Recognition: unknown
X-PCR: A Benchmark for Cross-modality Progressive Clinical Reasoning in Ophthalmic Diagnosis
Pith reviewed 2026-05-10 00:57 UTC · model grok-4.3
The pith
The X-PCR benchmark reveals critical gaps in multi-modal AI models for progressive reasoning and cross-modal integration in eye disease diagnosis.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
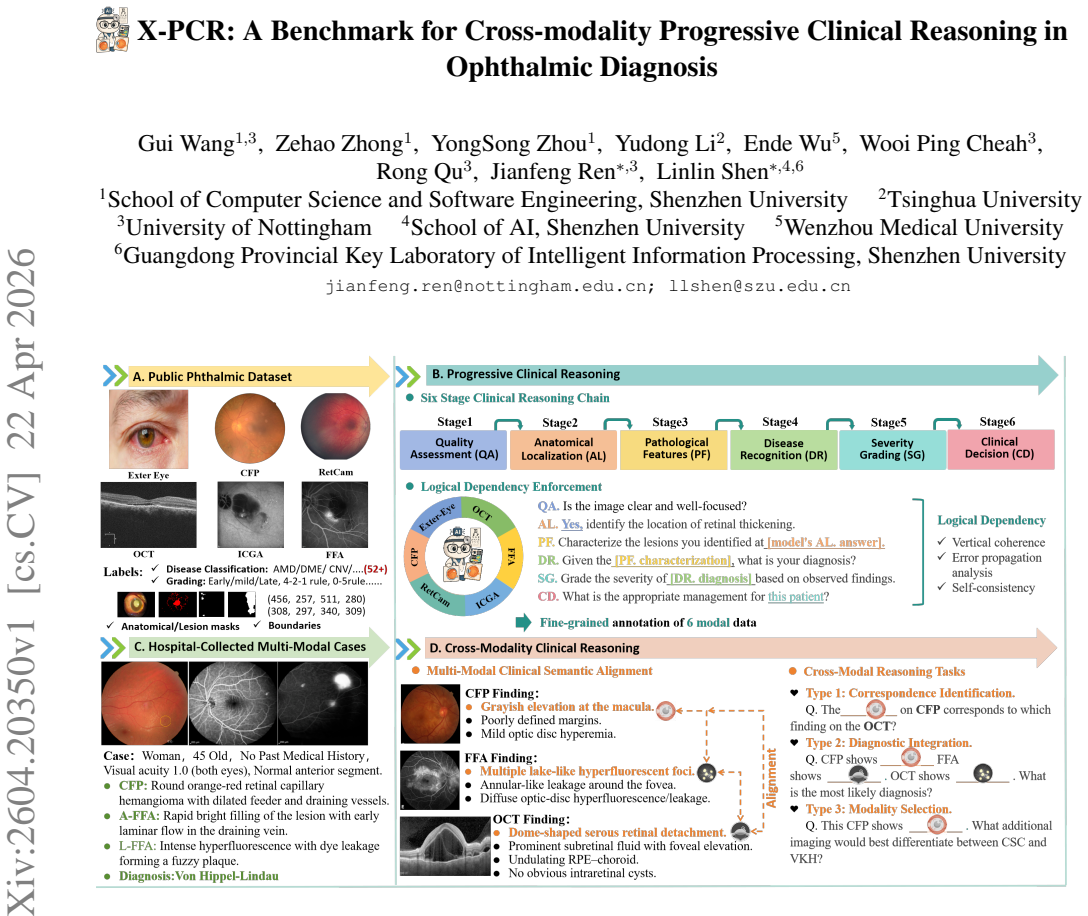
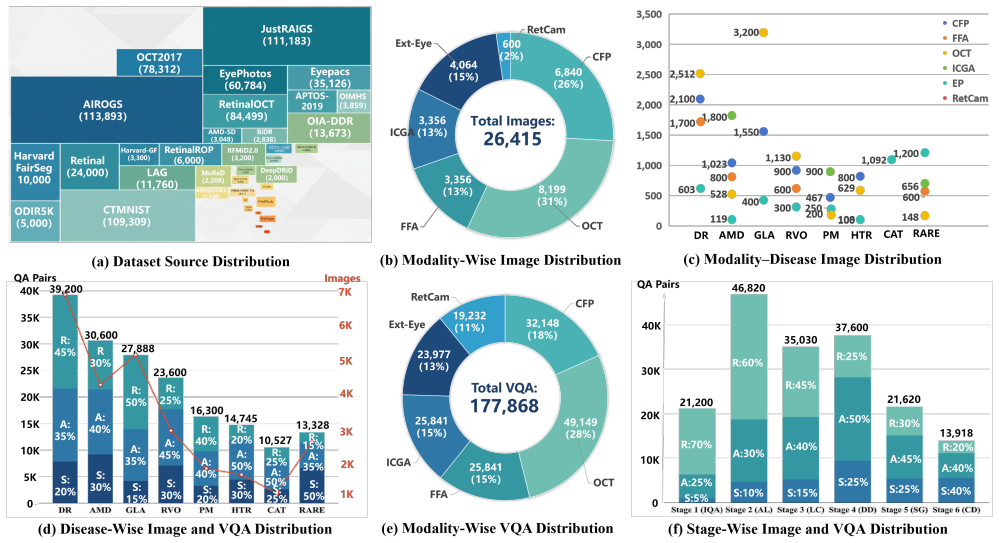
The authors establish the X-PCR benchmark as the first comprehensive evaluation framework for MLLMs in ophthalmology, featuring a six-stage progressive reasoning chain and a cross-modality reasoning task. Through testing 21 MLLMs on this benchmark with its large collection of images and VQA pairs, the work demonstrates significant deficiencies in the models' capacity for progressive reasoning and cross-modal integration.
What carries the argument
The X-PCR benchmark, defined by its six-stage progressive reasoning chain from image quality assessment to clinical decision-making and its cross-modality reasoning task that integrates six imaging modalities.
If this is right
- Current MLLMs exhibit critical gaps in performing progressive clinical reasoning across diagnostic steps.
- Models struggle particularly with integrating information across different imaging modalities.
- The benchmark supplies a standardized measure for tracking future improvements in medical AI reasoning.
- New model development should prioritize explicit training on intermediate reasoning stages and multi-modal fusion.
Where Pith is reading between the lines
- Similar progressive-reasoning benchmarks could be built for other medical specialties to expose parallel limitations.
- The gaps point toward a need for training methods that supervise explicit intermediate reasoning steps rather than end-to-end answers alone.
- If benchmark scores correlate with real clinical outcomes, the test could become a practical filter for deploying AI assistants in ophthalmology clinics.
Load-bearing premise
The six-stage progressive reasoning chain and the selection of 51 public datasets accurately represent the essential elements of real-world ophthalmic clinical reasoning.
What would settle it
A direct comparison in which ophthalmologists complete the same VQA tasks on the benchmark data and their accuracy is measured against the models, or a follow-up study showing that high benchmark scores fail to predict performance on real uncurated patient cases.
Figures
read the original abstract
Despite significant progress in Multi-modal Large Language Models (MLLMs), their clinical reasoning capacity for multi-modal diagnosis remains largely unexamined. Current benchmarks, mostly single-modality data, can't evaluate progressive reasoning and cross-modal integration essential for clinical practice. We introduce the Cross-Modality Progressive Clinical Reasoning (X-PCR) benchmark, the first comprehensive evaluation of MLLMs through a complete ophthalmology diagnostic workflow, with two reasoning tasks: 1) a six-stage progressive reasoning chain spanning image quality assessment to clinical decision-making, and 2) a cross-modality reasoning task integrating six imaging modalities. The benchmark comprises 26,415 images and 177,868 expert-verified VQA pairs curated from 51 public datasets, covering 52 ophthalmic diseases. Evaluation of 21 MLLMs reveals critical gaps in progressive reasoning and cross-modal integration. Dataset and code: https://github.com/CVI-SZU/X-PCR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the X-PCR benchmark for assessing multi-modal large language models (MLLMs) on ophthalmic clinical reasoning. It aggregates 26,415 images and 177,868 VQA pairs from 51 public datasets spanning 52 diseases into two tasks: a six-stage progressive reasoning chain (image quality assessment through clinical decision-making) and a cross-modality integration task across six imaging modalities. Evaluation of 21 MLLMs is reported to reveal critical gaps in progressive reasoning and cross-modal integration.
Significance. If the benchmark construction accurately reflects real-world ophthalmic workflows, the work would provide a useful large-scale resource for evaluating sequential and integrative clinical reasoning in MLLMs, filling a gap left by single-modality benchmarks. The public release of data and code is a positive contribution to reproducibility in medical AI evaluation.
major comments (2)
- [§3] §3 (Benchmark Construction): The six-stage progressive reasoning chain is introduced as capturing essential elements of clinical practice, yet no details are given on its derivation from actual ophthalmologist workflows, no comparison to observed diagnostic sequences, and no clinician validation or inter-rater reliability metrics (e.g., Cohen’s kappa) for the staging or VQA pair annotations. This directly affects the load-bearing claim that model failures indicate clinically relevant deficiencies.
- [Abstract and §3] Abstract and §3: The benchmark is described as 'expert-verified' with curation from 51 datasets, but the manuscript supplies no information on the number of experts, verification protocol, disagreement resolution, or quality control procedures. Without these, the central evaluation results on 'critical gaps' rest on an uncharacterized construction process.
minor comments (2)
- [Abstract] The abstract mentions six imaging modalities but does not list them explicitly; adding this would improve clarity for readers unfamiliar with ophthalmic imaging.
- [References] Ensure the 51 source datasets receive full citations in the references section rather than only a GitHub link.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We agree that the benchmark construction process requires greater transparency to support claims about clinical relevance. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: §3 (Benchmark Construction): The six-stage progressive reasoning chain is introduced as capturing essential elements of clinical practice, yet no details are given on its derivation from actual ophthalmologist workflows, no comparison to observed diagnostic sequences, and no clinician validation or inter-rater reliability metrics (e.g., Cohen’s kappa) for the staging or VQA pair annotations. This directly affects the load-bearing claim that model failures indicate clinically relevant deficiencies.
Authors: We appreciate this feedback. The six stages were derived from standard ophthalmic diagnostic workflows as outlined in clinical guidelines (e.g., AAO Preferred Practice Patterns and standard ophthalmology texts). We did not perform a dedicated clinician validation study or compute inter-rater reliability for the staging or annotations. In the revised §3, we will add explicit literature-based justification for each stage and state the lack of formal validation or kappa metrics as a limitation. revision: yes
-
Referee: Abstract and §3: The benchmark is described as 'expert-verified' with curation from 51 datasets, but the manuscript supplies no information on the number of experts, verification protocol, disagreement resolution, or quality control procedures. Without these, the central evaluation results on 'critical gaps' rest on an uncharacterized construction process.
Authors: We agree that additional details are needed. The expert verification originates from the 51 source datasets, each published with annotations by ophthalmologists or trained experts (details in the original papers). As an aggregation effort, we did not conduct new expert verification or track per-dataset protocols. We will revise §3 to describe our curation and filtering pipeline, cite the source papers for expert information, and outline the quality control steps applied during aggregation. revision: yes
Circularity Check
No circularity: benchmark paper with definitional construction only
full rationale
The paper introduces the X-PCR benchmark by defining a six-stage reasoning chain and curating 26,415 images / 177,868 VQA pairs from 51 public datasets. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. The evaluation of 21 MLLMs is direct empirical testing on the constructed resource rather than any result that reduces to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. This matches the default case of a non-circular benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal biomedical ai.Nature medicine, 28(9):1773–1784, 2022
Juli ´an N Acosta, Guido J Falcone, Pranav Rajpurkar, and Eric J Topol. Multimodal biomedical ai.Nature medicine, 28(9):1773–1784, 2022. 2
2022
-
[2]
Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23736,
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in Neural Information Processing Systems, 35:23716–23736,
-
[3]
Introducing claude haiku 4.5.https://www
Anthropic. Introducing claude haiku 4.5.https://www. anthropic.com/news/claude-haiku-4-5, 2025. Anthropic News, accessed 2026-03-14. 6, 7, 8
2025
-
[4]
arXiv preprint arXiv:2305.11692 (2023)
Long Bai, Mobarakol Islam, Lalithkumar Seenivasan, and Hongliang Ren. Surgical-vqla: Transformer with gated vision-language embedding for visual question localized-answering in robotic surgery.arXiv preprint arXiv:2305.11692, 2023. 2, 3
-
[5]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025. 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhao- hai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Jun- yang Lin. Qwen2.5-vl technical repor...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Microvqa: A multimodal reason- ing benchmark for microscopy-based scientific research
James Burgess, Jeffrey J Nirschl, Laura Bravo-S ´anchez, Alejandro Lozano, Sanket Rajan Gupte, Jesus G Galaz- Montoya, Yuhui Zhang, Yuchang Su, Disha Bhowmik, Zachary Coman, et al. Microvqa: A multimodal reason- ing benchmark for microscopy-based scientific research. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 19552–195...
2025
-
[8]
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shu- nian Chen, Guiming Hardy Chen, Xidong Wang, Ruifei Zhang, Zhenyang Cai, Ke Ji, et al. Huatuogpt-vision, to- wards injecting medical visual knowledge into multimodal llms at scale.arXiv preprint arXiv:2406.19280, 2024. 3, 6, 7, 8
-
[9]
Sharegpt4v: Improving large multi-modal models with better captions
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. In European Conference on Computer Vision (ECCV), 2024. 6, 7, 8
2024
-
[10]
Wsi-vqa: Interpreting whole slide images by gen- erative visual question answering
Pingyi Chen, Chenglu Zhu, Sunyi Zheng, Honglin Li, and Lin Yang. Wsi-vqa: Interpreting whole slide images by gen- erative visual question answering. InEuropean Conference on Computer Vision, pages 401–417. Springer, 2024. 2, 3
2024
-
[11]
Ophglm: An ophthalmology large language-and-vision assistant.Artificial Intelligence in Medicine, 157:103001, 2024
Zhuo Deng, Weihao Gao, Chucheng Chen, Zhiyuan Niu, Zheng Gong, Ruiheng Zhang, Zhenjie Cao, Fang Li, Zhaoyi Ma, Wenbin Wei, et al. Ophglm: An ophthalmology large language-and-vision assistant.Artificial Intelligence in Medicine, 157:103001, 2024. 3
2024
-
[12]
Xiaotang Gai, Chenyi Zhou, Jiaxiang Liu, Yang Feng, Jian Wu, and Zuozhu Liu. Medthink: Explaining medical visual question answering via multimodal decision-making ratio- nale.arXiv preprint arXiv:2404.12372, 2024. 3
-
[13]
GLM-V Team, Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Jun- hui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Bin Chen, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Ji- azheng Xu, Jiale Zhu, Jiali...
work page internal anchor Pith review arXiv 2025
-
[14]
Trust, trustworthiness, and the future of medical ai.Journal of Medical Internet Research, 27: e71236, 2025
Marina Goisauf et al. Trust, trustworthiness, and the future of medical ai.Journal of Medical Internet Research, 27: e71236, 2025. 2
2025
-
[15]
Gemini 2.5 Pro.https://ai.google.dev/ gemini - api / docs / models / gemini - 2
Google. Gemini 2.5 Pro.https://ai.google.dev/ gemini - api / docs / models / gemini - 2 . 5 - pro,
-
[16]
Ac- cessed: 2026-03-22
Google AI for Developers model documentation. Ac- cessed: 2026-03-22. 2, 6, 7, 8
2026
-
[17]
Gemini 2.5 Flash.https://ai.google.dev/ gemini-api/docs/models/gemini-2.5-flash,
Google. Gemini 2.5 Flash.https://ai.google.dev/ gemini-api/docs/models/gemini-2.5-flash,
-
[18]
Ac- cessed: 2026-03-22
Google AI for Developers model documentation. Ac- cessed: 2026-03-22. 6, 7, 8
2026
-
[19]
Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Ba- tra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answer- ing. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 6904–6913, 2017. 3
2017
-
[20]
A novel effect of microaneurysms and retinal cysts on capillary perfusion in diabetic macular edema: A multimodal imaging study.Journal of Clinical Medicine, 14(9):2985, 2025
Bilal Haj Najeeb et al. A novel effect of microaneurysms and retinal cysts on capillary perfusion in diabetic macular edema: A multimodal imaging study.Journal of Clinical Medicine, 14(9):2985, 2025. 2
2025
-
[21]
Pathvqa: 30000+ questions for medical visual question answering
Xuehai He, Yichen Zhang, Luntian Mou, Eric Xing, and Pengtao Xie. Pathvqa: 30000+ questions for medical visual question answering. 2020. 2, 3
2020
-
[22]
Interpretable medical image visual question answering via multi-modal relationship graph learning.Med- ical Image Analysis, 97:103279, 2024
Xinyue Hu, Lin Gu, Kazuma Kobayashi, Liangchen Liu, Mengliang Zhang, Tatsuya Harada, Ronald M Summers, and Yingying Zhu. Interpretable medical image visual question answering via multi-modal relationship graph learning.Med- ical Image Analysis, 97:103279, 2024. 3, 4
2024
-
[23]
Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. Omnimedvqa: A new large-scale comprehensive evaluation benchmark for medical lvlm. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 22170–22183, 2024. 3
2024
-
[24]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 6700–6709, 2019. 3
2019
-
[25]
Rjua-meddqa: A multimodal benchmark for med- ical document question answering and clinical reasoning
Congyun Jin, Ming Zhang, Weixiao Ma, Yujiao Li, Yingbo Wang, Yabo Jia, Yuliang Du, Tao Sun, Haowen Wang, Cong Fan, et al. Rjua-meddqa: A multimodal benchmark for med- ical document question answering and clinical reasoning. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5218–5229,
-
[26]
Uncertainty estimation in medical im- age classification.JMIR Medical Informatics, 10(8):e36427,
Anna Kurz et al. Uncertainty estimation in medical im- age classification.JMIR Medical Informatics, 10(8):e36427,
-
[27]
Benjamin Lambert, Florence Forbes, Senan Doyle, Har- monie Dehaene, and Michel Dojat. Trustworthy clinical ai solutions: a unified review of uncertainty quantification in deep learning models for medical image analysis.Artificial Intelligence in Medicine, 150:102830, 2024. 2
2024
-
[28]
A dataset of clinically generated visual questions and answers about radiology images
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. A dataset of clinically generated visual questions and answers about radiology images. InScientific Data, pages 1–10. Nature Publishing Group, 2018. 3
2018
-
[29]
Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language- and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564,
-
[30]
Towards a holistic framework for multi- modal llm in 3d medical imaging: Braingpt for ct radiology report generation.Nature Communications, 2025
Chenyang Li et al. Towards a holistic framework for multi- modal llm in 3d medical imaging: Braingpt for ct radiology report generation.Nature Communications, 2025. 2
2025
-
[31]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Fuchen Li, Yuanhan Zhang, Sheng Shen, Yong Jae Lee, et al. Llava-next-interleave: Tackling multi-image, video, and multi-view in large multimodal models.arXiv preprint arXiv:2407.07895, 2024. 6, 7, 8
work page internal anchor Pith review arXiv 2024
-
[32]
Visionunite: A vision-language foundation model for ophthalmology en- hanced with clinical knowledge.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2025
Zihan Li, Diping Song, Zefeng Yang, Deming Wang, Fei Li, Xiulan Zhang, Paul E Kinahan, and Yu Qiao. Visionunite: A vision-language foundation model for ophthalmology en- hanced with clinical knowledge.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2025. 3
2025
-
[33]
Slake: A semantically-labeled knowledge- enhanced dataset for medical visual question answering
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. Slake: A semantically-labeled knowledge- enhanced dataset for medical visual question answering. In 2021 IEEE 18th international symposium on biomedical imaging (ISBI), pages 1650–1654. IEEE, 2021. 2, 3
2021
-
[34]
Gemex: A large-scale, groundable, and ex- plainable medical vqa benchmark for chest x-ray diagnosis
Bo Liu, Ke Zou, Li-Ming Zhan, Zexin Lu, Xiaoyu Dong, Yidi Chen, Chengqiang Xie, Jiannong Cao, Xiao-Ming Wu, and Huazhu Fu. Gemex: A large-scale, groundable, and ex- plainable medical vqa benchmark for chest x-ray diagnosis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21310–21320, 2025. 3
2025
-
[35]
Llava-1.5: Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Llava-1.5: Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03761, 2023. 6, 7, 8
-
[36]
Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023. 2, 3
2023
-
[37]
En- dobench: A comprehensive evaluation of multi-modal large language models for endoscopy analysis
Shengyuan Liu, Boyun Zheng, Wenting Chen, Zhihao Peng, Zhenfei Yin, Jing Shao, Jiancong Hu, and Yixuan Yuan. En- dobench: A comprehensive evaluation of multi-modal large language models for endoscopy analysis. InAdvances in Neural Information Processing Systems, 2025. 2, 3
2025
-
[38]
Xiaoling Luo, Ruli Zheng, Qiaojian Zheng, Zibo Du, Shuo Yang, Meidan Ding, Qihao Xu, Chengliang Liu, and Lin- lin Shen. A survey of multimodal ophthalmic diagnostics: From task-specific approaches to foundational models.arXiv preprint arXiv:2508.03734, 2025. 2
-
[39]
Chatgpt assisting diagnosis of neuro- ophthalmology diseases based on case reports.Journal of Neuro-Ophthalmology, 45(3):301–306, 2025
Yeganeh Madadi, Mohammad Delsoz, Priscilla A Lao, Joseph W Fong, TJ Hollingsworth, Malik Y Kahook, and Siamak Yousefi. Chatgpt assisting diagnosis of neuro- ophthalmology diseases based on case reports.Journal of Neuro-Ophthalmology, 45(3):301–306, 2025. 3
2025
-
[40]
The llama 4 herd: The beginning of a new era of natively multimodal ai innovation.https: //ai.meta.com/blog/llama- 4- multimodal- intelligence/, 2025
Meta AI. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation.https: //ai.meta.com/blog/llama- 4- multimodal- intelligence/, 2025. AI at Meta blog, accessed 2026- 03-14. 3
2025
-
[41]
Foundation models for generalist medi- cal artificial intelligence.Nature, 616(7956):259–265, 2023
Michael Moor, Oishi Banerjee, Zahra Shakeri Hossein Abad, Harlan M Krumholz, Jure Leskovec, Eric J Topol, and Pranav Rajpurkar. Foundation models for generalist medi- cal artificial intelligence.Nature, 616(7956):259–265, 2023. 2
2023
-
[42]
Med-flamingo: A multimodal medical few-shot learner
Michael Moor, Qian Huang, Shirley Wu, Michihiro Ya- sunaga, Cyril Zakka, Yash Dalmia, Eduardo Pontes Reis, Pranav Rajpurkar, and Jure Leskovec. Med-flamingo: A multimodal medical few-shot learner. InProceedings of the 3rd Machine Learning for Health Symposium, pages 353–
-
[43]
GPT-5 System Card.https : / / openai
OpenAI. GPT-5 System Card.https : / / openai . com/index/gpt-5-system-card/, 2025. Accessed: 2026-03-22. 2, 3, 6, 7, 8
2025
-
[44]
GPT-5 nano.https : / / developers
OpenAI. GPT-5 nano.https : / / developers . openai . com / api / docs / models / gpt - 5 - nano,
-
[45]
Accessed: 2026-03-22
OpenAI API model page. Accessed: 2026-03-22. 6, 7, 8
2026
-
[46]
Multimodal imaging in diabetic retinopathy and macular edema: An update about biomark- ers.Survey of Ophthalmology, 69(6):893–904, 2024
Mariacristina Parravano, Giovanni Cennamo, Davide De Geronimo, et al. Multimodal imaging in diabetic retinopathy and macular edema: An update about biomark- ers.Survey of Ophthalmology, 69(6):893–904, 2024. 2
2024
-
[47]
Lmod: A large multimodal ophthalmology dataset and benchmark for large vision-language models
Zhenyue Qin, Yu Yin, Dylan Campbell, Xuansheng Wu, Ke Zou, Yih-Chung Tham, Ninghao Liu, Xiuzhen Zhang, and Qingyu Chen. Lmod: A large multimodal ophthalmology dataset and benchmark for large vision-language models. arXiv preprint arXiv:2410.01620, 2024. 2, 3
-
[48]
Andrew Sellergren, Sahar Kazemzadeh, Tiam Jaroen- sri, Atilla Kiraly, Madeleine Traverse, Timo Kohlberger, Shawn Xu, Fayaz Jamil, C ´ıan Hughes, Charles Lau, et al. Medgemma technical report.arXiv preprint arXiv:2507.05201, 2025. 3, 6, 7, 8
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Pathbench: Advancing the benchmark of large multimodal models for pathology image understanding at patch and whole slide level.IEEE Transactions on Medi- cal Imaging, 2025
Yuxuan Sun, Hao Wu, Chenglu Zhu, Yixuan Si, Qizi Chen, Yunlong Zhang, Kai Zhang, Jingxiong Li, Jiatong Cai, Yuhan Wang, et al. Pathbench: Advancing the benchmark of large multimodal models for pathology image understanding at patch and whole slide level.IEEE Transactions on Medi- cal Imaging, 2025. 2, 3
2025
-
[50]
Ryutaro Tanno, David G. T. Barrett, Andrew Sellergren, et al. Collaboration between clinicians and vision–language models in radiology report generation.Nature Medicine, 31 (2):599–608, 2025. 2
2025
-
[51]
Towards gen- eralist biomedical ai.Nejm Ai, 1(3):AIoa2300138, 2024
Tao Tu, Shekoofeh Azizi, Danny Driess, Mike Schaeker- mann, Mohamed Amin, Pi-Chuan Chang, Andrew Carroll, Charles Lau, Ryutaro Tanno, Ira Ktena, et al. Towards gen- eralist biomedical ai.Nejm Ai, 1(3):AIoa2300138, 2024. 3
2024
-
[52]
Gui Wang, Yang Wennuo, Xusen Ma, Zehao Zhong, Zhuoru Wu, Ende Wu, Rong Qu, Wooi Ping Cheah, Jianfeng Ren, and Linlin Shen. Eyepcr: A comprehensive benchmark for fine-grained perception, knowledge comprehension and clinical reasoning in ophthalmic surgery.arXiv preprint arXiv:2509.15596, 2025. 2, 3, 4
-
[53]
Advances and prospects of multi-modal ophthalmic artificial intelligence based on deep learning: A review.Eye and Vision, 11(1):1–23, 2024
Shuang Wang et al. Advances and prospects of multi-modal ophthalmic artificial intelligence based on deep learning: A review.Eye and Vision, 11(1):1–23, 2024. 2
2024
-
[54]
arXiv preprint arXiv:2506.07044 (2025)
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, et al. Lingshu: A general- ist foundation model for unified multimodal medical under- standing and reasoning.arXiv preprint arXiv:2506.07044,
-
[55]
Blip-3: A family of open large multimodal models
Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, et al. Blip-3: A family of open large multimodal models. InProceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 6124–6135,
-
[56]
arXiv preprint arXiv:2505.16964 (2025)
Suhao Yu, Haojin Wang, Juncheng Wu, Cihang Xie, and Yuyin Zhou. Medframeqa: A multi-image medi- cal vqa benchmark for clinical reasoning.arXiv preprint arXiv:2505.16964, 2025. 2, 3, 4
-
[57]
Role of calibration in uncertainty- based referral for deep medical image classification.Nature Communications, 14:4299, 2023
Ruoxuan Zhang et al. Role of calibration in uncertainty- based referral for deep medical image classification.Nature Communications, 14:4299, 2023. 2
2023
-
[58]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-vqa: Vi- sual instruction tuning for medical visual question answer- ing.arXiv preprint arXiv:2305.10415, 2023. 2, 3
-
[59]
Development of a large-scale medical visual question-answering dataset.Com- munications Medicine, 4(1):277, 2024
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Development of a large-scale medical visual question-answering dataset.Com- munications Medicine, 4(1):277, 2024. 3
2024
-
[60]
Ophtha-llama2: A large language model for ophthalmology.arXiv preprint arXiv:2312.04906, 2023
Huan Zhao, Qian Ling, Yi Pan, Tianyang Zhong, Jin-Yu Hu, Junjie Yao, Fengqian Xiao, Zhenxiang Xiao, Yutong Zhang, San-Hua Xu, et al. Ophtha-llama2: A large language model for ophthalmology.arXiv preprint arXiv:2312.04906, 2023. 3
-
[61]
A foundation model for generalizable disease detection from retinal images.Nature, 622(7981):156–163,
Yukun Zhou, Mark A Chia, Siegfried K Wagner, Murat S Ayhan, Dominic J Williamson, Robbert R Struyven, Tim- ing Liu, Moucheng Xu, Mateo G Lozano, Peter Woodward- Court, et al. A foundation model for generalizable disease detection from retinal images.Nature, 622(7981):156–163,
-
[62]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weidong Chen, Yifei Liu, et al. In- ternvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 6, 7, 8
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.