Recognition: unknown
Rethinking Math Reasoning Evaluation: A Robust LLM-as-a-Judge Framework Beyond Symbolic Rigidity
Pith reviewed 2026-05-08 11:42 UTC · model grok-4.3
The pith
An LLM-based judge evaluates mathematical answers more reliably than rigid symbolic comparison across varied formats and representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Symbolic mathematics comparison fails to generalize across diverse mathematical representations and solution formats, leading to inaccurate verification of model-generated answers on reasoning benchmarks; an LLM-based evaluation framework offers a robust alternative that determines correctness more accurately by handling varied answer styles without relying on exact symbolic matches.
What carries the argument
LLM-as-a-judge framework that uses semantic understanding to verify answer correctness against ground truth, replacing rule-based symbolic comparison.
If this is right
- Benchmark scores for mathematical reasoning become more accurate because fewer correct but non-standard answers are discarded.
- Performance monitoring of models on math tasks reflects genuine capability rather than artifacts of the checker.
- Evaluation can extend to a wider range of solution formats without requiring new symbolic rules for each case.
- Advancement in intelligent systems benefits from clearer signals about which models truly improve at logical problem-solving.
Where Pith is reading between the lines
- The same flexible judging approach could reduce evaluation errors in related areas such as code generation or scientific reasoning where output formats vary widely.
- If LLM judges prove stable, benchmark creators might shift from maintaining complex symbolic verifiers to curating human-validated reference sets for training the judge.
- Repeated use of the same judge model risks creating a new form of circularity where models learn to match the judge's preferences rather than objective correctness.
Load-bearing premise
An LLM judge can consistently and accurately determine mathematical correctness without introducing new biases or inconsistencies that undermine the evaluation.
What would settle it
Collect a set of model answers that symbolic checkers reject but human experts accept as correct due to format differences, then measure whether the LLM judge agrees with the humans at high rates and without high run-to-run variance.
Figures





read the original abstract
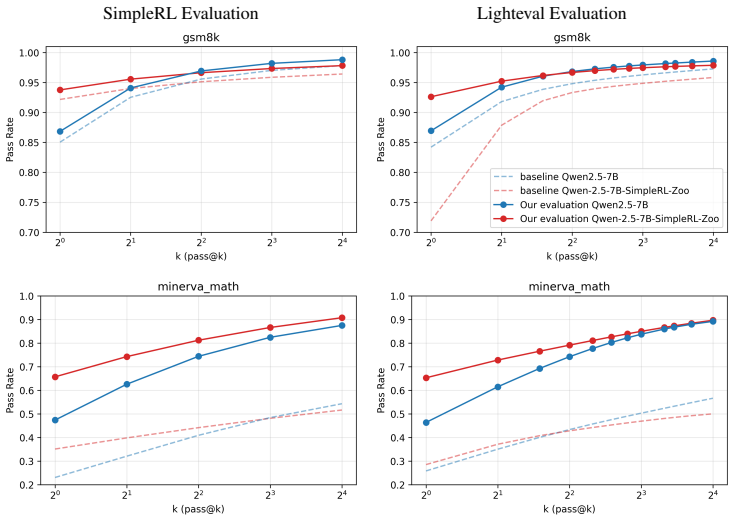
Recent advancements in large language models have led to significant improvements across various tasks, including mathematical reasoning, which is used to assess models' intelligence in logical reasoning and problem-solving. Models are evaluated on mathematical reasoning benchmarks by verifying the correctness of the final answer against a ground truth answer. A common approach for this verification is based on symbolic mathematics comparison, which fails to generalize across diverse mathematical representations and solution formats. In this work, we offer a robust and flexible alternative to rule-based symbolic mathematics comparison. We propose an LLM-based evaluation framework for evaluating model-generated answers, enabling accurate evaluation across diverse mathematical representations and answer formats. We present failure cases of symbolic evaluation in two popular frameworks, Lighteval and SimpleRL, and compare them to our approach, demonstrating clear improvements over commonly used methods. Our framework enables more reliable evaluation and benchmarking, leading to more accurate performance monitoring, which is important for advancing mathematical problem-solving and intelligent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that symbolic mathematics comparison fails to generalize across diverse representations and answer formats in math reasoning benchmarks, and proposes an LLM-as-a-judge framework as a robust, flexible alternative that enables accurate evaluation. It presents failure cases from Lighteval and SimpleRL, asserts clear improvements over these methods, and argues that the framework leads to more reliable benchmarking of mathematical problem-solving in LLMs.
Significance. A validated LLM judge that reliably handles varied mathematical notations and formats without introducing new biases would be a meaningful contribution to evaluation methodology, as current symbolic approaches are known to be brittle. The manuscript identifies real failure modes but does not yet supply the quantitative evidence needed to establish superiority.
major comments (3)
- [Abstract / Experiments] Abstract and Experiments section: the claim of 'clear improvements' and 'accurate evaluation' is unsupported because no quantitative metrics (e.g., agreement rate, precision/recall, or error analysis) are reported against human ground-truth annotations on a held-out set containing both symbolic-success and symbolic-failure cases.
- [Method] Method section: the description of the LLM judge lacks any specification of the prompting strategy, model choice, temperature, or validation procedure, so it is impossible to determine whether the framework reduces to an untested assumption that the LLM will not introduce offsetting inconsistencies.
- [Results] Results / comparison with Lighteval and SimpleRL: only qualitative failure cases are shown; without a controlled test set and human-validated labels, the demonstration establishes only that the LLM differs from symbolic rules, not that its correctness labels are more reliable.
minor comments (2)
- [Abstract] The abstract repeats the importance of mathematical reasoning evaluation in consecutive sentences; tighten for conciseness.
- [Figures/Tables] Ensure that any tables or figures comparing evaluation outcomes include explicit column definitions and sample sizes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important areas for strengthening the empirical support of our LLM-as-a-judge framework. We address each major comment below and will revise the manuscript accordingly to provide the requested quantitative validation and methodological details.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the claim of 'clear improvements' and 'accurate evaluation' is unsupported because no quantitative metrics (e.g., agreement rate, precision/recall, or error analysis) are reported against human ground-truth annotations on a held-out set containing both symbolic-success and symbolic-failure cases.
Authors: We acknowledge that the current manuscript relies primarily on qualitative failure cases to illustrate the limitations of symbolic comparison. While these cases demonstrate systematic issues with diverse representations, we agree that quantitative metrics against human annotations are necessary to substantiate claims of superior accuracy. In the revised version, we will add a human evaluation study on a held-out test set that includes both symbolic-success and symbolic-failure instances, reporting agreement rates, precision, recall, and detailed error analysis comparing the LLM judge to the symbolic baselines. revision: yes
-
Referee: [Method] Method section: the description of the LLM judge lacks any specification of the prompting strategy, model choice, temperature, or validation procedure, so it is impossible to determine whether the framework reduces to an untested assumption that the LLM will not introduce offsetting inconsistencies.
Authors: We will substantially expand the Method section to include the full prompting strategy with the exact prompt template, the specific model used (GPT-4o), temperature set to 0 for reproducibility, and a validation procedure consisting of a pilot study with human annotators to assess consistency and potential biases. This will allow readers to evaluate the framework's reliability directly. revision: yes
-
Referee: [Results] Results / comparison with Lighteval and SimpleRL: only qualitative failure cases are shown; without a controlled test set and human-validated labels, the demonstration establishes only that the LLM differs from symbolic rules, not that its correctness labels are more reliable.
Authors: The presented results use qualitative examples to highlight concrete failure modes in Lighteval and SimpleRL that arise from rigid symbolic matching. To establish greater reliability, the revised Results section will incorporate a controlled test set with human-validated ground-truth labels, enabling a direct quantitative comparison of correctness judgments between our LLM judge and the symbolic methods. revision: yes
Circularity Check
No circularity: LLM-as-a-Judge framework is an independent methodological proposal
full rationale
The paper proposes an LLM-based evaluation framework as a flexible alternative to symbolic comparison for math reasoning benchmarks. It illustrates symbolic failures via examples from Lighteval and SimpleRL but does not derive its claims through equations, fitted parameters renamed as predictions, or self-citations that bear the central load. No step reduces the framework's correctness or superiority to its own inputs by construction; the approach stands as a self-contained tool with external applicability. Concerns about validation against human ground truth pertain to empirical strength, not circular reasoning in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (1)
- LLM judge selection and prompting
axioms (1)
- domain assumption LLMs can reliably assess mathematical equivalence across formats
Forward citations
Cited by 1 Pith paper
-
GSM-SEM: Benchmark and Framework for Generating Semantically Variant Augmentations
GSM-SEM generates reusable, stochastic semantic variants of math reasoning benchmarks that alter underlying facts but preserve answers, producing larger LLM performance drops than prior surface-level variants.
Reference graph
Works this paper leans on
-
[1]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pond \'e , Jared Kaplan, Harrison Edwards, Yura Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, and 34 others. 2021. https://api.semanticscholar.org/CorpusID:235755472 Evaluating lar...
work page internal anchor Pith review arXiv 2021
-
[2]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review arXiv 2021
-
[3]
Bofei Gao, Feifan Song, Zhe Yang, Zefan Cai, Yibo Miao, Qingxiu Dong, Lei Li, Chenghao Ma, Liang Chen, Runxin Xu, and 1 others. 2024. Omni-math: A universal olympiad level mathematic benchmark for large language models. arXiv preprint arXiv:2410.07985
work page internal anchor Pith review arXiv 2024
-
[4]
Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Yu Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, and 1 others. 2025. Are we done with mmlu? In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Langu...
2025
-
[5]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review arXiv 2024
-
[6]
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, and 1 others. 2024. A survey on llm-as-a-judge. arXiv preprint arXiv:2411.15594
work page internal anchor Pith review arXiv 2024
-
[7]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review arXiv 2025
-
[8]
Nathan Habib, Clémentine Fourrier, Hynek Kydlíček, Thomas Wolf, and Lewis Tunstall. 2023. https://github.com/huggingface/lighteval Lighteval: A lightweight framework for llm evaluation
2023
-
[9]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, and 1 others. 2024. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume...
2024
-
[10]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874
work page internal anchor Pith review arXiv 2021
-
[11]
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, and 1 others. 2024. Tulu 3: Pushing frontiers in open language model post-training. arXiv preprint arXiv:2411.15124
work page internal anchor Pith review arXiv 2024
-
[12]
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, and 1 others. 2022. Solving quantitative reasoning problems with language models. Advances in neural information processing systems, 35:3843--3857
2022
-
[13]
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. 2024 a . Llms-as-judges: a comprehensive survey on llm-based evaluation methods. arXiv preprint arXiv:2412.05579
work page internal anchor Pith review arXiv 2024
- [14]
- [15]
-
[16]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let's verify step by step. In The Twelfth International Conference on Learning Representations
2023
-
[17]
Tianqiao Liu, Zui Chen, Zhensheng Fang, Weiqi Luo, Mi Tian, and Zitao Liu. 2025. Matheval: A comprehensive benchmark for evaluating large language models on mathematical reasoning capabilities. Frontiers of Digital Education, 2(2):16
2025
-
[18]
Aaron Meurer, Christopher P. Smith, Mateusz Paprocki, Ond r ej C ert\' i k, Sergey B. Kirpichev, Matthew Rocklin, AMiT Kumar, Sergiu Ivanov, Jason K. Moore, Sartaj Singh, Thilina Rathnayake, Sean Vig, Brian E. Granger, Richard P. Muller, Francesco Bonazzi, Harsh Gupta, Shivam Vats, Fredrik Johansson, Fabian Pedregosa, and 8 others. 2017. https://doi.org/1...
-
[19]
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. 2024. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models. arXiv preprint arXiv:2410.05229
work page Pith review arXiv 2024
-
[20]
A Yang Qwen, Baosong Yang, B Zhang, B Hui, B Zheng, B Yu, Chengpeng Li, D Liu, F Huang, H Wei, and 1 others. 2024. Qwen2. 5 technical report. arXiv preprint
2024
-
[21]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review arXiv 2024
- [22]
- [23]
- [24]
- [25]
- [26]
-
[27]
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. 2024. Math-shepherd: Verify and reinforce llms step-by-step without human annotations. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9426--9439
2024
-
[28]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171
work page internal anchor Pith review arXiv 2022
-
[29]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
- [30]
-
[31]
Shijie Xia, Xuefeng Li, Yixin Liu, Tongshuang Wu, and Pengfei Liu. 2025. Evaluating mathematical reasoning beyond accuracy. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 27723--27730
2025
-
[32]
An Yang, Beichen Zhang, Binyuan Hui, Bofei Gao, Bowen Yu, Chengpeng Li, Dayiheng Liu, Jianhong Tu, Jingren Zhou, Junyang Lin, and 1 others. 2024. Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement. arXiv preprint arXiv:2409.12122
work page internal anchor Pith review arXiv 2024
- [33]
-
[34]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. 2025. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837
work page internal anchor Pith review arXiv 2025
-
[35]
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. 2025. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild. arXiv preprint arXiv:2503.18892
work page internal anchor Pith review arXiv 2025
-
[36]
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2025. Processbench: Identifying process errors in mathematical reasoning. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1009--1024
2025
-
[37]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, and 1 others. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in neural information processing systems, 36:46595--46623
2023
-
[38]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[39]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.