Recognition: unknown
LLM-Guided Agentic Floor Plan Parsing for Accessible Indoor Navigation of Blind and Low-Vision People
Pith reviewed 2026-05-08 03:47 UTC · model grok-4.3
The pith
A multi-agent LLM framework turns floor plan images into structured maps for generating safe navigation instructions for blind and low-vision people.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
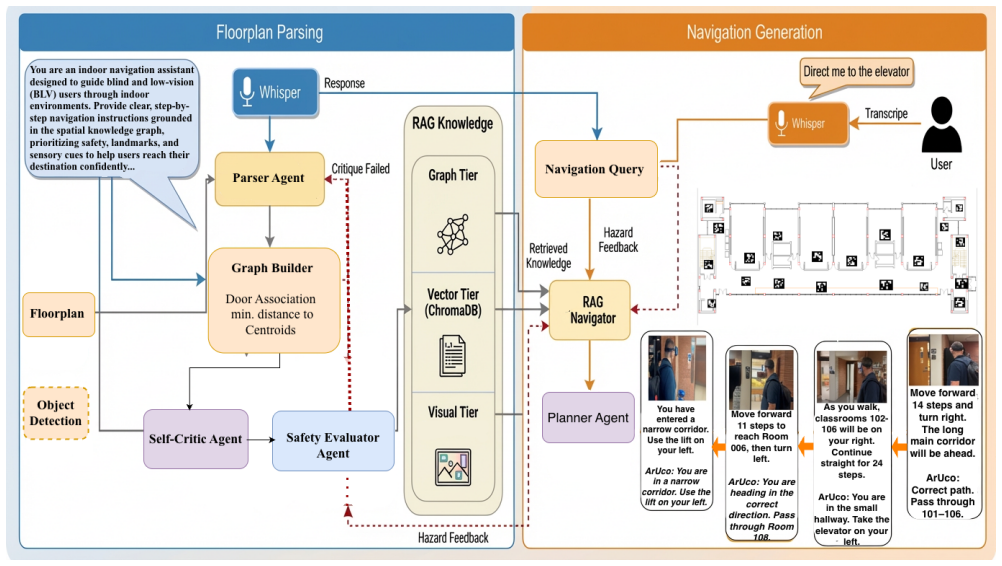
The paper shows that the agentic parsing pipeline builds a retrievable spatial knowledge base from one floor plan image, enabling a path planner and safety evaluator to produce accessible navigation instructions that succeed at rates up to 92.31 percent for short routes on the MP-1 floor, outperforming the strongest baseline.
What carries the argument
The multi-agent module that parses the floor plan into a spatial knowledge graph through a self-correcting pipeline with iterative retry loops and corrective feedback.
If this is right
- Provides a scalable solution for accessible indoor navigation using only existing floor plans.
- Achieves consistent performance gains over single LLM calls across route lengths and building floors.
- Reduces reliance on costly per-building infrastructure for BLV navigation.
- Supports generation of safe routes by evaluating hazards along proposed paths.
Where Pith is reading between the lines
- The approach could extend to dynamic environments by updating the knowledge graph with real-time sensor data.
- Similar agentic workflows might improve other tasks like generating tactile maps or voice descriptions of spaces.
- Testing on diverse building types would reveal how well the system generalizes beyond university structures.
Load-bearing premise
The LLM agents accurately extract spatial relations and hazard information from floor plan images without systematic errors or the need for building-specific fine-tuning.
What would settle it
Running the system on a new building and finding that many generated routes contain unaccounted hazards or fail to reach the destination more often than the baseline method.
Figures




read the original abstract
Indoor navigation remains a critical accessibility challenge for the blind and low-vision (BLV) individuals, as existing solutions rely on costly per-building infrastructure. We present an agentic framework that converts a single floor plan image into a structured, retrievable knowledge base to generate safe, accessible navigation instructions with lightweight infrastructure. The system has two phases: a multi-agent module that parses the floor plan into a spatial knowledge graph through a self-correcting pipeline with iterative retry loops and corrective feedback; and a Path Planner that generates accessible navigation instructions, with a Safety Evaluator agent assessing potential hazards along each route. We evaluate the system on the real-world UMBC Math and Psychology building (floors MP-1 and MP-3) and on the CVC-FP benchmark. On MP-1, we achieve success rates of 92.31%, 76.92%, and 61.54% for short, medium, and long routes, outperforming the strongest single-call baseline (Claude 3.7 Sonnet) at 84.62%, 69.23%, and 53.85%. On MP-3, we reach 76.92%, 61.54%, and 38.46%, compared to the best baseline at 61.54%, 46.15%, and 23.08%. These results show consistent gains over single-call LLM baselines and demonstrate that our workflow is a scalable solution for accessible indoor navigation for BLV individuals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents an agentic LLM framework that parses a single floor-plan image into a structured spatial knowledge graph via a multi-agent self-correcting pipeline with retry loops, then employs a Path Planner and Safety Evaluator to generate accessible navigation instructions for blind and low-vision users. It reports concrete success rates on two floors of the UMBC Math & Psychology building (MP-1: 92.31%/76.92%/61.54% for short/medium/long routes; MP-3: 76.92%/61.54%/38.46%) that outperform single-call baselines such as Claude 3.7 Sonnet, and states that the system was also evaluated on the CVC-FP benchmark.
Significance. If the performance claims hold under transparent protocols, the work offers a potentially scalable, low-infrastructure alternative to hardware-dependent indoor navigation aids by turning existing floor plans into retrievable knowledge bases. Credit is due for the real-building evaluation on MP-1/MP-3 and the inclusion of an external benchmark, as well as the explicit multi-agent error-correction design. The approach addresses a genuine accessibility gap, but its impact hinges on demonstrating that the reported gains stem from reliable spatial parsing rather than extra inference steps.
major comments (3)
- [Abstract and §4] Abstract and §4 (Evaluation): The headline success rates on MP-1 and MP-3 are given without any description of the evaluation protocol, including total number of routes per length bin, route sampling procedure, number of independent trials, or the exact criteria used to judge a route 'successful' (e.g., hazard-free arrival, time limits, or human verification). With only ~13 routes per category, the 7–8 percentage-point margins over baselines cannot be assessed for statistical reliability or robustness.
- [Abstract and §4] Abstract and §4: No quantitative results, success rates, or error analysis are reported for the CVC-FP benchmark despite its explicit mention as an evaluation target. This omission prevents any assessment of generalization beyond the visual conventions of the two MP floors.
- [§3.1–3.2] §3.1–3.2 (Multi-agent Parsing Pipeline): The central claim that the self-correcting multi-agent module produces an accurate spatial knowledge graph and hazard map rests on the assumption that LLMs can reliably extract precise spatial relations (door swings, connectivity, stair/elevator symbols) without systematic errors. No failure-case breakdown, per-relation accuracy metrics, or ablation on the retry/feedback loop is provided to substantiate this assumption.
minor comments (2)
- [§3.1] The notation used for the spatial knowledge graph entities and relations should be formalized (e.g., via a small table or BNF) to improve reproducibility.
- [Figures 2–4] Figure captions and legends for parsed graph visualizations should explicitly label all node/edge types and hazard symbols.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important areas for improving the clarity and rigor of our evaluation and analysis. We address each major comment point-by-point below and commit to substantial revisions that directly incorporate the requested details, metrics, and ablations.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Evaluation): The headline success rates on MP-1 and MP-3 are given without any description of the evaluation protocol, including total number of routes per length bin, route sampling procedure, number of independent trials, or the exact criteria used to judge a route 'successful' (e.g., hazard-free arrival, time limits, or human verification). With only ~13 routes per category, the 7–8 percentage-point margins over baselines cannot be assessed for statistical reliability or robustness.
Authors: We agree that the evaluation protocol was under-specified in the submitted version. In the revised manuscript we will add a dedicated subsection in §4 that explicitly states: (i) 13 routes per length bin (short: <20 m, medium: 20–50 m, long: >50 m), sampled by enumerating all feasible start–end pairs on the ground-truth graph and binning by shortest-path distance; (ii) the exact success criterion (the generated instruction sequence must produce a hazard-free path that reaches the destination when executed on the verified building graph, confirmed by two independent human annotators); (iii) three independent runs of the full pipeline per route to account for LLM stochasticity, with mean success rates and standard deviations reported; and (iv) a statistical comparison (McNemar’s test or bootstrap confidence intervals) for the observed margins. These additions will allow readers to assess reliability directly. revision: yes
-
Referee: [Abstract and §4] Abstract and §4: No quantitative results, success rates, or error analysis are reported for the CVC-FP benchmark despite its explicit mention as an evaluation target. This omission prevents any assessment of generalization beyond the visual conventions of the two MP floors.
Authors: We acknowledge the omission. Although the manuscript states that the system was evaluated on CVC-FP, we did not include the numerical results. In the revision we will insert a new paragraph in §4 reporting: overall parsing accuracy (node/edge F1), navigation success rates broken down by route length, and a brief error analysis contrasting failure modes on CVC-FP versus the MP floors. This will directly demonstrate generalization across different floor-plan visual styles. revision: yes
-
Referee: [§3.1–3.2] §3.1–3.2 (Multi-agent Parsing Pipeline): The central claim that the self-correcting multi-agent module produces an accurate spatial knowledge graph and hazard map rests on the assumption that LLMs can reliably extract precise spatial relations (door swings, connectivity, stair/elevator symbols) without systematic errors. No failure-case breakdown, per-relation accuracy metrics, or ablation on the retry/feedback loop is provided to substantiate this assumption.
Authors: We agree that stronger empirical support for the parsing module is required. The revised §3 will include: (1) a qualitative failure-case table with representative examples of initial extraction errors (e.g., incorrect door-swing direction, missed stair symbols) and how the retry/feedback loop corrects them; (2) per-relation precision/recall/F1 scores computed on a manually annotated subset of 20 floor-plan images (covering connectivity, door attributes, and symbol detection); and (3) an ablation that disables the self-correction loop and reports the resulting drop in graph accuracy and downstream navigation success. These additions will quantify the contribution of the multi-agent design. revision: yes
Circularity Check
No circularity: empirical system evaluation with no derivations or fitted predictions
full rationale
The paper presents a multi-agent LLM framework for parsing floor-plan images into a spatial knowledge graph and generating navigation instructions, evaluated empirically on real building floors (MP-1, MP-3) and the CVC-FP benchmark. Success rates are reported as direct measurements against single-call LLM baselines, with no equations, first-principles derivations, parameter fitting, or self-referential definitions. The claimed gains rest on external comparisons and real-world testing rather than any reduction of outputs to inputs by construction. No self-citation chains, ansatzes, or uniqueness theorems are invoked as load-bearing elements. The work is therefore self-contained as a systems contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
World report on vision
World Health Organization. World report on vision. WHO, 2019
2019
-
[2]
Kuriakose, R
B. Kuriakose, R. Shrestha, and F. Sandnes. Smartphone- based indoor navigation for the blind and visually impaired: A comprehensive review.Electronics, 11(8):1283, 2022
2022
-
[3]
Nakajimaet al.Indoor navigation using ArUco markers and graph-based pathfinding
Y . Nakajimaet al.Indoor navigation using ArUco markers and graph-based pathfinding. InProc. IEEE ICCE, 2023
2023
-
[4]
Zafari, A
F. Zafari, A. Gkelias, and K. Leung. A survey of indoor lo- calization systems and technologies.IEEE Commun. Surveys Tut., 21(3):2568–2599, 2019
2019
-
[5]
Chenet al.MapGPT: Map-guided prompting with adap- tive path planning for vision-and-language navigation
J. Chenet al.MapGPT: Map-guided prompting with adap- tive path planning for vision-and-language navigation. In Proc. ACL, 2024
2024
-
[6]
Chenet al.SpatialVLM: Endowing vision-language mod- els with spatial reasoning
B. Chenet al.SpatialVLM: Endowing vision-language mod- els with spatial reasoning. InProc. CVPR, 2024
2024
- [7]
-
[8]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever. Robust speech recognition via large-scale weak supervision.arXiv:2212.04356, 2022
work page internal anchor Pith review arXiv 2022
-
[9]
de las Heras, S
L.-P. de las Heras, S. Terrades, S. Robles, and G. Sánchez. CVC-FP and SGT: A new database for structural floor plan analysis and its groundtruthing tool.International Journal on Document Analysis and Recognition (IJDAR), 18(1):15– 30, 2015
2015
-
[10]
A. Dubeyet al.The LLaMA 3 herd of models. arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[11]
Ganon, M
K. Ganon, M. Alper, R. Mikulinsky, and H. Averbuch-Elor. Waffle: Multimodal floorplan understanding in the wild. In Proc. IEEE/CVF WACV, pp. 1488–1497, 2025
2025
- [12]
-
[13]
Coffrini, P
A. Coffrini, P. Barsocchi, F. Furfari, A. Crivello, and A. Fer- rari. LLM-guided indoor navigation with multimodal map understanding. InProc. IPIN, pp. 1–6, 2025
2025
-
[14]
A. Ayanzadeh and T. Oates. Floorplan2Guide: LLM- guided floorplan parsing for BLV indoor navigation. arXiv:2512.12177, 2025
work page internal anchor Pith review arXiv 2025
-
[15]
Singh, R
A. Singh, R. Patel, and M. Kumar. ViLLA: Vision-language layout analyzer for automatic floor plan analysis. InProc. DAS, 2024
2024
-
[16]
Lewiset al.Retrieval-augmented generation for knowledge-intensive NLP tasks
P. Lewiset al.Retrieval-augmented generation for knowledge-intensive NLP tasks. InProc. NeurIPS, 2020
2020
-
[17]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
D. Edgeet al.From local to global: A graph RAG approach to query-focused summarization.arXiv:2404.16130, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
Y . Ning, Y . Liu, and Y . Zheng. UrbanKGent: A unified LLM agent framework for urban knowledge graph construction. In Proc. NeurIPS, 2024
2024
-
[19]
Madaanet al.Self-Refine: Iterative refinement with self- feedback
A. Madaanet al.Self-Refine: Iterative refinement with self- feedback. InProc. NeurIPS, 2023
2023
-
[20]
Yanget al.W AFFLE: Multimodal floor plan understand- ing with LLMs and VLMs.arXiv:2407.10320, 2024
X. Yanget al.W AFFLE: Multimodal floor plan understand- ing with LLMs and VLMs.arXiv:2407.10320, 2024
-
[21]
R. Jianget al.ChatHouseDiffusion: LLM-driven floor plan generation with diffusion and graph representation. arXiv:2405.13632, 2024
-
[22]
Y . Tian, Q. Ye, and D. Doermann. YOLOv12: Attention- centric real-time object detectors.arXiv:2502.12524, 2025
work page internal anchor Pith review arXiv 2025
-
[23]
Claude 3.7 Sonnet model card, 2025
Anthropic. Claude 3.7 Sonnet model card, 2025
2025
-
[24]
Chroma: The AI-native open-source embedding database, 2024
Chroma. Chroma: The AI-native open-source embedding database, 2024
2024
-
[25]
Hagberg, P
A. Hagberg, P. Swart, and D. Chult. Exploring network structure, dynamics, and function using NetworkX. InProc. SciPy, 2008
2008
-
[26]
Gupta and A
T. Gupta and A. Kembhavi. Visual programming: Compo- sitional visual reasoning without training. InProc. CVPR, 2023
2023
-
[27]
R. K. Keser, I. Nallbani, N. Çalik, A. Ayanzadeh, and B. U. Töreyin. Graph embedding for link prediction using residual variational graph autoencoders. InProc. SIU, pp. 1– 4, 2020
2020
-
[28]
I. Nallbani, R. K. Keser, A. Ayanzadeh, N. Çalık, and B. U. Töreyin. ResVGAE: Going Deeper with Residual Modules for Link Prediction.arXiv preprint arXiv:2105.00695, 2021
-
[29]
Garrido-Jurado, R
S. Garrido-Jurado, R. Muñoz-Salinas, F. J. Madrid-Cuevas, and M. J. Marín-Jiménez. Automatic generation and detec- tion of highly reliable fiducial markers under occlusion.Pat- tern Recognition, 47(6):2280–2292, 2014
2014
-
[30]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Z. Yanget al.MM-ReAct: Prompting ChatGPT for multi- modal reasoning and action.arXiv:2303.11381, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
Yaoet al.ReAct: Synergizing reasoning and acting in language models
S. Yaoet al.ReAct: Synergizing reasoning and acting in language models. InProc. ICLR, 2023
2023
-
[32]
Wanget al.V oyager: An open-ended embodied agent with large language models
G. Wanget al.V oyager: An open-ended embodied agent with large language models. InProc. NeurIPS, 2023
2023
-
[33]
Zhouet al.NavGPT: Explicit reasoning in vision-and- language navigation with large language models
W. Zhouet al.NavGPT: Explicit reasoning in vision-and- language navigation with large language models. InProc. AAAI, 2024
2024
-
[34]
Liang, G
Y . Liang, G. Li, and X. Chen. DiscussNav: Discussion im- proves zero-shot vision-and-language navigation via multi- expert consultation. InProc. IEEE ICRA, 2024
2024
-
[35]
Shabani, S
M. Shabani, S. Lim, and Y . Furukawa. HouseDiffusion: Vec- tor floorplan generation via a diffusion model with discrete and continuous denoising. InProc. CVPR, 2023
2023
-
[36]
Z. Fan, L. Zhu, H. Li, X. Chen, S. Zhu, and P. Tan. Floor- PlanCAD: A large-scale CAD drawing dataset for panoptic symbol spotting. InProc. ICCV, 2021
2021
-
[37]
arXiv preprint arXiv:2009.09941 , year=
Y . Duet al.PP-OCR: A practical ultra lightweight OCR system.arXiv preprint arXiv:2009.09941, 2020. Appendix A Compact version of prompt for Parser, Planner, self-critics, and safety evaluator Agents. Parser Agent You are an AI analysing architectural floor plan images. TASK: Extract room-connectivity graph + metadata. Return ONLY valid JSON. {detection_c...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.