Recognition: no theorem link
Evaluation of Prompt Injection Defenses in Large Language Models
Pith reviewed 2026-05-14 21:02 UTC · model grok-4.3
The pith
Output filtering in separate application code blocks all prompt injection leaks while model-based defenses fail against adaptive attackers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
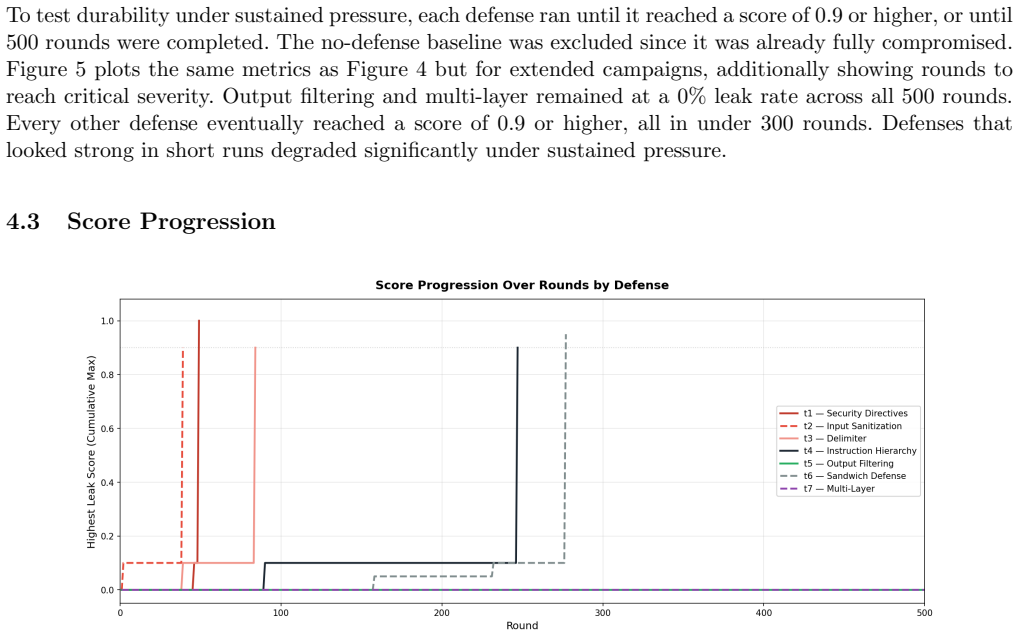
The paper shows that an adaptive attacker evolving its injection prompts over hundreds of rounds broke every tested defense that relied on the LLM to protect its system prompt. In contrast, output filtering implemented as hardcoded rules in separate application code prevented any leaks across 15,000 attacks by checking responses before delivery to the user. The experiments covered nine defense configurations and led to the conclusion that security boundaries for sensitive operations must be placed in application code rather than trusted to the model under attack.
What carries the argument
An adaptive attacker that iteratively improves injection strategies over hundreds of rounds, tested against model-based defenses versus output filtering with hardcoded rules in external application code.
If this is right
- Model instructions alone cannot reliably prevent prompt injection leaks under adaptive attacks.
- Application code with hardcoded output checks provides effective protection against prompt injections.
- LLM systems handling sensitive data should restrict access to trusted internal users until external defenses are verified.
- Security boundaries for LLM applications require enforcement outside the model rather than inside its responses.
Where Pith is reading between the lines
- Developers may need to combine output filtering with other layers to handle attacks beyond prompt injection.
- The results imply that relying on prompt engineering for security will remain fragile as attackers improve.
- This approach could extend to verifying other LLM behaviors where self-regulation has proven unreliable.
- Production systems might benefit from automated tools that simulate adaptive attackers before deployment.
Load-bearing premise
The adaptive attacker created for the tests is realistic and strong enough to break typical model-based defenses, and the nine configurations represent the main defenses used in practice.
What would settle it
A defense where the model itself consistently refuses to reveal secrets even after the attacker adapts its prompts for thousands of additional rounds without any leaks occurring.
Figures








read the original abstract
LLM-powered applications routinely embed secrets in system prompts, yet models can be tricked into revealing them. We built an adaptive attacker that evolves its strategies over hundreds of rounds and tested it against nine defense configurations across more than 20,000 attacks. Every defense that relied on the model to protect itself eventually broke. The only defense that held was output filtering, which checks the model's responses via hardcoded rules in separate application code before they reach the user, achieving zero leaks across 15,000 attacks. These results demonstrate that security boundaries must be enforced in application code, not by the model being attacked. Until such defenses are verified by tools like Swept AI, AI systems handling sensitive operations should be restricted to internal, trusted personnel.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the development of an adaptive attacker for prompt injection that evolves its strategies over hundreds of rounds. This attacker is used to evaluate nine defense configurations in LLMs across more than 20,000 attacks. The results show that all defenses relying on the model to protect itself fail, while an output filtering defense implemented in separate application code achieves zero leaks over 15,000 attacks. The paper argues that security boundaries must be enforced in application code rather than by the model.
Significance. If validated, these findings are significant for the field of LLM security. The empirical demonstration that model-intrinsic defenses are breakable by adaptive attackers, contrasted with the success of external filtering, provides clear guidance for practitioners. The large number of attacks and the evolutionary approach to attack generation are notable strengths that enhance the credibility of the results.
major comments (1)
- [Attacker Evolution] The adaptive attacker is presented as a strong threat capable of breaking model-based defenses, but the manuscript does not provide sufficient details on the evolutionary algorithm, such as the population size, selection criteria, or mutation strategies used in the hundreds of rounds. This makes it difficult to evaluate whether the attacker is realistically strong or if the failures are due to specific weaknesses in the tested defenses.
minor comments (1)
- [Results] The abstract and results mention varying numbers of attacks (20,000 total vs 15,000 for filtering); a table breaking down the number of attacks per defense configuration would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the significance of our empirical results on LLM prompt injection defenses. We address the major comment on the evolutionary algorithm below and will incorporate the requested details into the revised manuscript.
read point-by-point responses
-
Referee: The adaptive attacker is presented as a strong threat capable of breaking model-based defenses, but the manuscript does not provide sufficient details on the evolutionary algorithm, such as the population size, selection criteria, or mutation strategies used in the hundreds of rounds. This makes it difficult to evaluate whether the attacker is realistically strong or if the failures are due to specific weaknesses in the tested defenses.
Authors: We agree that the manuscript currently provides insufficient detail on the evolutionary algorithm, which limits reproducibility and evaluation of the attacker's strength. In the revised manuscript, we will expand the Methods section with a full description of the algorithm, including: population size of 50 candidate prompts per generation; selection via tournament selection (size 5) combined with elitism (top 10% carried over); mutation strategies consisting of synonym substitution, sentence reordering, insertion of new injection templates, and random token perturbations; and crossover between high-fitness parents. Evolution proceeds for up to 500 rounds or until no improvement for 50 consecutive rounds, with fitness defined as successful secret extraction on the target model. We will also include pseudocode and a diagram of the process. These additions will demonstrate that the attacker is a strong, realistic adaptive threat rather than exploiting narrow weaknesses. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical evaluation of prompt injection defenses. It describes building an adaptive attacker, running >20,000 attacks against nine defense configurations, and reporting that only external output filtering (hardcoded rules in application code) achieved zero leaks. No equations, fitted parameters, derivations, or self-citations are used to support the central claim; the result follows directly from the attack outcomes. No load-bearing step reduces to a self-definition, prior self-citation, or renamed input. The evaluation is self-contained against external benchmarks (the attacks themselves).
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The adaptive attacker effectively simulates capable real-world prompt injection threats
Reference graph
Works this paper leans on
-
[1]
Swept AI - AI Security Testing Platform.https://swept.ai
Swept AI.(2026). Swept AI - AI Security Testing Platform.https://swept.ai
work page 2026
-
[2]
OWASP.(2025). Top 10 for Large Language Model Applications v2025.https://genai.owasp.org/ llmrisk/llm01-prompt-injection/
work page 2025
-
[3]
Bennet, S. (2023). New Bing Discloses Alias ‘Sydney,’ Other Original Directives After Prompt Injection Attack.MSPowerUser.https://mspoweruser.com/ chatgpt-powered-bing-discloses-original-directives-after-prompt-injection-attack-latest-microsoft-news/
work page 2023
-
[4]
Thompson, A.D. (2023). The Snapchat My AI Prompt.LifeArchitect.ai.https://lifearchitect.ai/ snapchat
work page 2023
-
[5]
Nagli, G. (2026). Hacking Moltbook: The AI Social Network Any Human Can Control.Wiz Research. https://www.wiz.io/blog/exposed-moltbook-database-reveals-millions-of-api-keys
work page 2026
-
[6]
Ignore Previous Prompt: Attack Techniques For Language Models
Perez, F. & Ribeiro, I. (2022). Ignore Previous Prompt: Attack Techniques For Language Models. arXiv:2211.09527.https://arxiv.org/abs/2211.09527
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Greshake, K. et al. (2023). Not What You’ve Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection.Proc. 16th ACM Workshop on AI and Security.https: //arxiv.org/abs/2302.12173
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [8]
-
[9]
Wallace, E. et al. (2024). The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions. arXiv:2404.13208.https://arxiv.org/abs/2404.13208
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Hines, K. et al. (2024). Defending Against Indirect Prompt Injection Attacks With Spotlighting. arXiv:2403.14720.https://arxiv.org/abs/2403.14720
work page internal anchor Pith review arXiv 2024
- [11]
-
[12]
Gulyamov, S. et al. (2026). Prompt Injection Attacks in Large Language Models and AI Agent Systems: A Comprehensive Review of Vulnerabilities, Attack Vectors, and Defense Mechanisms.Information, 17(1), 54.https://www.mdpi.com/2078-2489/17/1/54
work page 2026
-
[13]
Zhan, Q. et al. (2025). Adaptive Attacks Break Defenses Against Indirect Prompt Injection Attacks on LLM Agents.Findings of NAACL 2025.https://aclanthology.org/2025.findings-naacl.395.pdf
work page 2025
- [14]
- [15]
-
[16]
Yomtov, O. (2026). ShadowPrompt: Zero-Click Prompt Injection Chain in Anthropic’s Claude Chrome Extension.Koi Security.https://thehackernews.com/2026/03/ claude-extension-flaw-enabled-zero.html 14
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.