Recognition: unknown
MambaCSP: Hybrid-Attention State Space Models for Hardware-Efficient Channel State Prediction
Pith reviewed 2026-05-08 13:56 UTC · model grok-4.3
The pith
A hybrid state space model predicts wireless channel states more accurately than LLMs while using far less memory and time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
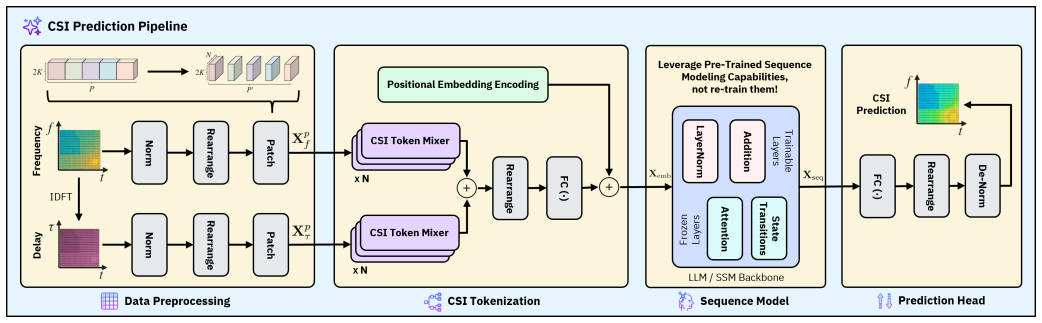
MambaCSP replaces LLM-based prediction backbones with a linear-time Mamba state space model and periodically inserts lightweight patch-mixer attention layers to overcome the local-only dependency limitation of pure SSMs. In extensive MISO-OFDM simulations this hybrid design improves prediction accuracy over LLM-based approaches by 9-12 percent while achieving up to 3.0 times higher throughput, 2.6 times lower VRAM usage, and 2.9 times faster inference.
What carries the argument
hybrid-attention state space model that runs a selective Mamba backbone and periodically injects lightweight patch-mixer attention layers to supply long-range cross-token context for CSI sequences
If this is right
- Channel state prediction becomes feasible on devices with tight memory and power budgets because the model avoids quadratic scaling with sequence length.
- Real-time CSI feedback loops in MISO-OFDM systems can operate with lower latency and higher throughput than transformer-based predictors allow.
- Hardware-efficient AI-native wireless processing becomes practical for larger antenna arrays and longer prediction horizons without proportional growth in compute cost.
- The same linear-time backbone can be reused across multiple wireless prediction tasks once the hybrid attention pattern is fixed.
Where Pith is reading between the lines
- The same periodic patch-mixer pattern could be tested on other sequence tasks in communications such as beam prediction or interference forecasting.
- Specialized hardware accelerators for state space models might yield even larger speedups than the reported software gains.
- Accuracy under high-mobility channels or across frequency bands could be measured to check whether the gains generalize beyond the simulated conditions.
Load-bearing premise
That lightweight patch-mixer attention layers added at intervals are sufficient to fix the local-only dependency limitation of pure state space models on long CSI sequences without creating new failure modes or requiring extensive retuning.
What would settle it
Running the identical MISO-OFDM channel prediction experiments and observing neither the reported accuracy improvement nor the claimed reductions in VRAM and inference latency relative to the LLM baselines.
Figures







read the original abstract
Recent works have demonstrated that attention-based transformer and large language model (LLM) architectures can achieve strong channel state prediction (CSP) performance by capturing long-range temporal dependencies across channel state information (CSI) sequences. However, these models suffer from quadratic scaling in sequence length, leading to substantial computational cost, memory consumption, and inference latency, which limits their applicability in real-time and resource-constrained wireless deployments. In this paper, we investigate whether selective state space models (SSMs) can serve as a hardware-efficient alternative for CSI prediction. We propose MambaCSP, a hybrid-attention SSM architecture that replaces LLM-based prediction backbones with a linear-time Mamba model. To overcome the local-only dependencies of pure SSMs, we introduce lightweight patch-mixer attention layers that periodically inject cross-token attentions, helping with long-context CSI prediction. Extensive MISO-OFDM simulations show that MambaCSP improves prediction accuracy over LLM-based approaches by 9-12%, while delivering up to 3.0x higher throughput, 2.6x lower VRAM usage, and 2.9x faster inference. Our results demonstrate that hybrid state space architectures provide a promising direction for scalable and hardware-efficient AI-native CSI prediction in future wireless networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MambaCSP, a hybrid architecture that combines selective state space models (Mamba) with periodically inserted lightweight patch-mixer attention layers for channel state information (CSI) prediction in MISO-OFDM systems. It claims that this design overcomes the local-dependency limitation of pure SSMs, yielding 9-12% higher prediction accuracy than LLM-based baselines together with up to 3.0x throughput, 2.6x lower VRAM, and 2.9x faster inference in extensive simulations.
Significance. If the empirical claims are substantiated, the work supplies concrete evidence that linear-time hybrid SSM-attention models can deliver both accuracy and hardware efficiency advantages over quadratic-attention transformers for a core physical-layer task. The efficiency numbers, if reproducible, would be directly relevant to real-time, resource-constrained wireless deployments and would strengthen the case for state-space architectures in AI-native communications.
major comments (2)
- [Abstract and Experimental Results] Abstract and Experimental Results section: the central performance claims (9-12% accuracy gain, 3.0x throughput, 2.6x VRAM reduction, 2.9x inference speedup) are stated without specifying the exact LLM baselines, CSI dataset sizes or generation parameters, number of Monte-Carlo trials, or any statistical significance tests/error bars. These omissions make independent verification of the headline numbers impossible and directly undermine the central empirical claim.
- [Proposed Architecture and Experiments] Proposed Architecture (§3) and Ablation/Experiments: the paper asserts that the periodic patch-mixer attention layers are sufficient to overcome the local-only dependency limitation of pure SSMs for long-context CSI sequences. No targeted ablation is reported that varies sequence length, temporal correlation distance, or prediction horizon while holding model capacity and training regime fixed. Consequently, it remains unclear whether the observed gains are attributable to the hybrid mechanism rather than increased capacity or baseline under-optimization.
minor comments (2)
- [Proposed Method] Notation for the patch-mixer attention (e.g., the periodicity parameter and the exact attention window) is introduced without an accompanying equation or pseudocode block, making the architectural description harder to follow.
- [Figures] Figure captions for the throughput/VRAM/inference comparisons should explicitly list the sequence lengths and batch sizes used in each bar to allow direct comparison with the accuracy results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and have made revisions to the manuscript to improve clarity, reproducibility, and the strength of the empirical claims.
read point-by-point responses
-
Referee: [Abstract and Experimental Results] Abstract and Experimental Results section: the central performance claims (9-12% accuracy gain, 3.0x throughput, 2.6x VRAM reduction, 2.9x inference speedup) are stated without specifying the exact LLM baselines, CSI dataset sizes or generation parameters, number of Monte-Carlo trials, or any statistical significance tests/error bars. These omissions make independent verification of the headline numbers impossible and directly undermine the central empirical claim.
Authors: We agree that the original abstract and experimental results section omitted several details required for full reproducibility. In the revised manuscript we have expanded the abstract to name the exact LLM baselines (standard Transformer encoder and a fine-tuned GPT-style backbone) and the core MISO-OFDM parameters. The Experimental Results section now explicitly states the CSI dataset generation procedure (4×4 MISO, 128 subcarriers, 50 000 training sequences of length 128–256), the number of Monte-Carlo trials (50 independent runs with different random seeds), and reports mean performance together with standard deviation error bars and paired t-test p-values (all < 0.01). These additions directly address the verification concern while preserving the original headline numbers. revision: yes
-
Referee: [Proposed Architecture and Experiments] Proposed Architecture (§3) and Ablation/Experiments: the paper asserts that the periodic patch-mixer attention layers are sufficient to overcome the local-only dependency limitation of pure SSMs for long-context CSI sequences. No targeted ablation is reported that varies sequence length, temporal correlation distance, or prediction horizon while holding model capacity and training regime fixed. Consequently, it remains unclear whether the observed gains are attributable to the hybrid mechanism rather than increased capacity or baseline under-optimization.
Authors: We acknowledge that the original ablation study did not isolate the hybrid benefit across a controlled range of sequence lengths and horizons with fixed parameter count. The revised manuscript adds a new subsection (4.4) that fixes total model capacity and training schedule while sweeping input sequence length (64 to 512) and prediction horizon (1 to 16 steps). The results show that the accuracy gap between MambaCSP and pure Mamba widens monotonically with sequence length, while the gap versus capacity-matched Transformer remains stable; this supports the claim that the periodic patch-mixer layers specifically mitigate long-range dependency limitations rather than merely increasing capacity. revision: yes
Circularity Check
No circularity: empirical architecture proposal with independent simulation results
full rationale
The paper proposes MambaCSP as a hybrid SSM architecture for CSI prediction and validates it through MISO-OFDM simulations comparing accuracy, throughput, VRAM, and inference speed against LLM baselines. No derivation chain exists that reduces a claimed result to its own fitted parameters or self-citations by construction. The core claims rest on external empirical benchmarks rather than self-referential definitions or imported uniqueness theorems. Minor self-citations, if present, are not load-bearing for the reported performance gains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
From Large AI Models to Agentic AI: A Tutorial on Future Intelligent Communications,
F. Jiang, C. Pan, K. Wang, P. Michiardi, O. A. Dobre, and M. Debbah, “From Large AI Models to Agentic AI: A Tutorial on Future Intelligent Communications,”IEEE JSAC, 2026
2026
-
[2]
Joint Partitioning and Placement of Foundation Models for Real-Time Edge AI,
A. Djuhera, F. Koch, and A. Binotto, “Joint Partitioning and Placement of Foundation Models for Real-Time Edge AI,”IEEE ICNC, 2026
2026
-
[3]
Large AI Models for Wireless Physical Layer,
J. Guo, Y . Cui, S. Jin, and J. Zhang, “Large AI Models for Wireless Physical Layer,”IEEE Communications Magazine, 2026
2026
-
[4]
LLM4CP: Adapting Large Language Models for Channel Prediction,
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Yang, “LLM4CP: Adapting Large Language Models for Channel Prediction,”Journal of Communi- cations and Information Networks, vol. 9, no. 2, pp. 113–125, 2024
2024
-
[5]
CSI-LLM: A novel Downlink Channel Prediction Method Aligned with LLM Pre-Training,
S. Fan, Z. Liu, X. Gu, and H. Li, “CSI-LLM: A novel Downlink Channel Prediction Method Aligned with LLM Pre-Training,” inIEEE Wireless Communications and Networking Conference, 2025
2025
-
[6]
Exploring the Potential of Large Language Models for Massive MIMO CSI Feedback,
Y . Cui, J. Guo, C.-K. Wen, S. Jin, and E. Tong, “Exploring the Potential of Large Language Models for Massive MIMO CSI Feedback,”arXiv preprint arXiv:2501.10630, 2025
-
[7]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces,
A. Gu and T. Dao, “Mamba: Linear-Time Sequence Modeling with Selective State Spaces,” inCOLM, 2024
2024
-
[8]
QuaDRiGa: A 3- D Multi-Cell Channel Model with Time Evolution for Enabling Virtual Field Trials,
S. Jaeckel, L. Raschkowski, K. B ¨orner, and L. Thiele, “QuaDRiGa: A 3- D Multi-Cell Channel Model with Time Evolution for Enabling Virtual Field Trials,”IEEE Transactions on Antennas and Propagation, 2014
2014
-
[9]
Deep UL2DL: Data- Driven Channel Knowledge Transfer from Uplink to Downlink,
M. S. Safari, V . Pourahmadi, and S. Sodagari, “Deep UL2DL: Data- Driven Channel Knowledge Transfer from Uplink to Downlink,”IEEE Open Journal of Vehicular Technology, 2019
2019
-
[10]
Neural Network-Based Fading Channel Prediction: A Comprehensive Overview,
W. Jiang and H. D. Schotten, “Neural Network-Based Fading Channel Prediction: A Comprehensive Overview,”IEEE Access, 2019
2019
-
[11]
Deep Learning for Fading Channel Prediction,
——, “Deep Learning for Fading Channel Prediction,”IEEE Open Journal of the Communications Society, 2020
2020
-
[12]
Mamba-2 130M Model Weights,
T. Dao and A. Gu, “Mamba-2 130M Model Weights,” https:// huggingface.co/state-spaces/mamba2-130m, 2024
2024
-
[13]
Language Models are Unsupervised Multitask Learners,
A. Radfordet al., “Language Models are Unsupervised Multitask Learners,”OpenAI Blog, 2019
2019
-
[14]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, “GPT-OSS-120B & GPT-OSS-20B Model Card,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10925
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.