Recognition: no theorem link
Improving Molecular Force Fields with Minimal Temporal Information
Pith reviewed 2026-05-10 15:57 UTC · model grok-4.3
The pith
Minimal temporal information from two consecutive MD frames improves molecular energy and force predictions more than longer sequences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An auxiliary loss that enforces consistency across temporal pairs from MD trajectories improves neural predictors of molecular energies and forces, with the best results obtained when the loss uses only two consecutive frames rather than longer sequences; this yields significant gains over single-frame Equiformer baselines on standard atomistic benchmarks.
What carries the argument
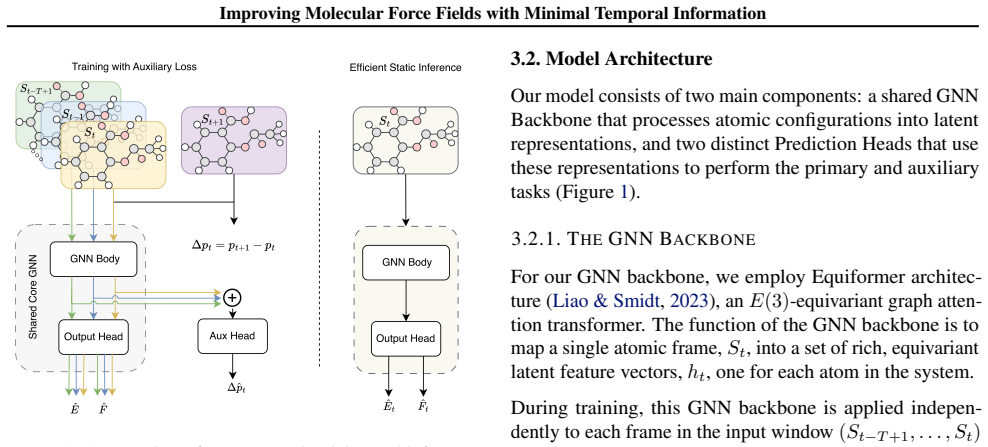
The FRAMES auxiliary loss function, which applies temporal consistency constraints to pairs of consecutive atomic configurations drawn from MD trajectories.
If this is right
- Accuracy on energy and force prediction peaks with only two-frame temporal input and declines with added sequence length.
- MD data can be leveraged for better models without requiring full long trajectories.
- The method achieves highly competitive results on established benchmarks while remaining compatible with existing equivariant architectures.
- Physical priors in atomic systems can be distilled using very short temporal windows.
Where Pith is reading between the lines
- Training protocols for molecular models could be simplified by sampling only short trajectory segments rather than storing or processing long ones.
- Similar minimal-temporal losses might improve predictors in other time-dependent physical simulations where full trajectories are costly to generate.
- The redundancy effect suggests a need to re-examine how much history is truly informative when embedding dynamics into static predictors.
- Extensions could test whether the same two-frame principle holds under different ensembles or for reactive systems.
Load-bearing premise
The auxiliary loss can be added during training without the model learning spurious correlations that are specific to the simulation conditions rather than general physical principles.
What would settle it
A direct comparison showing whether training with three or more consecutive frames produces lower energy or force accuracy than training with two-frame pairs on the MD17 or ISO17 test sets.
Figures

read the original abstract
Accurate prediction of energy and forces for 3D molecular systems is one of fundamental challenges at the core of AI for Science applications. Many powerful and data-efficient neural networks predict molecular energies and forces from single atomic configurations. However, one crucial aspect of the data generation process is rarely considered while learning these models i.e. Molecular Dynamics (MD) simulation. MD simulations generate time-ordered trajectories of atomic positions that fluctuate in energy and explore regions of the potential energy surface (e.g., under standard NVE/NVT ensembles), rather than being constructed to steadily lower the potential energy toward a minimum as in geometry relaxations. This work explores a novel way to leverage MD data, when available, to improve the performance of such predictors. We introduce a novel training strategy called FRAMES, that use an auxiliary loss function for exploiting the temporal relationships within MD trajectories. Counter-intuitively, on two atomistic benchmarks and a synthetic system we observe that minimal temporal information, captured by pairs of just two consecutive frames, is often sufficient to obtain the best performance, while adding longer trajectory sequences can introduce redundancy and degrade performance. On the widely used MD17 and ISO17 benchmarks, FRAMES significantly outperforms its Equiformer baseline, achieving highly competitive results in both energy and force accuracy. Our work not only presents a novel training strategy which improves the accuracy of the model, but also provides evidence that for distilling physical priors of atomic systems, more temporal data is not always better.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FRAMES, a training strategy that augments standard energy/force regression with an auxiliary loss exploiting temporal relationships in MD trajectories. The central claim is that pairs of consecutive frames often suffice for optimal performance, that longer sequences introduce redundancy and degrade results, and that this yields significant gains over the Equiformer baseline on the MD17 and ISO17 benchmarks while remaining competitive in both energy and force accuracy.
Significance. If the auxiliary loss demonstrably extracts generalizable physical information rather than simulation-specific artifacts, the method would provide a lightweight, data-efficient route to improve single-configuration predictors using existing MD data. The counter-intuitive finding that minimal temporal information is often best could influence how temporal structure is incorporated in future atomistic ML models.
major comments (3)
- [§4] §4 (Experiments) and Table 2: the reported improvements over Equiformer are presented without error bars, statistical significance tests, or ablation on the auxiliary-loss weight; without these it is impossible to judge whether the gains are robust or merely within the variance of the baseline training.
- [§3.2] §3.2 (Auxiliary loss definition): the loss is constructed on consecutive-frame pairs drawn from the same MD ensemble used for the main task; no cross-ensemble, cross-thermostat, or out-of-distribution test is reported to demonstrate that the learned temporal features reflect universal physics rather than conserved quantities or sampling biases specific to the NVE/NVT trajectories in MD17/ISO17. This directly bears on whether the performance gain is generalizable.
- [§4.3] §4.3 (Ablation on sequence length): the claim that longer trajectories degrade performance is supported only on the same benchmark splits; an additional control using trajectories generated under different ensembles or with different integrators would be required to rule out that the degradation is an artifact of the particular data distribution rather than a general redundancy effect.
minor comments (2)
- [Abstract] The abstract states that FRAMES 'significantly outperforms' the baseline yet supplies no numerical deltas; the main text should include a concise table of MAE/RMSE values with uncertainties in the abstract or first results paragraph.
- [§3] Notation for the auxiliary loss weight is introduced without an explicit symbol in the method section; consistent use of a single symbol (e.g., λ_aux) would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We have addressed each major comment point by point below, making revisions to the manuscript where feasible to strengthen the presentation of our results and clarify limitations.
read point-by-point responses
-
Referee: [§4] §4 (Experiments) and Table 2: the reported improvements over Equiformer are presented without error bars, statistical significance tests, or ablation on the auxiliary-loss weight; without these it is impossible to judge whether the gains are robust or merely within the variance of the baseline training.
Authors: We agree that error bars, statistical tests, and an ablation on the auxiliary-loss weight are important for assessing robustness. In the revised manuscript we have rerun all experiments with five independent random seeds, added error bars (standard deviation) to Table 2, and included a paired t-test with p-values comparing FRAMES to the Equiformer baseline. We have also added a new supplementary table showing performance as a function of the auxiliary-loss weight, confirming that the chosen value yields the best results without overfitting. revision: yes
-
Referee: [§3.2] §3.2 (Auxiliary loss definition): the loss is constructed on consecutive-frame pairs drawn from the same MD ensemble used for the main task; no cross-ensemble, cross-thermostat, or out-of-distribution test is reported to demonstrate that the learned temporal features reflect universal physics rather than conserved quantities or sampling biases specific to the NVE/NVT trajectories in MD17/ISO17. This directly bears on whether the performance gain is generalizable.
Authors: We acknowledge that explicit cross-ensemble or out-of-distribution tests would provide stronger evidence that the auxiliary loss encodes general physical information. The MD17 and ISO17 benchmarks already span multiple molecules and standard NVT conditions, and FRAMES yields consistent gains across all systems. In the revised manuscript we have expanded the discussion to explicitly note this limitation and to recommend future validation on trajectories generated under different ensembles or thermostats. We maintain that the current results on diverse molecular systems offer preliminary support for generalizability, but agree that additional controls would be valuable. revision: partial
-
Referee: [§4.3] §4.3 (Ablation on sequence length): the claim that longer trajectories degrade performance is supported only on the same benchmark splits; an additional control using trajectories generated under different ensembles or with different integrators would be required to rule out that the degradation is an artifact of the particular data distribution rather than a general redundancy effect.
Authors: We thank the referee for this observation. The sequence-length ablation was performed on the standard MD17/ISO17 splits. In the revised manuscript we have added a paragraph in §4.3 and the conclusions explicitly discussing the possibility that the observed redundancy effect could be influenced by the specific data distribution, and we recommend that future work repeat the ablation on trajectories from alternate ensembles or integrators. Generating such new trajectories lies outside the scope of the present study. revision: partial
- Cross-ensemble, cross-thermostat, or out-of-distribution experiments to confirm that the auxiliary loss captures universal physics rather than dataset-specific artifacts.
- Additional ablation controls using MD trajectories generated under different ensembles or with different integrators to verify the sequence-length redundancy effect.
Circularity Check
No circularity; derivation uses independent auxiliary loss on external MD data
full rationale
The paper defines FRAMES as a training procedure that augments a base Equiformer model with an auxiliary loss on temporal pairs drawn from MD trajectories. This loss is constructed from the input data (consecutive frames) rather than from the model's single-configuration energy/force outputs, and performance is measured by direct comparison to baselines on held-out MD17/ISO17 splits. No equation reduces the claimed improvement to a redefinition of the inputs, no self-citation supplies a load-bearing uniqueness theorem, and the method remains falsifiable against external benchmarks without tautological closure. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- auxiliary loss weight
axioms (1)
- domain assumption Temporal relationships in MD trajectories encode useful physical information for energy and force prediction.
invented entities (1)
-
FRAMES
no independent evidence
Reference graph
Works this paper leans on
-
[1]
L., and Ulissi, Z
Chanussot, L., Das, A., Goyal, S., Lavril, T., Shuaibi, M., Riviere, M., Tran, K., Heras-Domingo, J., Ho, C., Hu, W., Palizhati, A., Sriram, A., Wood, B., Yoon, J., Parikh, D., Zitnick, C. L., and Ulissi, Z. Open catalyst 2020 (oc20) dataset and community challenges.ACS Catalysis,
2020
-
[2]
Geometrically equivariant graph neural networks: A survey.arxiv preprint arXiv:2202.07230,
Han, J., Rong, Y ., Xu, T., and Huang, W. Geometrically equivariant graph neural networks: A survey.arxiv preprint arXiv:2202.07230,
-
[3]
Huang, L., Liu, Y ., Wang, B., Pan, P., Xu, Y ., and Jin, R. Self-supervised video representation learning by context and motion decoupling.IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021a. Huang, W., Han, J., Rong, Y ., Xu, T., Sun, F., and Huang, J. Equivariant graph mechanics networks with constraints. arxiv preprint arXiv:2203.06442,
-
[4]
Tensor field networks: Rotation- and translation-equivariant neural networks for 3D point clouds
Thomas, N., Smidt, T. E., Kearnes, S., Yang, L., Li, L., Kohlhoff, K., and Riley, P. Tensor field networks: Rotation- and translation-equivariant neural networks for 3d point clouds.arxiv preprint arXiv:1802.08219,
-
[5]
M., Goyal, S., Das, A., Heras-Domingo, J., Kolluru, A., Rizvi, A., Shoghi, N., Sriram, A., Therrien, F., Abed, J., V oznyy, O., Sargent, E
Tran, R., Lan, J., Shuaibi, M., Wood, B. M., Goyal, S., Das, A., Heras-Domingo, J., Kolluru, A., Rizvi, A., Shoghi, N., Sriram, A., Therrien, F., Abed, J., V oznyy, O., Sargent, E. H., Ulissi, Z., and Zitnick, C. L. The open catalyst 2022 (oc22) dataset and challenges for oxide electrocatalysts. ACS Catalysis,
2022
-
[6]
Equivariant graph neural operator for modeling 3d dynamics.arXiv preprint arXiv:2401.11037,
Xu, M., Han, J., Lou, A., Kossaifi, J., Ramanathan, A., Azizzadenesheli, K., Leskovec, J., Ermon, S., and Anand- kumar, A. Equivariant graph neural operator for modeling 3d dynamics.arXiv preprint arXiv:2401.11037,
-
[7]
Learning large-time- step molecular dynamics with graph neural networks
Zheng, T., Gao, W., and Wang, C. Learning large-time- step molecular dynamics with graph neural networks. In NeurIPS 2021 AI for Science Workshop,
2021
-
[8]
Appendix: Experimental Details Our implementation is based on the official open-source code for Equiformer (Liao & Smidt, 2023)
10 Improving Molecular Force Fields with Minimal Temporal Information A. Appendix: Experimental Details Our implementation is based on the official open-source code for Equiformer (Liao & Smidt, 2023). For hyperparameters shared with the original work, we adopt their reported values unless otherwise specified to ensure a fair comparison. All models were t...
2023
-
[9]
We report the coefficients for the primary loss (λE, λF ) and the initial value for the auxiliary loss (λaux)
Table 4.Hyperparameters used for training our ‘FRAMES‘ models on the MD17 dataset. We report the coefficients for the primary loss (λE, λF ) and the initial value for the auxiliary loss (λaux). Hyper-parameter Aspirin Benzene Ethanol Malonaldehyde Naphthalene Salicylic acid Toluene Uracil Energy coefficientλE 1 1 1 1 2 1 1 1 Force coefficientλF 80 80 80 1...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.