Recognition: unknown
CodeGraphVLP: Code-as-Planner Meets Semantic-Graph State for Non-Markovian Vision-Language-Action Models
Pith reviewed 2026-05-08 11:37 UTC · model grok-4.3
The pith
CodeGraphVLP pairs a persistent semantic-graph state with a code planner to succeed more often on non-Markovian robot tasks than standard VLA models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
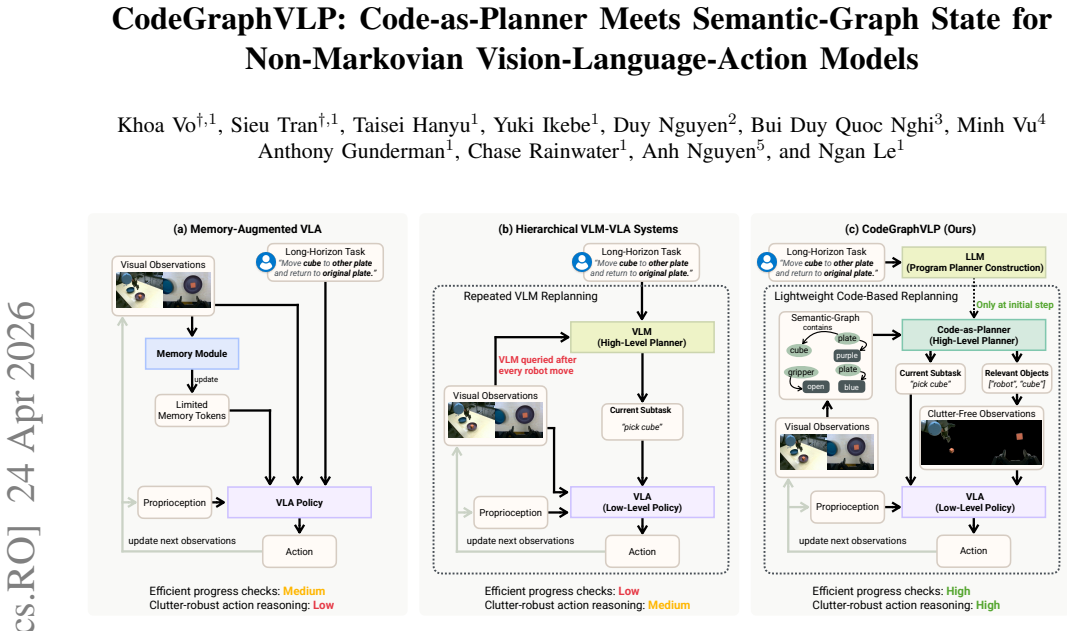
The framework maintains task-relevant entities and relations in a semantic-graph state under partial observability. An executable code planner runs progress checks on this graph and produces subtask instructions together with relevant objects; these outputs drive construction of clutter-suppressed observations that focus the VLA executor on critical evidence.
What carries the argument
Persistent semantic-graph state combined with an executable code-based planner that performs progress checks and generates focused subtask instructions.
If this is right
- On real-world non-Markovian tasks the method improves task completion over strong VLA baselines and history-enabled variants.
- It substantially lowers planning latency compared with VLM-in-the-loop planning.
- Ablation studies confirm that the graph state, code planner, and progress-guided prompting each contribute to the gains.
- The hierarchical loop lets the VLA executor operate on observations that suppress irrelevant clutter.
Where Pith is reading between the lines
- Explicit graph-based memory may let other short-horizon learned policies operate in partially observable environments without retraining.
- Replacing repeated large-model queries with code execution over a compact state could reduce both latency and compute cost in deployed systems.
- The same graph-plus-code structure might extend to tasks such as sequential assembly or multi-room navigation where order and persistence matter.
Load-bearing premise
The semantic-graph state can reliably track task-relevant entities and relations even when parts of the scene are occluded or cluttered.
What would settle it
An experiment in which the semantic graph is replaced by a simple buffer of recent observations while keeping the rest of the pipeline identical, and which then shows no gain in task completion, would indicate that the graph representation itself is not carrying the reported benefit.
Figures



read the original abstract
Vision-Language-Action (VLA) models promise generalist robot manipulation, but are typically trained and deployed as short-horizon policies that assume the latest observation is sufficient for action reasoning. This assumption breaks in non-Markovian long-horizon tasks, where task-relevant evidence can be occluded or appear only earlier in the trajectory, and where clutter and distractors make fine-grained visual grounding brittle. We present CodeGraphVLP, a hierarchical framework that enables reliable long-horizon manipulation by combining a persistent semantic-graph state with an executable code-based planner and progress-guided visual-language prompting. The semantic-graph maintains task-relevant entities and relations under partial observability. The synthesized planner executes over this semantic-graph to perform efficient progress checks and outputs a subtask instruction together with subtask-relevant objects. We use these outputs to construct clutter-suppressed observations that focus the VLA executor on critical evidence. On real-world non-Markovian tasks, CodeGraphVLP improves task completion over strong VLA baselines and history-enabled variants while substantially lowering planning latency compared to VLM-in-the-loop planning. We also conduct extensive ablation studies to confirm the contributions of each component.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CodeGraphVLP, a hierarchical framework that augments vision-language-action (VLA) models with a persistent semantic-graph state representation, an executable code-based planner for progress checks and subtask decomposition, and progress-guided visual-language prompting to focus the VLA executor on relevant evidence. It claims that this integration enables reliable performance on non-Markovian long-horizon manipulation tasks under partial observability by maintaining task-relevant entities and relations, yielding higher task completion rates than strong VLA baselines and history-enabled variants while reducing planning latency relative to VLM-in-the-loop approaches, with supporting ablation studies.
Significance. If the performance claims are substantiated, the work would be significant for bridging symbolic planning with neural VLA policies in robotics, offering a practical way to handle non-Markovian dependencies and clutter that currently limit short-horizon VLA deployment. The extensive ablation studies are a clear strength, as they directly test component contributions rather than relying on end-to-end black-box gains.
major comments (2)
- [Results section] Results section (and abstract performance claims): the manuscript reports qualitative improvements in task completion and latency but provides no exact quantitative metrics (e.g., success rates, latency values in seconds), baseline implementations with citations or code, error bars, or statistical significance tests. This absence is load-bearing because the central claim of superiority over VLA baselines and history variants cannot be verified or sized without these details.
- [Method / Semantic-graph construction] Semantic-graph state description (likely §3.2 or Method): no error rates, drift measurements, update rules, or failure-mode analysis are supplied for how the graph is constructed and maintained from VLM observations under partial observability, occlusions, and distractors. This directly undermines the weakest assumption that the graph reliably supports accurate progress checks by the code planner.
minor comments (2)
- [Method] Notation for the semantic-graph (entities, relations, update function) could be formalized with a small table or pseudocode to improve clarity for readers unfamiliar with the exact representation.
- [Ablation studies] The ablation studies are mentioned but would benefit from a dedicated table summarizing the contribution of each component (graph, code planner, prompting) with the same metrics used in the main results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We have reviewed the major comments carefully and provide point-by-point responses below. Where the comments identify gaps in quantitative detail or analysis, we agree and commit to revisions that will strengthen the paper without altering its core contributions.
read point-by-point responses
-
Referee: [Results section] Results section (and abstract performance claims): the manuscript reports qualitative improvements in task completion and latency but provides no exact quantitative metrics (e.g., success rates, latency values in seconds), baseline implementations with citations or code, error bars, or statistical significance tests. This absence is load-bearing because the central claim of superiority over VLA baselines and history variants cannot be verified or sized without these details.
Authors: We acknowledge that the current manuscript presents performance improvements in summarized form in the abstract and results section without a dedicated table of exact metrics, error bars, or statistical tests, which limits independent verification. We will revise the results section to include a table with precise quantitative values from our real-world experiments (task success rates as percentages with standard deviations across repeated trials, planning latency in seconds with comparisons), full citations to the baseline VLA models and history variants used, descriptions of their implementations, and statistical significance tests (e.g., p-values from appropriate tests). This will allow the claims of superiority to be fully sized and verified. revision: yes
-
Referee: [Method / Semantic-graph construction] Semantic-graph state description (likely §3.2 or Method): no error rates, drift measurements, update rules, or failure-mode analysis are supplied for how the graph is constructed and maintained from VLM observations under partial observability, occlusions, and distractors. This directly undermines the weakest assumption that the graph reliably supports accurate progress checks by the code planner.
Authors: We agree that the method section describes semantic-graph construction from VLM observations but does not supply quantitative error rates, drift analysis, explicit update rules, or failure-mode discussion under partial observability and distractors. We will revise §3.2 (and add an appendix if needed) to include the update rules for graph maintenance (e.g., how new observations are merged or used to correct entities/relations), empirical error rates measured during our experiments (such as entity detection precision/recall in occluded or cluttered scenes), and a failure-mode analysis with concrete examples. This will directly support the reliability of the graph for the code planner's progress checks. revision: yes
Circularity Check
No circularity: empirical framework integration with ablations
full rationale
The paper introduces CodeGraphVLP as a hierarchical integration of a persistent semantic-graph state, executable code planner, and progress-guided VLA prompting for non-Markovian tasks. All claims rest on real-world task completion rates, latency measurements, and ablation studies that isolate component contributions. No mathematical derivations, fitted parameters renamed as predictions, or self-referential definitions appear; the semantic-graph maintenance and planner outputs are presented as engineered components whose reliability is evaluated externally rather than assumed by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic-graph state maintains task-relevant entities and relations under partial observability
invented entities (2)
-
Semantic-graph state
no independent evidence
-
Code-based planner
no independent evidence
Reference graph
Works this paper leans on
-
[1]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finnet al., “Rt-1: Robotics transformer for real-world control at scale,” inarXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
Rt-2: Vision- language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xiaet al., “Rt-2: Vision- language-action models transfer web knowledge to robotic control,” in CoRL, 2023, pp. 2165–2183
2023
-
[3]
Octo: An open-source generalist robot policy,
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees et al., “Octo: An open-source generalist robot policy,” inProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[4]
Vision-language foundation models as effective robot imitators,
X. Li, M. Liu, H. Zhang, C. Yu, J. Xu, H. Wuet al., “Vision-language foundation models as effective robot imitators,” inICLR, 2024
2024
-
[5]
OpenVLA: An open-source vision-language-action model,
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair et al., “OpenVLA: An open-source vision-language-action model,” in CoRL, 2024
2024
-
[6]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finnet al., “π0: A vision-language-action flow model for general robot control,” arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review arXiv 2024
-
[7]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
K. Pertsch, K. Stachowicz, B. Ichter, D. Driess, S. Nair, Q. Vuong et al., “Fast: Efficient action tokenization for vision-language-action models,”arXiv preprint arXiv:2501.09747, 2025
work page internal anchor Pith review arXiv 2025
-
[8]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driesset al., “π 0.5: a vision-language-action model with open- world generalization,”arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. Fanet al., “Gr00t n1: An open foundation model for generalist humanoid robots,” arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review arXiv 2025
-
[10]
Bridgedata v2: A dataset for robot learning at scale,
H. R. Walke, K. Black, T. Z. Zhao, Q. Vuong, C. Zheng, P. Hansen- Estruchet al., “Bridgedata v2: A dataset for robot learning at scale,” inCoRL. PMLR, 2023, pp. 1723–1736
2023
-
[11]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Leeet al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0,” inICRA. IEEE, 2024, pp. 6892–6903
2024
-
[12]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karam- chetiet al., “Droid: A large-scale in-the-wild robot manipulation dataset,”arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review arXiv 2024
-
[13]
Visually grounding lanuage instruction for history-dependent manipulation,
H. Ahn, O. Kwon, K. Kim, J. Jeong, H. Jun, H. Leeet al., “Visually grounding lanuage instruction for history-dependent manipulation,” in ICRA, May 2022
2022
-
[14]
Memer: Scaling up memory for robot control via experience retrieval,
A. Sridhar, J. Pan, S. Sharma, and C. Finn, “Memer: Scaling up memory for robot control via experience retrieval,” 2025
2025
-
[15]
HAMLET: Switch your vision-language-action model into a history-aware policy,
M. Koo, D. Choi, T. Kim, K. Lee, C. Kim, Y . Seoet al., “HAMLET: Switch your vision-language-action model into a history-aware policy,” inICLR, 2026
2026
-
[16]
MemoryVLA: Perceptual-cognitive memory in vision-language-action models for robotic manipulation,
H. Shi, B. Xie, Y . Liu, L. Sun, F. Liu, T. Wanget al., “MemoryVLA: Perceptual-cognitive memory in vision-language-action models for robotic manipulation,” inICLR, 2026
2026
-
[17]
Hi robot: Open-ended instruction following with hierarchical vision-language-action models,
L. X. Shi, brian ichter, M. R. Equi, L. Ke, K. Pertsch, Q. Vuong et al., “Hi robot: Open-ended instruction following with hierarchical vision-language-action models,” inICML, 2025
2025
-
[18]
Thinkact: Vision-language-action reasoning via reinforced visual la- tent planning,
C.-P. Huang, Y .-H. Wu, M.-H. Chen, Y .-C. F. Wang, and F.-E. Yang, “Thinkact: Vision-language-action reasoning via reinforced visual la- tent planning,” inNeurIPS, 2025
2025
-
[19]
arXiv preprint arXiv:2601.09708 (2026) 3
C.-P. Huang, Y . Man, Z. Yu, M.-H. Chen, J. Kautz, Y .-C. F. Wang et al., “Fast-thinkact: Efficient vision-language-action reasoning via verbalizable latent planning,”arXiv preprint arXiv:2601.09708, 2026
-
[20]
Towards long-horizon vision-language-action system: Reasoning, acting and memory,
D. Li, Y . Zhang, M. Cao, D. Liu, W. Xie, T. Huiet al., “Towards long-horizon vision-language-action system: Reasoning, acting and memory,” inICCV, 2025, pp. 6839–6848
2025
-
[21]
Code as policies: Language model programs for embodied control,
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichteret al., “Code as policies: Language model programs for embodied control,” inICRA, 2023, pp. 9493–9500
2023
-
[22]
Flamingo: a visual language model for few-shot learning,
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson et al., “Flamingo: a visual language model for few-shot learning,” inNeurIPS, vol. 35, 2022
2022
-
[23]
Palm-e: an embodied multimodal language model,
D. Driess, F. Xia, M. S. M. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter et al., “Palm-e: an embodied multimodal language model,” inICML, ser. ICML’23. JMLR.org, 2023
2023
-
[24]
On scaling up a multilingual vision and language model,
X. Chen, J. Djolonga, P. Padlewski, B. Mustafa, S. Changpinyo, J. Wu et al., “On scaling up a multilingual vision and language model,” in CVPR, June 2024, pp. 14 432–14 444
2024
-
[25]
Prismatic vlms: Investigating the design space of visually- conditioned language models,
S. Karamcheti, S. Nair, A. Balakrishna, P. Liang, T. Kollar, and D. Sadigh, “Prismatic vlms: Investigating the design space of visually- conditioned language models,” inICML, 2024
2024
-
[26]
PaliGemma: A versatile 3B VLM for transfer
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz et al., “Paligemma: A versatile 3b vlm for transfer,”arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review arXiv 2024
-
[27]
Flow matching for generative modeling,
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,” inICLR, 2023
2023
-
[28]
Moka: Open-world robotic manipulation through mark-based visual prompting,
K. Fang, F. Liu, P. Abbeel, and S. Levine, “Moka: Open-world robotic manipulation through mark-based visual prompting,”Robotics: Science and Systems (RSS), 2024
2024
-
[29]
Inner monologue: Embodied reasoning through planning with language models,
W. Huang, F. Xia, T. Xiao, H. Chan, J. Liang, P. Florenceet al., “Inner monologue: Embodied reasoning through planning with language models,” inCoRL, 2022
2022
-
[30]
Robotic Control via Embodied Chain-of-Thought Reasoning
M. Zawalski, W. Chen, K. Pertsch, O. Mees, C. Finn, and S. Levine, “Robotic control via embodied chain-of-thought reasoning,”arXiv preprint arXiv:2407.08693, 2024
work page internal anchor Pith review arXiv 2024
-
[31]
Sayplan: Grounding large language models using 3d scene graphs for scalable task planning,
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Suen- derhauf, “Sayplan: Grounding large language models using 3d scene graphs for scalable task planning,” inCoRL, 2023
2023
-
[32]
Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation,
W. Huang, C. Wang, Y . Li, R. Zhang, and L. Fei-Fei, “Rekep: Spatio-temporal reasoning of relational keypoint constraints for robotic manipulation,” inCoRL. PMLR, 2025
2025
-
[33]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,” inRobotics: Science and Systems XIX, Daegu, Republic of Korea, July 10-14, 2023, 2023
2023
-
[34]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfielet al., “Diffusion policy: Visuomotor policy learning via action diffusion,” The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[35]
Yoloe: Real- time seeing anything,
A. Wang, L. Liu, H. Chen, Z. Lin, J. Han, and G. Ding, “Yoloe: Real- time seeing anything,” inICCV, October 2025, pp. 24 591–24 602
2025
-
[36]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
J. Yang, H. Zhang, F. Li, X. Zou, C. Li, and J. Gao, “Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v,”arXiv preprint arXiv:2310.11441, 2023
work page internal anchor Pith review arXiv 2023
-
[37]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal et al., “Learning transferable visual models from natural language supervision,” inICML. PMLR, 2021
2021
-
[38]
Putting the object back into video object segmentation,
H. K. Cheng, S. W. Oh, B. Price, J.-Y . Lee, and A. Schwing, “Putting the object back into video object segmentation,” inCVPR, 2024, pp. 3151–3161
2024
-
[39]
Progprompt: Generating situated robot task plans using large language models,
I. Singh, V . Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay et al., “Progprompt: Generating situated robot task plans using large language models,” inICRA, 2023, pp. 11 523–11 530
2023
-
[40]
Run-time observation interventions make vision-language-action models more visually ro- bust,
A. J. Hancock, A. Z. Ren, and A. Majumdar, “Run-time observation interventions make vision-language-action models more visually ro- bust,” inICRA, 2025, pp. 9499–9506
2025
-
[41]
LoRA: Low-rank adaptation of large language models,
E. J. Hu, yelong shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wanget al., “LoRA: Low-rank adaptation of large language models,” inICLR, 2022
2022
-
[42]
Gpt-4 technical report,
OpenAI, “Gpt-4 technical report,” 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.