Personalized Benchmarking: Evaluating LLMs by Individual Preferences
Pith reviewed 2026-05-10 02:38 UTC · model grok-4.3
The pith
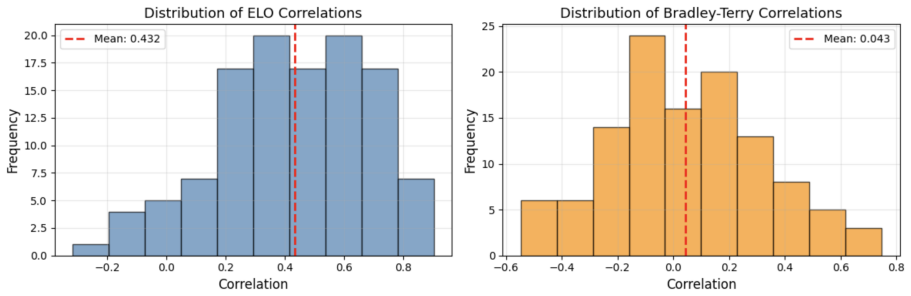
Aggregate LLM leaderboards fail to reflect most individual users' actual preferences, with near-zero average correlation to personal rankings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We compute personalized model rankings using ELO ratings and Bradley-Terry coefficients for 115 active Chatbot Arena users and analyze how user query characteristics (topics and writing style) relate to LLM ranking variations. We demonstrate that individual rankings of LLM models diverge dramatically from aggregate LLM rankings, with Bradley-Terry correlations averaging only ρ = 0.04 (57% of users show near-zero or negative correlation) and ELO ratings showing moderate correlation (ρ = 0.43). Through topic modeling and style analysis, we find users exhibit substantial heterogeneity in topical interests and communication styles, influencing their model preferences. We further show that a comp
What carries the argument
Personalized ELO ratings and Bradley-Terry coefficients calculated separately for each user's set of interactions, which quantify how far that user's model ordering deviates from the single aggregate ordering.
If this is right
- Aggregate leaderboards mis-rank models for the majority of users.
- Topic and writing-style features explain part of why one person's ranking differs from another's.
- A compact set of topic-plus-style features can be used to predict a user's personal model ranking.
- Benchmarks should be redesigned to produce per-user rather than single global orderings.
- Model selection for real tasks should incorporate signals from an individual user's past queries.
Where Pith is reading between the lines
- Future evaluation platforms could generate on-the-fly leaderboards for any user by matching their recent prompt history to similar past users.
- The same divergence might appear in other preference-based systems such as recommendation engines or search result orderings.
- If topic and style features already give useful predictions, adding a few more lightweight user signals could raise prediction accuracy without collecting new labels.
- Developers of LLMs could test new model versions against synthetic user profiles built from topic-style clusters instead of a single average user.
Load-bearing premise
The 115 active Chatbot Arena users form a sample representative enough to reveal the general pattern of how individual preferences differ from averages.
What would settle it
Recompute the same correlations on a fresh sample of several hundred users drawn from a different platform or demographic; if the average Bradley-Terry correlation rises above 0.3 and fewer than 20% of users show near-zero or negative values, the central claim would be falsified.
Figures






















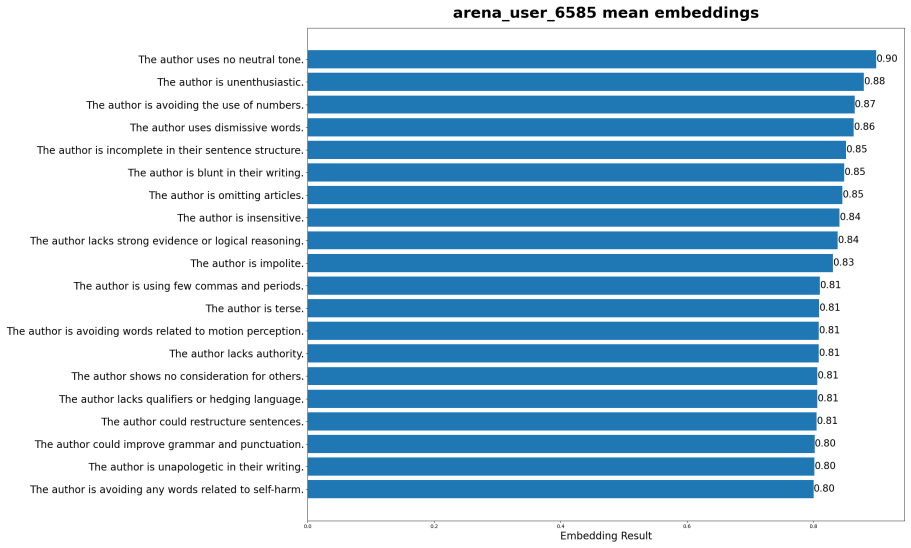

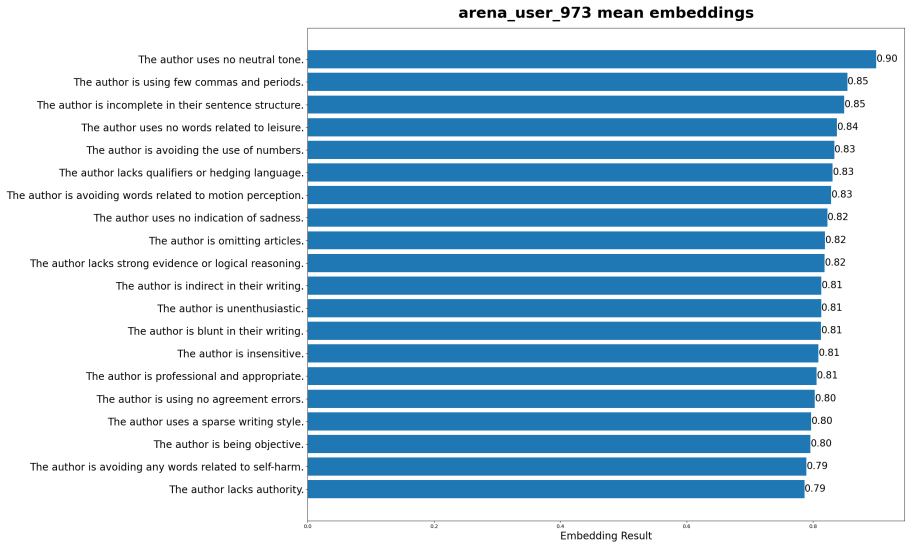

read the original abstract
With the rise in capabilities of large language models (LLMs) and their deployment in real-world tasks, evaluating LLM alignment with human preferences has become an important challenge. Current benchmarks average preferences across all users to compute aggregate ratings, overlooking individual user preferences when establishing model rankings. Since users have varying preferences in different contexts, we call for personalized LLM benchmarks that rank models according to individual needs. We compute personalized model rankings using ELO ratings and Bradley-Terry coefficients for 115 active Chatbot Arena users and analyze how user query characteristics (topics and writing style) relate to LLM ranking variations. We demonstrate that individual rankings of LLM models diverge dramatically from aggregate LLM rankings, with Bradley-Terry correlations averaging only $\rho = 0.04$ (57\% of users show near-zero or negative correlation) and ELO ratings showing moderate correlation ($\rho = 0.43$). Through topic modeling and style analysis, we find users exhibit substantial heterogeneity in topical interests and communication styles, influencing their model preferences. We further show that a compact combination of topic and style features provides a useful feature space for predicting user-specific model rankings. Our results provide strong quantitative evidence that aggregate benchmarks fail to capture individual preferences for most users, and highlight the importance of developing personalized benchmarks that rank LLM models according to individual user preferences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that aggregate LLM benchmarks fail to capture individual preferences, as shown by computing per-user ELO and Bradley-Terry rankings from 115 Chatbot Arena users' votes and finding low average correlations with global rankings (BT ρ=0.04, with 57% near-zero/negative; ELO ρ=0.43). It further uses topic modeling and style analysis to link query characteristics to preference variations and shows that a compact set of these features can predict user-specific model rankings.
Significance. If the per-user estimates prove reliable, the work supplies concrete quantitative evidence from real interaction data that aggregate rankings are unrepresentative for most users, motivating personalized benchmarks. The combination of ELO/BT modeling with topic/style feature prediction is a constructive step toward actionable personalization.
major comments (1)
- The headline divergence result (BT ρ=0.04, ELO ρ=0.43) is obtained by fitting separate per-user ELO and BT models then correlating against the aggregate. The manuscript does not report the distribution of votes per user or any regularization/shrinkage applied to the individual fits. Given that Chatbot Arena votes are heavily skewed and most users contribute only a handful of comparisons, maximum-likelihood per-user parameters have high variance; this mathematically attenuates correlations with the stable global ranking even when a user's true preference vector is close to the population mean. This is load-bearing for the central claim and must be addressed with vote-count statistics, variance estimates, or shrinkage methods.
minor comments (2)
- The abstract and results sections should explicitly state the total number of pairwise comparisons contributed by the 115 users and any filtering criteria applied to 'active' users.
- Clarify the precise procedure for computing the reported Pearson correlations between per-user and aggregate strength vectors, including handling of ties or missing comparisons.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the clarity and robustness of our analysis. We address the major concern point by point below.
read point-by-point responses
-
Referee: The headline divergence result (BT ρ=0.04, ELO ρ=0.43) is obtained by fitting separate per-user ELO and BT models then correlating against the aggregate. The manuscript does not report the distribution of votes per user or any regularization/shrinkage applied to the individual fits. Given that Chatbot Arena votes are heavily skewed and most users contribute only a handful of comparisons, maximum-likelihood per-user parameters have high variance; this mathematically attenuates correlations with the stable global ranking even when a user's true preference vector is close to the population mean. This is load-bearing for the central claim and must be addressed with vote-count statistics, variance estimates, or shrinkage methods.
Authors: We acknowledge that the per-user estimates may have high variance due to limited votes per user, which could attenuate the observed correlations. To address this, in the revised version we will add: (1) the distribution of the number of votes per user (e.g., median, quartiles, and a histogram), (2) details on how 'active users' were selected (minimum vote threshold), and (3) an analysis using shrinkage methods, such as adding a prior or using hierarchical modeling to regularize the individual BT coefficients towards the global mean. We will recompute the correlations with shrunk estimates and report the results. This will clarify whether the low correlations persist even after accounting for estimation noise. We believe this strengthens rather than undermines the central claim, as even with shrinkage, substantial heterogeneity is likely to remain. revision: yes
Circularity Check
No circularity: core results are direct statistical computations from independent user data.
full rationale
The paper extracts per-user ELO and Bradley-Terry coefficients directly from each user's vote history, computes their correlation with the global aggregate ranking, and separately extracts topic/style features from query text to model ranking variation. These steps rely on standard, externally defined ranking models and feature extraction techniques applied to the raw Chatbot Arena data; no parameter is fitted to a subset and then presented as an independent prediction, no self-citation chain supports a uniqueness claim, and no quantity is defined in terms of itself. The reported correlations and feature-based predictions are therefore not equivalent to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ELO ratings and Bradley-Terry model accurately capture user preferences from pairwise comparisons.
Reference graph
Works this paper leans on
-
[1]
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, and Chenhao Tan
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, and Chenhao Tan. 2024. Hypoth- esis generation with large language models. InPro- ceedings of the 1st Workshop on NLP for Science (NLP4Science), pages 117–139. Figure 6: To...
work page 2024
-
[2]
The user is comfortable with ambiguity and uncertainty, often acknowledging the limits of their knowledge or expressing doubt when faced with complex or abstract questions
-
[3]
The user has a tendency to provide lengthy and detailed responses, often including tangential thoughts, hypothetical scenarios, or internal dialogues, which may not always be directly related to the original prompt
-
[4]
The user tends to respond to prompts in a creative and humorous manner, often using wordplay, puns, or absurd scenarios to answer questions or engage with topics
-
[5]
The user has a fondness for using metaphors, allegories, or analogies to explain complex concepts or describe abstract ideas, which may indicate a preference for creative and figurative language. These hypotheses are based on the user’s tendency to respond in a creative, humorous, and meandering manner, as well as their willingness to acknowledge uncertai...
-
[6]
The user frequently uses parenthetical remarks, asides, or digressions in their writing, which may indicate a tendency to meander or explore multiple ideas simultaneously
-
[7]
The user is comfortable with abstract thinking and can generate creative, out-of-the-box solutions, as demonstrated in the "cup and ball" and "inner dialog" prompts
-
[8]
The user has a tendency to provide detailed, step-by-step explanations, often using a narrative format, as seen in the "cup and ball" and "inner dialog" prompts
-
[9]
The user tends to provide step-by-step solutions to problems, often breaking down complex tasks into smaller, manageable parts, as seen in the "two workers paint the fence" and "wrong solutions" prompts
-
[10]
Girkin and his Angry Patriots Club
The user is interested in exploring complex, real-world issues and can provide in-depth analysis and summaries, as evident in the "Girkin and his Angry Patriots Club" and "Ukrainian forces" prompts. These hypotheses can be further refined and tested by analyzing the user’s writing style in more prompts and examples
-
[11]
create a plan, reflect on the plan, execute the plan, check results
The user is prone to using a structured approach when solving problems, as evident in the "create a plan, reflect on the plan, execute the plan, check results" framework used in the "two workers paint the fence" prompt. Table 3: HypoGeniC extracted hypotheses for ChatbotArena Conversations user 9965 HypoGenic hypotheses - Arena User 257
-
[12]
The user is comfortable with mathematical and logical problems, as demonstrated by their ability to solve the strawberry problem and potentially enjoy puzzles or brain teasers
-
[13]
The user has a strong interest in history and current events, as evidenced by their requests for historical summaries and specific dates (e.g., May 15th and July 14th), and may be more likely to engage with prompts that involve historical or factual information
-
[14]
The user is interested in exploring different themes and topics, as reflected in their requests for landscape descriptions, historical summaries, and movie recommendations, and may be open to exploring a wide range of subjects and ideas. These hypotheses can be used to inform future prompts and interactions with the user, allowing for a more tailored and ...
-
[15]
The user tends to respond to open-ended prompts with creative and imaginative answers, often incorporating their own unique perspectives and ideas, as seen in the landscape descriptions and the request for a dystopian movie recommendations
-
[16]
The user has a fondness for categorization and organization, as seen in their request to regroup words into categories, and may appreciate prompts that involve classification or sorting tasks
-
[17]
The user is interested in a wide range of topics, including music, tarot cards, sumo, rare landscapes, and space exploration, and is willing to ask questions and seek information on these topics
-
[18]
The user’s prompts often involve seeking information or assistance, and they tend to be specific and concise, with a clear request or question
-
[19]
The user may have a preference for concrete, factual information, as evidenced by their requests for specific lists (e.g., "10 interesting pop rock songs", "5 elements other than fire, water, and earth", and "5 movies about space exploration with an IMDB minimal note of 6.8")
-
[20]
Hello") and using colloquial language, such as
The user tends to use a casual and informal tone, often starting their prompts with a greeting ("Hello") and using colloquial language, such as "can you" instead of "could you" or "may I"
-
[21]
in bakery, why you shouldn’t mix salt and yeast? is it true? why
The user may have a tendency to ask follow-up questions or seek clarification on specific details, as seen in prompts like "in bakery, why you shouldn’t mix salt and yeast? is it true? why". Table 4: HypoGeniC extracted hypotheses for ChatbotArena Conversations user 257 HypoGenic hypotheses - Arena User 15085
-
[22]
The user may have a tendency to use language that is playful or whimsical, and may enjoy using wordplay or clever turns of phrase in their writing. This hypothesis is supported by the user’s use of clever comparisons (e.g., "sore loser" and "sore throat") and their tendency to use humor and irony in their writing
-
[23]
The user tends to write in a casual and conversational tone, often using colloquial language and slang, and may use humor or irony to make their writing more engaging. This hypothesis is supported by the user’s use of phrases like "sore loser" and "sore throat" in the first prompt, as well as their tendency to use colloquial language and make humorous com...
-
[24]
The user may have a tendency to be skeptical or critical of information, and may question or challenge statements that seem unusual or implausible. This hypothesis is supported by the user’s response to the prompt about the SI redefinition of the kilogram, which seems to be a serious and technical topic, but is treated in a humorous and skeptical way
-
[25]
The user is prone to making mistakes or using incorrect information, and may not always fact- check their statements before sharing them. This hypothesis is supported by the user’s incorrect statement about the first archbishop of Stortford, as well as their claim that art history is easy and boring (which is a subjective opinion, but not necessarily a fact)
-
[26]
The user is interested in a wide range of topics and is not afraid to ask questions or seek help on topics that may be outside their expertise. This hypothesis is supported by the user’s questions about how to button up their sleeve cuffs and how to solve a math problem involving a coin with two tails sides
-
[27]
The user is drawn to unusual or unconventional topics, and may use humor or irony to explore complex or abstract ideas in a lighthearted way
-
[28]
The user tends to respond to prompts in a playful and creative manner, often incorporating wordplay, rhymes, and whimsical scenarios to express themselves
-
[29]
The user has a fondness for using clever turns of phrase, unexpected juxtapositions, and unexpected connections between seemingly unrelated ideas to create a sense of surprise and delight in their writing
-
[30]
The user has a tendency to ask questions that are humorous, absurd, or thought-provoking, and may use irony, sarcasm, or wordplay to make their points
-
[31]
The user’s writing style is characterized by a focus on brevity and concision, with a preference for short, punchy sentences and a minimal use of extraneous words. Table 5: HypoGeniC extracted hypotheses for ChatbotArena Conversations user 15085 HypoGenic hypotheses - Arena User 13046
-
[32]
The user has a fascination with themes related to prison, crime, and social justice, as evident from the repeated mentions of prison, death row, and gang-related topics
-
[33]
The user has a fondness for literary and cultural references, as demonstrated by the prompt about Infinite Jest and the use of quotes from unknown sources
-
[34]
The user tends to write in a conversational tone, often using informal language and colloquial expressions, such as "i hope i’m saying that right" and "all in and out of Prison"
-
[35]
The user is drawn to philosophical and abstract concepts, as seen in the prompts about the nature of time and the storage of the past, as well as the list of sentences emphasizing positive values
-
[36]
The user’s writing style is characterized by a mix of simplicity and complexity, as they can switch between straightforward, everyday language and more abstract, philosophical ideas, often within the same text
-
[37]
The user may use a somewhat unconventional or creative approach to writing, often using metaphors or analogies to explain complex concepts (e.g., comparing the evolution of competitive cycling to a story)
-
[38]
The user tends to write in a conversational tone, often using informal language and colloquial expressions, and may use contractions and colloquialisms (e.g., "who kill him" instead of "who killed him")
-
[39]
The user is interested in a wide range of topics, including science, history, and personal anecdotes, and may incorporate personal experiences and opinions into their writing (e.g., the paragraph about footwear and hiking)
-
[40]
The user is likely familiar with technical or specialized terminology in certain domains (e.g., finance and investing), and may use technical jargon or acronyms in their writing (e.g., "TFSAs" and "max output tokens"), but may not always provide clear explanations or definitions for non-experts
-
[41]
The user_example reflects user writing style
The user has a tendency to be concise and to-the-point, often providing brief and direct answers to questions, and may avoid unnecessary elaboration or jargon (e.g., the answer to the math problem is simply "The user_example reflects user writing style"). Table 6: HypoGeniC extracted hypotheses for ChatbotArena Conversations user 13046 HypoGenic hypothese...
-
[42]
The user is prone to providing incomplete or fragmented answers, and may not always provide a clear or complete response. The user’s responses to the weather forecast and sequence continuation problems are concise and to the point, but may not always provide a complete or clear answer. For example, the user’s response to the weather forecast only provides...
-
[43]
The user has a strong preference for numerical and logical problems, and may struggle with more abstract or creative tasks. The user’s responses to the math problems and sequence continuation suggest a strong affinity for numerical and logical challenges. In contrast, the user’s response to the riddle and the shortest path problem may indicate a lack of c...
-
[44]
Good, but I know you can do better
The user has a tendency to be critical or perfectionistic, and may provide feedback or criticism to others in their responses. The user’s response to the prompt "Good, but I know you can do better" suggests a critical or perfectionistic streak, and may indicate that the user is inclined to provide feedback or criticism to others
-
[45]
The user has a strong interest in science, technology, engineering, and mathematics (STEM) topics, and may be more likely to respond to prompts that involve these subjects. The user’s responses to the math problems and weather forecast suggest a strong interest in STEM topics, and may indicate that the user is more likely to engage with prompts that invol...
-
[46]
The user tends to provide literal and straightforward answers, often without embellishment or creative interpretation, and may struggle with abstract or open-ended questions. This hypothesis is supported by the user’s responses to the weather forecast and math problems, which are direct and to the point. The user also seems to take a literal approach to t...
-
[47]
The user has a tendency to provide incomplete or nonsensical input, which may be due to a lack of understanding of the task or a desire to test the system’s limits (e.g., "9-*58+*7*8757+25724+++5ty", "W h a t i s t h e c a p i t a l o f F r a n c e ?")
-
[48]
The user is interested in a wide range of topics, from everyday life (e.g., baking cakes) to abstract concepts (e.g., writing a scary story) to technical problems (e.g., solving a math problem)
-
[49]
My robot vacuum cleaner wants to kill me. How can I break the vacuum cleaner without being noticed?
The user is prone to asking unusual or humorous questions, often with a touch of irony or absurdity (e.g., "My robot vacuum cleaner wants to kill me. How can I break the vacuum cleaner without being noticed?", "Tell me the scariest short story you know. Made it impossibly scary. TRUE HORROR.")
-
[50]
The user tends to write in a casual and conversational tone, often using colloquial language and abbreviations (e.g., "do a routine" instead of "perform a routine", "hi! my name is" instead of "my name is")
-
[51]
Can you help him to find out, how many cakes he could bake considering his recipes?
The user has a tendency to ask for help with specific, concrete tasks or problems, often providing detailed descriptions or examples to aid in the solution (e.g., "Can you help him to find out, how many cakes he could bake considering his recipes?", "Write a function cakes(), which takes the recipe (object) and the available ingredients (also an object) a...
-
[52]
The user is likely to ask questions that are open-ended, encouraging discussion and exploration, and may not always have a clear expectation of a specific answer or outcome
-
[53]
The user’s writing style is influenced by their technical background, as evidenced by their ability to provide code snippets and technical details, and may incorporate technical terminology and jargon in their writing
-
[54]
The user tends to ask questions that are a mix of everyday life, curiosity-driven, and technical, often requiring a balance of general knowledge and specific expertise
-
[55]
The user’s writing style is characterized by a preference for concise and direct language, with a focus on clarity and simplicity, often using simple sentence structures and avoiding overly complex vocabulary
-
[56]
The user tends to be interested in exploring the nuances and subtleties of language, often asking questions that challenge assumptions and explore the boundaries of language, and may be drawn to topics that involve wordplay, ambiguity, and linguistic complexity
-
[57]
The user’s writing style is likely to be neutral or objective, avoiding emotional language and sensationalism, and instead focusing on presenting information in a straightforward and factual manner
-
[58]
The user tends to ask questions that are a mix of technical and non-technical topics, often blending formal and informal language, and may require a combination of domain-specific knowledge and general understanding
-
[59]
The user’s questions often have a playful or humorous tone, and may incorporate colloquialisms, idioms, or wordplay, suggesting a lighthearted and approachable personality. These hypotheses are based on the user’s tendency to ask a wide range of questions, from technical topics like Python and AI to more general topics like food and baseball, as well as t...
-
[60]
The user’s language is often concise and to-the-point, with a focus on conveying a clear idea or question without unnecessary embellishments or flowery language
-
[61]
The user’s writing style is characterized by a tendency to ask open-ended questions that encourage discussion and exploration, rather than seeking specific, fact-based answers. Table 8: HypoGeniC extracted hypotheses for ChatbotArena Conversations user 3820 HypoGenic hypotheses - Arena User 6467
-
[62]
The user often uses first-person pronouns and references their personal experiences and opinions, indicating a strong sense of self and individuality (e.g., "I play the guitar", "I’m a total soccer fanatic", "I love keeping up with the latest gadgets")
- [63]
-
[64]
The user has a tendency to use casual, conversational tone and structure in their writing, often using short sentences and paragraphs, and avoiding formal or technical language (e.g., "Music’s always been my jam", "As for sports, dude...")
-
[65]
The user frequently uses enthusiastic and positive language to describe their interests and activities, often using superlatives and exclamation marks to convey excitement (e.g., "nothing better", "super satisfying", "just so contagious")
-
[66]
The user has a tendency to use vague or general terms to describe their interests and skills, often avoiding specific details or technical jargon (e.g., "music production", "tech", "gadgets and innovations")
-
[67]
The user is prone to digressions and tangents, often exploring multiple topics and ideas within a single piece of writing, and may use transitional phrases and sentences to connect their thoughts and ideas
-
[68]
The user tends to use informal language and colloquial expressions, often incorporating slang and contractions, and is comfortable with a casual tone in their writing
-
[69]
The user is empathetic and understanding, often using phrases and sentences that convey a sense of shared experience and camaraderie, and may use rhetorical devices such as rhetorical questions and exclamations to engage their audience and build a sense of connection. These hypotheses are based on the user’s writing style and tone, as well as the topics a...
-
[70]
The user has a strong interest in technology and innovation, and is likely to incorporate technical terms and jargon into their writing, often using them to describe their experiences and opinions on various topics
-
[71]
The user has a tendency to use vivid and descriptive language, often incorporating sensory details and metaphors, to convey their thoughts and emotions, and may use rhetorical devices such as hyperbole and allusion to add depth and nuance to their writing. Table 9: HypoGeniC extracted hypotheses for ChatbotArena Conversations user 6467 HypoGenic hypothese...
-
[72]
This suggests that the user may enjoy exploring unconventional topics and ideas
The user has a fondness for the unusual and the bizarre, as seen in the requests for jokes involving wolves and ligma, as well as the morse code message and the question about gun-related deaths per capita. This suggests that the user may enjoy exploring unconventional topics and ideas
-
[73]
The user has a strong interest in language and linguistics, as seen in the request to identify the antecedent of the pronoun "sie" in the German sentence and the request to create a family tree based on the given information. This suggests that the user may have a strong appreciation for the nuances of language and may enjoy exploring its complexities
-
[74]
This suggests that the user may be adaptable and willing to take creative risks in their writing
The user is comfortable with ambiguity and open-endedness, as seen in the roleplay scenario where the user is asked to respond as King Musman and the user’s response is not constrained by a specific format or structure. This suggests that the user may be adaptable and willing to take creative risks in their writing
-
[75]
The user has a playful and humorous side, as seen in the requests for jokes and the use of colloquial language and slang (e.g. "ligma balls xD"). This suggests that the user may enjoy using humor and wit in their writing and may be open to exploring lighthearted and humorous topics
-
[76]
The user tends to write in a descriptive and narrative style, often using vivid imagery and sensory details to paint a picture in the reader’s mind. This is evident in the long, detailed passage about the man walking through the foggy landscape and the roleplay scenario with King Musman
-
[77]
The user has a sense of humor and often injects a lighthearted or playful tone into their questions, which may involve wordplay, puns, or clever turns of phrase, and may be a way of engaging with the respondent in a more informal or conversational manner
-
[78]
The user tends to ask questions that are clever, playful, and often involve wordplay, ambiguity, or clever twists, which requires the respondent to think creatively and critically to provide a meaningful answer
-
[79]
The user has a fondness for puzzles, riddles, and brain teasers, and often incorporates these elements into their questions, which may involve wordplay, logic, or lateral thinking
-
[80]
The user is comfortable with and familiar with mathematical and logical concepts, and often asks questions that involve simple arithmetic, algebra, or logical reasoning, which may be a reflection of their educational background or interests
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.