When Graph Structure Becomes a Liability: A Critical Re-Evaluation of Graph Neural Networks for Bitcoin Fraud Detection under Temporal Distribution Shift
Pith reviewed 2026-05-10 02:49 UTC · model grok-4.3
The pith
Under a leakage-free inductive protocol, random forests on raw features outperform all graph neural networks for Bitcoin fraud detection on the Elliptic dataset.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
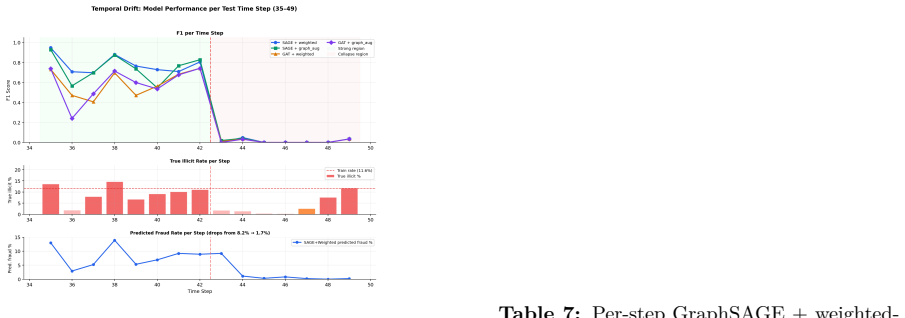
The authors establish that the performance edge previously attributed to GNNs on this dataset is an artifact of temporal leakage. Under a controlled inductive-versus-transductive comparison, Random Forest on raw features achieves F1 = 0.821 while the strongest GNN reaches 0.689. A paired experiment isolates a 39.5-point F1 gap caused solely by allowing models to see test-period adjacency at training time. Random-edge ablations show that arbitrary wiring outperforms the genuine transaction graph, and hybrid GNN-plus-feature models remain below the pure feature baseline.
What carries the argument
The strictly inductive evaluation protocol that partitions training and test periods to eliminate all access to future adjacency information, combined with edge-shuffle ablations that test whether the real topology adds value.
Load-bearing premise
The chosen inductive protocol fully removes every possible channel of temporal leakage and that measured differences arise mainly from the presence or absence of graph structure rather than other training details.
What would settle it
A replication in which any GNN trained under the identical strict inductive protocol and seed-matched conditions records an F1 score above 0.821 on the held-out test set, or in which the real transaction edges produce higher performance than randomly shuffled edges.
Figures









read the original abstract
The consensus that GCN, GraphSAGE, GAT, and EvolveGCN outperform feature-only baselines on the Elliptic Bitcoin Dataset is widely cited but has not been rigorously stress-tested under a leakage-free evaluation protocol. We perform a seed-matched inductive-versus-transductive comparison and find that this consensus does not hold. Under a strictly inductive protocol, Random Forest on raw features achieves F1 = 0.821 and outperforms all evaluated GNNs, while GraphSAGE reaches F1 = 0.689 +/- 0.017. A paired controlled experiment reveals a 39.5-point F1 gap attributable to training-time exposure to test-period adjacency. Additionally, edge-shuffle ablations show that randomly wired graphs outperform the real transaction graph, indicating that the dataset's topology can be misleading under temporal distribution shift. Hybrid models combining GNN embeddings with raw features provide only marginal gains and remain substantially below feature-only baselines. We release code, checkpoints, and a strict-inductive protocol to enable reproducible, leakage-free evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript re-evaluates GNNs (GCN, GraphSAGE, GAT, EvolveGCN) for fraud detection on the Elliptic Bitcoin dataset under temporal distribution shift. It claims that a strictly inductive, leakage-free protocol reverses the consensus: Random Forest on raw features reaches F1=0.821 and outperforms all GNNs (e.g., GraphSAGE at 0.689±0.017); a seed-matched paired experiment shows a 39.5-point F1 gap attributable to training-time exposure to test-period adjacency; edge-shuffle ablations indicate randomly wired graphs beat the real topology; and hybrid GNN+feature models add only marginal value. Code, checkpoints, and the inductive protocol are released.
Significance. If the inductive protocol is verifiably leakage-free and the paired controls are complete, the result would meaningfully challenge GNN adoption in temporally dynamic domains such as transaction fraud detection, highlighting risks of graph structure under distribution shift and the value of strong feature baselines. The explicit release of code and protocol is a clear strength that supports reproducibility and future work.
major comments (2)
- [Paired controlled experiment] Paired controlled experiment (results section describing the inductive-vs-transductive comparison): the 39.5-point F1 gap is attributed to training-time exposure to test-period adjacency, but the manuscript only states seed-matching and does not supply side-by-side hyperparameter tables, architecture specifications, optimizer details, learning-rate schedules, batch construction, negative-sampling ratios, or early-stopping criteria to confirm that every non-adjacency factor was frozen. This verification is load-bearing for the central claim that the gap is caused by the graph rather than implementation differences.
- [Methods] Definition of strictly inductive protocol (methods section): the precise temporal split, adjacency construction (ensuring no test-period edges reach training), and handling of node features/labels across periods must be specified in sufficient detail to allow independent verification that temporal leakage is fully eliminated. The abstract reports concrete F1 numbers and standard deviations, but without this, the protocol's soundness cannot be fully assessed.
minor comments (2)
- [Abstract] Abstract: the 39.5-point gap is stated without the corresponding transductive F1 value for the paired run, which would aid immediate interpretation.
- [Ablations] Edge-shuffle ablations: report the number of shuffles performed and any statistical significance tests on the outperformance of random graphs over the real topology.
Simulated Author's Rebuttal
Thank you for the detailed review. We address the major comments below, providing additional details and committing to revisions that enhance the clarity and reproducibility of our work on evaluating GNNs for Bitcoin fraud detection under temporal shifts.
read point-by-point responses
-
Referee: [Paired controlled experiment] Paired controlled experiment (results section describing the inductive-vs-transductive comparison): the 39.5-point F1 gap is attributed to training-time exposure to test-period adjacency, but the manuscript only states seed-matching and does not supply side-by-side hyperparameter tables, architecture specifications, optimizer details, learning-rate schedules, batch construction, negative-sampling ratios, or early-stopping criteria to confirm that every non-adjacency factor was frozen. This verification is load-bearing for the central claim that the gap is caused by the graph rather than implementation differences.
Authors: We acknowledge the referee's concern regarding the need for explicit verification that non-adjacency factors were identical in the paired experiment. Although the manuscript indicates seed-matching and controlled conditions, we agree that side-by-side documentation is crucial. In the revised manuscript, we will include a table detailing all hyperparameters, model architectures, optimizer settings, learning rate schedules, batch construction, negative-sampling ratios, and early-stopping criteria for both inductive and transductive setups. The released code already encodes these exact configurations, allowing direct inspection to confirm that the 39.5-point F1 gap arises solely from the difference in adjacency information. revision: yes
-
Referee: [Methods] Definition of strictly inductive protocol (methods section): the precise temporal split, adjacency construction (ensuring no test-period edges reach training), and handling of node features/labels across periods must be specified in sufficient detail to allow independent verification that temporal leakage is fully eliminated. The abstract reports concrete F1 numbers and standard deviations, but without this, the protocol's soundness cannot be fully assessed.
Authors: We appreciate the emphasis on fully specifying the inductive protocol to ensure no temporal leakage. The current manuscript provides an overview, but we concur that more granular details are required. We will revise the Methods section to explicitly describe: the precise temporal split (training on earlier time steps, testing on later ones), the adjacency construction process that excludes all test-period edges from training graphs, and the handling of node features and labels to avoid any information leakage across periods. Furthermore, the released code and protocol documentation implement these steps precisely, enabling independent verification. This will support the reported F1 scores and standard deviations. revision: yes
Circularity Check
No circularity: purely empirical evaluation with no derivations or self-referential reductions
full rationale
The manuscript reports experimental results on the Elliptic Bitcoin dataset under inductive and transductive protocols, including F1 scores for Random Forest vs. GNNs, a paired controlled comparison, and edge-shuffle ablations. No first-principles derivations, equations, or predictions are claimed that could reduce to fitted inputs or self-citations by construction. All load-bearing claims rest on direct measurements and ablations from public data, with code released for verification. This matches the default case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Elliptic Bitcoin Dataset is a suitable benchmark for testing temporal distribution shift in fraud detection.
Reference graph
Works this paper leans on
-
[1]
KDD Workshop on Anomaly Detection in Finance , year =
Anti-Money Laundering in Bitcoin: Experimenting with Graph Convolutional Networks for Financial Forensics , author =. KDD Workshop on Anomaly Detection in Finance , year =
-
[2]
Pareja, Aldo and Domeniconi, Giacomo and Chen, Jie and Ma, Tengfei and Suzumura, Toyotaro and Kanezashi, Hiroki and Kaler, Tim and Schardl, Tao B. and Leiserson, Charles E. , booktitle =
-
[3]
Advances in Neural Information Processing Systems , volume =
Inductive Representation Learning on Large Graphs , author =. Advances in Neural Information Processing Systems , volume =
-
[4]
International Conference on Learning Representations , year =
Graph Attention Networks , author =. International Conference on Learning Representations , year =
-
[5]
International Conference on Learning Representations , year =
Semi-Supervised Classification with Graph Convolutional Networks , author =. International Conference on Learning Representations , year =
-
[6]
Proceedings of the 2020 5th International Conference on Machine Learning Technologies , pages =
Competence of Graph Convolutional Networks for Anti-Money Laundering in Bitcoin Blockchain , author =. Proceedings of the 2020 5th International Conference on Machine Learning Technologies , pages =
work page 2020
-
[7]
Lo, Wai Weng and Kulatilleke, Gayan Kasun and Sarhan, Mohanad and Layeghy, Siamak and Portmann, Marius , journal =. Inspection-L: Self-supervised
-
[8]
Chawla, Nitesh V. and Bowyer, Kevin W. and Hall, Lawrence O. and Kegelmeyer, W. Philip , journal =
-
[9]
Zhao, Tianxiang and Zhang, Xiang and Wang, Suhang , booktitle =
-
[10]
Proceedings of the 34th International Conference on Machine Learning , pages =
On Calibration of Modern Neural Networks , author =. Proceedings of the 34th International Conference on Machine Learning , pages =
-
[11]
Fast Graph Representation Learning with
Fey, Matthias and Lenssen, Jan Eric , booktitle =. Fast Graph Representation Learning with
-
[12]
Sankar, Aravind and Wu, Yanhong and Gou, Liang and Zhang, Wei and Yang, Hao , booktitle =
-
[13]
Adversarial Attacks on Neural Networks for Graph Data , author =. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages =
-
[14]
ICLR Workshop on Distributed and Private Machine Learning , year =
FedGraphNN: A Federated Learning System and Benchmark for Graph Neural Networks , author =. ICLR Workshop on Distributed and Private Machine Learning , year =
-
[15]
Report to the Nations: 2020 Global Study on Occupational Fraud and Abuse , author =
work page 2020
-
[16]
Data Mining and Knowledge Discovery , volume =
Graph-based anomaly detection and description: a survey , author =. Data Mining and Knowledge Discovery , volume =
-
[17]
Proceedings of the IEEE International Conference on Computer Vision , pages =
Focal Loss for Dense Object Detection , author =. Proceedings of the IEEE International Conference on Computer Vision , pages =
-
[18]
International Conference on Learning Representations , year =
Inductive Representation Learning on Temporal Graphs , author =. International Conference on Learning Representations , year =
-
[19]
ACM Computing Surveys , volume =
A survey on concept drift adaptation , author =. ACM Computing Surveys , volume =
-
[20]
IEEE International Conference on Big Data , pages =
Semi-supervised Graph Attention Networks for Financial Fraud Detection , author =. IEEE International Conference on Big Data , pages =
-
[21]
Liu, Ziqi and Chen, Chaochao and Li, Longfei and Zhou, Jun and Li, Xiaolong and Song, Le and Hu, Yuan , booktitle =
-
[22]
Decision Support Systems , volume =
Fraud Detection: A Systematic Literature Review of Graph-Based Anomaly Detection Approaches , author =. Decision Support Systems , volume =
-
[23]
Advances in Neural Information Processing Systems , volume =
GNNExplainer: Generating Explanations for Graph Neural Networks , author =. Advances in Neural Information Processing Systems , volume =
-
[24]
Chen, Tianqi and Guestrin, Carlos , booktitle =
-
[25]
Proceedings of the 34th International Conference on Machine Learning , pages =
Neural Message Passing for Quantum Chemistry , author =. Proceedings of the 34th International Conference on Machine Learning , pages =
-
[26]
IEEE Transactions on Neural Networks and Learning Systems , volume =
A Comprehensive Survey on Graph Neural Networks , author =. IEEE Transactions on Neural Networks and Learning Systems , volume =
- [27]
-
[28]
and Hauskrecht, Milos , booktitle =
Naeini, Mahdi Pakdaman and Cooper, Gregory F. and Hauskrecht, Milos , booktitle =. Obtaining Well Calibrated Probabilities Using
-
[29]
Proceedings of the Internet Measurement Conference , pages =
A Fistful of Bitcoins: Characterizing Payments Among Men with No Names , author =. Proceedings of the Internet Measurement Conference , pages =
-
[30]
IEEE Transactions on Knowledge and Data Engineering , volume =
Learning under Concept Drift: A Review , author =. IEEE Transactions on Knowledge and Data Engineering , volume =
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Deeper Insights into Graph Convolutional Networks for Semi-Supervised Learning , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =
-
[32]
International Conference on Learning Representations , year =
Decoupled Weight Decay Regularization , author =. International Conference on Learning Representations , year =
-
[33]
Expert Systems with Applications , volume =
Financial Fraud: A Review of Anomaly Detection Techniques and Recent Advances , author =. Expert Systems with Applications , volume =
-
[34]
Dataset Shift in Machine Learning , author =
-
[35]
You, Jiaxuan and Du, Tianyu and Leskovec, Jure , booktitle =
-
[36]
Proceedings of the 32nd International Conference on Machine Learning , pages =
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift , author =. Proceedings of the 32nd International Conference on Machine Learning , pages =
-
[37]
arXiv preprint arXiv:1907.07225 , year =
DeepTrax: Embedding Graphs of Financial Transactions , author =. arXiv preprint arXiv:1907.07225 , year =
-
[38]
Decision Support Systems , volume =
The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature , author =. Decision Support Systems , volume =
-
[39]
Journal of Machine Learning Research , volume =
Covariate Shift Adaptation by Importance Weighted Cross Validation , author =. Journal of Machine Learning Research , volume =
-
[40]
A theory of learning from different domains , author =. Machine Learning , volume =
-
[41]
Advances in Large Margin Classifiers , pages =
Probabilistic Outputs for Support Vector Machines and Comparisons to Regularized Likelihood Methods , author =. Advances in Large Margin Classifiers , pages =. 1999 , publisher =
work page 1999
-
[42]
Obtaining calibrated probability estimates from decision trees and naive
Zadrozny, Bianca and Elkan, Charles , booktitle =. Obtaining calibrated probability estimates from decision trees and naive
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.