Recognition: 2 theorem links
· Lean TheoremFrom Actions to Understanding: Conformal Interpretability of Temporal Concepts in LLM Agents
Pith reviewed 2026-05-14 22:29 UTC · model grok-4.3
The pith
Conformal prediction on step-wise rewards reveals linearly separable temporal concepts in LLM agent activations that align with task success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
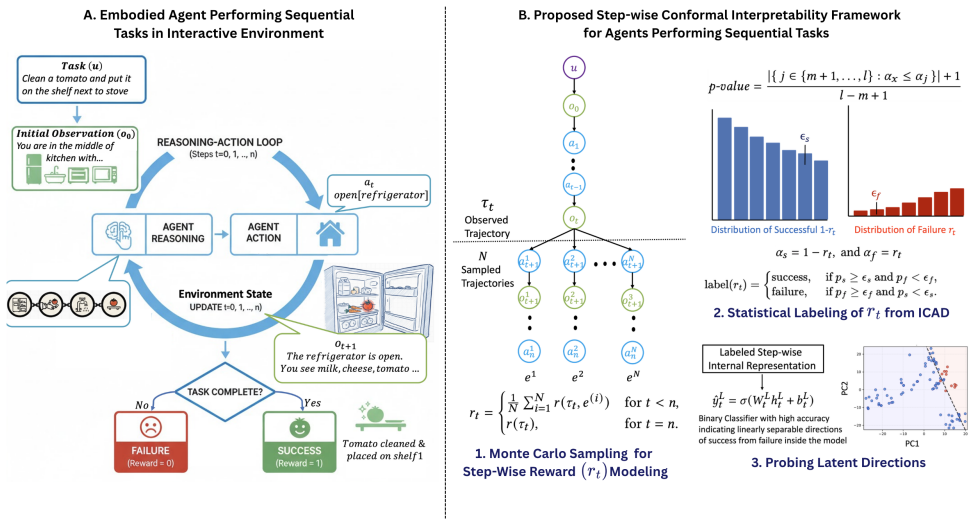
The authors claim that by applying conformal prediction to step-wise reward signals, one can statistically annotate an LLM agent's hidden states at each timestep, after which linear probes trained on those annotations recover directions in activation space that represent temporal concepts such as success or reasoning drift, and that these directions are linearly separable in the tested environments while correlating with overall task success.
What carries the argument
Conformal interpretability framework combining step-wise reward modeling and conformal prediction to label activations, followed by linear probing to extract temporal concept directions.
Load-bearing premise
That conformal prediction applied to step-wise reward models provides accurate, low-noise labels for the agent's internal representations at each step.
What would settle it
Finding a new interactive task where the trained linear probes achieve no better than random accuracy in separating successful from failing steps, or where steering does not improve outcomes.
Figures


read the original abstract
Large Language Models (LLMs) are increasingly deployed as autonomous agents capable of reasoning, planning, and acting within interactive environments. Despite their growing capability to perform multi-step reasoning and decision-making tasks, internal mechanisms guiding their sequential behavior remain opaque. This paper presents a framework for interpreting the temporal evolution of concepts in LLM agents through a step-wise conformal lens. We introduce the conformal interpretability framework for temporal tasks, which combines step-wise reward modeling with conformal prediction to statistically label model's internal representation at each step as successful or failing. Linear probes are then trained on these representations to identify directions of temporal concepts - latent directions in the model's activation space that correspond to consistent notions of success, failure or reasoning drift. Experimental results on two simulated interactive environments, namely ScienceWorld and AlfWorld, demonstrate that these temporal concepts are linearly separable, revealing interpretable structures aligned with task success. We further show preliminary results on improving an LLM agent's performance by leveraging the proposed framework for steering the identified successful directions inside the model. The proposed approach, thus, offers a principled method for early failure detection as well as intervention in LLM-based agents, paving the path towards trustworthy autonomous language models in complex interactive settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a conformal interpretability framework for LLM agents that combines step-wise reward modeling with conformal prediction to label internal activations at each timestep as successful or failing. Linear probes are then trained on these labeled representations to recover directions corresponding to temporal concepts such as success, failure, and reasoning drift. Experiments on ScienceWorld and AlfWorld are reported to show that these directions are linearly separable and aligned with task success, with preliminary results on using the directions for steering agent behavior toward improved performance.
Significance. If the labeling step is shown to be reliable, the framework would provide a statistically grounded method for interpreting and intervening in the sequential decision-making of LLM agents, with potential applications in early failure detection and trustworthy autonomy. The approach builds on standard linear probing and conformal techniques but applies them to temporal agent trajectories, which could be useful if the core separability result is robustly validated.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The central claim that temporal concepts are linearly separable rests on the step-wise reward model plus conformal prediction producing accurate success/failure labels. No quantitative validation (accuracy, calibration error, or agreement with simulator ground-truth outcomes) is reported for the labeling step on ScienceWorld or AlfWorld trajectories, leaving open the possibility that the recovered directions reflect reward-model artifacts rather than genuine internal representations.
- [§3] §3 (Method): The description of how conformal prediction is applied to produce per-step labels does not specify the nonconformity score, the calibration set construction, or how the reward model is trained (e.g., on proxy signals versus verified environment outcomes). Without these details, it is impossible to assess whether the labeling procedure introduces systematic bias that would undermine the subsequent linear-probe results.
minor comments (2)
- [Abstract] The abstract mentions 'preliminary results on improving an LLM agent's performance' via steering but provides no quantitative metrics, baselines, or statistical tests for the steering experiments.
- [§4] Figure captions and experimental tables should include error bars, number of runs, and exact definitions of the linear-probe metrics used to claim separability.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that identify key areas for strengthening the rigor and clarity of the manuscript. We address each major comment below and will revise the paper accordingly to incorporate the requested details and validations.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central claim that temporal concepts are linearly separable rests on the step-wise reward model plus conformal prediction producing accurate success/failure labels. No quantitative validation (accuracy, calibration error, or agreement with simulator ground-truth outcomes) is reported for the labeling step on ScienceWorld or AlfWorld trajectories, leaving open the possibility that the recovered directions reflect reward-model artifacts rather than genuine internal representations.
Authors: We agree that explicit quantitative validation of the labeling step is essential to substantiate the central claims. In the revised manuscript, we will add a dedicated subsection in §4 reporting accuracy, calibration error, and agreement with simulator ground-truth outcomes for the conformal labels on both ScienceWorld and AlfWorld trajectories. These results will demonstrate that the labels are reliable and that the recovered directions reflect genuine internal representations rather than artifacts. revision: yes
-
Referee: [§3] §3 (Method): The description of how conformal prediction is applied to produce per-step labels does not specify the nonconformity score, the calibration set construction, or how the reward model is trained (e.g., on proxy signals versus verified environment outcomes). Without these details, it is impossible to assess whether the labeling procedure introduces systematic bias that would undermine the subsequent linear-probe results.
Authors: We acknowledge that the current description of the conformal prediction procedure lacks necessary technical details. The revised §3 will fully specify the nonconformity score (defined as the absolute prediction error from the reward model), the construction of the calibration set (from held-out trajectories with verified environment outcomes), and the reward model training process (including the use of proxy signals versus ground-truth). These additions will enable readers to evaluate potential biases and ensure the labeling procedure is transparent. revision: yes
Circularity Check
No significant circularity detected; framework relies on standard external techniques
full rationale
The paper introduces a conformal interpretability framework that applies step-wise reward modeling and conformal prediction to label LLM activations, followed by training linear probes to detect temporal concepts. No equations, derivations, or self-citations are shown that reduce the claimed linear separability result to a fitted parameter or input by construction. The experimental demonstration on ScienceWorld and AlfWorld trajectories uses externally validated techniques (conformal prediction, linear probing) whose correctness does not depend on the target claim. The central result is presented as an empirical finding rather than a tautological renaming or self-referential definition, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce the conformal interpretability framework for temporal tasks, which combines step-wise reward modeling with conformal prediction to statistically label model's internal representation at each step as successful or failing. Linear probes are then trained on these representations to identify directions of temporal concepts
-
IndisputableMonolith/Cost/FunctionalEquation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Tables 1-6 report probe accuracy/F1 on ScienceWorld and AlfWorld trajectories; steering via RepE contrastive directions yields 1.1% accuracy gain
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Cheb- otar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, et al. Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Understanding inter- mediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding inter- mediate layers using linear classifier probes. InProceedings of the International Conference on Learning Representations (ICLR) Workshop Track, 2017. 3, 6
work page 2017
-
[4]
Vineeth Balasubramanian, Shen-Shyang Ho, and Vladimir V ovk.Conformal prediction for reliable machine learning: theory, adaptations and applications. Newnes, 2014. 3, 4
work page 2014
-
[5]
Llm explainability via at- tributive masking learning
Oren Barkan, Yonatan Toib, Yehonatan Elisha, Jonathan Weill, and Noam Koenigstein. Llm explainability via at- tributive masking learning. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 9522– 9537, 2024. 3
work page 2024
-
[6]
Toward univer- sal steering and monitoring of ai models.arXiv preprint arXiv:2502.03708, 2025
Daniel Beaglehole, Adityanarayanan Radhakrishnan, En- ric Boix-Adsera, and Mikhail Belkin. Toward univer- sal steering and monitoring of ai models.arXiv preprint arXiv:2502.03708, 2025. 1, 3
-
[7]
Real-time out- of-distribution detection in learning-enabled cyber-physical systems
Feiyang Cai and Xenofon Koutsoukos. Real-time out- of-distribution detection in learning-enabled cyber-physical systems. In2020 ACM/IEEE 11th International Conference on Cyber-Physical Systems (ICCPS), pages 174–183. IEEE,
-
[8]
Alexis Conneau, German Kruszewski, Guillaume Lample, Lo¨ıc Barrault, and Marco Baroni. What you can cram into a single $&!#* vector: Probing sentence embeddings for lin- guistic properties. InProceedings of the 56th Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2126–2136, Melbourne, Australia,
-
[9]
Association for Computational Linguistics. 3
-
[10]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600, 2023. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Achref Doula, Max M ¨uhlh¨auser, and Alejandro Sanchez Guinea. Safepath: conformal prediction for safe llm-based autonomous navigation.arXiv preprint arXiv:2505.09427,
-
[12]
Polysemantic dropout: Conformal ood detection for specialized llms
Ayush Gupta, Ramneet Kaur, Anirban Roy, Adam D Cobb, Rama Chellappa, and Susmit Jha. Polysemantic dropout: Conformal ood detection for specialized llms. InProceed- ings of the 2025 Conference on Empirical Methods in Natu- ral Language Processing, pages 11768–11781, 2025. 3
work page 2025
-
[13]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT), pages 4129–4138, 2019. 3 Distribution Statement “A” (Approved for Public Release, Distribution Unlimited)
work page 2019
-
[14]
Ehsan Hosseini-Asl, Bryan McCann, Chien-Sheng Wu, Semih Yavuz, and Richard Socher. A simple language model for task-oriented dialogue.Advances in Neural Information Processing Systems, 33:20179–20191, 2020. 3
work page 2020
-
[15]
Shiyuan Huang, Siddarth Mamidanna, Shreedhar Jangam, Yilun Zhou, and Leilani H Gilpin. Can large language models explain themselves? a study of llm-generated self- explanations.arXiv preprint arXiv:2310.11207, 2023. 3
-
[16]
Inner Monologue: Embodied Reasoning through Planning with Language Models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Em- bodied reasoning through planning with language models. arXiv preprint arXiv:2207.05608, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Understanding the planning of llm agents: A survey.CoRR, 2024
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. Understanding the planning of llm agents: A survey.CoRR, 2024. 1
work page 2024
-
[18]
idecode: In- distribution equivariance for conformal out-of-distribution detection
Ramneet Kaur, Susmit Jha, Anirban Roy, Sangdon Park13, Edgar Dobriban, Oleg Sokolsky, and Insup Lee. idecode: In- distribution equivariance for conformal out-of-distribution detection. 2022. 5, 7
work page 2022
-
[19]
Ramneet Kaur, Colin Samplawski, Adam D Cobb, Anir- ban Roy, Brian Matejek, Manoj Acharya, Daniel Elenius, Alexander M Berenbeim, John A Pavlik, Nathaniel D Bas- tian, et al. Addressing uncertainty in llms to enhance reliabil- ity in generative ai.arXiv preprint arXiv:2411.02381, 2024. 3
-
[20]
Ramneet Kaur, Yahan Yang, Oleg Sokolsky, and Insup Lee. Out-of-distribution detection in dependent data for cyber- physical systems with conformal guarantees.ACM Trans- actions on Cyber-Physical Systems, 8(4):1–27, 2024. 5
work page 2024
-
[21]
Towards understanding in-context learning with contrastive demonstrations and saliency maps
Fuxiao Liu. Towards understanding in-context learning with contrastive demonstrations and saliency maps. InNeurIPS 2024 Workshop on Scientific Methods for Understanding Deep Learning. 3
work page 2024
-
[22]
Open-world planning via lifted regression with llm-inferred affordances for embodied agents
Xiaotian Liu, Ali Pesaranghader, Hanze Li, Punyaphat Sukcharoenchaikul, Jaehong Kim, Tanmana Sadhu, Hye- jeong Jeon, and Scott Sanner. Open-world planning via lifted regression with llm-inferred affordances for embodied agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 20881–20...
work page 2025
-
[23]
Yang Liu, Weixing Chen, Yongjie Bai, Xiaodan Liang, Guanbin Li, Wen Gao, and Liang Lin. Aligning cyber space with physical world: A comprehensive survey on embodied ai.IEEE/ASME Transactions on Mechatronics, 2025. 7
work page 2025
-
[24]
Scott M Lundberg and Su-In Lee. A unified approach to interpreting model predictions.Advances in neural informa- tion processing systems, 30, 2017. 1
work page 2017
-
[25]
Faithful chain-of-thought reasoning
Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison- Burch. Faithful chain-of-thought reasoning. InProceedings of the 13th International Joint Conference on Natural Lan- guage Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: ...
work page 2023
-
[26]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in llm representations of true/false datasets. InProceedings of the Conference on Language Modeling (COLM), 2024. arXiv preprint arXiv:2310.06824. 3, 6, 8
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
WebGPT: Browser-assisted question-answering with human feedback
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332, 2021. 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Analyzing uncertainty of llm-as-a-judge: Inter- val evaluations with conformal prediction
Huanxin Sheng, Xinyi Liu, Hangfeng He, Jieyu Zhao, and Jian Kang. Analyzing uncertainty of llm-as-a-judge: Inter- val evaluations with conformal prediction. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 11297–11339, 2025. 3
work page 2025
-
[29]
Reflexion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. InThirty-seventh Con- ference on Neural Information Processing Systems. 3
-
[30]
Alfworld: Aligning text and embodied environments for in- teractive learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cote, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for in- teractive learning. InInternational Conference on Learning Representations. 1, 3, 7
-
[31]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks
Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10740–10749, 2020. 7
work page 2020
-
[32]
Ricl: Adding in-context adaptability to pre- trained vision-language-action models
Kaustubh Sridhar, Souradeep Dutta, Dinesh Jayaraman, and Insup Lee. Ricl: Adding in-context adaptability to pre- trained vision-language-action models. In9th Annual Con- ference on Robot Learning. 1
-
[33]
Bert rediscov- ers the classical nlp pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. Bert rediscov- ers the classical nlp pipeline. InProceedings of the 57th Annual Meeting of the Association for Computational Lin- guistics (ACL), pages 4593–4601, 2019. 3
work page 2019
-
[34]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023. 1, 2, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Harit Vishwakarma, Alan Mishler, Thomas Cook, Niccolo Dalmasso, Natraj Raman, and Sumitra Ganesh. Prune’n pre- dict: Optimizing llm decision-making with conformal pre- diction.arXiv preprint arXiv:2501.00555, 2024. 3
-
[36]
Springer Science & Business Media, 2005
Vladimir V ovk, Alex Gammerman, and Glenn Shafer.Al- gorithmic learning in a random world. Springer Science & Business Media, 2005. 5
work page 2005
-
[37]
Jun Wang, David Smith Sundarsingh, Jyotirmoy V Desh- mukh, and Yiannis Kantaros. Conformalnl2ltl: Translating natural language instructions into temporal logic formulas with conformal correctness guarantees. 1
-
[38]
Jiahao Wang, Mingyue Cheng, and Qi Liu. Can slow- thinking llms reason over time? empirical studies in time series forecasting.arXiv e-prints, pages arXiv–2505, 2025. 3
work page 2025
-
[39]
Ruoyao Wang, Peter Jansen, Marc-Alexandre C ˆot´e, and Prithviraj Ammanabrolu. Scienceworld: Is your agent Distribution Statement “A” (Approved for Public Release, Distribution Unlimited). smarter than a 5th grader? InProceedings of the 2022 Con- ference on Empirical Methods in Natural Language Process- ing, pages 11279–11298, 2022. 1, 3, 6
work page 2022
-
[40]
Tianyu Wu, Shizhu He, Jingping Liu, Siqi Sun, Kang Liu, Qing-Long Han, and Yang Tang. A brief overview of chat- gpt: The history, status quo and potential future develop- ment.IEEE/CAA Journal of Automatica Sinica, 10(5):1122– 1136, 2023. 3
work page 2023
-
[41]
Xiaoying Xing, Chia-Wen Kuo, Li Fuxin, Yulei Niu, Fan Chen, Ming Li, Ying Wu, Longyin Wen, and Sijie Zhu. Where do large vision-language models look at when an- swering questions?arXiv e-prints, pages arXiv–2503, 2025. 1
work page 2025
-
[42]
Watch every step! llm agent learning via iterative step-level pro- cess refinement
Weimin Xiong, Yifan Song, Xiutian Zhao, Wenhao Wu, Xun Wang, Ke Wang, Cheng Li, Wei Peng, and Sujian Li. Watch every step! llm agent learning via iterative step-level pro- cess refinement. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1556–1572, 2024. 2, 3, 4, 5
work page 2024
-
[43]
Yahan Yang, Ramneet Kaur, Souradeep Dutta, and Insup Lee. Memory-based distribution shift detection for learn- ing enabled cyber-physical systems with statistical guaran- tees.ACM Transactions on Cyber-Physical Systems, 8(2): 1–28, 2024. 5
work page 2024
-
[44]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022. 3, 4, 7
work page 2022
-
[45]
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Za- ibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, et al. The landscape of agentic reinforce- ment learning for llms: A survey.arXiv e-prints, pages arXiv–2509, 2025. 7
work page 2025
-
[46]
Jiahui Zhou, Dan Li, Lin Li, Zhuomin Chen, Shunyu Wu, Haozheng Ye, Jian Lou, and Costas J Spanos. Enhancing llm reasoning for time series classification by tailored thinking and fused decision.arXiv e-prints, pages arXiv–2506, 2025. 3
work page 2025
-
[47]
Representation engineering: A top-down approach to ai transparency.CoRR,
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to ai transparency.CoRR,
-
[48]
Supplementary Material 7.1. Task Examples from ScienceWorld and Alf- World Figure 3 illustrates a representative task, “Testing Con- ductivity” in ScienceWorld, along with the corresponding action-observation trajectory, and Figure 3 shows an exam- ple trajectory of the agent-environment interaction on one of the household’s task of “cleaning a tomato and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.