Recognition: unknown
Hierarchically Robust Zero-shot Vision-language Models
Pith reviewed 2026-05-10 04:21 UTC · model grok-4.3
The pith
Hierarchical embeddings and multi-level alignments make zero-shot vision-language models robust to adversarial attacks at different class levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a novel adversarial fine-tuning framework based on hierarchical embeddings and several levels of adversarially robust alignment of image-text modalities. We provide a theoretical connection between the depth of embedding in the hierarchy and the maximum viable margin size. Our model naturally realizes several margin sizes, boosting generalization of adversaries for robustification. As various trees with different parent labels can share the same leaf labels, we also consider aligning over multiple trees to boost semantic variety.
What carries the argument
Hierarchical embeddings placed at desired depths with multi-level adversarially robust image-text alignment, theoretically tied to margin size.
Load-bearing premise
That visual embeddings can be reliably placed at desired hierarchy depths and that alignment across multiple trees with shared leaf labels boosts semantic variety without inconsistencies or degrading base performance.
What would settle it
If experiments show no gain in robustness to superclass attacks compared to standard methods, or if clean accuracy drops, the approach would not hold.
Figures
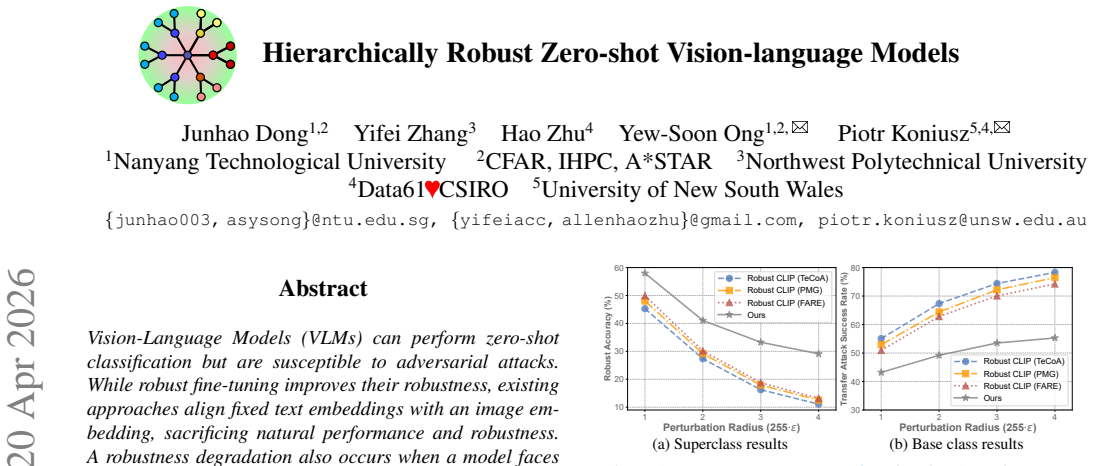







read the original abstract
Vision-Language Models (VLMs) can perform zero-shot classification but are susceptible to adversarial attacks. While robust fine-tuning improves their robustness, existing approaches align fixed text embeddings with an image embedding, sacrificing natural performance and robustness. A robustness degradation also occurs when a model faces adversarial attacks targeting superclasses (parent classes, e.g., mammal) in addition to their base (leaf) classes (e.g., cat). Thus, to enhance adversarial robustness and leverage the inherent hierarchical properties of class space, we propose a novel adversarial fine-tuning framework based on hierarchical embeddings and several levels of adversarially robust alignment of image-text modalities. Additional mechanisms place visual embeddings at the desired depth of hierarchy, and we provide a theoretical connection between the depth of embedding in the hierarchy and the maximum viable margin size. Our model naturally realizes several margin sizes, boosting generalization of adversaries for robustification. As various trees with different parent labels can share the same leaf labels, we also consider aligning over multiple trees to boost semantic variety. Experiments across several datasets are performed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel adversarial fine-tuning framework for zero-shot vision-language models (VLMs) that uses hierarchical embeddings and multi-level adversarially robust alignment of image-text modalities. It introduces additional mechanisms to place visual embeddings at chosen hierarchy depths, claims a theoretical connection between embedding depth and maximum viable margin size (allowing the model to naturally realize several margin sizes for better adversary generalization), and considers alignment over multiple trees sharing leaf labels to increase semantic variety. The approach targets robustness degradation on both leaf classes and superclasses while aiming to preserve natural performance, with experiments reported across several datasets.
Significance. If the placement mechanisms and depth-margin theoretical link can be rigorously derived and shown to preserve zero-shot capability, the work could offer a principled, hierarchy-aware route to multi-scale adversarial robustness in VLMs that avoids the performance-robustness trade-offs of standard fine-tuning. The multi-tree alignment idea, if consistent, would add a low-cost way to increase semantic coverage. These elements address a genuine gap in current robust VLM literature, but their impact hinges on verifiable implementation details and empirical gains that are not yet substantiated in the provided description.
major comments (3)
- Abstract: The central claim of a 'theoretical connection between the depth of embedding in the hierarchy and the maximum viable margin size' is asserted without any derivation, equation, or proof sketch. This link is load-bearing for the assertion that the model 'naturally realizes several margin sizes' and boosts adversary generalization; the full manuscript must supply the derivation (including any assumptions on embedding placement) to allow verification that the relation holds beyond the leaf level and is not circular.
- Abstract: The statement that 'additional mechanisms place visual embeddings at the desired depth of hierarchy' is presented without describing the concrete procedure (loss term, projection operator, constraint, or regularization). This mechanism is essential to the framework's feasibility, stability, and preservation of zero-shot performance; without it, it is impossible to assess whether the placement is reliable or introduces inconsistencies when aligning across multiple trees with shared leaf labels.
- Abstract: The multi-tree alignment claim ('aligning over multiple trees to boost semantic variety') lacks any consistency guarantee or method for handling shared leaf labels across trees with differing parent labels. This is load-bearing for the semantic-variety benefit and could otherwise degrade base-task performance or introduce label conflicts; the manuscript must provide the alignment objective and any cross-tree consistency analysis.
minor comments (1)
- Abstract: The description of experiments is limited to 'across several datasets' with no mention of specific datasets, baselines, attack types, or metrics; adding these would improve clarity even at the abstract level.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the abstract requires additional supporting details to substantiate the core claims, and we will revise the manuscript to include the requested derivations, procedural descriptions, and consistency analysis. Our responses to each major comment are provided below.
read point-by-point responses
-
Referee: Abstract: The central claim of a 'theoretical connection between the depth of embedding in the hierarchy and the maximum viable margin size' is asserted without any derivation, equation, or proof sketch. This link is load-bearing for the assertion that the model 'naturally realizes several margin sizes' and boosts adversary generalization; the full manuscript must supply the derivation (including any assumptions on embedding placement) to allow verification that the relation holds beyond the leaf level and is not circular.
Authors: We agree that a self-contained derivation is essential. The full manuscript contains a theoretical analysis deriving the depth-margin relationship from the hierarchical embedding constraints and the adversarial objective, but we will add an explicit proof sketch (with equations) to the abstract and expand the assumptions in Section 3. The derivation starts from the placement of embeddings at tree depths and uses margin bounds induced by the hierarchy levels; it is grounded in the loss formulation rather than being circular. We will also verify and state its extension to superclass attacks. revision: yes
-
Referee: Abstract: The statement that 'additional mechanisms place visual embeddings at the desired depth of hierarchy' is presented without describing the concrete procedure (loss term, projection operator, constraint, or regularization). This mechanism is essential to the framework's feasibility, stability, and preservation of zero-shot performance; without it, it is impossible to assess whether the placement is reliable or introduces inconsistencies when aligning across multiple trees with shared leaf labels.
Authors: We will provide the concrete implementation details in the revised methods section. The placement uses a depth-conditioned projection operator combined with a regularization term in the overall loss that enforces embedding proximity to the target hierarchy depth. We will include the exact mathematical formulation, stability analysis, and empirical checks confirming that zero-shot performance is preserved and that the mechanism remains consistent under multi-tree alignment. revision: yes
-
Referee: Abstract: The multi-tree alignment claim ('aligning over multiple trees to boost semantic variety') lacks any consistency guarantee or method for handling shared leaf labels across trees with differing parent labels. This is load-bearing for the semantic-variety benefit and could otherwise degrade base-task performance or introduce label conflicts; the manuscript must provide the alignment objective and any cross-tree consistency analysis.
Authors: We will expand the multi-tree alignment description to include the full objective function and a cross-tree consistency constraint that reconciles shared leaf embeddings while respecting differing parent labels (via label-aware averaging in the alignment loss). A consistency analysis will be added showing that semantic variety increases without label conflicts or degradation on base tasks. This will be supported by additional ablation results in the experiments section. revision: yes
Circularity Check
No circularity: theoretical link and hierarchical placement presented as derived properties without reduction to inputs
full rationale
The paper's core claims rest on proposing a framework with hierarchical embeddings, multi-level robust alignment, and a stated theoretical connection between embedding depth and margin size, plus mechanisms for placing embeddings at chosen depths. No equations, loss terms, or derivations are shown in the provided text that reduce the claimed connection or placement procedure to a self-definition, fitted parameter renamed as prediction, or self-citation chain. The multi-tree alignment is described as an additional consideration without invoking uniqueness theorems or ansatzes from prior self-work. The derivation chain therefore remains self-contained against external benchmarks and does not exhibit the enumerated circular patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures
James Bergstra, Daniel Yamins, and David Cox. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. InInternational conference on machine learning, pages 115–123. PMLR, 2013
2013
-
[2]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VI 13, pages 446–461. Springer, 2014
2014
-
[3]
Padchest: A large chest x-ray image dataset with multi-label annotated reports.Medical image analysis, 66:101797, 2020
Aurelia Bustos, Antonio Pertusa, Jose-Maria Salinas, and Maria De La Iglesia-Vaya. Padchest: A large chest x-ray image dataset with multi-label annotated reports.Medical image analysis, 66:101797, 2020
2020
-
[4]
Hyperbolic geometry.Flavors of geometry, 31(59-115): 2, 1997
James W Cannon, William J Floyd, Richard Kenyon, Walter R Parry, et al. Hyperbolic geometry.Flavors of geometry, 31(59-115): 2, 1997
1997
-
[5]
Towards evaluating the robustness of neural networks
Nicholas Carlini and David Wagner. Towards evaluating the robustness of neural networks. In2017 ieee symposium on security and privacy (sp), pages 39–57. IEEE, 2017
2017
-
[6]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014
2014
-
[7]
An analysis of single-layer networks in unsupervised feature learning
Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 215–223. JMLR Workshop and Conference Proceedings, 2011
2011
-
[8]
Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks
Francesco Croce and Matthias Hein. Reliable evaluation of adversarial robustness with an ensemble of diverse parameter-free attacks. InInternational conference on machine learning, pages 2206–2216. PMLR, 2020
2020
-
[9]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[10]
Hyperbolic image- text representations
Karan Desai, Maximilian Nickel, Tanmay Rajpurohit, Justin Johnson, and Shanmukha Ramakrishna Vedantam. Hyperbolic image- text representations. InInternational Conference on Machine Learning, pages 7694–7731. PMLR, 2023
2023
-
[11]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa De- hghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InInternational Conference on Learning Representations, ICLR, 2021
2021
-
[12]
Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories
Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In2004 conference on computer vision and pattern recognition workshop, pages 178–178. IEEE, 2004
2004
-
[13]
Caltech-256 object category dataset
Gregory Griffin, Alex Holub, and Pietro Perona. Caltech-256 object category dataset. 2007
2007
-
[14]
Gradient-based adversarial attacks against text transformers
Chuan Guo, Alexandre Sablayrolles, Herv ´e J´egou, and Douwe Kiela. Gradient-based adversarial attacks against text transformers. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP, pages 5747–5757, 2021
2021
-
[15]
Hypercolumns for object segmentation and fine-grained localization
Bharath Hariharan, Pablo Arbel ´aez, Ross Girshick, and Jitendra Malik. Hypercolumns for object segmentation and fine-grained localization. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 447–456, 2015
2015
-
[16]
Patrick Helber, Benjamin Bischke, Andreas Dengel, and Damian Borth. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification.IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 12(7): 2217–2226, 2019
2019
-
[17]
A token-wise cnn-based method for sentence compression
Weiwei Hou, Hanna Suominen, Piotr Koniusz, Sabrina Caldwell, and Tom Gedeon. A token-wise cnn-based method for sentence compression. InInternational Conference on Neural Information Processing (ICONIP), pages 668–679. Springer, Cham, 2020
2020
-
[18]
Adversarial attacks on foundational vision models.arXiv preprint arXiv:2308.14597, 2023
Nathan Inkawhich, Gwendolyn McDonald, and Ryan Luley. Adversarial attacks on foundational vision models.arXiv preprint arXiv:2308.14597, 2023
-
[19]
Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison
Jeremy Irvin, Pranav Rajpurkar, Michael Ko, Yifan Yu, Silviana Ciurea-Ilcus, Chris Chute, Henrik Marklund, Behzad Haghgoo, Robyn Ball, Katie Shpanskaya, et al. Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison. In Proceedings of the AAAI conference on artificial intelligence, pages 590–597, 2019
2019
-
[20]
Visual prompt tuning
Menglin Jia, Luming Tang, Bor-Chun Chen, Claire Cardie, Serge Belongie, Bharath Hariharan, and Ser-Nam Lim. Visual prompt tuning. InEuropean Conference on Computer Vision, pages 709–727. Springer, 2022
2022
-
[21]
Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
Alistair EW Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-ying Deng, Roger G Mark, and Steven Horng. Mimic-cxr, a de-identified publicly available database of chest radiographs with free-text reports.Scientific data, 6(1):317, 2019
2019
-
[22]
Hyperbolic image embeddings
Valentin Khrulkov, Leyla Mirvakhabova, Evgeniya Ustinova, Ivan Oseledets, and Victor Lempitsky. Hyperbolic image embeddings. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6418–6428, 2020
2020
-
[23]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. InProceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013
2013
-
[24]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
2009
-
[25]
Carzero: Cross- attention alignment for radiology zero-shot classification
Haoran Lai, Qingsong Yao, Zihang Jiang, Rongsheng Wang, Zhiyang He, Xiaodong Tao, and S Kevin Zhou. Carzero: Cross- attention alignment for radiology zero-shot classification. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11137–11146, 2024
2024
-
[26]
Biobert: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: a pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
2020
-
[27]
Blip: Bootstrapping language-image pre-training for unified vision- language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision- language understanding and generation. InICML, 2022
2022
-
[28]
BERT-ATTACK: adversarial attack against BERT using BERT
Linyang Li, Ruotian Ma, Qipeng Guo, Xiangyang Xue, and Xipeng Qiu. BERT-ATTACK: adversarial attack against BERT using BERT. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing EMNLP, pages 6193–6202, 2020
2020
-
[29]
One prompt word is enough to boost adversarial robustness for pre-trained vision-language models
Lin Li, Haoyan Guan, Jianing Qiu, and Michael Spratling. One prompt word is enough to boost adversarial robustness for pre-trained vision-language models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
2024
-
[30]
Feature pyramid networks for object detection
Tsung-Yi Lin, Piotr Doll ´ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2117–2125, 2017
2017
-
[31]
Openkd: Opening prompt diversity for zero- and few-shot keypoint detection
Changsheng Lu, Zheyuan Liu, and Piotr Koniusz. Openkd: Opening prompt diversity for zero- and few-shot keypoint detection. In Computer Vision – ECCV 2024, pages 148–165, Cham, 2025. Springer Nature Switzerland
2024
-
[32]
Set-level guidance attack: Boosting adversar- ial transferability of vision-language pre-training models
Dong Lu, Zhiqiang Wang, Teng Wang, Weili Guan, Hongchang Gao, and Feng Zheng. Set-level guidance attack: Boosting adversar- ial transferability of vision-language pre-training models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 102–111, 2023
2023
-
[33]
Towards deep learning models resistant to adversarial attacks
Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards deep learning models resistant to adversarial attacks. In6th International Conference on Learning Representations, ICLR, 2018
2018
-
[34]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review arXiv 2013
-
[35]
Understanding zero-shot adversarial robustness for large-scale models
Chengzhi Mao, Scott Geng, Junfeng Yang, Xin Wang, and Carl V ondrick. Understanding zero-shot adversarial robustness for large-scale models. InThe Eleventh International Conference on Learning Representations,ICLR, 2023
2023
-
[36]
Wordnet: a lexical database for english.Communications of the ACM, 38(11):39–41, 1995
George A Miller. Wordnet: a lexical database for english.Communications of the ACM, 38(11):39–41, 1995
1995
-
[37]
PACE: marrying the generalization of PArameter-efficient fine-tuning with consistency regularization
Yao Ni, Shan Zhang, and Piotr Koniusz. PACE: marrying the generalization of PArameter-efficient fine-tuning with consistency regularization. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[38]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE, 2008
2008
-
[39]
Chatgpt [large language model].https://chatgpt.com, 2024
OpenAI. Chatgpt [large language model].https://chatgpt.com, 2024
2024
-
[40]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012
2012
-
[41]
Xplainer: From x-ray observations to explainable zero-shot diagnosis
Chantal Pellegrini, Matthias Keicher, Ege ¨Ozsoy, Petra Jiraskova, Rickmer Braren, and Nassir Navab. Xplainer: From x-ray observations to explainable zero-shot diagnosis. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 420–429. Springer, 2023
2023
-
[42]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational confer- ence on machine learning, pages 8748–8763. PMLR, 2021
2021
-
[43]
Christian Schlarmann, Naman Deep Singh, Francesco Croce, and Matthias Hein. Robust clip: Unsupervised adversarial fine-tuning of vision embeddings for robust large vision-language models.arXiv preprint arXiv:2402.12336, 2024
-
[44]
Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning.Nature Biomedical Engineering, 6(12):1399–1406, 2022
Ekin Tiu, Ellie Talius, Pujan Patel, Curtis P Langlotz, Andrew Y Ng, and Pranav Rajpurkar. Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning.Nature Biomedical Engineering, 6(12):1399–1406, 2022
2022
-
[45]
Rotation equivariant cnns for digital pathology
Bastiaan S Veeling, Jasper Linmans, Jim Winkens, Taco Cohen, and Max Welling. Rotation equivariant cnns for digital pathology. InMedical Image Computing and Computer Assisted Intervention–MICCAI 2018: 21st International Conference, Granada, Spain, September 16-20, 2018, Proceedings, Part II 11, pages 210–218. Springer, 2018
2018
-
[46]
Pre-trained model guided fine-tuning for zero-shot adversarial robustness
Sibo Wang, Jie Zhang, Zheng Yuan, and Shiguang Shan. Pre-trained model guided fine-tuning for zero-shot adversarial robustness. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024
2024
-
[47]
Chestx-ray8: Hospital- scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases
Xiaosong Wang, Yifan Peng, Le Lu, Zhiyong Lu, Mohammadhadi Bagheri, and Ronald M Summers. Chestx-ray8: Hospital- scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2097–2106, 2017
2097
-
[48]
Sun database: Large-scale scene recognition from abbey to zoo
Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE, 2010
2010
-
[49]
Coca: Contrastive captioners are image-text foundation models.Trans
Jiahui Yu, Zirui Wang, Vijay Vasudevan, Legg Yeung, Mojtaba Seyedhosseini, and Yonghui Wu. Coca: Contrastive captioners are image-text foundation models.Trans. Mach. Learn. Res., 2022, 2022
2022
-
[50]
Towards adversarial attack on vision-language pre-training models
Jiaming Zhang, Qi Yi, and Jitao Sang. Towards adversarial attack on vision-language pre-training models. InProceedings of the 30th ACM International Conference on Multimedia, pages 5005–5013, 2022
2022
-
[51]
arXiv preprint arXiv:2410.19694 , year=
Yifei Zhang, Hao Zhu, Aiwei Liu, Han Yu, Piotr Koniusz, and Irwin King. Less is more: Extreme gradient boost rank-1 adaption for efficient finetuning of llms. InarXiv/2410.19694, 2024
-
[52]
Crossspectra: Exploiting cross-layer smoothness for parameter-efficient fine-tuning
Yifei Zhang, Hao Zhu, Junhao Dong, Haoran Shi, Ziqiao Meng, Piotr Koniusz, and Han Yu. Crossspectra: Exploiting cross-layer smoothness for parameter-efficient fine-tuning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[53]
On evaluating adversarial robustness of large vision-language models.Advances in Neural Information Processing Systems, 36:54111–54138, 2023
Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Chongxuan Li, Ngai-Man Man Cheung, and Min Lin. On evaluating adversarial robustness of large vision-language models.Advances in Neural Information Processing Systems, 36:54111–54138, 2023
2023
-
[54]
Clip in medical imaging: A comprehensive survey.arXiv preprint arXiv:2312.07353, 2023
Zihao Zhao, Yuxiao Liu, Han Wu, Yonghao Li, Sheng Wang, Lin Teng, Disheng Liu, Xiang Li, Zhiming Cui, Qian Wang, et al. Clip in medical imaging: A comprehensive survey.arXiv preprint arXiv:2312.07353, 2023
-
[55]
Learning to prompt for vision-language models.International Journal of Computer Vision (IJCV), 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision (IJCV), 2022
2022
-
[56]
Bilora: Almost-orthogonal parameter spaces for continual learning
Hao Zhu, Yifei Zhang, Junhao Dong, and Piotr Koniusz. Bilora: Almost-orthogonal parameter spaces for continual learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 25613–25622, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.