Easy Samples Are All You Need: Self-Evolving LLMs via Data-Efficient Reinforcement Learning
Pith reviewed 2026-05-10 06:28 UTC · model grok-4.3
The pith
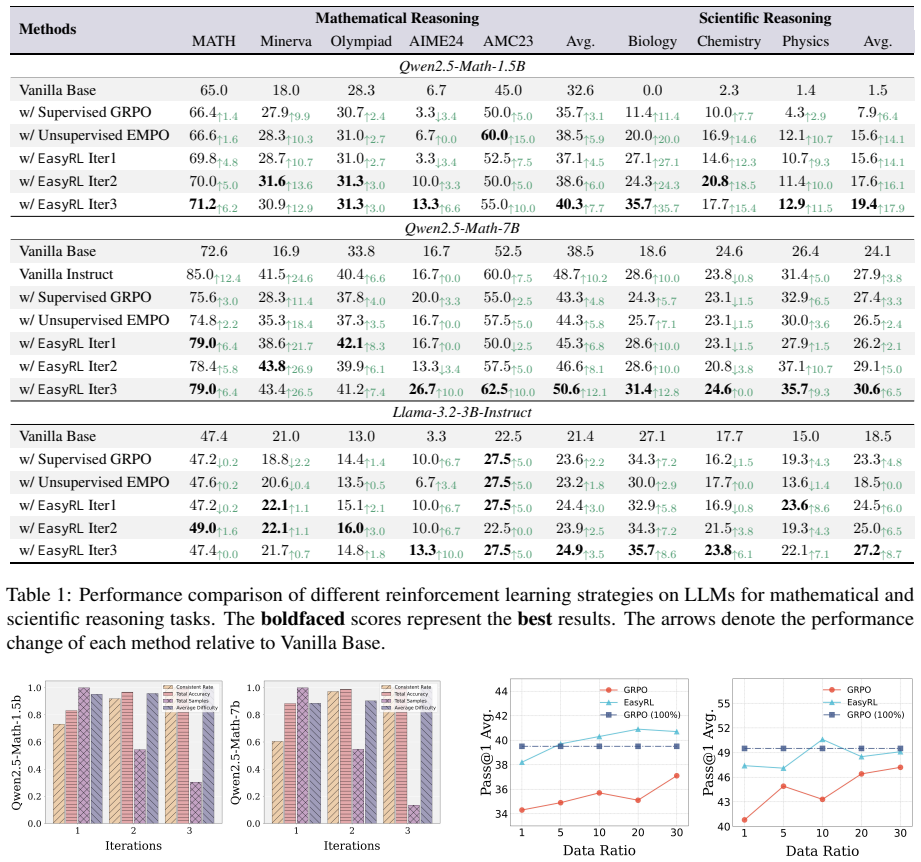
EasyRL lets LLMs self-evolve and beat baselines on math and science tasks using just 10 percent easy labeled data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
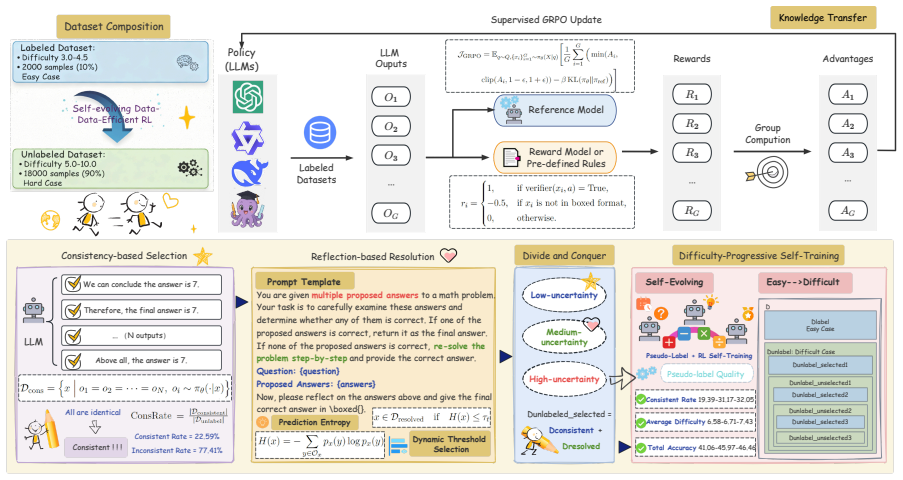
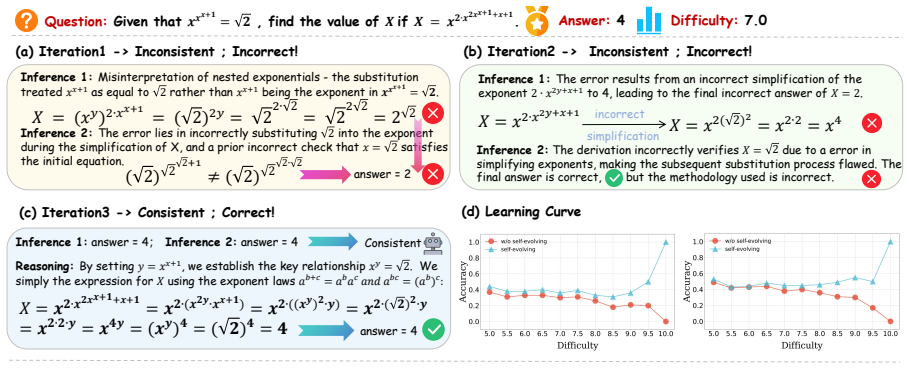
EasyRL warms up an initial model via supervised RL on few-shot easy labeled data, applies a divide-and-conquer pseudo-labeling step on unlabeled data that uses consistency-based selection for low-uncertainty cases and reflection-based resolution for medium-uncertainty cases, and then runs iterative difficulty-progressive self-training to strengthen reasoning capability on mathematical and scientific benchmarks.
What carries the argument
A divide-and-conquer pseudo-labeling strategy that combines consistency checks on easy unlabeled cases with reflection on medium-uncertainty cases, embedded inside an iterative self-training loop that advances from easy to harder data.
If this is right
- Annotation effort for post-training can drop to roughly one-tenth while still exceeding current supervised and unsupervised baselines.
- Starting from easy samples provides a stable base that prevents the model collapse observed in voting- or entropy-only reward schemes.
- The same pipeline supplies a single framework for data-efficient reinforcement learning across both mathematical and scientific reasoning tasks.
- Progressive handling of unlabeled data lets performance keep rising without requiring new human labels at each stage.
Where Pith is reading between the lines
- The same easy-to-hard progression could be tested on coding or multi-step planning tasks where difficulty also varies naturally.
- If the initial easy sample set is poorly chosen, the entire bootstrap process may stall before reaching harder examples.
- Removing the reflection step for medium-uncertainty cases might still work on some domains but would likely increase error accumulation on others.
Load-bearing premise
That the pseudo-labels created from consistency and reflection steps on unlabeled data stay accurate enough across iterations and do not introduce errors that grow worse over time.
What would settle it
An experiment in which EasyRL is run on a math benchmark and the model's accuracy on medium-difficulty problems falls below the warm-up model's level after two or three self-training rounds due to accumulating incorrect pseudo-labels.
Figures

read the original abstract
Previous LLMs-based RL studies typically follow either supervised learning with high annotation costs, or unsupervised paradigms using voting or entropy-based rewards. However, their performance remains far from satisfactory due to the substantial annotation cost and issues such as model collapse or reward hacking. To address these issues, we introduce a new perspective inspired by cognitive learning theory and propose a novel approach called EasyRL. The core of EasyRL is to simulate the human cognitive acquisition curve by integrating reliable knowledge transfer from easy labeled data with a progressive divide-and-conquer strategy that tackles increasingly difficult unlabeled data. Specifically, we initialize a warm-up model using supervised RL with few-shot labeled data. This is followed by a divide-and-conquer pseudo-labeling strategy on difficult unlabeled data, combining consistency-based selection for low-uncertainty cases and reflection-based resolution for medium-uncertainty cases. Finally, difficulty-progressive self-training with iterative pseudo-labeling and RL further strengthens the model's reasoning capability. EasyRL provides a unified self-evolving framework that facilitates data-efficient post-training of LLMs. Experimental results on mathematical and scientific benchmarks demonstrate that EasyRL, using only 10% of easy labeled data, consistently outperforms state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EasyRL, a self-evolving framework for data-efficient RL post-training of LLMs. It begins with supervised RL warm-up on a small fraction (claimed 10%) of easy labeled data, applies a divide-and-conquer pseudo-labeling strategy on unlabeled data that uses consistency-based selection for low-uncertainty cases and reflection-based resolution for medium-uncertainty cases, and then performs iterative difficulty-progressive self-training. The central empirical claim is that this approach consistently outperforms state-of-the-art baselines on mathematical and scientific reasoning benchmarks while relying on far less labeled data.
Significance. If the empirical results and the underlying pseudo-label quality assumption hold, the work provides a practical route to lower annotation costs in LLM reasoning enhancement and addresses common failure modes (model collapse, reward hacking) in prior unsupervised RL paradigms. The progressive, cognitively inspired design and unified self-training loop are conceptually attractive and could influence scalable post-training methods if supported by rigorous verification of pseudo-label fidelity.
major comments (3)
- [Method (divide-and-conquer pseudo-labeling)] The divide-and-conquer pseudo-labeling strategy (described in the method) is load-bearing for the data-efficiency claim, yet the manuscript supplies no quantitative pseudo-label accuracy metrics (e.g., agreement with held-out ground truth or error rates stratified by uncertainty tier), no ablation removing the reflection component, and no analysis of error propagation across self-training iterations. Without these, it is impossible to confirm that the iterative loop improves rather than degrades performance.
- [§4 (Experiments)] §4 (Experiments): The reported outperformance on mathematical and scientific benchmarks is presented without statistical significance tests, standard deviations across runs, or explicit comparison of total labeled-plus-unlabeled data volume against baselines, weakening the claim that EasyRL achieves superior results with only 10% easy labeled data.
- [Method (consistency and reflection)] The consistency-based selection and reflection-based resolution are asserted to produce sufficiently accurate pseudo-labels for progressive RL, but no validation experiment or sensitivity analysis tests this axiom directly; if reflection fails on medium-uncertainty cases, the self-training loop risks confirmation bias.
minor comments (2)
- [Abstract] The abstract states '10% of easy labeled data' without defining how 'easy' samples are identified or what the total pool size is, which should be clarified for reproducibility.
- [Method] Notation for uncertainty thresholds and the exact RL objective in the self-training phase could be made more precise to aid implementation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects for strengthening the empirical support of EasyRL. We address each major comment point by point below, committing to revisions that add the requested analyses and metrics without altering the core claims or methodology.
read point-by-point responses
-
Referee: [Method (divide-and-conquer pseudo-labeling)] The divide-and-conquer pseudo-labeling strategy (described in the method) is load-bearing for the data-efficiency claim, yet the manuscript supplies no quantitative pseudo-label accuracy metrics (e.g., agreement with held-out ground truth or error rates stratified by uncertainty tier), no ablation removing the reflection component, and no analysis of error propagation across self-training iterations. Without these, it is impossible to confirm that the iterative loop improves rather than degrades performance.
Authors: We agree that direct quantitative validation of pseudo-label quality is necessary to substantiate the data-efficiency claims. In the revised manuscript, we will add pseudo-label accuracy metrics against held-out ground truth, reported both overall and stratified by uncertainty tier (low/medium). We will include an ablation that disables the reflection-based resolution to isolate its contribution. We will also analyze performance trajectories across self-training iterations to show net improvement and bound any error propagation effects. revision: yes
-
Referee: [§4 (Experiments)] §4 (Experiments): The reported outperformance on mathematical and scientific benchmarks is presented without statistical significance tests, standard deviations across runs, or explicit comparison of total labeled-plus-unlabeled data volume against baselines, weakening the claim that EasyRL achieves superior results with only 10% easy labeled data.
Authors: We acknowledge that the current experimental presentation lacks statistical rigor and explicit data-volume accounting. In the revision, we will report mean performance with standard deviations over multiple random seeds and include statistical significance tests (e.g., paired t-tests with p-values) for all key comparisons. We will also add a table that explicitly lists the total labeled plus unlabeled data volume consumed by EasyRL versus each baseline, clarifying the 10% labeled-data regime. revision: yes
-
Referee: [Method (consistency and reflection)] The consistency-based selection and reflection-based resolution are asserted to produce sufficiently accurate pseudo-labels for progressive RL, but no validation experiment or sensitivity analysis tests this axiom directly; if reflection fails on medium-uncertainty cases, the self-training loop risks confirmation bias.
Authors: We recognize the value of a direct test of the pseudo-labeling assumptions. The revised manuscript will contain a dedicated validation subsection that measures the accuracy of both consistency-based selection and reflection-based resolution on held-out labeled examples. We will further include a sensitivity analysis over the uncertainty thresholds used to route cases into each branch, demonstrating robustness and addressing potential confirmation-bias concerns. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a standard semi-supervised self-training pipeline: supervised RL warm-up on a small set of labeled data, followed by consistency/reflection-based pseudo-labeling of unlabeled data and iterative RL self-training. All performance claims are evaluated on external held-out mathematical and scientific benchmarks. No equations, parameter fits, or self-citations are shown that reduce any claimed result to its own inputs by construction. The iterative pseudo-labeling step is a conventional mechanism whose validity is tested empirically rather than assumed tautologically. This is the most common honest finding for papers whose central contribution is an empirical training recipe validated externally.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Easy labeled data provides reliable knowledge transfer that initializes a stable model without introducing harmful biases.
- ad hoc to paper Consistency-based selection and reflection-based resolution generate pseudo-labels of sufficient quality for medium- and low-uncertainty cases.
Forward citations
Cited by 1 Pith paper
-
EvoTrainer: Co-Evolving LLM Policies and Training Harnesses for Autonomous Agentic Reinforcement Learning
EvoTrainer co-evolves LLM policies and training harnesses via empirical feedback to match or exceed human-engineered RL on math reasoning, code generation, and long-horizon software engineering.
Reference graph
Works this paper leans on
-
[1]
For RL training, we adopt the GRPO algorithm with a maximum sequence length of 4096
All experiments are conducted with the vLLM framework on 2 x NVIDIA H200 GPUs (140GB). For RL training, we adopt the GRPO algorithm with a maximum sequence length of 4096. The training batch size is set to 8, with a mini-batch size of 2 and a micro-batch size of 1. The actor and critic are optimized using learning rates of5×10 −7 and 9×10 −6, respectively...
work page 2025
-
[2]
Therefore, the only solution is(a, b) = 1 2 , 1 2
By symmetry, if a= 1 2, then b= 1 2 is also a solution. Therefore, the only solution is(a, b) = 1 2 , 1 2 . Thus, there is only one ordered pair of positive real numbers (a, b) that satisfies the equation. The final answer is:1
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.