chip architecture.Nature572 (2019), 106–111
2019
-
[44]
Michael Pfeiffer and Thomas Pfeil. 2018. Deep Learning With Spiking Neurons: Opportunities and Challenges.Frontiers in Neuroscience12 (2018), 774
2018
-
[45]
Nitin Rathi, Gopalakrishnan Srinivasan, Priyadarshini Panda, and Kaushik Roy
-
[46]
InInternational Conference on Learning Representations
Enabling deep spiking neural networks with hybrid conversion and spike timing dependent backpropagation. InInternational Conference on Learning Representations
-
[47]
Kaushik Roy, Akhilesh Jaiswal, and Priyadarshini Panda. 2019. Towards spike- based machine intelligence with neuromorphic computing.Nature575, 7784 (2019), 607–617
2019
-
[48]
Catherine D. Schuman, Shruti R. Kulkarni, Maryam Parsa, J. Parker Mitchell, Bill Kay, et al. 2022. Opportunities for neuromorphic computing algorithms and applications.Nature Computational Science2, 1 (2022), 10–19. doi:10.1038/s43588- 021-00174-0
-
[49]
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. 2019. Towards VQA models that can read. InCVPR. 8317–8326
2019
-
[50]
Hongze Sun, Rui Liu, Wuque Cai, Jun Wang, Yue Wang, Huajin Tang, Yan Cui, Dezhong Yao, and Daqing Guo. 2024. Reliable object tracking by multimodal hybrid feature extraction and transformer-based fusion.Neural Networks178 (2024), 106493
2024
-
[51]
Clarence Tan, Gerardo Ceballos, Nikola Kasabov, and Narayan Puthanmadam Subramaniyam. 2020. FusionSense: Emotion classification using feature fusion of multimodal data and deep learning in a brain-inspired spiking neural network. Sensors20, 18 (2020), 5328
2020
-
[52]
Amirhossein Tavanaei, Masoud Ghodrati, Saeed Reza Kheradpisheh, Timothée Masquelier, and Anthony Maida. 2019. Deep learning in spiking neural networks. Neural Networks111 (2019), 47–63. doi:10.1016/j.neunet.2018.12.002
-
[53]
Sadia Anjum Tumpa, Anusha Devulapally, Matthew Brehove, Espoir Kyubwa, and Vijaykrishnan Narayanan. 2024. SNN-ANN Hybrid Networks for Embedded Multimodal Monocular Depth Estimation. In2024 IEEE Computer Society Annual 9 Symposium on VLSI (ISVLSI). IEEE, 198–203
2024
-
[54]
Huizheng Wang, Zichuan Wang, Zhiheng Yue, Yousheng Long, Taiquan Wei, Jianxun Yang, Yang Wang, Chao Li, Shaojun Wei, Yang Hu, and Shouyi Yin. 2025. MCBP: A Memory-Compute Efficient LLM Inference Accelerator Leveraging Bit- Slice-enabled Sparsity and Repetitiveness. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture. Associatio...
-
[55]
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. 2024. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution.arXiv preprint arXiv:2409.12191(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[56]
Zhanpeng Wang, Wei Fang, Jianguo Cao, Qi Zhang, Zhenzhi Wang, and Rui Xu
-
[57]
InProceedings of the IEEE/CVF International Conference on Computer Vision
Masked spiking transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision. 1761–1771
-
[58]
Jibin Wu, Chenglin Xu, Xiao Han, Daquan Zhou, Malu Zhang, Haizhou Li, and Kay Chen Tan. 2021. Progressive tandem learning for pattern recognition with deep spiking neural networks.IEEE Transactions on Pattern Analysis and Machine Intelligence44, 11 (2021), 7824–7840
2021
-
[59]
Yujie Wu, Lei Deng, Guoqi Li, Jun Zhu, and Luping Shi. 2018. Spatio-temporal backpropagation for training high-performance spiking neural networks.Fron- tiers in Neuroscience12 (2018), 331
2018
-
[60]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. InInternational Conference on Machine Learning
2023
-
[61]
Xingrun Xing, Boyan Gao, Zheng Liu, David Clifton, Shitao Xiao, Wanpeng Zhang, Li Du, Zheng Zhang, Guoqi Li, and Jiajun Zhang. 2025. SpikeLLM: Scaling up Spiking Neural Network to Large Language Models via Saliency- based Spiking. InInternational Conference on Learning Representations
2025
-
[62]
Xingrun Xing, Zheng Zhang, Ziyi Ni, Shitao Xiao, Yiming Ju, Siqi Fan, Yequan Wang, Jiajun Zhang, and Guoqi Li. 2024. SpikeLM: Towards General Spike- Driven Language Modeling via Elastic Bi-Spiking Mechanisms. InInternational Conference on Machine Learning
2024
-
[63]
Han Xu, Xuerui Qiu, Yunhui Xu, Mohammed E. Elbitty, Peng Zhou, Yang Tian, Rui-Jie Zhu, Jiahong Zhang, Shaowei Gu, Yuqi Pan, Yuhong Chou, Qinghao Wen, Man Yao, Jiangbo Qian, Yonghong Tian, Lei Ma, Tiejun Huang, Jason K. Eshraghian, Bo Xu, and Guoqi Li. 2025. Neuromorphic Spike-Based Large Lan- guage Model.National Science Review(2025), nwaf551. doi:10.1093...
-
[64]
Sheng Xu, Yuhang Li, Ming Lin, Peng Gao, Guodong Guo, Jianhua Lü, and Baoyuan Zhang. 2023. Q-DETR: An Efficient Low-bit Quantized Detection Transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 3842–3851
2023
-
[65]
Man Yao, JiaKui Hu, Tianxiang Hu, Yifan Xu, Zhaokun Zhou, Yonghong Tian, Bo XU, and Guoqi Li. 2024. Spike-driven Transformer V2: Meta Spiking Neural Network Architecture Inspiring the Design of Next-generation Neuromorphic Chips. InThe Twelfth International Conference on Learning Representations. https: //openreview.net/forum?id=1SIBN5Xyw7
2024
-
[66]
Man Yao, Xuerui Qiu, Tianxiang Hu, Jiakui Hu, Yuhong Chou, Keyu Tian, Jianxing Liao, Luziwei Leng, Bo Xu, and Guoqi Li. 2025. Scaling Spike-driven Transformer with Efficient Spike Firing Approximation Training.IEEE Transactions on Pattern Analysis and Machine Intelligence (IEEE TPAMI)(2025)
2025
-
[67]
Man Yao, Ole Richter, Guangshe Zhao, Ning Qiao, Yannan Xing, Dingheng Wang, et al. 2024. Spike-based dynamic computing with asynchronous sensing- computing neuromorphic chip.Nature Communications15 (2024), 4464
2024
-
[68]
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. 2024. MiniCPM-V: A GPT-4V Level MLLM on Your Phone.arXiv preprint arXiv:2408.01800(2024)
work page internal anchor Pith review arXiv 2024
-
[69]
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. 2024. A survey on multimodal large language models.National Science Review11, 12 (2024), nwae403
2024
-
[70]
Hanle Zheng, Yujie Wu, Lei Deng, Yifan Hu, and Guoqi Li. 2021. Going deeper with directly-trained larger spiking neural networks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 11062–11070
2021
-
[71]
Shibo Zhou, Bo Yang, Mengwen Yuan, Runhao Jiang, Rui Yan, Gang Pan, and Huajin Tang. 2024. Enhancing SNN-based spatio-temporal learning: A bench- mark dataset and cross-modality attention model.Neural Networks180 (2024), 106677
2024
-
[72]
Eshraghian
Rui-Jie Zhu, Yu Zhang, Steven Abreu, Ethan Sifferman, Tyler Sheaves, Yiqiao Wang, Dustin Richmond, Sumit Bam Shrestha, Peng Zhou, and Jason K. Eshraghian. 2024. Scalable MatMul-free Language Modeling.Transactions on Machine Learning Research(2024)
2024
-
[73]
Eshraghian
Rui-Jie Zhu, Qihang Zhao, Guoqi Li, and Jason K. Eshraghian. 2024. SpikeGPT: Generative Pre-trained Language Model with Spiking Neural Networks.Trans- actions on Machine Learning Research(2024). 10 Supplementary Materials: SpikeMLLM: Spike-based Multimodal Large Language Models via Modality-Specific Temporal Scales and Temporal Compression Han Xu1,2,3,† Z...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.