Recognition: unknown
V.O.I.C.E (Voice, Ownership, Identity, Control, Expression): Risk Taxonomy of Synthetic Voice Generation From Empirical Data
Pith reviewed 2026-05-08 07:42 UTC · model grok-4.3
The pith
The V.O.I.C.E taxonomy classifies risks from synthetic voice generation by drawing on empirical incidents, reports, and discussions to show how harms emerge and interact with exposure, visibility, and legal protections.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
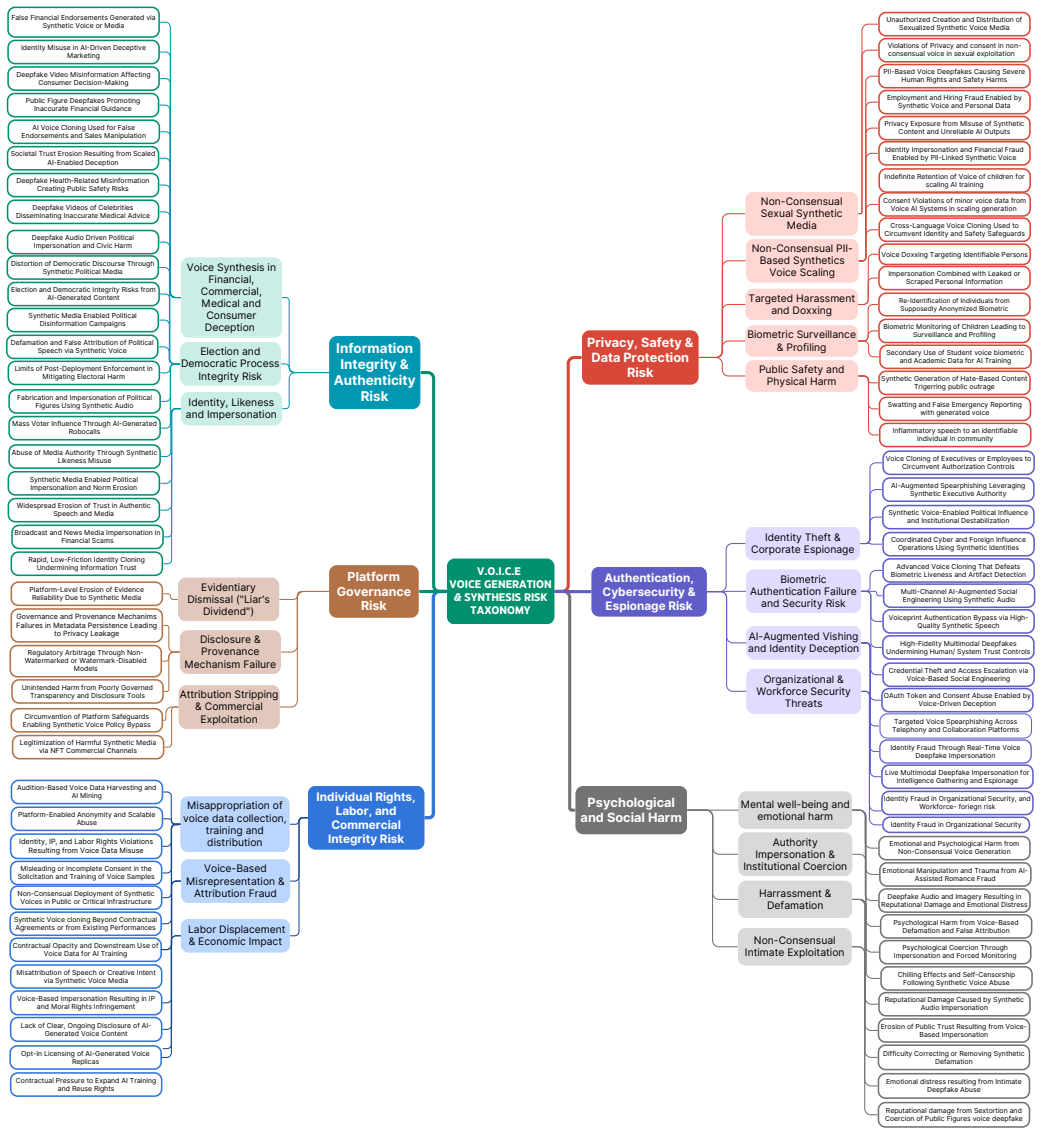
The central claim is that a taxonomy named V.O.I.C.E (Voice, Ownership, Identity, Control, Expression), derived from multi-source real-world data, explicitly models the emergence of synthetic voice risks and their interactions with contextual factors such as degree of exposure, social visibility, and the availability of legal protections across affected groups, thereby filling gaps in existing uniform threat models.
What carries the argument
The V.O.I.C.E taxonomy, which stands for Voice, Ownership, Identity, Control, Expression, functions as the organizing framework that categorizes risks and traces their dependence on contextual factors like exposure and legal protections.
Load-bearing premise
The collected incidents, reports, and discussions are representative enough to produce a comprehensive taxonomy that captures all major risk interactions with exposure, visibility, and legal protections.
What would settle it
Discovery of a major synthetic voice risk scenario that cannot be placed in any V.O.I.C.E category or that does not interact with exposure, visibility, or legal protections in the manner the taxonomy predicts.
Figures
read the original abstract
As generative voice models are rapidly advancing in both capabilities and public utilization, the unconsented collection, reuse, and synthesis of voice data are introducing new classes of privacy, security and governance risk that are poorly captured by existing, largely uniform threat models. To fill the gap, we present V.O.I.C.E, a taxonomy of voice generation risk grounded in a multi-source threat modeling effort with 569 incidents from major AI incident database, FTC and Internet Crime Complaint Center (IC3); 1067 direct incident reports from U.S. based participants across diverse groups (including voice actors, internet personalities, political personnel, and general public); and 2,221 Reddit discussions. Grounded in real-world data, our taxonomy explicitly models how risk emerges, interact with contextual factors such as degree of exposure, social visibility, and the availability of legal protections for various affected groups.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces V.O.I.C.E, a five-category taxonomy (Voice, Ownership, Identity, Control, Expression) for risks arising from synthetic voice generation. It is constructed from a multi-source empirical effort comprising 569 incidents drawn from AI incident databases, FTC, and IC3 records; 1,067 direct reports from U.S.-based participants across voice actors, internet personalities, political figures, and the general public; and 2,221 Reddit discussions. The central claim is that this taxonomy explicitly models how risks emerge and interact with contextual factors such as degree of exposure, social visibility, and availability of legal protections for different affected groups.
Significance. If the empirical construction and interaction modeling are substantiated with transparent methods, the taxonomy would represent a meaningful advance over existing uniform threat models in AI security and privacy. The scale and diversity of the data sources—particularly the inclusion of reports from voice professionals and public figures—provide a concrete empirical base that could inform policy, detection tools, and governance frameworks. This data-driven approach is a clear strength relative to purely conceptual taxonomies in the field.
major comments (2)
- [§3 and §4] §3 Data Collection and §4 Taxonomy Derivation: The manuscript provides counts of incidents, reports, and discussions but contains no description of the thematic analysis or coding procedure used to map these sources onto the five V.O.I.C.E categories, nor any mention of inter-rater reliability, duplicate handling, or bias mitigation. This absence directly undermines the central claim that the taxonomy is 'grounded in real-world data' and 'explicitly models' risk emergence.
- [§5] §5 Risk Interaction Analysis: The abstract asserts that the taxonomy models interactions between risks and contextual factors (exposure, visibility, legal protections), yet no concrete examples, tables, or diagrams illustrate these interactions for specific groups (e.g., how legal protections differentially affect voice actors versus the general public). Without such evidence the interaction-modeling claim remains unsupported.
minor comments (2)
- [Abstract] Abstract: The V.O.I.C.E acronym is expanded but the paper does not provide even one-sentence definitions of each category, which would improve immediate readability.
- [Related Work] Related Work: The discussion of prior voice-synthesis risk literature is brief; adding explicit comparison to existing taxonomies (e.g., those focused on deepfakes or biometric privacy) would clarify the claimed novelty.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important opportunities to strengthen the transparency and evidentiary support in our manuscript. We address each major comment below and commit to revisions that will clarify our methods and substantiate our claims without altering the core contributions.
read point-by-point responses
-
Referee: [§3 and §4] §3 Data Collection and §4 Taxonomy Derivation: The manuscript provides counts of incidents, reports, and discussions but contains no description of the thematic analysis or coding procedure used to map these sources onto the five V.O.I.C.E categories, nor any mention of inter-rater reliability, duplicate handling, or bias mitigation. This absence directly undermines the central claim that the taxonomy is 'grounded in real-world data' and 'explicitly models' risk emergence.
Authors: We agree that the absence of a methods description for the thematic analysis is a significant omission that weakens the presentation of our empirical grounding. In the revised manuscript, we will insert a dedicated subsection in §4 that details the iterative coding process used to map the 569 incidents, 1,067 reports, and 2,221 discussions onto the V.O.I.C.E categories. This will include the initial open coding approach, how duplicates were identified and resolved across sources, and steps taken to mitigate researcher bias through team review. Although formal inter-rater reliability statistics were not calculated in the original exploratory analysis, we will explicitly describe the collaborative validation process and acknowledge this as a limitation. These additions will directly support the claim that the taxonomy is grounded in real-world data. revision: yes
-
Referee: [§5] §5 Risk Interaction Analysis: The abstract asserts that the taxonomy models interactions between risks and contextual factors (exposure, visibility, legal protections), yet no concrete examples, tables, or diagrams illustrate these interactions for specific groups (e.g., how legal protections differentially affect voice actors versus the general public). Without such evidence the interaction-modeling claim remains unsupported.
Authors: We concur that §5 currently provides insufficient concrete illustrations of the risk interactions with contextual factors, leaving the abstract's claims under-supported. In the revision, we will expand §5 with specific examples drawn from the empirical sources, a new table that contrasts differential impacts (such as legal protections for voice actors versus the general public), and a diagram showing how exposure, visibility, and legal context modulate the V.O.I.C.E categories. These elements will be tied directly to the collected data to make the interaction modeling explicit and verifiable. revision: yes
Circularity Check
No circularity: empirical taxonomy from external data sources
full rationale
The paper constructs the V.O.I.C.E taxonomy directly from multi-source external data (569 incidents from public databases, 1067 participant reports, 2221 Reddit discussions). No equations, fitted parameters, predictions, or self-referential derivations appear. The central claim is an inductive classification grounded in independent real-world sources rather than any reduction to the paper's own inputs or prior self-citations. This is a standard non-circular empirical effort.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-source incident and report data is representative of the full range of synthetic voice risks and their interactions with exposure, visibility, and legal protections.
invented entities (1)
-
V.O.I.C.E taxonomy (Voice, Ownership, Identity, Control, Expression categories)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Biometric Information Privacy Act
-
[2]
Minnesota Consumer Privacy Act
-
[3]
Nurture Originals, Foster Art, and Keep Entertainment Safe Act of 2025
2025
-
[4]
Require the Exposure of AI–Led Political Advertisements Act
-
[5]
Stop Spying Bosses Act
-
[6]
Strengthening Artificial intelligence Normalization and Diffusion By Oversight and eXperimentation Act
-
[7]
Texas Responsible Artificial Intelligence Governance Act
-
[8]
Sound check: Auditing audio datasets
William Agnew,JuliaBarnett,AnnieChu,RachelHong,Michael Feffer, Robin Netzorg, Harry H Jiang, Ezra Awumey, and Sauvik Das. Sound check: Auditing audio datasets. arXiv preprint arXiv:2410.13114, 2024
-
[9]
Artificial intelligence risk management framework (ai rmf 1.0).URL: https://nvlpubs.nist
NIST AI. Artificial intelligence risk management framework (ai rmf 1.0).URL: https://nvlpubs.nist. gov/nistpubs/ai/nist.ai, pages 100–1, 2023
2023
-
[10]
Resemble ai: Generative voice cloning.https: //www.resemble.ai, 2024
Resemble AI. Resemble ai: Generative voice cloning.https: //www.resemble.ai, 2024. Accessed: 2024-05-20
2024
-
[11]
Artificial intelligence incident database (aiid)
AI Incident Database. Artificial intelligence incident database (aiid). https://incidentdatabase.ai/ , 2026. Incident repository indexing real-world AI harms and near-harms
2026
-
[12]
TheriseoftheAI-clonedvoicescam
JeffreyM.Allen. TheriseoftheAI-clonedvoicescam. American Bar Association, Voice of Experience, September 2025
2025
-
[13]
Areviewofmodernaudio deepfake detection methods: challenges and future directions
ZaynabAlmutairiandHebahElgibreen. Areviewofmodernaudio deepfake detection methods: challenges and future directions. Algorithms, 15(5):155, 2022
2022
-
[14]
Amazon Alexa.https://alexa.amazon.com/,2024
Amazon. Amazon Alexa.https://alexa.amazon.com/,2024. Accessed: 2024
2024
-
[15]
Deep voice 2: multi-speaker neural text-to-speech
SercanÖ.Arık,GregoryDiamos,AndrewGibiansky,JohnMiller, KainanPeng,WeiPing,JonathanRaiman,andYanqiZhou. Deep voice 2: multi-speaker neural text-to-speech. NIPS’17, page 2966–2974, Red Hook, NY, USA, 2017. Curran Associates Inc
2017
-
[16]
Athleticdirectorusedaitoframeprincipalwith racist remarks, police say, 2024
AssociatedPress. Athleticdirectorusedaitoframeprincipalwith racist remarks, police say, 2024. Accessed: 2026-02-05
2024
-
[17]
Visar Berisha, Prad Kadambi, and Isabella Lenz. Why speech deepfake detectors won’t generalize: The limits of detection in an open world.arXivpreprint arXiv:2509.20405, 2025
-
[18]
Tortoise-TTS: A Multi-Voice TTS System.https: //github.com/neonbjb/tortoise- tts , 2022
James Betker. Tortoise-TTS: A Multi-Voice TTS System.https: //github.com/neonbjb/tortoise- tts , 2022. Accessed: 2024
2022
-
[19]
Using thematic analysis in psychology.Qualitativeresearchin psychology, 3(2):77–101, 2006
Virginia Braun and Victoria Clarke. Using thematic analysis in psychology.Qualitativeresearchin psychology, 3(2):77–101, 2006
2006
-
[20]
Miles Brundage, Shahar Avin, Jack Clark, Helen Toner, Peter Eckersley, Ben Garfinkel, Allan Dafoe, Paul Scharre, Thomas Zeitzoff, Bobby Filar, et al. The malicious use of artificial intel- ligence: Forecasting, prevention, and mitigation.arXivpreprint arXiv:1802.07228, 2018
-
[21]
Gendershades:Intersectional accuracy disparities in commercial gender classification
JoyBuolamwiniandTimnitGebru. Gendershades:Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency, pages 77–91. PMLR, 2018
2018
-
[22]
Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice con- version for everyone
Edresson Casanova, Julian Weber, Christopher D Shulby, Ar- naldo Candido Junior, Eren Gölge, and Moacir A Ponti. Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice con- version for everyone. InInternational conference on machine learning, pages 2709–2720. PMLR, 2022
2022
-
[23]
AI Watch: Global regulatory tracker - United States | White & Case LLP — whitecase.com.https://www
White & Case. AI Watch: Global regulatory tracker - United States | White & Case LLP — whitecase.com.https://www. whitecase.com/insight-our-thinking/ai-watch-globa l-regulatory-tracker-united-states , 2025. [Accessed 29-01-2026]
2025
-
[24]
Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio,
Guoguo Chen, Shuzhou Chai, Guanbo Wang, Jiayu Du, Wei- Qiang Zhang, Chao Weng, Dan Su, Daniel Povey, Jan Trmal, Junbo Zhang, et al. Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio.arXiv preprint arXiv:2106.06909, 2021
-
[25]
Ju-chieh Chou, Cheng-chieh Yeh, and Hung-yi Lee. One-shot voiceconversionbyseparatingspeakerandcontentrepresentations with instance normalization.arXiv preprint arXiv:1904.05742, 2019
-
[26]
Between truth and power
Julie E Cohen. Between truth and power. Oxford University Press, 2019
2019
-
[27]
Congress
U.S. Congress. H.r.5388 – american artificial intelligence lead- ership and uniformity act.https://www.congress.gov/bil l/119th-congress/house-bill/5388 , 2025. Introduced in 119th Congress; referred to committee
2025
-
[28]
Coqui TTS: Deep Learning Toolkit for Text-to-Speech
Coqui AI. Coqui TTS: Deep Learning Toolkit for Text-to-Speech. https://github.com/coqui-ai/TTS, 2024. Accessed: 2024
2024
-
[29]
The us approach to ai regulation: federal laws, policies,andstrategiesexplained
Tatevik Davtyan. The us approach to ai regulation: federal laws, policies,andstrategiesexplained. JournalofLaw,Technology,& the Internet, 16(2):223, 2025
2025
-
[30]
Defending speaker verification against deepfake: A multi-step approach
Thien-Phuc Doan, Hung Dinh-Xuan, Inho Kim, Woongjae Lee, SeongKyu Han, and Souhwan Jung. Defending speaker verification against deepfake: A multi-step approach. In Proceedingsofthe1stACMWorkshoponDeepfake,Deception, andDisinformationSecurity, pages 44–51, 2025
2025
-
[31]
Oxford Uni- versity Press, 2020
Sam Dubberley, Alexa Koenig, and Daragh Murray.Digital witness: using open source information for human rights investigation,documentation, and accountability. Oxford Uni- versity Press, 2020
2020
-
[32]
Trump says he’ll sign executive order blocking state AI regulations, despite safety fears | CNN Business
Clare Duffy. Trump says he’ll sign executive order blocking state AI regulations, despite safety fears | CNN Business
-
[33]
ElevenLabs: Prime Voice AI.https://elevenla bs.io/, 2024
ElevenLabs. ElevenLabs: Prime Voice AI.https://elevenla bs.io/, 2024. Accessed: 2024
2024
-
[34]
General data protection regulation (gdpr).https: //gdpr-info.eu/, 2018
EU GDPR. General data protection regulation (gdpr).https: //gdpr-info.eu/, 2018. Official consolidated text of the EU data protection regulation; accessed 2026-01-29
2018
-
[35]
European Commission. Regulation (eu) 2024/1689 of the eu- ropean parliament and of the council of 13 june 2024 laying down harmonised rules on artificial intelligence and amending regulations(ec)no300/2008. http://data.europa.eu/eli/r eg/2024/1689/oj, 2024. Addition to the GDPR about AI from the EU
2024
-
[36]
Preventing Woke AI in the Federal Government
Executive Office of the President. Preventing Woke AI in the Federal Government
-
[37]
Promoting the Export of the American AI Technology Stack
Executive Office of the President. Promoting the Export of the American AI Technology Stack
-
[38]
Creating, using, misusing, and detecting deep fakes
Hany Farid. Creating, using, misusing, and detecting deep fakes. Journal ofOnlineTrustandSafety, 2022
2022
-
[39]
Internet crime complaint center (ic3), n.d
Federal Bureau of Investigation. Internet crime complaint center (ic3), n.d. Accessed: 2026-02-05. 14
2026
-
[40]
Ftc voice cloning challenge.https: //www.ftc.gov/news-events/contests/ftc-voice-clo ning-challenge , 2026
Federal Trade Commission. Ftc voice cloning challenge.https: //www.ftc.gov/news-events/contests/ftc-voice-clo ning-challenge , 2026. FTC initiative addressing consumer harms from AI-enabled voice cloning
2026
-
[41]
Timit acoustic-phonetic continuous speech corpus.(NoTitle), 1993
JohnSGarofolo,LoriFLamel,WilliamMFisher,DavidSPallett, Nancy L Dahlgren, Victor Zue, and Jonathan G Fiscus. Timit acoustic-phonetic continuous speech corpus.(NoTitle), 1993
1993
-
[42]
Google Cloud Text-to-Speech.https://cloud.goog le.com/text-to-speech, 2024
Google. Google Cloud Text-to-Speech.https://cloud.goog le.com/text-to-speech, 2024. Accessed: 2024
2024
-
[43]
Pressprotect: Helping journalists navigate social media in the face of online harassment
Catherine Han, Anne Li, Deepak Kumar, and Zakir Durumeric. Pressprotect: Helping journalists navigate social media in the face of online harassment. Proceedings of the ACM on Human-Computer Interaction, 8(CSCW2):1–34, 2024
2024
-
[44]
Not myvoice!ataxonomyofethicalandsafetyharmsofspeechgener- ators
Wiebke Hutiri, Orestis Papakyriakopoulos, and Alice Xiang. Not myvoice!ataxonomyofethicalandsafetyharmsofspeechgener- ators. InProceedingsofthe2024ACMConferenceonFairness, Accountability,andTransparency,FAccT’24,page359–376,New York, NY, USA, 2024. Association for Computing Machinery
2024
-
[45]
Transfer learning from speaker verification to multispeaker text-to-speech synthesis
Ye Jia, Yu Zhang, Ron Weiss, Quan Wang, Jonathan Shen, Fei Ren, Patrick Nguyen, Ruoming Pang, Ignacio Lopez Moreno, Yonghui Wu, et al. Transfer learning from speaker verification to multispeaker text-to-speech synthesis. Advances in neural informationprocessingsystems, 31, 2018
2018
-
[46]
Libri-light: A benchmark for asr with limited or no supervision
Jacob Kahn, Morgane Riviere, Weiyi Zheng, Evgeny Kharitonov, Qiantong Xu, Pierre-Emmanuel Mazaré, Julien Karadayi, Vitaliy Liptchinsky,RonanCollobert,ChristianFuegen,etal. Libri-light: A benchmark for asr with limited or no supervision. InICASSP 2020-2020IEEEInternationalConferenceonAcoustics,Speech andSignalProcessing(ICASSP), pages 7669–7673. IEEE, 2020
2020
-
[47]
Librivox: Free public domain audiobooks, 2014
Jodi Kearns. Librivox: Free public domain audiobooks, 2014
2014
-
[48]
Conditional varia- tionalautoencoderwithadversariallearningforend-to-endtext-to- speech
Jaehyeon Kim, Jungil Kong, and Juhee Son. Conditional varia- tionalautoencoderwithadversariallearningforend-to-endtext-to- speech. InInternationalConferenceonMachineLearning,pages 5530–5540. PMLR, 2021
2021
-
[49]
Thesimpleeconomicsofcybercrimes
NirKshetri. Thesimpleeconomicsofcybercrimes. IEEESecurity &Privacy, 4(1):33–39, 2006
2006
-
[50]
Voicebox: Text-guided multilingual univer- sal speech generation at scale.Advancesin neural information processingsystems, 36:14005–14034, 2023
Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, RashelMoritz,MaryWilliamson,VimalManohar,YossiAdi,Jay Mahadeokar, et al. Voicebox: Text-guided multilingual univer- sal speech generation at scale.Advancesin neural information processingsystems, 36:14005–14034, 2023
2023
-
[51]
A hierarchical speaker representation framework for one-shot singing voice conversion
Xu Li, Shansong Liu, and Ying Shan. A hierarchical speaker representation framework for one-shot singing voice conversion. arXivpreprint arXiv:2206.13762, 2022
-
[52]
Fish-speech:Leveraginglargelan- guage models for advanced multilingual text-to-speech synthesis,
ShijiaLiao,YuxuanWang,TianyuLi,YifanCheng,RuoyiZhang, RongzhiZhou,andYijinXing. Fish-speech:Leveraginglargelan- guage models for advanced multilingual text-to-speech synthesis,
- [53]
-
[54]
Autoregressive diffusion transformer for text-to-speech synthesis
Zhijun Liu, Shuai Wang, Sho Inoue, Qibing Bai, and Haizhou Li. Autoregressive diffusion transformer for text-to-speech synthesis. arXivpreprint arXiv:2406.05551, 2024
-
[55]
Warning: Humans cannot reliably detect speech deepfakes.Plos one, 18(8):e0285333, 2023
Kimberly T Mai, Sergi Bray, Toby Davies, and Lewis D Griffin. Warning: Humans cannot reliably detect speech deepfakes.Plos one, 18(8):e0285333, 2023
2023
-
[56]
The creation and detection of deepfakes: A survey.ACMcomputingsurveys(CSUR),54(1):1– 41, 2021
Yisroel Mirsky and Wenke Lee. The creation and detection of deepfakes: A survey.ACMcomputingsurveys(CSUR),54(1):1– 41, 2021
2021
-
[57]
The economics of cybersecurity: Principles and policy options
Tyler Moore. The economics of cybersecurity: Principles and policy options. International Journal of Critical Infrastructure Protection, 3(3-4):103–117, 2010
2010
-
[58]
Does Audio Deepfake Detection Generalize?
Nicolas M Müller, Pavel Czempin, Franziska Dieckmann, Adam Froghyar, and Konstantin Böttinger. Does audio deepfake detec- tion generalize?arXiv preprint arXiv:2203.16263, 2022
-
[59]
Humanper- ceptionofaudiodeepfakes
NicolasMMüller,KarlaPizzi,andJenniferWilliams. Humanper- ceptionofaudiodeepfakes. In Proceedingsofthe1stinternational workshopondeepfakedetectionforaudiomultimedia,pages85– 91, 2022
2022
-
[60]
V oxCeleb: A large-scale speaker identifica- tion dataset
Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. Vox- celeb: a large-scale speaker identification dataset.arXivpreprint arXiv:1706.08612, 2017
-
[61]
Aim: Ai incidents and hazards monitor (incidents portal).https://oecd.ai/en/incidents,
OECD AI Policy Observatory. Aim: Ai incidents and hazards monitor (incidents portal).https://oecd.ai/en/incidents,
-
[62]
OECD portal documenting AI incidents and hazards
-
[63]
OpenAI Text-to-Speech API.https://platform.o penai.com/docs/guides/text-to-speech, 2024
OpenAI. OpenAI Text-to-Speech API.https://platform.o penai.com/docs/guides/text-to-speech, 2024. Accessed: 2024
2024
-
[64]
Librispeech: an asr corpus based on public domain au- dio books
Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khu- danpur. Librispeech: an asr corpus based on public domain au- dio books. In2015 IEEE international conferenceon acoustics, speechandsignalprocessing(ICASSP),pages5206–5210.IEEE, 2015
2015
-
[65]
InProceedings of 5th International ConferenceonSpeechProsody(SpeechProsody2010),Chicago, Illinois, 2010
KishorePrahallad,EVeeraRaghavendra,andAlanWBlack.Semi- supervised learning of acoustic driven prosodic phrase breaks for text-to-speech systems. InProceedings of 5th International ConferenceonSpeechProsody(SpeechProsody2010),Chicago, Illinois, 2010
2010
-
[66]
Openvoice: Versatile instant voice cloning
ZengyiQin,WenliangZhao,XuminYu,andXinSun. Openvoice: Versatileinstantvoicecloning. arXivpreprintarXiv:2312.01479, 2023
-
[67]
Qwen3-tts technical report.https://github.com /QwenLM/Qwen3-TTS/blob/main/assets/Qwen3_TTS.pdf
Qwen Team. Qwen3-tts technical report.https://github.com /QwenLM/Qwen3-TTS/blob/main/assets/Qwen3_TTS.pdf . GitHub repository PDF, accessed Feb. 5, 2026
2026
-
[68]
Robust speech recognition via large-scale weak supervision
AlecRadford,JongWookKim,TaoXu,GregBrockman,Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. In International conference on machinelearning, pages 28492–28518. PMLR, 2023
2023
-
[69]
Millions}of people are watching{you
Patrawat Samermit, Anna Turner, Patrick Gage Kelley, Tara Matthews, Vanessia Wu, Sunny Consolvo, and Kurt Thomas. {“Millions}of people are watching{you”}: Understanding the {Digital-Safety}needsandpracticesofcreators. In 32ndUSENIX Security Symposium(USENIXSecurity 23), pages 5629–5645, 2023
2023
-
[70]
Human perception of audio deepfakes: the roleoflanguageandspeakingstyle
Eugenia San Segundo, Aurora López-Jareño, Xin Wang, and Junichi Yamagishi. Human perception of audio deepfakes: the roleoflanguageandspeakingstyle. AvailableatSSRN5954496, 2025
2025
-
[71]
Verifying humanness: Personhood credentials for the digital identity crisis
Tanusree Sharma. Verifying humanness: Personhood credentials for the digital identity crisis. 2025
2025
-
[72]
An analysis of phish- ing emails and how the human vulnerabilities are exploited
Tanusree Sharma and Masooda Bashir. An analysis of phish- ing emails and how the human vulnerabilities are exploited. In International Conference on Applied Human Factors and Ergonomics, pages 49–55. Springer, 2020
2020
-
[73]
Aligning ai with public values: Deliberation and decision-making for governing multimodal llms in political video analysis
Tanusree Sharma, Yujin Potter, Zachary Kilhoffer, Yun Huang, Dawn Song, and Yang Wang. Aligning ai with public values: Deliberation and decision-making for governing multimodal llms in political video analysis. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, pages 2345– 2359, 2025
2025
-
[74]
Disability- first design and creation of a dataset showing private visual information collected with people who are blind
Tanusree Sharma, Abigale Stangl, Lotus Zhang, Yu-Yun Tseng, InanXu,LeahFindlater,DannaGurari,andYangWang. Disability- first design and creation of a dataset showing private visual information collected with people who are blind. InProceedings of the 2023 CHI Conference on Human Factors in Computing Systems, pages 1–15, 2023. 15
2023
-
[75]
be- fore, i asked my mom, now i ask chatgpt
TanusreeSharma,Yu-YunTseng,LotusZhang,AyaeIde,KellyAv- ery Mack, Leah Findlater, Danna Gurari, and Yang Wang. “be- fore, i asked my mom, now i ask chatgpt”: Visual privacy management with generative ai for blind and low-vision peo- ple. InProceedingsofthe27thInternationalACMSIGACCESS Conferenceon Computersand Accessibility, pages 1–14, 2025
2025
-
[76]
Prac3(privacy, reputation, accountability, consent, credit, compensation): Voice actors in ai data-economy
TanusreeSharma,YihaoZhou,andVisarBerisha. Prac3(privacy, reputation, accountability, consent, credit, compensation): Voice actors in ai data-economy. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 8, pages 2360– 2372, 2025
2025
-
[77]
Sociotechnical harms of algorithmic systems: Scoping a taxonomy for harm reduction
Renee Shelby, Shalaleh Rismani, Kathryn Henne, AJung Moon, Negar Rostamzadeh, Paul Nicholas, N’Mah Yilla-Akbari, Jess Gallegos, Andrew Smart, Emilio Garcia, et al. Sociotechnical harms of algorithmic systems: Scoping a taxonomy for harm reduction. InProceedings of the 2023 AAAI/ACMConference onAI, Ethics,andSociety, pages 723–741, 2023
2023
-
[78]
Yakun Song, Zhuo Chen, Xiaofei Wang, Ziyang Ma, Guanrou Yang, and Xie Chen. Tacolm: Gated attention equipped codec language model are efficient zero-shot text to speech synthesizers. arXivpreprint arXiv:2406.15752, 2024
-
[79]
Data is the new what? popularmetaphors&professionalethicsinemergingdataculture
Luke Stark and Anna Lauren Hoffmann. Data is the new what? popularmetaphors&professionalethicsinemergingdataculture. Journal of Cultural Analytics, 4(1), 2019
2019
-
[80]
Natu- ralspeech: End-to-end text-to-speech synthesis with human-level quality
XuTan,JiaweiChen,HaoheLiu,JianCong,ChenZhang,Yanqing Liu, Xi Wang, Yichong Leng, Yuanhao Yi, Lei He, et al. Natu- ralspeech: End-to-end text-to-speech synthesis with human-level quality. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(6):4234–4245, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.