Recognition: unknown
Forage V2: Knowledge Evolution and Transfer in Autonomous Agent Organizations
Pith reviewed 2026-05-10 03:11 UTC · model grok-4.3
The pith
Weaker agents seeded with stronger agents' accumulated knowledge close most of a coverage gap while halving costs and converging faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
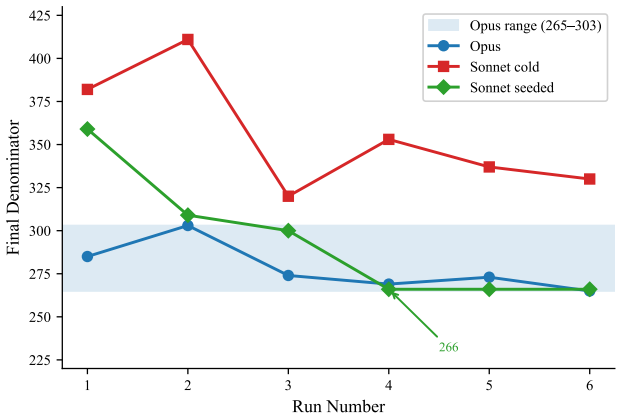
The paper establishes that an autonomous agent organization accumulates knowledge entries over successive runs, growing from zero to dozens of entries while denominator estimates stabilize. It further shows that transferring those entries as readable documents from a stronger model to a weaker one reduces a 6.6 percentage point coverage gap to 1.1 points, cuts cost in half, and shortens convergence time, with three independent seeded runs all arriving at the identical denominator value.
What carries the argument
Organizational memory: knowledge entries stored as readable documents together with institutional safeguards such as audit separation and contract protocols that keep the record accurate and transferable.
If this is right
- Knowledge entries grow and estimates stabilize over multiple runs as domain understanding deepens.
- Seeded weaker agents achieve nearly the same coverage as stronger agents at lower cost and in fewer rounds.
- The same transferred knowledge produces identical denominator estimates in independent runs.
- The accumulated experience is model-agnostic and can be inherited by any future agent regardless of provider.
- Institutional design elements like audit separation prevent knowledge degradation during transfer.
Where Pith is reading between the lines
- Persistent organizations could let teams of agents improve indefinitely without each new member starting from scratch.
- The approach may generalize beyond the tested tasks to any setting where completeness is hard to define in advance.
- Future tests could examine whether the same documents remain effective when transferred to models with even larger capability differences.
Load-bearing premise
Knowledge entries captured as readable documents remain accurate and usable by agents of different capabilities without loss of context or introduction of errors when transferred across runs and models.
What would settle it
A weaker agent given the transferred documents still produces a large remaining coverage gap or inconsistent denominator estimates across repeated runs.
Figures




read the original abstract
Autonomous agents operating in open-world tasks -- where the completion boundary is not given in advance -- face denominator blindness: they systematically underestimate the scope of the target space. Forage V1 addressed this through co-evolving evaluation (an independent Evaluator discovers what "complete" means) and method isolation (Evaluator and Planner cannot see each other's code). V2 extends the architecture from a single expedition to a learning organization: experience accumulates across runs, transfers across model capabilities, and institutional safeguards prevent knowledge degradation. We demonstrate two claims across three task types (web scraping, API queries, mathematical reasoning). Knowledge accumulation: over six runs, knowledge entries grow from 0 to 54, and denominator estimates stabilize as domain understanding deepens. Knowledge transfer: a weaker agent (Sonnet) seeded with a stronger agent's (Opus) knowledge narrows a 6.6pp coverage gap to 1.1pp, halves cost (9.40 to 5.13 USD), converges in half the rounds (mean 4.5 vs. 7.0), and three independent seeded runs arrive at exactly the same denominator estimate (266), suggesting organizational knowledge calibrates evaluation itself. V2's contribution is architectural: it designs institutions -- audit separation, contract protocols, organizational memory -- that make any agent more reliable upon entry. The accumulated experience is organizational, model-agnostic, and transferable, stored as readable documents that any future agent inherits regardless of provider or capability level.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Forage V2, which builds on Forage V1 by adding organizational memory to autonomous agent systems. This allows knowledge to accumulate over multiple runs and transfer across agents of different capabilities (e.g., from Opus to Sonnet models). The central claims are that this architecture mitigates denominator blindness in open-world tasks, with evidence from knowledge growth (0 to 54 entries) and transfer benefits including reduced coverage gap (6.6pp to 1.1pp), lower costs (9.40 to 5.13 USD), faster convergence (7.0 to 4.5 rounds), and exact replication of denominator estimates (266) across runs.
Significance. Should the empirical results prove robust to controls and ablations, the paper offers a novel architectural approach to building learning organizations of agents. The emphasis on model-agnostic, readable knowledge documents and institutional safeguards (audit separation, contract protocols) could have broad implications for scalable, reliable autonomous systems in AI.
major comments (2)
- [Abstract] The interpretation of the exact match in denominator estimate (266) across three independent seeded runs as evidence of calibration via organizational knowledge is not supported without additional evidence. An ablation study removing entries related to the denominator or an external check against ground truth would be necessary to rule out direct propagation of specific values from the transferred knowledge.
- [Abstract / Results] Specific quantitative claims are made (e.g., coverage gap narrowing, cost halving, round reduction) but the abstract and available description provide no information on experimental methods, controls, statistical details, or data. This is a load-bearing issue for verifying the soundness of the transfer results.
minor comments (2)
- [Abstract] The three task types are listed but not described; adding one-sentence examples for each would improve clarity.
- Consider adding a figure or table summarizing the knowledge accumulation over the six runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, indicating where we will revise the paper to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [Abstract] The interpretation of the exact match in denominator estimate (266) across three independent seeded runs as evidence of calibration via organizational knowledge is not supported without additional evidence. An ablation study removing entries related to the denominator or an external check against ground truth would be necessary to rule out direct propagation of specific values from the transferred knowledge.
Authors: We acknowledge that the exact replication of the denominator estimate alone is suggestive rather than conclusive, as it could in principle reflect indirect propagation of related insights. The transferred knowledge consists of readable, high-level documents containing domain insights and procedural guidelines, not explicit numerical targets. To address this directly, we will add an ablation study to the revised manuscript in which we remove or mask all entries potentially related to denominator estimation and re-run the transfer experiments to test whether convergence to 266 persists. Where ground truth is determinable (particularly in the mathematical reasoning tasks), we will also report direct comparisons between the estimated and true denominators. These additions will appear in the Results and Discussion sections. revision: yes
-
Referee: [Abstract / Results] Specific quantitative claims are made (e.g., coverage gap narrowing, cost halving, round reduction) but the abstract and available description provide no information on experimental methods, controls, statistical details, or data. This is a load-bearing issue for verifying the soundness of the transfer results.
Authors: We agree that the abstract is concise by design and omits methodological specifics, which can hinder immediate verification of the quantitative claims. The full manuscript contains a dedicated Experimental Setup section that details the three task types, the specific models (Claude Opus and Sonnet), seeding procedures, run counts, transfer protocols, and metrics for coverage, cost, and convergence. We will revise the abstract to include a brief summary sentence on the experimental framework and will add explicit references to the methods section. In addition, we will expand the Results section with further statistical details, including the exact number of independent runs and any observed variance, to make the evidence more transparent and load-bearing. revision: yes
Circularity Check
No significant circularity; results are empirical observations without derivations or self-referential fits.
full rationale
The paper presents an architectural extension of prior agent systems through experimental runs on web scraping, API queries, and mathematical reasoning tasks. Knowledge growth is reported as a direct count (0 to 54 entries) and performance metrics (coverage gaps, costs, convergence rounds, and a repeated denominator value) are framed as observed outcomes across seeded and unseeded runs. No equations, fitted parameters, or derivation chains appear in the provided text. Claims rest on measured experimental results rather than quantities defined in terms of themselves or load-bearing self-citations that reduce to unverified premises. This is self-contained empirical work with no reduction of predictions to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Agents suffer from denominator blindness in open-world tasks where completion boundaries are undefined
- domain assumption Knowledge can be stored as readable documents that transfer effectively across model capabilities without degradation
invented entities (1)
-
organizational memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lu, Chris and Lu, Cong and Lange, Robert Tjarko and Foerster, Jakob and Clune, Jeff and Ha, David , journal=. The
-
[2]
2026 , howpublished=
autoresearch: Automated Machine Learning Research , author=. 2026 , howpublished=
2026
-
[3]
Trends in Chemistry , volume=
Next-Generation Experimentation with Self-Driving Laboratories , author=. Trends in Chemistry , volume=
-
[4]
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P and Zhang, Hao and Gonzalez, Joseph E and Stoica, Ion , journal=. Judging
-
[6]
Wang, Rui and Lehman, Joel and Clune, Jeff and Stanley, Kenneth O , journal=
-
[7]
Enhanced
Wang, Rui and Lehman, Joel and Rawal, Aditya and Zhi, Jiale and Li, Yulun and Clune, Jeff and Stanley, Kenneth O , journal=. Enhanced
-
[8]
1986 , publisher=
Foraging Theory , author=. 1986 , publisher=
1986
-
[9]
Theoretical Population Biology , volume=
Optimal Foraging, the Marginal Value Theorem , author=. Theoretical Population Biology , volume=
-
[10]
Yale Law Journal , volume=
Probability Neglect: Emotions, Worst Cases, and Law , author=. Yale Law Journal , volume=
-
[11]
2024 , howpublished=
Scrapy: A Fast High-Level Web Crawling and Web Scraping Framework , author=. 2024 , howpublished=
2024
-
[12]
2024 , howpublished=
browser-use:. 2024 , howpublished=
2024
-
[13]
Assaf Elovic , year=
-
[14]
2025 , note=
Automated Harness Search for Terminal-Bench 2.0 , author=. 2025 , note=
2025
-
[16]
2026 , howpublished=
Kimi. 2026 , howpublished=
2026
-
[17]
arXiv preprint , year=
Forage: Solving Denominator Blindness in Autonomous Agents via Co-Evolving Evaluation , author=. arXiv preprint , year=
-
[18]
2026 , howpublished=
Automated Weak-to-Strong Researcher , author=. 2026 , howpublished=
2026
-
[19]
2025 , howpublished=
Claude Code:. 2025 , howpublished=
2025
-
[20]
2025 , howpublished=
Building Effective Agents , author=. 2025 , howpublished=
2025
-
[21]
arXiv preprint , year=
Hermes: A Self-Improving Agent Framework , author=. arXiv preprint , year=
-
[22]
Zhang, Shengtao and Wang, Jiaqian and Zhou, Ruiwen and Liao, Junwei and Feng, Yuchen and others , journal=
-
[26]
Agent Laboratory: Using
Schmidgall, Samuel and others , year=. Agent Laboratory: Using
-
[27]
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and Awadallah, Ahmed Hassan and White, Ryen W and Burger, Doug and Wang, Chi , journal=
-
[28]
Hong, Sirui and Zhuge, Mingchen and Chen, Jonathan and Zheng, Xiawu and Cheng, Yuheng and Zhang, Ceyao and Wang, Jinlin and Wang, Zili and Yau, Steven Ka Shing and Lin, Zijuan and Zhou, Liyang and Ran, Chenyu and Xiao, Lingfeng and Wu, Chenglin and Schmidhuber, Jurgen , journal=
-
[29]
2026 , howpublished=
Symphony: Autonomous Coding Agent Orchestration , author=. 2026 , howpublished=
2026
-
[30]
Claude Blog , year=
Multi-Agent Coordination Patterns: Five Approaches and When to Use Them , author=. Claude Blog , year=
-
[31]
2025 , note=
Routa: Multi-Agent Team Management Framework , author=. 2025 , note=
2025
-
[32]
Mohammed Abouzaid, Andrew J. Blumberg, Martin Hairer, Joe Kileel, Tamara G. Kolda, Paul D. Nelson, Daniel Spielman, Nikhil Srivastava, Rachel Ward, Shmuel Weinberger, and Lauren Williams. First proof. arXiv preprint arXiv:2602.05192, 2026. Ten research-level mathematics questions with encrypted answers for AI evaluation
-
[33]
Claude code: AI -powered software engineering
Anthropic . Claude code: AI -powered software engineering. https://docs.anthropic.com/en/docs/claude-code, 2025 a
2025
-
[34]
Building effective agents
Anthropic . Building effective agents. https://docs.anthropic.com/en/docs/build-with-claude/agentic, 2025 b
2025
-
[35]
Automated weak-to-strong researcher
Anthropic . Automated weak-to-strong researcher. https://alignment.anthropic.com/2026/automated-w2s-researcher/, 2026. PGR 0.97 via automated agent configuration search with human-designed metrics
2026
-
[36]
Widesearch: Benchmarking agentic broad info-seeking.arXiv preprint arXiv:2508.07999, 2025
ByteDance Research . WideSearch : A benchmark for comprehensive information-seeking tasks. arXiv preprint arXiv:2508.07999, 2025
-
[37]
Hermes: A self-improving agent framework
Hermes Team . Hermes: A self-improving agent framework. arXiv preprint, 2025. Cross-episode knowledge accumulation for autonomous agents
2025
-
[38]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Ceyao Zhang, Jinlin Wang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jurgen Schmidhuber. MetaGPT : Meta programming for a multi-agent collaborative framework. arXiv preprint arXiv:2308.00352, 2023
work page internal anchor Pith review arXiv 2023
-
[39]
autoresearch: Automated machine learning research
Andrej Karpathy. autoresearch: Automated machine learning research. https://github.com/karpathy/autoresearch, 2026. Accessed: 2026-04-01
2026
-
[40]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist: Towards fully automated open-ended scientific discovery. arXiv preprint arXiv:2408.06292, 2024
work page internal anchor Pith review arXiv 2024
-
[41]
Kimi K2.6 : Agent swarm coordination at scale
Moonshot AI . Kimi K2.6 : Agent swarm coordination at scale. https://www.kimi.com/blog/kimi-k2-6, 2026. Centralized coordinator scaling to 300 sub-agents across 4000 coordinated steps
2026
-
[42]
Symphony: Autonomous coding agent orchestration
OpenAI . Symphony: Autonomous coding agent orchestration. https://github.com/openai/symphony, 2026. Persistent daemon connecting project management tools to autonomous agent execution
2026
-
[43]
Multi-agent coordination patterns: Five approaches and when to use them
Cara Phillips, Eugene Yan, Jiri De Jonghe, and Samuel Weller. Multi-agent coordination patterns: Five approaches and when to use them. Claude Blog, 2026
2026
-
[44]
Routa: Multi-agent team management framework, 2025
Routa Team . Routa: Multi-agent team management framework, 2025. Centralized coordination for multi-agent teams
2025
-
[45]
Agent laboratory: Using LLM agents as research assistants, 2025
Samuel Schmidgall et al. Agent laboratory: Using LLM agents as research assistants, 2025
2025
-
[46]
Are your agents upward deceivers? arXiv preprint arXiv:2512.04864, 2025
Upward Deception Team . Upward deception: Can LLM s deceive their supervisors through self-assessment? arXiv preprint arXiv:2512.04864, 2025
-
[47]
arXiv preprint arXiv:2502.15840 , year =
Vending-Bench Team . Vending-bench: Benchmarking AI agent decision-making in simulated business environments. arXiv preprint arXiv:2502.15840, 2025
-
[48]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review arXiv 2023
-
[49]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. AutoGen : Enabling next-gen LLM applications via multi-agent conversation. arXiv preprint arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
Forage: Solving denominator blindness in autonomous agents via co-evolving evaluation
Huaqing Xie. Forage: Solving denominator blindness in autonomous agents via co-evolving evaluation. arXiv preprint, 2026. arXiv ID 7447726
2026
-
[51]
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, et al. MemRL : Self-evolving agents via runtime reinforcement learning on episodic memory. arXiv preprint arXiv:2601.03192, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.